SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
Pith reviewed 2026-06-27 16:33 UTC · model grok-4.3
The pith
A new benchmark across eight simulators shows even top multimodal agents succeed on fewer than 18 percent of interactive spatial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
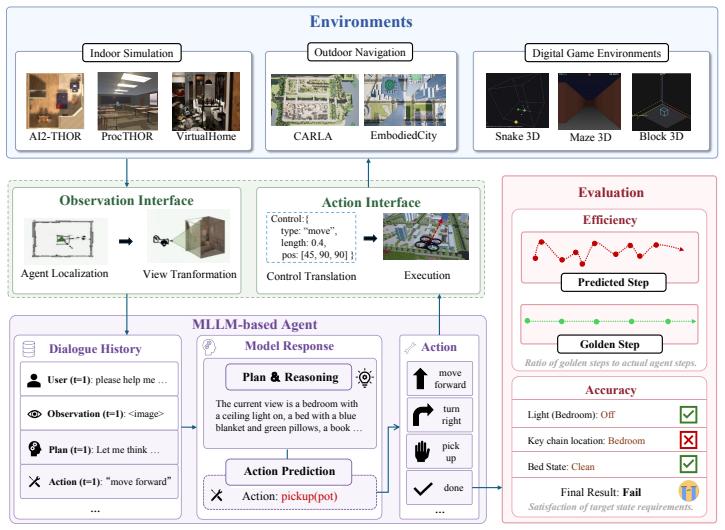
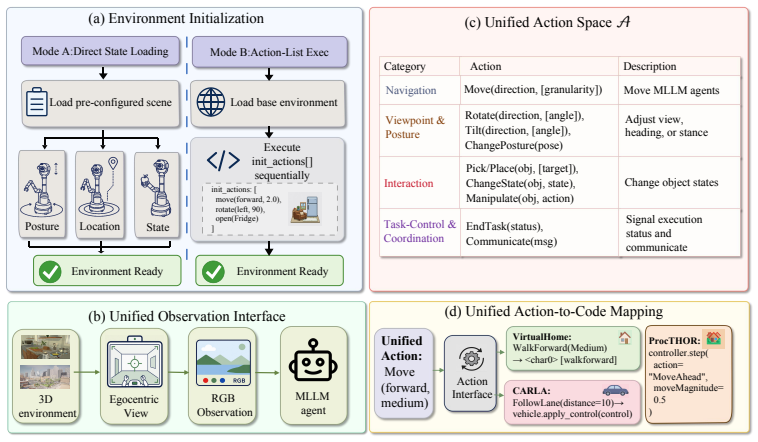
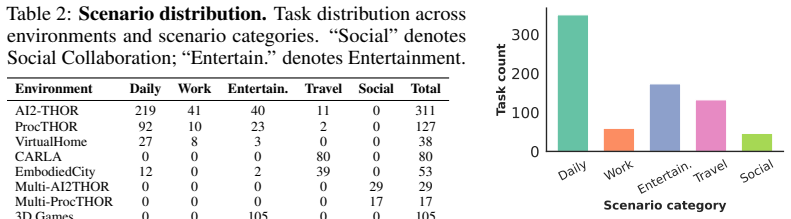
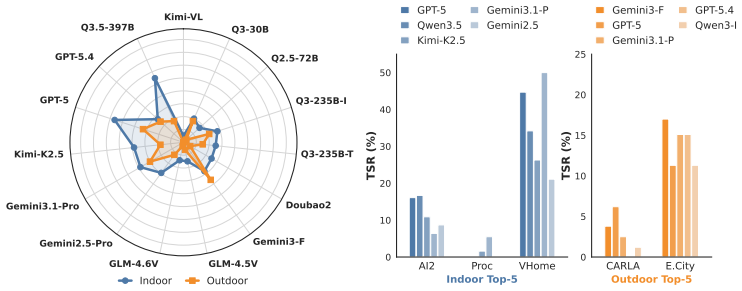
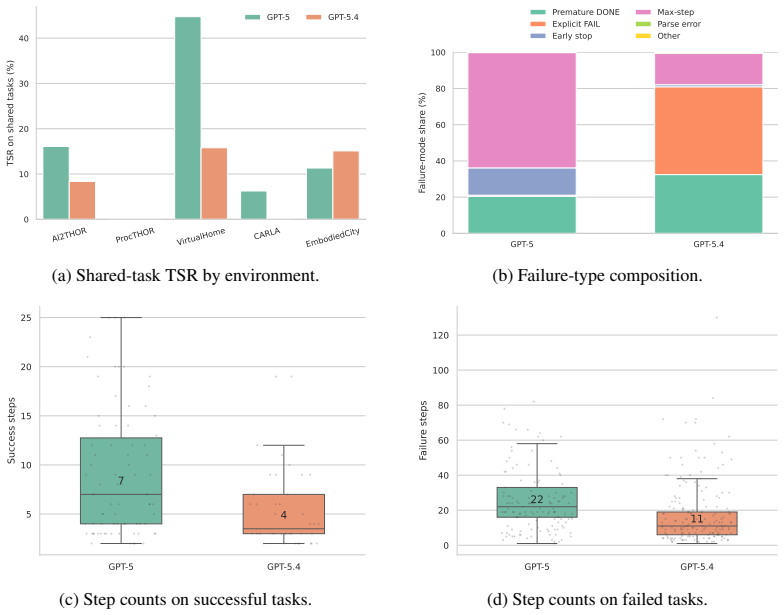
SpatialWorld integrates eight heterogeneous simulation backends under a simulator-agnostic protocol and supplies 760 tasks with human-validated initial states, reference trajectories, and terminal verifiers; under vision-only partial observability and a unified text action space, fifteen advanced agents achieve at most 17.4 percent average task success rate, exposing persistent gaps in active exploration and long-horizon planning.
What carries the argument
SpatialWorld benchmark, a simulator-agnostic collection of tasks and verifiers that forces agents to gather egocentric visual evidence and issue decisions through a single text-based action interface.
If this is right
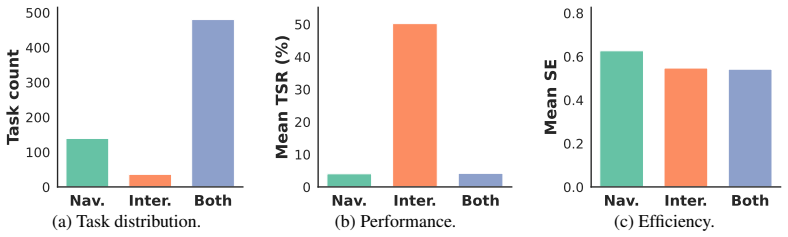
- Task success rates and execution efficiency are often mismatched, so efficiency metrics must be tracked separately.
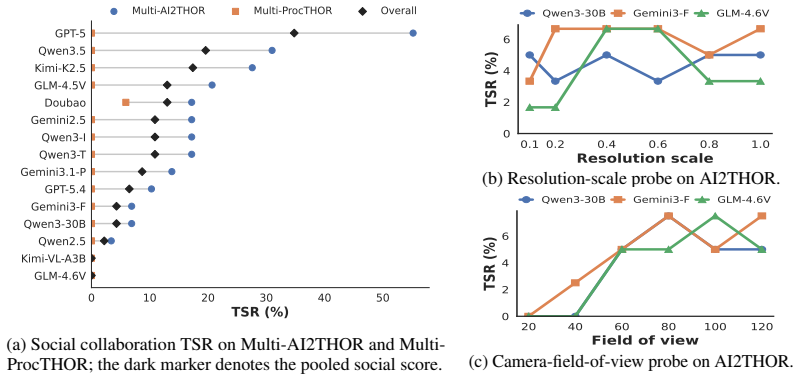
- Performance varies sharply across domains such as household routines and social collaboration, indicating domain-specific weaknesses.
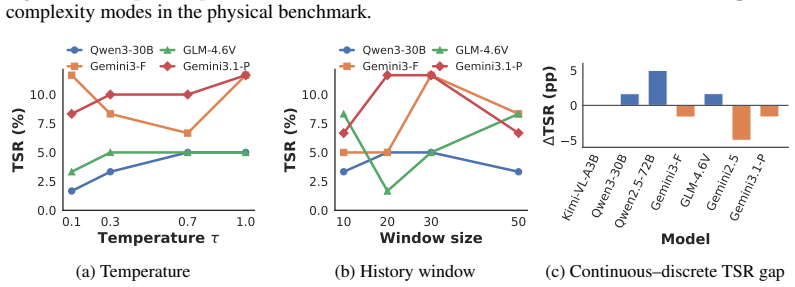
- Active exploration under partial observability and long-horizon planning remain the dominant bottlenecks for current agents.
- A shared protocol across simulators allows direct comparison of agents without simulator-specific tuning.
Where Pith is reading between the lines
- Designers of future agents may need to add explicit spatial memory or mapping modules rather than relying solely on larger models.
- The benchmark could be extended by adding human performance baselines on the same tasks to quantify the remaining gap.
- Because the action interface is text-only, improvements in language-to-action grounding could raise scores without changing the visual pipeline.
Load-bearing premise
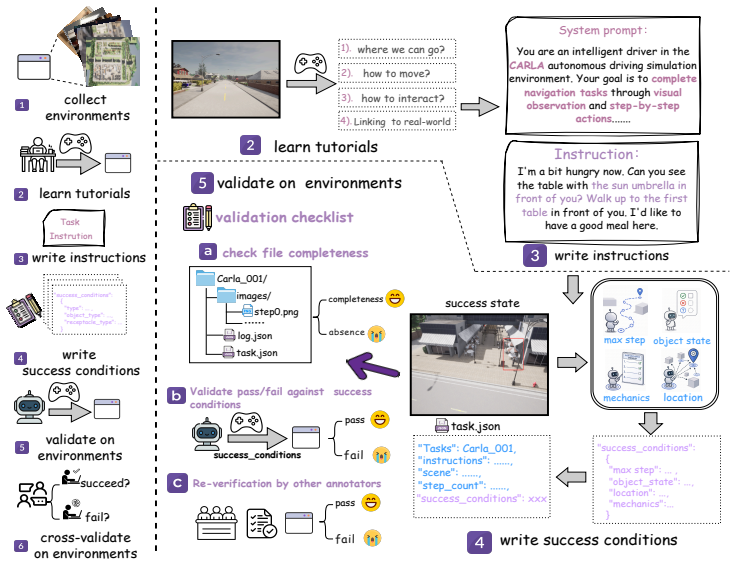
The 760 tasks, reference trajectories, and verifiers across the eight simulators accurately and representatively measure interactive spatial understanding needed for real-world tasks.
What would settle it
An agent that achieves greater than 50 percent average task success rate on the full set of 760 tasks while following the same vision-only and text-action rules would show the reported performance ceiling is not fundamental.
Figures





read the original abstract
Spatial reasoning is a foundational capability for multimodal large language models (MLLMs) to perceive and operate within the physical world. However, existing benchmarks predominantly rely on passive evaluation (e.g., static VQA) or simulator-specific pipelines, failing to assess general interactive spatial understanding. We introduce SpatialWorld, a unified benchmark designed specifically for evaluating the interactive spatial understanding of multimodal agents in complex real-world tasks. Integrating eight heterogeneous simulation backends under a shared, simulator-agnostic protocol, SpatialWorld features 760 human-annotated tasks across diverse domains (e.g., household routines, travel, social collaboration). Agents must solve tasks under vision-only partial observability, actively gathering egocentric visual evidence and expressing decisions via a unified, text-based action interface native to MLLMs. For reliable evaluation, each task includes a human-validated initial state, a reference trajectory, and a terminal-state verifier. Evaluating 15 advanced agents reveals that robust spatial task solving remains challenging: the strongest model, GPT-5, achieves an average task success rate (TSR) of only 17.4%, while the leading open-source model, Qwen-3.5, reaches 14.1%. Further analysis exposes a clear mismatch between task success and execution efficiency, alongside substantial domain-specific performance variations. These bottlenecks in active exploration and long-horizon planning position SpatialWorld as a rigorous testbed for future spatial agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatialWorld, a unified benchmark for interactive spatial reasoning in multimodal agents. It integrates eight heterogeneous simulation backends under a simulator-agnostic protocol, with 760 human-annotated tasks across domains like household routines and social collaboration. Each task includes a human-validated initial state, reference trajectory, and terminal-state verifier. Evaluation of 15 agents shows low performance, with GPT-5 achieving 17.4% average TSR and Qwen-3.5 at 14.1%, exposing mismatches between success and efficiency plus domain variations.
Significance. If the tasks and verifiers hold, the work is significant for providing the first large-scale, cross-simulator test of active spatial understanding under partial observability. The low TSR results and identified bottlenecks in exploration/planning offer concrete evidence of current MLLM limitations, positioning the benchmark as a useful testbed. The shared protocol across backends is a clear strength for generalizability.
major comments (1)
- [Benchmark construction] Benchmark construction (methods section describing task creation and verifiers): The criteria for selecting the 760 tasks, potential annotation biases, and exact implementation of the terminal-state verifiers are not detailed. This is load-bearing for the central TSR claims, as the reported performance gaps (e.g., 17.4% for GPT-5) cannot be interpreted without confirming that the tasks accurately and representatively measure interactive spatial understanding.
minor comments (1)
- [Abstract] The abstract mentions 'eight heterogeneous simulation backends' but does not list them or their domains explicitly; adding this would improve clarity without altering the claims.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of SpatialWorld's significance and for highlighting the need for greater transparency in benchmark construction. We agree that additional detail on task selection, annotation processes, and verifier implementation is warranted to strengthen interpretability of the TSR results and will revise the methods section accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (methods section describing task creation and verifiers): The criteria for selecting the 760 tasks, potential annotation biases, and exact implementation of the terminal-state verifiers are not detailed. This is load-bearing for the central TSR claims, as the reported performance gaps (e.g., 17.4% for GPT-5) cannot be interpreted without confirming that the tasks accurately and representatively measure interactive spatial understanding.
Authors: We acknowledge that the current manuscript provides only high-level descriptions of task creation and verifiers. In the revised version we will insert a new subsection (Methods 3.2) that explicitly details: (1) the multi-stage selection criteria used to curate the 760 tasks across the eight simulators (diversity in domain, horizon length, and required spatial operations, with explicit balancing to avoid over-representation of any single simulator); (2) the annotation protocol, including the number of annotators per task, inter-annotator agreement metrics, and steps taken to reduce selection and confirmation biases (e.g., blind review of initial states and reference trajectories); and (3) the precise implementation of each terminal-state verifier, including the predicate logic, simulator-specific APIs invoked, and example verification traces for representative tasks. These additions will directly support the validity of the reported performance gaps. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces SpatialWorld as an external benchmark with 760 human-annotated tasks, reference trajectories, and verifiers across eight simulators, then reports direct empirical TSR results from evaluating 15 agents (e.g., GPT-5 at 17.4%). No equations, fitted parameters, derivations, or self-citation chains exist that reduce any claim to prior inputs by construction. The work is self-contained as a benchmark construction and evaluation protocol.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing claude opus 4.5.https://www.anthropic.com/news/claude-opus-4-5, 2025
Anthropic. Introducing claude opus 4.5.https://www.anthropic.com/news/claude-opus-4-5, 2025
2025
-
[2]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022
2022
-
[3]
Qwen2.5-vl technical report,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[4]
URLhttps://arxiv.org/abs/2502.13923
-
[5]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[6]
Seed2.0, 2026
ByteDance. Seed2.0, 2026. URLhttps://seed.bytedance.com/en/seed2
2026
-
[7]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
arXiv 2025
-
[8]
Holistic evaluation of multimodal llms on spatial intelligence.arXiv preprint arXiv:2508.13142, 2025
Zhongang Cai, Yubo Wang, Qingping Sun, Ruisi Wang, Chenyang Gu, Wanqi Yin, Zhiqian Lin, Zhitao Yang, Chen Wei, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen, Jiaqi Li, Xiangyu Fan, Hanming Deng, Lewei Lu, Bo Li, Ziwei Liu, Quan Wang, Dahua Lin, and Lei Yang. Holistic evaluation of multimodal llms on spatial intelligence.arXiv preprint arXiv:2508.13142, 2025
arXiv 2025
-
[9]
Spider2-v: How far are multi- modal agents from automating data science and engineering workflows?Advances in Neural Information Processing Systems, 37:107703–107744, 2024
Ruisheng Cao, Fangyu Lei, Haoyuan Wu, Jixuan Chen, Yeqiao Fu, Hongcheng Gao, Xinzhuang Xiong, Hanchong Zhang, Yuchen Mao, Wenjing Hu, et al. Spider2-v: How far are multi- modal agents from automating data science and engineering workflows?Advances in Neural Information Processing Systems, 37:107703–107744, 2024
2024
-
[10]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[11]
Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks.IEEE Transactions on Cognitive and Developmental Systems, 2025
Yaran Chen, Wenbo Cui, Yuanwen Chen, Mining Tan, Xinyao Zhang, Jinrui Liu, Haoran Li, Dongbin Zhao, and He Wang. Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks.IEEE Transactions on Cognitive and Developmental Systems, 2025
2025
-
[12]
EmbodiedEval: Evaluate multimodal LLMs as embodied agents.arXiv preprint arXiv:2501.11858, 2025
Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, and Maosong Sun. EmbodiedEval: Evaluate multimodal LLMs as embodied agents.arXiv preprint arXiv:2501.11858, 2025
arXiv 2025
-
[13]
Gemini 3 pro best for complex tasks and bringing creative concepts to life
Google Deepmind. Gemini 3 pro best for complex tasks and bringing creative concepts to life. https://deepmind.google/models/gemini/pro/, 2025
2025
-
[14]
Proc- thor: Large-scale embodied AI using procedural generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Sal- vador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. Proc- thor: Large-scale embodied AI using procedural generation. In Sanmi Koyejo, S. Mo- hamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Sys...
2022
-
[15]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 12
2017
-
[16]
Palm-e: an embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: an embodied multimodal language model. InProceedings of the 40th International Conference on Machine Learning, pages 8469–8488, 2023
2023
-
[17]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346–355, 2024
2024
-
[18]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM international conference on multimedia, pages 11198–11201, 2024
2024
-
[19]
Vlm-gronav: Robot naviga- tion using physically grounded vision-language models in outdoor environments
Mohamed Elnoor, Kasun Weerakoon, Gershom Seneviratne, Ruiqi Xian, Tianrui Guan, Mo- hamed Khalid M Jaffar, Vignesh Rajagopal, and Dinesh Manocha. Vlm-gronav: Robot naviga- tion using physically grounded vision-language models in outdoor environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 2391–2398. IEEE, 2025
2025
-
[20]
Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343–18362, 2022
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343–18362, 2022
2022
-
[21]
Videoagent: A memory-augmented multimodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024
2024
-
[22]
Chen Gao, Baining Zhao, Weichen Zhang, Jinzhu Mao, Jun Zhang, Zhiheng Zheng, Fan- hang Man, Jianjie Fang, Zile Zhou, Jinqiang Cui, Xinlei Chen, and Yong Li. EmbodiedCity: A benchmark platform for embodied agent in real-world city environment.arXiv preprint arXiv:2410.09604, 2024
arXiv 2024
-
[23]
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, and Mohammad Akbari. Spatial reasoning with vision-language models in ego-centric multi-view scenes.arXiv preprint arXiv:2509.06266, 2025
arXiv 2025
-
[24]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
Pith/arXiv arXiv 2025
-
[25]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models.arXiv preprint arXiv:2401.13919, 2024
Pith/arXiv arXiv 2024
-
[26]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281–14290, 2024
2024
-
[27]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
Pith/arXiv arXiv 2025
-
[28]
3d concept learning and reasoning from multi-view images
Yining Hong, Chunru Lin, Yilun Du, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. 3d concept learning and reasoning from multi-view images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9202–9212, 2023
2023
-
[29]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019. 13
2019
-
[30]
OmniSpatial: Towards comprehensive spatial reasoning benchmark for vision language models
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. OmniSpatial: Towards comprehensive spatial reasoning benchmark for vision language models. InInternational Conference on Learning Representations, 2026
2026
-
[31]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
2017
-
[32]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
2024
-
[33]
Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
Pith/arXiv arXiv 2017
-
[34]
Zhiqian Lan, Yuxuan Jiang, Ruiqi Wang, Xuanbing Xie, Rongkui Zhang, Yicheng Zhu, Peihang Li, Tianshuo Yang, Tianxing Chen, Haoyu Gao, et al. Autobio: A simulation and benchmark for robotic automation in digital biology laboratory.arXiv preprint arXiv:2505.14030, 2025
arXiv 2025
-
[35]
Chengshu Li, Fei Xia, Roberto Martín-Martín, Michael Lingelbach, Sanjana Srivastava, Bokui Shen, Kent Vainio, Cem Gokmen, Gokul Dharan, Tanish Jain, et al. igibson 2.0: Object-centric simulation for robot learning of everyday household tasks.arXiv preprint arXiv:2108.03272, 2021
arXiv 2021
-
[36]
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Li Fei-Fei, Jiayuan Mao, and Jiajun Wu. Embodied agent interface: Benchmarking LLMs for embodied decision making.arXiv preprint arXiv:2410.07166, 2024
arXiv 2024
-
[37]
Mingsheng Li, Xin Chen, Chi Zhang, Sijin Chen, Hongyuan Zhu, Fukun Yin, Gang Yu, and Tao Chen. M3dbench: Let’s instruct large models with multi-modal 3d prompts.arXiv preprint arXiv:2312.10763, 2023
arXiv 2023
-
[38]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022
2022
-
[39]
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419, 2025
Pith/arXiv arXiv 2025
-
[40]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689–26699, 2024
2024
-
[41]
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, Chenming Zhu, Yiman Xie, Yilin Long, Wenbo Hu, Dahua Lin, Tai Wang, and Jiangmiao Pang. MMSI-Video-Bench: A holistic benchmark for video-based spatial intelligence.arXiv preprint arXiv:2512.10863, 2025
arXiv 2025
-
[42]
Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene understanding
JingLi Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, and Jiangmiao Pang. Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene understanding. arXiv preprint arXiv:2507.07984, 2025
arXiv 2025
-
[43]
Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
2023
-
[44]
Llava-plus: Learning to use tools for creating multimodal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multimodal agents. InEuropean conference on computer vision, pages 126–142. Springer, 2024. 14
2024
-
[45]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
arXiv 2025
-
[46]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025
arXiv 2025
-
[47]
3DSRBench: A comprehensive 3D spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3DSRBench: A comprehensive 3D spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025
2025
-
[48]
Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
arXiv 2022
-
[49]
Introducing gpt-5.2.https://openai.com/index/introducing-gpt-5-2/, 2025
OpenAI. Introducing gpt-5.2.https://openai.com/index/introducing-gpt-5-2/, 2025
2025
-
[50]
Gpt -5.4 thinking system card, 2026
OpenAI. Gpt -5.4 thinking system card, 2026. URL https://openai.com/index/ gpt-5-4-thinking-system-card/
2026
-
[51]
Virtualhome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. Virtualhome: Simulating household activities via programs. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 8494–8502. Computer Vision Foundation / IEEE Computer Society, 2018. doi: 1...
-
[52]
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
Pith/arXiv arXiv 2021
-
[53]
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
Pith/arXiv arXiv 2024
-
[54]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019
2019
-
[55]
ALFRED: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mot- taghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10740–10749, 2020
2020
-
[56]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[57]
Tin Stribor Sohn, Maximilian Dillitzer, Jason J. Corso, and Eric Sax. Embodied4c: Measuring what matters for embodied vision-language navigation, 2025. URL https://arxiv.org/ abs/2512.18028
arXiv 2025
-
[58]
Gemini 3 pro: the frontier of vision ai, 2025b
Gemini Team. Gemini 3 pro: the frontier of vision ai, 2025b. URL https://blog.google/ technology/developers/gemini-3-pro-vision
-
[59]
Gemini 3 flash, 2025b
Gemini Team. Gemini 3 flash, 2025b. URL https://deepmind.google/models/gemini/ flash/. 15
-
[60]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[61]
Gemini 2.5 Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https://arxiv.org/abs/ 2507.06261
Pith/arXiv arXiv 2025
-
[62]
Glm-4.6v: Open source multimodal models with native tool use, 2025a
GLM-V Team. Glm-4.6v: Open source multimodal models with native tool use, 2025a. URL https://z.ai/blog/glm-4.6v
-
[63]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Pith/arXiv arXiv 2025
-
[64]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Pith/arXiv arXiv 2026
-
[65]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[66]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[67]
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
Pith/arXiv arXiv 2025
-
[68]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[69]
Mobile-agent: Autonomous multi-modal mobile device agent with visual perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024
Pith/arXiv arXiv 2024
-
[70]
Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving.arXiv preprint arXiv:2312.09245, 2023
arXiv 2023
-
[71]
SITE: Towards spatial intelligence thorough evaluation
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. SITE: Towards spatial intelligence thorough evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9058–9069, 2025
2025
-
[72]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
arXiv 2025
-
[73]
Haoning Wu, Xiao Huang, Yaohui Chen, Ya Zhang, Yanfeng Wang, and Weidi Xie. Spa- tialScore: Towards unified evaluation for multimodal spatial understanding.arXiv preprint arXiv:2505.17012, 2025
Pith/arXiv arXiv 2025
-
[74]
Gibson env: Real-world perception for embodied agents
Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson env: Real-world perception for embodied agents. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9068–9079, 2018
2018
-
[75]
Sapien: A simulated part-based interactive environ- ment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environ- ment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
-
[76]
Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024
Junlin Xie, Zhihong Chen, Ruifei Zhang, Xiang Wan, and Guanbin Li. Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024. 16
arXiv 2024
-
[77]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[78]
Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, Gege Qi, and Yunjian Zhang. Spatial- Bench: Benchmarking multimodal large language models for spatial cognition.arXiv preprint arXiv:2511.21471, 2025
Pith/arXiv arXiv 2025
-
[79]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer, 2024
2024
-
[80]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.