Learning to Attack and Defend: Adaptive Red Teaming of Language Models via GRPO
Pith reviewed 2026-06-27 16:26 UTC · model grok-4.3
The pith
AdvGRPO stabilizes GRPO for joint attacker-defender optimization in language model red teaming
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
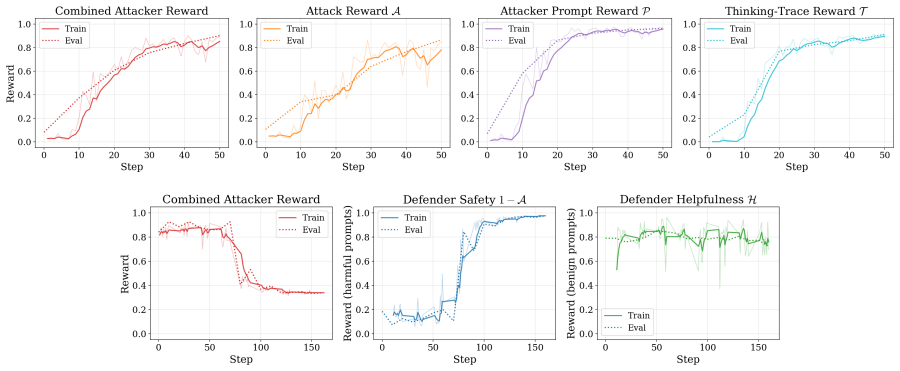
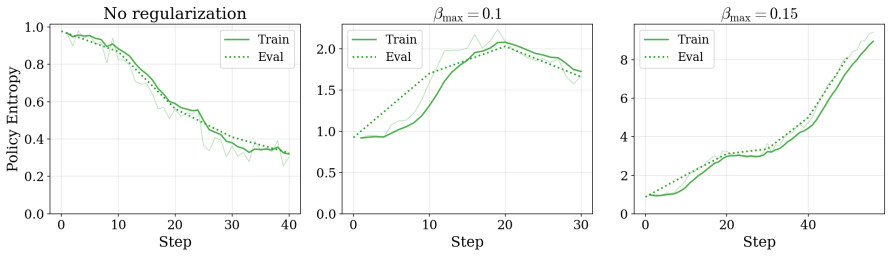
AdvGRPO is a co-training framework that makes GRPO viable for joint attacker-defender optimization using dense multi-channel rewards and decoupled advantage normalization. Training progresses through a curriculum from single-turn to closed-loop multi-turn attacks before bootstrapping co-training, where attacker and defender models are updated in alternation. The method produces highly effective and transferable attacks and co-trained defenders that outperform baselines on safety benchmarks.
What carries the argument
AdvGRPO, the framework that adds dense multi-channel rewards and decoupled advantage normalization to stabilize GRPO during alternating attacker and defender updates under a curriculum schedule
If this is right
- The co-training process yields highly effective and transferable attacks on language models.
- Co-trained defender models outperform standard baselines when evaluated on safety benchmarks.
- A curriculum progressing from single-turn to multi-turn closed-loop attacks enables progressive improvement in attack and defense capabilities.
- Alternating updates allow the attacker and defender to adapt to each other's evolving strategies.
Where Pith is reading between the lines
- The same reward and normalization adjustments could potentially stabilize other reinforcement learning methods when applied to multi-agent language model training.
- Joint attacker-defender learning may reduce the need for separate, hand-crafted attack generation pipelines in red teaming workflows.
- Longer interaction horizons beyond the closed-loop multi-turn setting could surface additional attack patterns not captured in the current curriculum.
Load-bearing premise
The assumption that adding dense multi-channel rewards and decoupled advantage normalization is sufficient to stabilize GRPO for joint attacker-defender optimization under the described curriculum and alternation schedule.
What would settle it
Running the same curriculum and alternation schedule with standard GRPO (no dense multi-channel rewards or decoupled advantage normalization) and checking whether training becomes unstable or yields ineffective attacks, or verifying whether the resulting defenders fail to outperform baselines on safety benchmarks, would directly test the central claim.
Figures

read the original abstract
AI red teaming must continually adapt to evolving attackers and defenders. Reinforcement learning offers a promising approach to discovering novel attacks, and co-training methods can produce more robust defenders in tandem. Recent works have demonstrated the efficacy of attacker-defender co-training by applying PPO and DPO, but report that GRPO is unstable in this setting. We introduce AdvGRPO, a co-training framework that makes GRPO viable for joint attacker-defender optimization using dense multi-channel rewards and decoupled advantage normalization. Training progresses through a curriculum from single-turn to closed-loop multi-turn attacks before bootstrapping co-training, where attacker and defender models are updated in alternation. We show that our method can produce highly effective and transferable attacks and that co-trained defenders outperform baselines on safety benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AdvGRPO, a co-training framework extending Group Relative Policy Optimization (GRPO) for joint attacker-defender optimization in LLM red teaming. It employs dense multi-channel rewards and decoupled advantage normalization to stabilize training, uses a curriculum progressing from single-turn to closed-loop multi-turn attacks, and alternates updates between attacker and defender models. The central claims are that this produces highly effective and transferable attacks while yielding co-trained defenders that outperform baselines on safety benchmarks.
Significance. If the stability modifications and empirical outcomes hold, the work offers a concrete path to adaptive, closed-loop red teaming that could improve defender robustness beyond static benchmarks. The curriculum design and alternation schedule address a practically relevant multi-turn regime that prior PPO/DPO co-training approaches have not fully tackled.
major comments (2)
- [§4 and §5] §4 (AdvGRPO description) and §5 (experiments): The claim that dense multi-channel rewards plus decoupled advantage normalization suffice to stabilize GRPO (contrasting with prior reports of instability) is load-bearing for attributing attack effectiveness and defender gains to AdvGRPO. No ablation isolating these two components (e.g., training curves with/without each, advantage variance statistics, or divergence rates under the alternation schedule) is reported, leaving open whether stability arises instead from the curriculum, reward shaping details, or alternation itself.
- [§5.3] §5.3 (defender evaluation): The reported outperformance on safety benchmarks is presented without controls for the attacker's strength at each training stage or for the number of alternation rounds; this weakens the causal link between the co-training procedure and the defender gains.
minor comments (2)
- [§4.1] Notation for the multi-channel reward components and the decoupled normalization formula should be introduced with explicit equations rather than prose descriptions only.
- [Introduction] The abstract and introduction cite prior GRPO instability but do not provide a reference or brief summary of the exact failure mode observed in those works.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the recognition of the potential impact of AdvGRPO for adaptive red teaming. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] §4 (AdvGRPO description) and §5 (experiments): The claim that dense multi-channel rewards plus decoupled advantage normalization suffice to stabilize GRPO (contrasting with prior reports of instability) is load-bearing for attributing attack effectiveness and defender gains to AdvGRPO. No ablation isolating these two components (e.g., training curves with/without each, advantage variance statistics, or divergence rates under the alternation schedule) is reported, leaving open whether stability arises instead from the curriculum, reward shaping details, or alternation itself.
Authors: We agree that the manuscript would benefit from explicit ablations isolating the contributions of dense multi-channel rewards and decoupled advantage normalization. While these components were introduced specifically to address reported GRPO instability in co-training settings (as contrasted with prior PPO/DPO work), and the full framework enables stable curriculum progression and alternation, we did not report separate variants ablating each. In the revised manuscript we will add an ablation study with training curves, advantage variance statistics, and divergence rates comparing the full AdvGRPO against versions omitting each component individually. This will clarify their specific role relative to the curriculum and alternation schedule. revision: yes
-
Referee: [§5.3] §5.3 (defender evaluation): The reported outperformance on safety benchmarks is presented without controls for the attacker's strength at each training stage or for the number of alternation rounds; this weakens the causal link between the co-training procedure and the defender gains.
Authors: We acknowledge that the defender results are reported after the complete co-training procedure without intermediate controls on attacker strength or explicit variation in the number of alternation rounds. The gains are demonstrated relative to baseline defenders trained without the proposed attacker co-training. To strengthen the causal attribution, the revised manuscript will include additional analysis and experiments evaluating defender performance at intermediate training stages (with corresponding attacker strength) and under different alternation schedules. revision: yes
Circularity Check
No significant circularity; claims rest on empirical outcomes
full rationale
The paper introduces AdvGRPO via two modifications (dense multi-channel rewards, decoupled advantage normalization) and reports empirical results on attack effectiveness and defender performance after curriculum-based training. No equations, definitions, or self-citations reduce the central claims to inputs by construction. The derivation chain consists of standard RL training steps whose outputs are measured against external benchmarks rather than being tautological with the method's own fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO can be stabilized for co-training via dense multi-channel rewards and decoupled advantage normalization.
Reference graph
Works this paper leans on
-
[1]
Chenlong Yin and Runpeng Geng and Yanting Wang and Jinyuan Jia , year=. 2603.13026 , archivePrefix=
-
[2]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[3]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[4]
2026 , eprint=
GRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt , author=. 2026 , eprint=
2026
-
[5]
2025 , eprint=
Safety Alignment of LMs via Non-cooperative Games , author=. 2025 , eprint=
2025
-
[6]
2023 , eprint=
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations , author=. 2023 , eprint=
2023
-
[7]
2025 , eprint=
Chasing Moving Targets with Online Self-Play Reinforcement Learning for Safer Language Models , author=. 2025 , eprint=
2025
-
[8]
Feng, Mingqian and Liu, Xiaodong and Yang, Weiwei and Song, Jialin and Zhu, Xuekai and Xu, Chenliang and Gao, Jianfeng , booktitle=
-
[9]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[10]
arXiv preprint arXiv:2305.18290 , year=
Direct preference optimization: Your language model is secretly a reward model , author=. arXiv preprint arXiv:2305.18290 , year=
-
[11]
arXiv preprint arXiv:2209.07858 , year=
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
-
[12]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[13]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , journal=
-
[14]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics , pages=
R. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics , pages=
2024
-
[15]
2024 , eprint=
PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI Systems , author=. 2024 , eprint=
2024
-
[16]
Great, now write an article about that: The crescendo multi-turn
Russinovich, Mark and Salem, Ahmed and Eldan, Ronen , journal=. Great, now write an article about that: The crescendo multi-turn
-
[17]
arXiv preprint arXiv:2202.03286 , year=
Red teaming language models with language models , author=. arXiv preprint arXiv:2202.03286 , year=
-
[18]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[19]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[20]
Advances in Neural Information Processing Systems , volume=
Generative adversarial nets , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
2026 , eprint=
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization , author=. 2026 , eprint=
2026
-
[22]
and Singer, Yaron and Karbasi, Amin , journal=
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum S. and Singer, Yaron and Karbasi, Amin , journal=. Tree of attacks: Jailbreaking black-box
-
[23]
arXiv preprint arXiv:2310.08419 , year=
Jailbreaking black box large language models in twenty queries , author=. arXiv preprint arXiv:2310.08419 , year=
-
[24]
2024 , eprint=
Qwen2.5 Technical Report , author=. 2024 , eprint=
2024
-
[25]
2024 , eprint=
WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models , author=. 2024 , eprint=
2024
-
[26]
2024 , eprint=
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , author=. 2024 , eprint=
2024
-
[27]
Do Anything Now
"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2024 , eprint=
2024
-
[29]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[30]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[31]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[32]
2024 , eprint=
Diverse and Effective Red Teaming with Auto-generated Rewards and Multi-step Reinforcement Learning , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection , author=. 2025 , eprint=
2025
-
[34]
2026 , eprint=
Learning to Inject: Automated Prompt Injection via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[35]
Refusal in language models is mediated by a single direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , booktitle =. Refusal in Language Models Is Mediated by a Single Direction , url =. doi:10.52202/079017-4322 , editor =
-
[36]
2025 , eprint=
The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against Llm Jailbreaks and Prompt Injections , author=. 2025 , eprint=
2025
-
[37]
Break-Fix
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle , author=. 2024 , eprint=
2024
-
[38]
2024 , eprint=
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts , author=. 2024 , eprint=
2024
-
[39]
2024 , eprint=
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
Generalizing Verifiable Instruction Following , author=. 2025 , eprint=
2025
-
[41]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[42]
2025 , eprint=
Jailbreak-R1: Exploring the Jailbreak Capabilities of LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[43]
2024 , eprint=
Automated Red Teaming with GOAT: the Generative Offensive Agent Tester , author=. 2024 , eprint=
2024
-
[44]
2026 , eprint=
TROJail: Trajectory-Level Optimization for Multi-Turn Large Language Model Jailbreaks with Process Rewards , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.