iMaC: Translating Actions into Motion and Contact Images for Embodied World Models
Pith reviewed 2026-06-27 16:14 UTC · model grok-4.3
The pith
Treating raw visual images as action commands improves prediction accuracy and task success in embodied world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
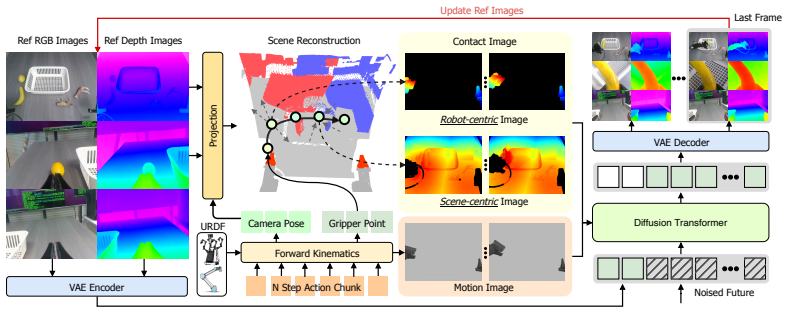
iMac formulates continuous visual manipulation as image-based action tokens, which inherently encapsulate spatial motion intentions, interactive geometric constraints and subtle physical dynamics. The dual-branch architecture consists of an image-action encoder that compresses target-driven visual images into compact action embeddings and a dynamic world predictor that learns environment transition rules conditioned on these image actions to achieve high-fidelity future state prediction and closed-loop embodied control.
What carries the argument
Image-based action tokens produced by the encoder that serve as the input representation for the dynamic world predictor.
If this is right
- Higher prediction accuracy than vector-based action control baselines.
- Higher task success rates in both simulated and real robotic scenarios.
- Better cross-scene generalization for the same model.
- Control that works for different robot bodies without manually defined action spaces.
Where Pith is reading between the lines
- The image representation might allow direct use of visual goal images from human demonstrations without extra translation steps.
- It could reduce the engineering effort needed when moving a policy from one robot hardware to another.
- Future extensions might combine the approach with large vision-language models to specify tasks purely through pictures.
Load-bearing premise
Target images contain enough information to be compressed into action embeddings that preserve all required details about movement and physical interaction for accurate control.
What would settle it
A side-by-side test on a public manipulation benchmark where the image-action method shows no improvement or lower success rates than vector baselines in new scenes would falsify the central claim.
Figures




read the original abstract
Embodied world models have emerged as a pivotal paradigm for visual robotic decision-making and interactive environment simulation. However, conventional embodied frameworks rely on low-dimensional structured action vectors (e.g., joint angles and end-effector poses), which suffer from limited expressive capacity, poor generalization across diverse embodiments, and unnatural dynamic modeling for complex physical interactions. To address these limitations, this paper proposesiMac (Image as Action Control), a novel unified control paradigm that treats raw visual images as native action representations for embodied world models. Departing from traditional explicit kinematic action encoding, iMac formulates continuous visual manipulation as image-based action tokens, which inherently encapsulate spatial motion intentions, interactive geometric constraints and subtle physical dynamics. We construct a dual-branch embodied architecture consisting of an image-action encoder and a dynamic world predictor: the encoder compresses target-driven visual images into compact action embeddings, while the predictor learns environment transition rules conditioned on image actions to achieve high-fidelity future state prediction and closed-loop embodied control. Extensive experiments are conducted on public embodied manipulation benchmarks and real-world robotic scenarios. The results demonstrate that iMac outperforms vector-based action control baselines in prediction accuracy, task success rate and cross-scene generalization ability. Moreover, our image-action design eliminates the reliance on manually defined action spaces, realizing flexible and universal control for heterogeneous embodied agents. This work provides an innovative visual-action perspective for embodied world models, offering a simple yet effective paradigm for scalable robotic perception and manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes iMaC (Image as Action Control), a unified control paradigm for embodied world models that represents actions via raw visual images rather than low-dimensional structured vectors such as joint angles or end-effector poses. It introduces a dual-branch architecture with an image-action encoder that compresses target-driven visual images into compact embeddings and a dynamic world predictor that learns environment transitions conditioned on these image actions. The manuscript claims that this formulation outperforms vector-based baselines in prediction accuracy, task success rate, and cross-scene generalization on public embodied manipulation benchmarks and real-world robotic scenarios, while eliminating reliance on manually defined action spaces for flexible control across heterogeneous agents.
Significance. If the empirical claims are substantiated with rigorous evidence, the image-as-action formulation could provide a more expressive and generalizable alternative to conventional action encodings, potentially simplifying control for diverse embodiments and better capturing kinematic and dynamic constraints in manipulation tasks.
major comments (1)
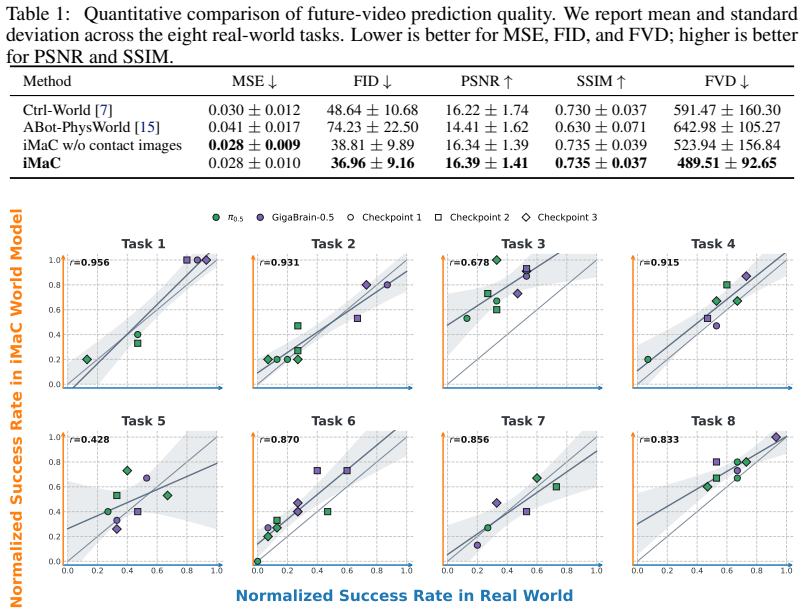
- [Abstract] Abstract: the central claim that 'the results demonstrate that iMac outperforms vector-based action control baselines in prediction accuracy, task success rate and cross-scene generalization ability' is asserted without any quantitative metrics, error bars, dataset details, ablation studies, or references to specific tables/figures/sections, rendering the primary empirical contribution unevaluable from the provided text.
minor comments (1)
- [Abstract] Abstract: typographical error in 'proposesiMac' (missing space before 'iMaC').
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting this issue with the abstract. We agree that the abstract as written does not sufficiently substantiate the central empirical claim and will revise it accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the results demonstrate that iMac outperforms vector-based action control baselines in prediction accuracy, task success rate and cross-scene generalization ability' is asserted without any quantitative metrics, error bars, dataset details, ablation studies, or references to specific tables/figures/sections, rendering the primary empirical contribution unevaluable from the provided text.
Authors: We agree that the abstract should provide concrete quantitative support and explicit pointers to the experimental results. In the revised manuscript we will expand the final sentence of the abstract to include key metrics (e.g., average prediction error reduction, task success rates on the evaluated benchmarks) together with references to the relevant tables and figures. This change will make the primary empirical contribution directly evaluable from the abstract while preserving its concise nature. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and text contain no equations, derivations, or self-citations. The iMaC formulation is introduced as a design choice (image-based action tokens) whose claimed benefits are supported by experimental comparisons rather than any reduction of predictions to fitted inputs or prior self-referential results. No load-bearing step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Pith/arXiv arXiv 1912
-
[2]
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba. Mastering atari with discrete world models. arXiv preprint arXiv:2010.02193, 2020
Pith/arXiv arXiv 2010
-
[3]
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[4]
M. Yang, Y . Du, K. Ghasemipour, J. Tompson, D. Schuurmans, and P. Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
Pith/arXiv arXiv 2023
-
[5]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning composi- tional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
Pith/arXiv arXiv 2024
-
[6]
Q. Garrido, T. Nagarajan, B. Terver, N. Ballas, Y . LeCun, and M. Rabbat. Learning latent action world models in the wild.arXiv preprint arXiv:2601.05230, 2026
arXiv 2026
-
[7]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
Pith/arXiv arXiv 2025
-
[8]
Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
Gemini Robotics Team. Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
arXiv 2025
-
[9]
Y . Wang, R. Syed, F. Wu, M. Zhang, A. Onol, J. Barreiros, H. Nayyeri, T. Dear, H. Zhang, and Y . Li. Interactive world simulator for robot policy training and evaluation.arXiv preprint arXiv:2603.08546, 2026
arXiv 2026
-
[10]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[11]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InNeurIPS, volume 30, pages 5998–6008, 2017
2017
-
[12]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, pages 4195– 4205, October 2023
2023
-
[13]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018
2018
- [14]
-
[15]
Y . Chen, R. Chen, D. Huo, Y . Yang, D. Qi, H. Liu, T. Lin, S. Zeng, J. Xiao, X. Chang, et al. Abot-physworld: Interactive world foundation model for robotic manipulation with physics alignment.arXiv preprint arXiv:2603.23376, 2026
arXiv 2026
-
[16]
H. Zhen, Z. Gao, Q. Sun, Y . Zhao, Y . Yang, Y . Du, T.-H. Wang, Y .-L. Qiao, and C. Gan. Action images: End-to-end policy learning via multiview video generation.arXiv preprint arXiv:2604.06168, 2026
Pith/arXiv arXiv 2026
-
[17]
L. Liu, X. Wang, G. Zhao, K. Li, W. Qin, J. Qiu, Z. Zhu, G. Huang, and Z. Su. Robotrans- fer: Geometry-consistent video diffusion for robotic visual policy transfer.arXiv preprint arXiv:2505.23171, 2025. 9
arXiv 2025
-
[18]
Z. Tong, D. Chen, S. Hu, H. Fan, L. Chen, G. Ren, H. Tang, H. Dong, and L. Shao. Fidelity- aware data composition for robust robot generalization.arXiv preprint arXiv:2509.24797, 2025
arXiv 2025
-
[19]
Z. Qian, X. Chi, Y . Li, S. Wang, Z. Qin, X. Ju, S. Han, and S. Zhang. Wristworld: Generating wrist-views via 4d world models for robotic manipulation.arXiv preprint arXiv:2510.07313, 2025
arXiv 2025
-
[20]
H. Li, I. Zhang, R. Ouyang, X. Wang, Z. Zhu, Z. Yang, Z. Zhang, B. Wang, C. Ni, W. Qin, et al. Mimicdreamer: Aligning human and robot demonstrations for scalable vla training. arXiv preprint arXiv:2509.22199, 2025
arXiv 2025
-
[21]
Y . Zhao, H. Fan, D. Chen, S. Chen, L. Chen, X. Li, G. Ren, and H. Dong. Real2edit2real: Generating robotic demonstrations via a 3d control interface. InCVPR, 2026
2026
-
[22]
G. Team, A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, J. Zhu, K. Li, M. Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861, 2025
arXiv 2025
-
[23]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.NeurIPS, 2023
2023
-
[24]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[25]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[26]
J. Xiao, Y . Yang, X. Chang, R. Chen, F. Xiong, M. Xu, W.-S. Zheng, and Q. Zhang. World- env: Leveraging world model as a virtual environment for vla post-training.arXiv preprint arXiv:2509.24948, 2025
Pith/arXiv arXiv 2025
-
[27]
H. Kress-Gazit, K. Hashimoto, N. Kuppuswamy, P. Shah, P. Horgan, G. Richardson, S. Feng, and B. Burchfiel. Robot learning as an empirical science: Best practices for policy evaluation. arXiv preprint arXiv:2409.09491, 2024
arXiv 2024
- [28]
-
[29]
Z. Zhou, P. Atreya, Y . L. Tan, K. Pertsch, and S. Levine. Autoeval: Autonomous evaluation of generalist robot manipulation policies in the real world.arXiv preprint arXiv:2503.24278, 2025
arXiv 2025
-
[30]
Y . R. Wang, C. Ung, G. Tannert, J. Duan, J. Li, A. Le, R. Oswal, M. Grotz, W. Pumacay, Y . Deng, et al. Roboeval: Where robotic manipulation meets structured and scalable evaluation. arXiv preprint arXiv:2507.00435, 2025
Pith/arXiv arXiv 2025
-
[31]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In IROS, pages 5026–5033. IEEE, 2012
2012
-
[32]
Y . Zhu, J. Wong, A. Mandlekar, R. Martin-Martin, A. Joshi, S. Nasiriany, and Y . Zhu. ro- bosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020
Pith/arXiv arXiv 2009
-
[33]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InCVPR, pages 11097–11107, 2020. 10
2020
-
[34]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. InNeurIPS, 2023
2023
-
[35]
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox. The colosseum: A bench- mark for evaluating generalization for robotic manipulation.arXiv preprint arXiv:2402.08191, 2024
arXiv 2024
-
[36]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
- [37]
-
[38]
A. Badithela, D. Snyder, L. Zha, J. Mikhail, M. O’Kelly, A. Dixit, and A. Majumdar. Reliable and scalable robot policy evaluation with imperfect simulators.arXiv preprint arXiv:2510.04354, 2025
arXiv 2025
- [39]
-
[40]
Meyer, F
L. Meyer, F. Erich, Y . Yoshiyasu, M. Stamminger, N. Ando, and Y . Domae. Pegasus: Phys- ically enhanced gaussian splatting simulation system for 6dof object pose dataset generation. InIROS, pages 10710–10715. IEEE, 2024
2024
-
[41]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
arXiv 2025
-
[42]
A. Majumdar, M. Sharma, D. Kalashnikov, S. Singh, P. Sermanet, and V . Sindhwani. Predictive red teaming: Breaking policies without breaking robots.arXiv preprint arXiv:2502.06575, 2025
arXiv 2025
-
[43]
Team Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[44]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[45]
V . Gabeur, S. Long, S. Peng, P. V oigtlaender, S. Sun, Y . Bao, K. Truong, Z. Wang, W. Zhou, J. T. Barron, et al. Image generators are generalist vision learners.arXiv preprint arXiv:2604.20329, 2026
Pith/arXiv arXiv 2026
-
[46]
Huang, Z
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.NeurIPS, 38:167283–167308, 2026
2026
-
[47]
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park. One-step diffusion with distribution matching distillation. InCVPR, 2024
2024
-
[48]
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and B. Freeman. Improved distribution matching distillation for fast image synthesis. InNeurIPS, 2024
2024
-
[49]
M. Zhou, H. Zheng, Z. Wang, M. Yin, and H. Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InICML, 2024
2024
-
[50]
M. Zhou, H. Zheng, Y . Gu, Z. Wang, and H. Huang. Adversarial score identity distillation: Rapidly surpassing the teacher in one step. InICLR, 2025. 11
2025
-
[51]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets. InNeurIPS, 2014
2014
-
[52]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π 0.5: A vision-language-action model with open-world gener- alization. InCoRL, 2025
2025
-
[53]
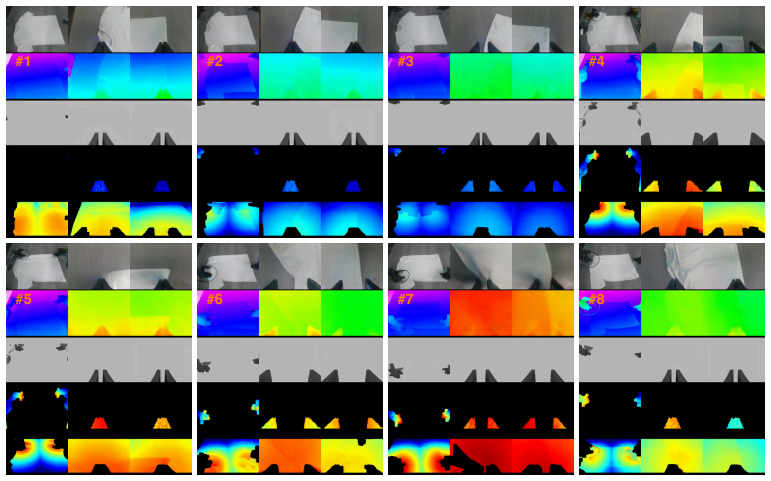
GigaBrain Team, B. Wang, B. Li, C. Ni, G. Huang, G. Zhao, H. Li, J. Li, J. Lv, J. Liu, et al. Gigabrain-0.5 m*: A vla that learns from world model-based reinforcement learning.arXiv preprint arXiv:2602.12099, 2026. Appendix A Task Suite This appendix provides additional materials for the eight real-world manipulation tasks used in Sec. 4.1. Fig. 4 visuali...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.