Mitigating Manifold Departure: Uncertainty-Aware Subspace Rectification for Trustworthy MLLM Decoding
Pith reviewed 2026-06-28 17:49 UTC · model grok-4.3
The pith
MGAP constructs an SVD language-prior subspace and uses a consistency gate to attenuate only inconsistent components during MLLM decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that hallucinations arise from unselective suppression of language priors and that a geometry-aware method can correct them by building a language-prior subspace via SVD on blind hidden states, projecting multimodal hidden states onto it, and using a consistency-aware gate to attenuate solely the projected inconsistent component, thereby producing a subspace-selective update that largely preserves the orthogonal semantic components.
What carries the argument
Manifold-Guided Adaptive Projection (MGAP), a training-free decoding procedure that derives a language-prior subspace via SVD and applies a consistency-aware gate for selective attenuation of multimodal hidden states.
If this is right
- MGAP yields stronger hallucination suppression than prior decoding baselines on POPE and CHAIR.
- The subspace-selective update largely preserves orthogonal semantic components.
- Performance degradation from manifold departure is avoided while coherence is maintained.
- The method remains training-free and operates at decoding time.
Where Pith is reading between the lines
- The same SVD-subspace and gated-projection pattern could be tested on other evidence-prior conflicts such as factual inconsistency in text-only generation.
- Replacing the fixed SVD subspace with an incrementally updated one might further reduce residual inconsistencies across long generations.
- The approach suggests a general template for evidence-aware rectification that could be combined with post-training alignment techniques.
Load-bearing premise
The language-prior subspace obtained via SVD on blind hidden states accurately isolates the harmful component of language priors, and the consistency-aware gate reliably attenuates only the inconsistent part.
What would settle it
A controlled run on the POPE or CHAIR benchmarks in which MGAP produces either higher hallucination rates or lower coherence scores than the strongest prior decoding baseline would falsify the central claim.
Figures


read the original abstract
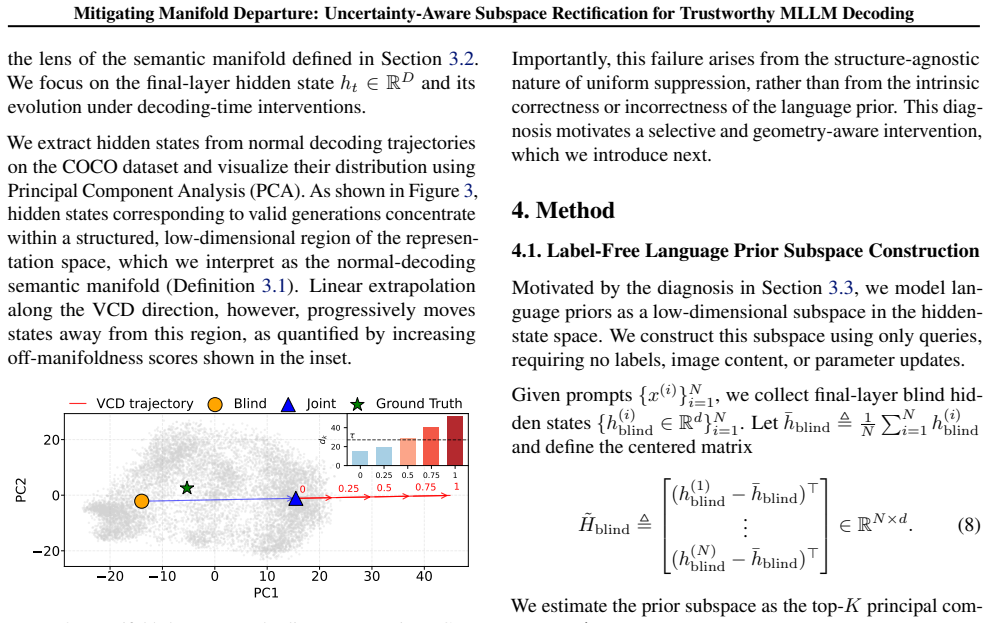
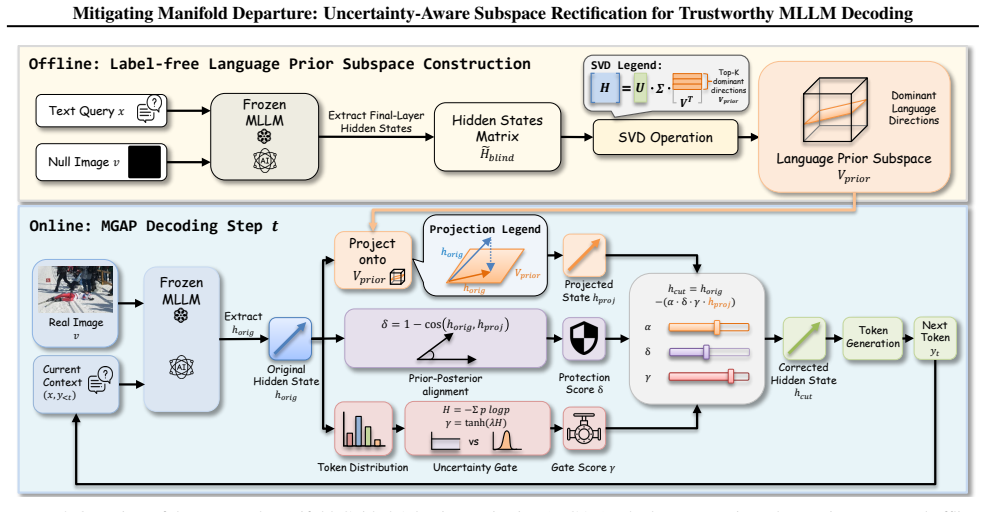
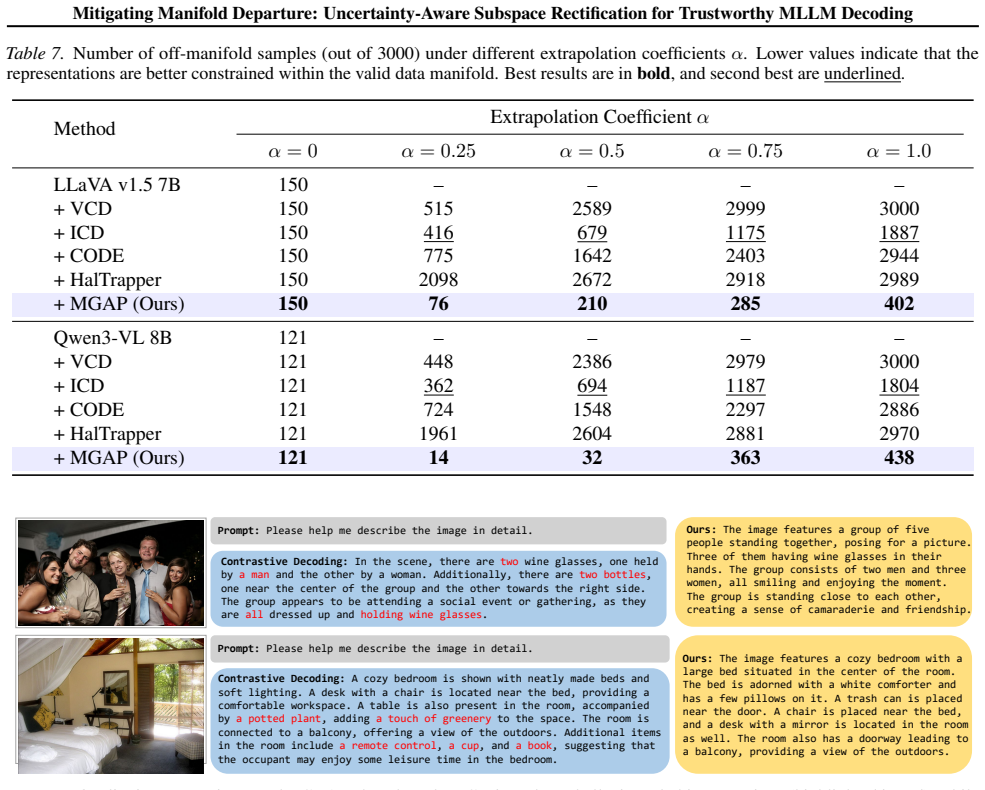
MLLMs frequently hallucinate objects inconsistent with visual inputs. This issue is typically attributed to the over-reliance on language priors, which can override the visual context. Recent training-free decoding strategies address this by penalizing language priors. However, these methods overlook the dual nature of language priors, where they can be both helpful and harmful depending on the alignment with visual evidence. In particular, blindly suppressing language priors often disrupts the model's semantic manifold, leading to performance degradation, a phenomenon we term Manifold Departure. To address this, we propose Manifold-Guided Adaptive Projection (MGAP), a geometry-aware, training-free decoding method that mitigates hallucinations while preserving representation structure. MGAP first constructs a language-prior subspace from blind hidden states via SVD. During decoding, MGAP projects each multimodal hidden state onto this subspace and applies a consistency-aware gate to adaptively attenuate only the projected prior component, yielding a subspace-selective update that largely preserves the orthogonal semantic components. Extensive experiments on POPE and CHAIR show that MGAP outperforms prior decoding baselines, achieving stronger hallucination suppression without sacrificing coherence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLM hallucinations arise from over-reliance on language priors that override visual evidence, and that prior decoding methods cause 'Manifold Departure' by indiscriminately suppressing priors. It proposes MGAP, which builds a language-prior subspace via SVD on blind hidden states, projects multimodal states onto it, and uses a consistency-aware gate to selectively attenuate only the inconsistent component, yielding a subspace-selective update that preserves orthogonal semantics. Experiments on POPE and CHAIR are said to show stronger hallucination suppression than baselines without coherence loss.
Significance. If the central geometric claim holds—that the SVD subspace isolates harmful priors and the gate selectively attenuates only inconsistent directions—the method would offer a principled, training-free alternative to blanket prior penalization. The emphasis on preserving manifold structure addresses a real gap in existing decoding strategies.
major comments (2)
- [Abstract] Abstract and method description: the claim that SVD on blind hidden states yields a subspace whose principal directions 'isolate the harmful component' is load-bearing for the selective-update argument, yet no direct geometric diagnostics (e.g., cosine alignment of top singular vectors with visual-vs-blind difference vectors on controlled consistent/inconsistent pairs) are supplied; only downstream POPE/CHAIR scores are referenced.
- [Abstract] Abstract: the consistency-aware gate is asserted to 'adaptively attenuate only the projected prior component' without affecting useful information, but the manuscript provides neither the gate's functional form, the consistency score definition, nor ablation results showing that gate errors do not degrade helpful priors.
minor comments (1)
- The term 'Manifold Departure' is introduced without a precise, quantifiable definition or metric that could be used to verify the claim that MGAP avoids it.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and commit to revisions that strengthen the geometric justification and methodological transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that SVD on blind hidden states yields a subspace whose principal directions 'isolate the harmful component' is load-bearing for the selective-update argument, yet no direct geometric diagnostics (e.g., cosine alignment of top singular vectors with visual-vs-blind difference vectors on controlled consistent/inconsistent pairs) are supplied; only downstream POPE/CHAIR scores are referenced.
Authors: We agree that direct geometric diagnostics would provide stronger support for the isolation claim. While downstream metrics on POPE and CHAIR demonstrate practical utility, we will add controlled-pair analyses, including cosine alignments of top singular vectors with visual-minus-blind difference vectors, to the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the consistency-aware gate is asserted to 'adaptively attenuate only the projected prior component' without affecting useful information, but the manuscript provides neither the gate's functional form, the consistency score definition, nor ablation results showing that gate errors do not degrade helpful priors.
Authors: The functional form and consistency score definition appear in Section 3.2, but we acknowledge that the abstract does not restate them and that explicit ablations on gate selectivity are absent. We will expand the abstract, restate the definitions, and add the requested ablation studies in the revision. revision: yes
Circularity Check
No circularity: method is a data-driven SVD projection with no self-referential reductions
full rationale
The paper describes MGAP as constructing a language-prior subspace via SVD on blind hidden states, then applying a consistency-aware gate during projection of multimodal states. No equations, derivations, or self-citations are exhibited that reduce any claimed prediction or result to a fitted input by construction. The central mechanism is presented as an external geometric operation on observed hidden states without self-definition or load-bearing self-citation. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SVD on blind hidden states isolates a language-prior subspace that contains the components to be attenuated.
invented entities (1)
-
Manifold Departure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation , author=. 2024 , eprint=
2024
-
[2]
Su, Jingran and Chen, Jingfan and Li, Hongxin and Chen, Yuntao and Qing, Li and Zhang, Zhaoxiang. Activation Steering Decoding: Mitigating Hallucination in Large Vision-Language Models through Bidirectional Hidden State Intervention. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:...
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
Instruct
Dai, Wenliang and Li, Junnan and Li, Dongxu and Zhao, Yu and Wu, Zhe and Liu, Jiaqing and Tang, Jian and Wang, Meng and Gong, Yihong and others , booktitle =. Instruct. 2023 , eprint =
2023
-
[5]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Evaluating Object Hallucination in Large Vision-Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Multi-Modal Hallucination Control by Visual Information Grounding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year =
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[8]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Similarity of Neural Network Representations Revisited , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Insights on Representational Similarity in Neural Networks with Canonical Correlation , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
International Conference on Learning Representations (ICLR) , year =
Measuring the Intrinsic Dimension of Objective Landscapes , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
International Conference on Computer Vision (ICCV) , year =
Why LVLMs Are More Prone to Hallucinations in Longer Responses: The Role of Context , author =. International Conference on Computer Vision (ICCV) , year =
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year =
CODE: Contrasting Self-generated Description to Combat Hallucination in Large Multi-modal Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[13]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[14]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of Multimodal Large Language Models: A Survey , author =. arXiv preprint arXiv:2404.18930 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Evaluating Object Hallucination in Large Vision-Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[16]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year =
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation , author =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year =
-
[17]
International Conference on Learning Representations (ICLR) , year =
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
Aligning Large Multimodal Models with Factually Augmented
Sun, Zhiqing and Shen, Sheng and Cao, Shuo and Liu, Hong and Li, Can and Shen, Yilin and Gan, Chuang and Gui, Liang-Yu and Wang, Ya-Xiong and Yang, Yi and others , journal =. Aligning Large Multimodal Models with Factually Augmented
-
[19]
2023 , eprint=
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization , author=. 2023 , eprint=
2023
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Hallucination Augmented Contrastive Learning for Multimodal Large Language Model , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[22]
arXiv preprint arXiv:2412.06775 , year =
Delve into Visual Contrastive Decoding for Hallucination Mitigation of Large Vision-Language Models , author =. arXiv preprint arXiv:2412.06775 , year =
-
[23]
Huang, Qidong and Dong, Xiaoyi and Zhang, Pan and Wang, Bin and He, Conghui and Wang, Jiaqi and Lin, Dahua and Zhang, Weiming and Yu, Nenghai , booktitle =
-
[24]
arXiv preprint arXiv:2403.00425 , year=
HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding , author=. arXiv preprint arXiv:2403.00425 , year=
-
[25]
arXiv preprint arXiv:2408.02032 , year =
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models , author =. arXiv preprint arXiv:2408.02032 , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
Do You Keep an Eye on What I Ask? Mitigating Multimodal Hallucination via Attention-Guided Ensemble Decoding , author =. International Conference on Learning Representations (ICLR) , year =
-
[27]
Park, Young and Lee, Dayeon and Choe, Jihye and Chang, Byung-Ok , booktitle =
-
[28]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. arXiv preprint arXiv:2010.11929 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Masked Autoencoders Are Scalable Vision Learners , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[30]
Beyer, Lucas and Izmailov, Pavel and Kolesnikov, Alexander and Caron, Mathilde and Kornblith, Simon and Zhai, Xiaohua and Minderer, Matthias and Tschannen, Michael and Abdulmohsin, Ibrahim and Pavetic, Felix , booktitle =
-
[31]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proceedings of the 38th International Conference on Machine Learning , series =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , series =. 2021 , note =
2021
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Flamingo: a Visual Language Model for Few-Shot Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[34]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , year =
VQA: Visual Question Answering , author =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , year =
-
[35]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Show and Tell: A Neural Image Caption Generator , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[36]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. European Conference on Computer Vision (ECCV) , year =
-
[37]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
Object Hallucination in Image Captioning , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
2018
-
[38]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Contrastive Decoding: Open-Ended Text Generation as Optimization , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[39]
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal
Tong, Shengbang and Liu, Zijian and Zhai, Yuhuai and Ma, Yang and LeCun, Yann and Xie, Saining , booktitle =. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal. 2024 , note =
2024
-
[40]
Findings of the Association for Computational Linguistics (Findings of ACL) , year =
Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding , author =. Findings of the Association for Computational Linguistics (Findings of ACL) , year =
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling , author =. arXiv preprint arXiv:2412.05271 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models , author=. arXiv preprint arXiv:2409.17146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Advances in Neural Information Processing Systems , year =
Are We on the Right Way for Evaluating Large Vision-Language Models? , author =. Advances in Neural Information Processing Systems , year =
-
[45]
Proceedings of CVPR , year=
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. Proceedings of CVPR , year=
-
[46]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos , author=. arXiv preprint arXiv:2501.13826 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Representation Learning: A Review and New Perspectives , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2013 , doi =
2013
-
[48]
Proceedings of the 36th International Conference on Machine Learning (ICML) , series =
Manifold Mixup: Better Representations by Interpolating Hidden States , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , series =
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Disentangling Adversarial Robustness and Generalization , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[50]
On the Geometry of Adversarial Examples
On the Geometry of Adversarial Examples , author =. arXiv preprint arXiv:1811.00525 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Science , volume=
Nonlinear Dimensionality Reduction by Locally Linear Embedding , author=. Science , volume=
-
[52]
Science , volume=
A Global Geometric Framework for Nonlinear Dimensionality Reduction , author=. Science , volume=
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Representation Learning: A Review and New Perspectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.