DexPIE: Stable Dexterous Policy Improvement from Real-World Experience
Pith reviewed 2026-06-27 16:45 UTC · model grok-4.3
The pith
DexPIE improves dexterous manipulation policies by turning real-world deployment experience into refined actions through intervention and asynchronous processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
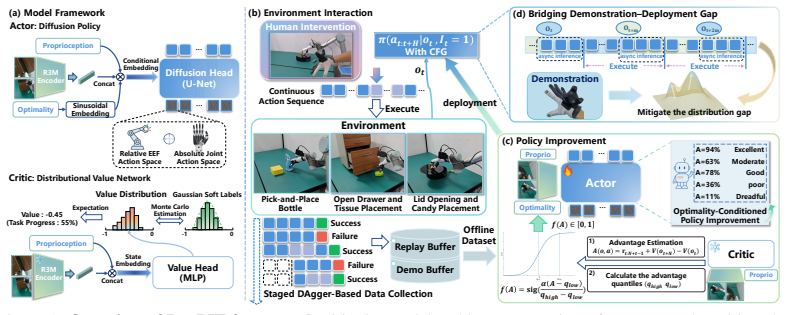
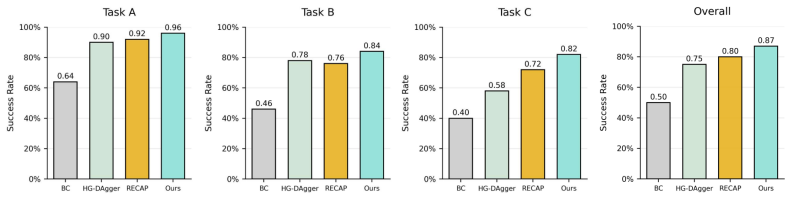
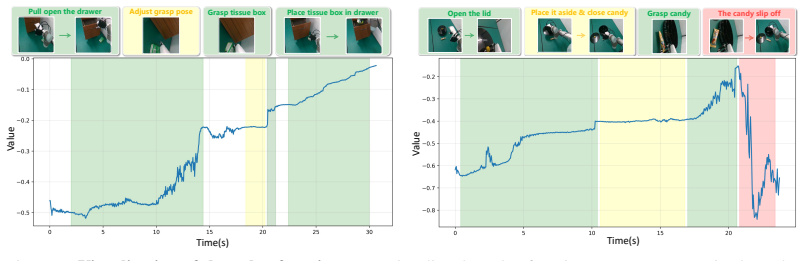
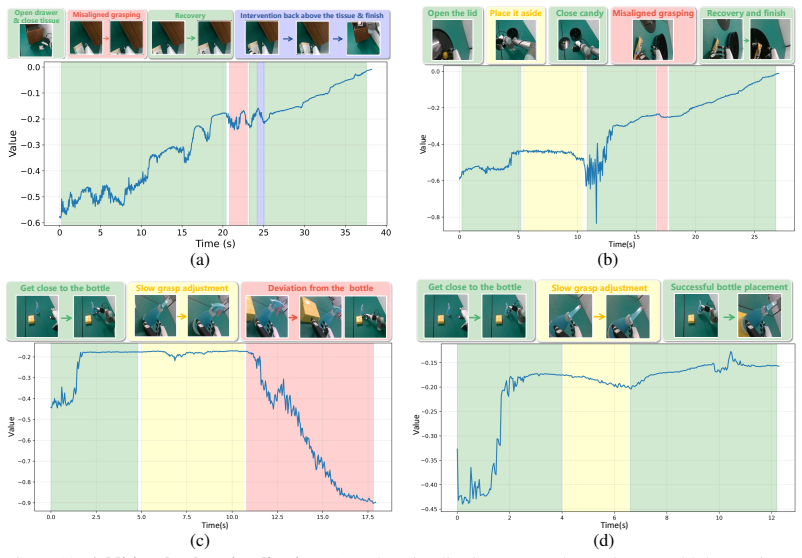
The paper claims that DexPIE, a post-training framework, enables stable improvement of dexterous policies from real-world experience. It does so by using a dexterous-hand-adapted intervention system and multi-stage DAgger-style data collection to gather reliable supervision data. Asynchronous inference in the relative action space reduces temporal noise, allowing better value function learning. Conditioning on a continuous optimality indicator lets the policy use data quality in a fine-grained way. This yields a 37% improvement in success rate over the demonstration-based reference policy across three challenging real-world tasks.
What carries the argument
DexPIE's key machinery is the post-training pipeline that combines multi-stage intervention-based data collection, asynchronous relative-action inference, and optimality-indicator conditioning to refine the policy from deployment experience.
If this is right
- The approach allows policies to be improved without needing large amounts of additional expert demonstrations.
- Data alignment through asynchronous inference in relative action space enables more consistent critic learning.
- Conditioning on continuous optimality allows fine-grained leverage of varying data quality.
- The method demonstrates stronger robustness compared to baseline methods on the tasks.
- Success rates increase by 37% over the reference policy on three real-world dexterous manipulation tasks.
Where Pith is reading between the lines
- Similar post-training loops could be applied to other robotics domains with high-dimensional actions to reduce reliance on demonstrations.
- The framework might enable continuous online improvement if the intervention system can be automated further.
- The relative action space technique may help in other settings where timing between expert and learner actions differs.
Load-bearing premise
The human-provided interventions in the adapted system supply reliable and unbiased signals for accurate policy evaluation and improvement.
What would settle it
Observing no improvement or a decrease in success rate when applying DexPIE to the three tasks compared to the reference policy under the same evaluation conditions would falsify the central performance claim.
Figures








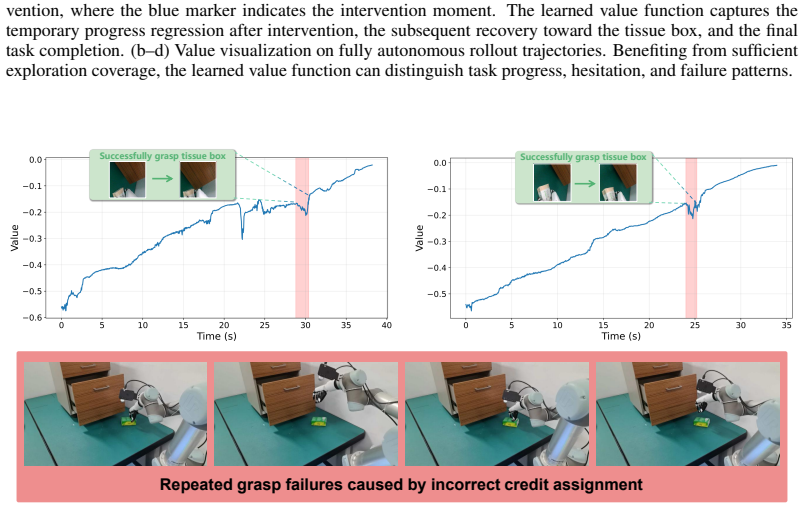

read the original abstract
Dexterous manipulation presents substantial challenges for imitation learning due to its high-dimensional action space and complex contact-rich dynamics. Policies trained purely from demonstrations often suffer from compounding errors during deployment and require large amounts of expert data to achieve reliable performance. To move beyond the limitations of demonstration data, in this work, we propose DexPIE, a post-training framework for dexterous policy improvement from experience collected through real-world deployment. First, DexPIE enables effective exploration coverage through a dexterous-hand-adapted intervention system and multi-stage DAgger-style data collection across initial and intermediate task stages, providing reliable supervision for accurate policy evaluation. To reduce temporal noise between post-training rollouts and demonstration data, we introduce asynchronous inference in the relative action space, which better aligns rollout data with demonstrated behavior and allows the critic to learn a value function induced by a more consistent underlying policy. Finally, DexPIE improves the policy through conditioning on a continuous optimality indicator, allowing the policy to leverage the quality of data in a more fine-grained manner. Across three challenging real-world dexterous manipulation tasks, DexPIE achieves a 37% improvement in success rate over the demonstration-based reference policy, outperforming all baseline methods and demonstrating stronger robustness. The source code and dataset will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DexPIE, a post-training framework to improve dexterous manipulation policies beyond pure imitation learning by collecting and leveraging real-world deployment experience. Key components include a dexterous-hand-adapted intervention system with multi-stage DAgger-style data collection for exploration and supervision, asynchronous inference in relative action space to align rollout and demonstration data, and policy conditioning on a continuous optimality indicator. The central empirical claim is a 37% success-rate improvement over a demonstration-based reference policy across three challenging real-world tasks, with outperformance of baselines and increased robustness. Code and dataset release is promised.
Significance. If the results hold under rigorous controls, the work could meaningfully advance imitation learning for high-dimensional, contact-rich dexterous tasks by showing how targeted real-world experience collection and fine-grained data quality conditioning can mitigate compounding errors without requiring vastly more expert demonstrations. The reproducibility commitment via public code and data is a positive factor.
major comments (2)
- [Abstract] Abstract: the 37% success-rate gain and robustness claims are presented without any description of the three tasks, baseline methods, trial counts, statistical tests, or failure-mode analysis; this directly undermines assessment of whether the improvement is load-bearing or reproducible.
- [Framework description] Framework description (as summarized): the claim that the dexterous-hand-adapted intervention system plus multi-stage DAgger-style collection supplies reliable supervision for policy evaluation is asserted without visible evidence or ablation; this is the weakest assumption supporting the entire post-training pipeline.
minor comments (1)
- [Abstract] The abstract would benefit from naming the three tasks and briefly characterizing the baselines to allow readers to gauge scope.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to clarify the manuscript. We address each major comment below with specific responses and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 37% success-rate gain and robustness claims are presented without any description of the three tasks, baseline methods, trial counts, statistical tests, or failure-mode analysis; this directly undermines assessment of whether the improvement is load-bearing or reproducible.
Authors: We agree the abstract is highly condensed and omits key evaluation details. Task descriptions, baseline methods, trial counts (20+ per condition), and qualitative failure analysis appear in Sections 4 and 5. No formal statistical hypothesis tests were conducted, consistent with standard practice in real-world robotics papers. We will revise the abstract to briefly reference the three tasks, evaluation protocol, and trial scale while respecting length limits. revision: partial
-
Referee: [Framework description] Framework description (as summarized): the claim that the dexterous-hand-adapted intervention system plus multi-stage DAgger-style collection supplies reliable supervision for policy evaluation is asserted without visible evidence or ablation; this is the weakest assumption supporting the entire post-training pipeline.
Authors: Section 3.2 describes the adapted intervention and multi-stage collection process, which supplies human-corrected trajectories at critical contact stages. The main results in Section 5 show performance gains from the resulting dataset. We acknowledge the absence of a dedicated ablation isolating this component. We will add such an ablation study in the revised manuscript to provide direct empirical support. revision: yes
Circularity Check
No significant circularity; empirical claim stands on measured outcomes
full rationale
The manuscript describes a post-training framework (intervention system, multi-stage DAgger collection, asynchronous relative-action inference, optimality-indicator conditioning) whose central claim is an empirical 37% success-rate gain on three real-world tasks. No equations, fitted parameters, or derivation steps are present that reduce by construction to the inputs; the reported performance is an external measurement rather than a self-defined quantity. No load-bearing self-citations or uniqueness theorems appear in the provided text. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: A Vision-Language-Action Model with Open-World Generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[3]
H. Luo, Y . Wang, W. Zhang, S. Zheng, Z. Xi, C. Xu, H. Xu, H. Yuan, C. Zhang, Y . Wang, et al. Being-h0. 5: Scaling human-centric robot learning for cross-embodiment generalization. arXiv preprint arXiv:2601.12993, 2026
arXiv 2026
-
[4]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[5]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[6]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[7]
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters. An algorithmic perspective on imitation learning. Foundations and Trends® in Robotics, 7(1-2):1–179, 2018
2018
-
[8]
R. S. Sutton, A. G. Barto, et al. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[9]
A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al. π∗ 0.6: A vla that learns from experience. arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[10]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy. arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[11]
Y . Li, X. Ma, J. Xu, Y . Cui, Z. Cui, Z. Han, L. Huang, T. Kong, Y . Liu, H. Niu, et al. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation. arXiv preprint arXiv:2512.01801, 2025
arXiv 2025
-
[12]
R. Yang, H. Wang, C. Liu, X. Yan, Y . Wang, X. Du, S. Yue, Y . Liu, C. Zhang, L. Qi, et al. Aloe: Action-level off-policy evaluation for vision-language-action model post-training.arXiv preprint arXiv:2602.12691, 2026
Pith/arXiv arXiv 2026
-
[13]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning. Science Robotics, 10(105):eads5033, 2025
2025
-
[14]
C. Xu, Q. Li, J. Luo, and S. Levine. Rldg: Robotic generalist policy distillation via reinforce- ment learning. arXiv preprint arXiv:2412.09858, 2024
arXiv 2024
-
[15]
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation. arXiv preprint arXiv:2509.25358, 2025. 9
Pith/arXiv arXiv 2025
- [16]
-
[17]
Y . Mao, Z. Yu, W. Mao, Y . Li, Q. Hu, Z. Lan, M. Zhu, and H. Chen. Arm: Advantage reward modeling for long-horizon manipulation. arXiv preprint arXiv:2604.03037, 2026
Pith/arXiv arXiv 2026
-
[18]
C. Yu, C. Sima, G. Jiang, H. Zhang, H. Mai, H. Li, H. Wang, J. Chen, K. Wu, L. Chen, et al.χ0: Resource-aware robust manipulation via taming distributional inconsistencies. arXiv preprint arXiv:2602.09021, 2026
arXiv 2026
- [19]
-
[20]
J. Tang, Y . Sun, Y . Zhao, S. Yang, Y . Lin, Z. Zhang, J. Hou, Y . Lu, Z. Liu, and S. Han. Vlash: Real-time vlas via future-state-aware asynchronous inference. arXiv preprint arXiv:2512.01031, 2025
arXiv 2025
-
[21]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. Advances in Neural Information Processing Systems, 38:33383–33407, 2026
2026
-
[22]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12156–12163. IEEE, 2024
2024
-
[23]
S. Yang, M. Liu, Y . Qin, R. Ding, J. Li, X. Cheng, R. Yang, S. Yi, and X. Wang. Ace: A cross-platform visual-exoskeletons system for low-cost dexterous teleoperation.arXiv preprint arXiv:2408.11805, 2024
arXiv 2024
-
[24]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation. arXiv preprint arXiv:2403.07788, 2024
arXiv 2024
-
[25]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. arXiv preprint arXiv:2307.04577, 2023
arXiv 2023
-
[26]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[27]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In 2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[28]
Z. Hu, R. Wu, N. Enock, J. Li, R. Kadakia, Z. Erickson, and A. Kumar. Rac: Robot learning for long-horizon tasks by scaling recovery and correction. arXiv preprint arXiv:2509.07953, 2025
arXiv 2025
-
[29]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel. Robocopi- lot: Human-in-the-loop interactive imitation learning for robot manipulation. arXiv preprint arXiv:2503.07771, 2025
arXiv 2025
-
[30]
Contributors
E.-R. Contributors. Evo-rl: Towards iterative policy improvement in real-world offline rl. https://github.com/MINT-SJTU/Evo-RL, 2026
2026
-
[31]
Y . Cui, Y . Zhang, L. Tao, Y . Li, X. Yi, and Z. Li. End-to-end dexterous arm-hand vla policies via shared autonomy: Vr teleoperation augmented by autonomous hand vla policy for efficient data collection. arXiv preprint arXiv:2511.00139, 2025. 10
arXiv 2025
-
[32]
Y . Han, Z. Chen, Y . Zhao, C. Xu, Y . Shao, Y . Peng, Y . Mu, and W. Lian. Dexhil: A human-in- the-loop framework for vision-language-action model post-training in dexterous manipulation. arXiv preprint arXiv:2603.09121, 2026
arXiv 2026
-
[33]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning. arXiv preprint arXiv:2509.09674, 2025
Pith/arXiv arXiv 2025
-
[34]
S. Zhai, Q. Zhang, T. Zhang, F. Huang, H. Zhang, M. Zhou, S. Zhang, L. Liu, S. Lin, and J. Pang. A vision-language-action-critic model for robotic real-world reinforcement learning. arXiv preprint arXiv:2509.15937, 2025
arXiv 2025
-
[35]
Zhang, C
T. Zhang, C. Yu, S. Su, and Y . Wang. Reinflow: Fine-tuning flow matching policy with on- line reinforcement learning. Advances in Neural Information Processing Systems, 38:106282– 106319, 2026
2026
-
[36]
K. Chen, Z. Liu, T. Zhang, Z. Guo, S. Xu, H. Lin, H. Zang, Q. Zhang, Z. Yu, G. Fan, et al. πrl: Online rl fine-tuning for flow-based vision-language-action models. arXiv preprint arXiv:2510.25889, 2025
arXiv 2025
-
[37]
Y . J. Ma, J. Hejna, C. Fu, D. Shah, J. Liang, Z. Xu, S. Kirmani, P. Xu, D. Driess, T. Xiao, et al. Vision language models are in-context value learners. In International Conference on Learning Representations, volume 2025, pages 33984–34009, 2025
2025
- [38]
-
[39]
F. Zhu, Z. Yan, Z. Hong, Q. Shou, X. Ma, and S. Guo. Wmpo: World model-based policy optimization for vision-language-action models. arXiv preprint arXiv:2511.09515, 2025
arXiv 2025
-
[40]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, et al. Rise: Self-improving robot policy with compositional world model. arXiv preprint arXiv:2602.11075, 2026
Pith/arXiv arXiv 2026
- [41]
-
[42]
Y . Guo, T. Lee, L. X. Shi, J. Chen, P. Liang, and C. Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model. arXiv preprint arXiv:2602.12063, 2026
arXiv 2026
-
[43]
S. Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018
Pith/arXiv arXiv 2018
- [44]
-
[45]
J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[46]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[47]
M. G. Bellemare, W. Dabney, and R. Munos. A distributional perspective on reinforcement learning. In International conference on machine learning, pages 449–458. Pmlr, 2017
2017
-
[48]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020. 11
2020
-
[49]
Y . Ze, Z. Chen, W. Wang, T. Chen, X. He, Y . Yuan, X. B. Peng, and J. Wu. Generalizable hu- manoid manipulation with 3d diffusion policies. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2873–2880. IEEE, 2025
2025
-
[50]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation. arXiv preprint arXiv:2203.12601, 2022. A Implementation Details A.1 Robot Platform Base camera Wrist camera 6 Dof Arm 6 Dof Hand Figure 9: Robot setup. This section describes the robotic platform and per- ception setup used in all exp...
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.