Closure-Validated Circuit Discovery in Attention Heads: Co-activation Proposes, Ablation Disposes
Pith reviewed 2026-06-27 17:18 UTC · model grok-4.3
The pith
Co-activation clusters propose attention-head circuits while ablation closure confirms or rejects them as causal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
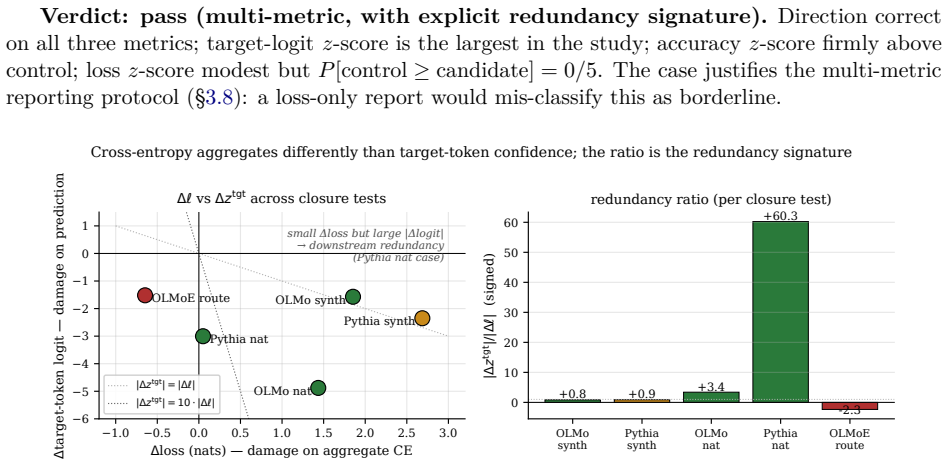
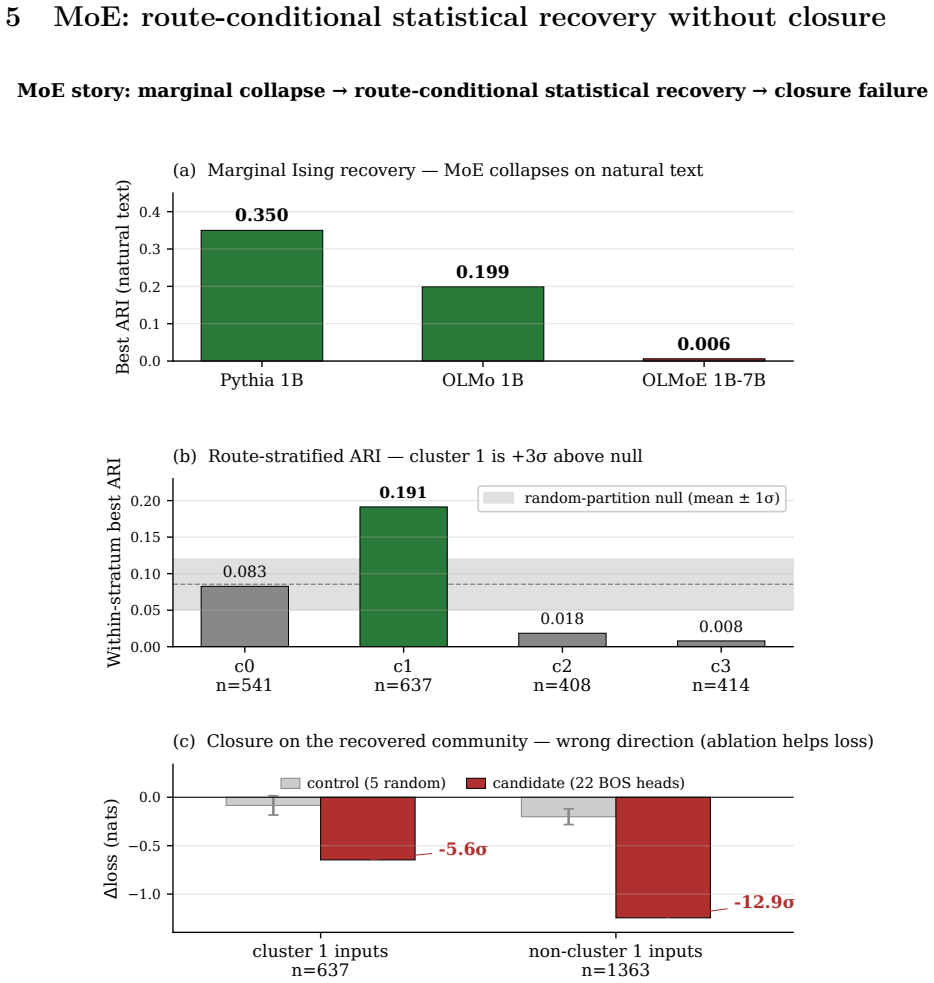
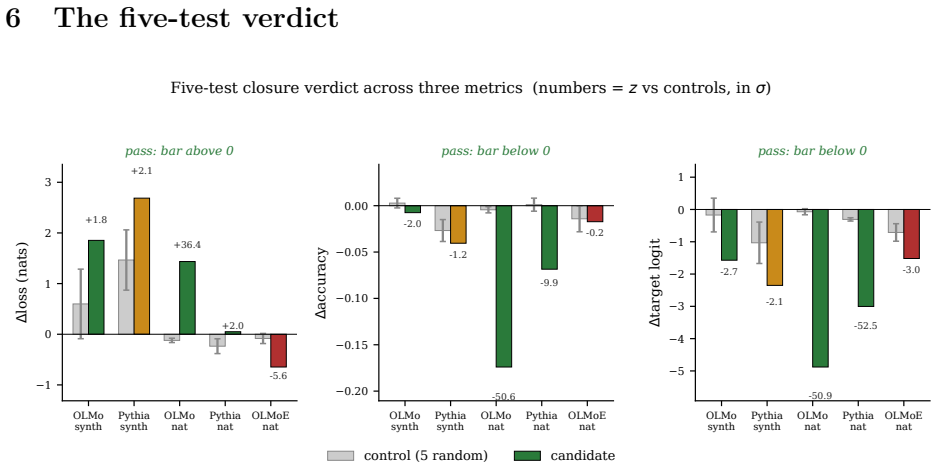
Adapting sparse-autoencoder-style clustering to attention heads and validating by causal ablation rather than reconstruction, the discovered communities pass closure tests across two dense 1B-scale models and two input distributions, whereas route-conditional clusters in an MoE model recover a signal that fails closure because ablation improves loss.
What carries the argument
The closure test that ablates a co-activation community and compares per-example damage to matched-random controls.
If this is right
- In dense transformers, co-activation communities identified by clustering function as causal circuits under the closure criterion.
- In MoE models, route-conditional clustering recovers a detectable signal whose ablation improves rather than harms loss.
- Attention-target selectivity and participation ratio decouple from functional circuit membership both during and across training.
- A cheap co-activation signal remains only a circuit proposal until closure validation is applied.
Where Pith is reading between the lines
- The same closure procedure could be applied to other component types such as MLP neurons or residual streams to test generality.
- Failure of closure in MoE settings points to the value of incorporating routing information directly into the clustering objective.
- Longitudinal application of closure across checkpoints could track when candidate communities become or cease to be causal.
Load-bearing premise
That ablation damage relative to matched-random controls is a valid measure of whether a co-activation community functions as a causal circuit.
What would settle it
A dense-model experiment in which a co-activation community identified by clustering produces less damage under ablation than its matched-random controls would falsify the claim that the communities pass closure.
Figures
read the original abstract
Interpretability increasingly treats groups of components, not individual units, as the basic object, and proposes to find them by clustering co-activation statistics. We ask whether such a cheap signal actually identifies an attention-head circuit. Adapting a sparse-autoencoder clustering recipe to attention heads -- but validating by causal ablation rather than reconstruction -- we cluster heads and then run a closure test: ablate the discovered community and compare per-example damage to matched-random controls. Across two dense 1B-scale models (Pythia 1B, OLMo 1B) and two input distributions, the communities pass closure. In a Mixture-of-Experts model (OLMoE-1B-7B), route-conditional clustering recovers a statistically real signal that nonetheless does not survive closure -- ablation improves loss, the wrong direction. Extending closure across training, attention-target selectivity and participation ratio decouple from function in both directions. We conclude that a cheap signal is a circuit proposal, not a confirmed circuit; closure is what separates them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that co-activation clustering of attention heads yields circuit proposals rather than confirmed circuits, and that a closure test (ablating the community and comparing per-example loss increase to size-matched random controls) is required for validation. It reports that the discovered communities pass this test in two dense 1B-scale models (Pythia 1B, OLMo 1B) across input distributions, but fail in an MoE model (where ablation improves loss). It further shows that attention-target selectivity and participation ratio decouple from functional impact when closure is tracked across training checkpoints.
Significance. If the closure test is valid, the work supplies a concrete, falsifiable distinction between correlational proposals and causally effective circuits, with the MoE counter-example and training-time decoupling providing useful negative results. The choice to validate by ablation rather than reconstruction error is a methodological strength, as is the multi-model, multi-distribution design. The approach could inform future clustering-based interpretability pipelines by emphasizing the need for causal checks.
major comments (1)
- [Abstract] Abstract (closure test paragraph): The central claim that communities 'pass closure' rests on greater ablation damage relative to matched-random controls. This comparison supports the circuit interpretation only if the random sets adequately control for confounders such as per-head importance, layer distribution, and activation magnitude; otherwise the test can succeed whenever clustering simply aggregates individually salient heads. The manuscript must specify the exact matching procedure and report verification that the controls are balanced on these metrics.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit controls in the closure test. The comment correctly identifies a point where additional methodological detail will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (closure test paragraph): The central claim that communities 'pass closure' rests on greater ablation damage relative to matched-random controls. This comparison supports the circuit interpretation only if the random sets adequately control for confounders such as per-head importance, layer distribution, and activation magnitude; otherwise the test can succeed whenever clustering simply aggregates individually salient heads. The manuscript must specify the exact matching procedure and report verification that the controls are balanced on these metrics.
Authors: We agree that the current description of the matched-random controls is insufficiently precise. The revised manuscript will add an explicit subsection detailing the matching procedure: random sets are sampled to match the discovered community on (i) layer distribution (exact layer counts), (ii) mean activation magnitude across the evaluation set, and (iii) a binned histogram of per-head importance scores (measured as mean ablation damage when heads are removed individually). We will also include supplementary figures verifying that the control distributions are statistically indistinguishable from the community on these three metrics (Kolmogorov-Smirnov tests, p > 0.1). These additions will be placed in the Methods section and referenced from the abstract. revision: yes
Circularity Check
No significant circularity; validation uses independent causal ablation
full rationale
The paper clusters heads via co-activation statistics then validates via a separate ablation-based closure test against matched-random controls. This test is an external causal intervention whose outcome is not algebraically or statistically forced by the clustering inputs. No self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the method or claims. The result that communities pass closure is therefore an empirical finding rather than a definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ablation of attention-head communities measures their causal contribution to model behavior
Reference graph
Works this paper leans on
-
[1]
J. Besag. Statistical analysis of non-lattice data.The Statistician, 24(3):179–195, 1975
1975
-
[2]
Do Sparse Autoencoders Capture Concept Manifolds?
U. Bhalla, T. Fel, C. Rager, S. Feucht, T. Haklay, D. Wurgaft, S. Boppana, M. Kowal, V. Shyam, O. Lewis, T. McGrath, J. Merullo, A. Geiger, and E. S. Lubana. Do sparse autoencoders capture concept manifolds?arXiv preprint arXiv:2604.28119, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Conmy, A
A. Conmy, A. N. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[4]
arXiv preprint arXiv:2405.14860 , year=
J. Engels, E. J. Michaud, I. Liao, W. Gurnee, and M. Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860, 2024
-
[5]
Interpreting language model parameters
Goodfire. Interpreting language model parameters. Goodfire research note, 2026. https: //www.goodfire.ai/research/interpreting-lm-parameters
2026
-
[6]
S. Kantamneni and M. Tegmark. Language models use trigonometry to do addition.arXiv preprint arXiv:2502.00873, 2025
-
[7]
Olsson, N
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, et al. In-context learning and induction heads.Transformer Circuits Thread, 2022
2022
-
[8]
K. Park, Y. J. Choe, and V. Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [9]
-
[10]
Ravikumar, M
P. Ravikumar, M. J. Wainwright, and J. D. Lafferty. High-dimensional Ising model selection usingℓ1-regularized logistic regression.The Annals of Statistics, 38(3):1287–1319, 2010
2010
-
[11]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InInternational Conference on Learning Representations (ICLR), 2023. 21
2023
-
[12]
Y. Xu. Spectral probe-circuits: a three-step recipe for identifying attention-head circuits in pretrained transformers.arXiv preprint arXiv:2605.24059, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
B. Zoph, I. Bello, S. Kumar, N. Du, Y. Huang, J. Dean, N. Shazeer, and W. Fedus. ST-MoE: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906, 2022. A Route-cluster routing-entropy diagnostic The four route clusters’ mean per-layer routing entropy on the OLMoE natural-text batch: ClusternMean per-layerH(nats) Fraction of ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.