QSplitFL: Capability Aware Deep Q-Learning for Optimal Split Point Selection in Split Federated Learning
Pith reviewed 2026-06-28 15:37 UTC · model grok-4.3
The pith
QSplitFL's deep Q-network selects split points using only client hardware metrics to speed convergence in split federated learning on heterogeneous devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
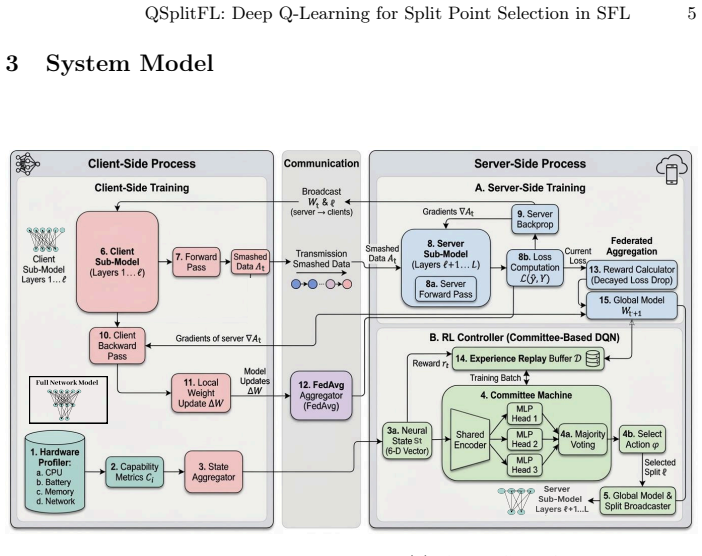
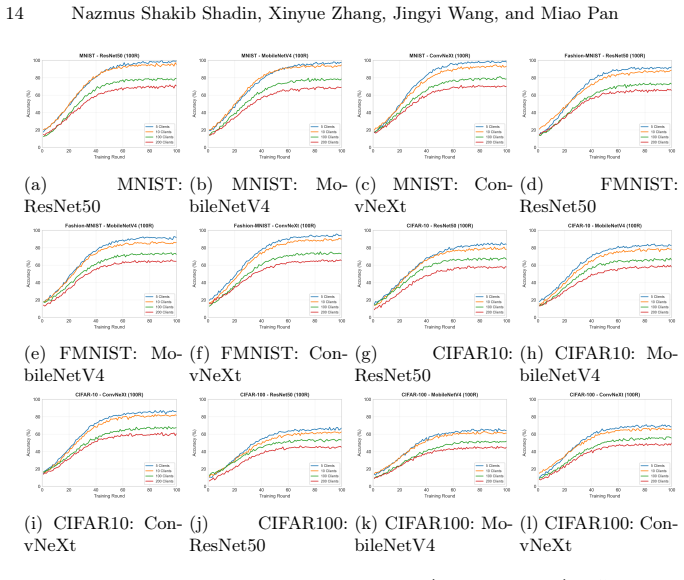
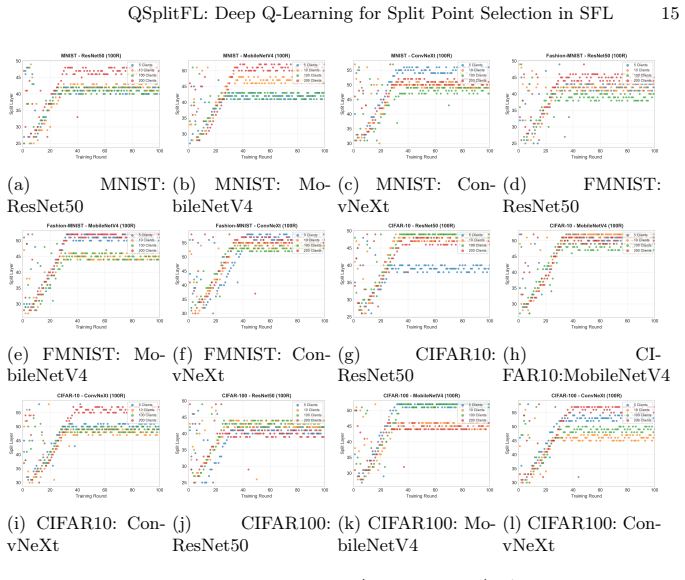
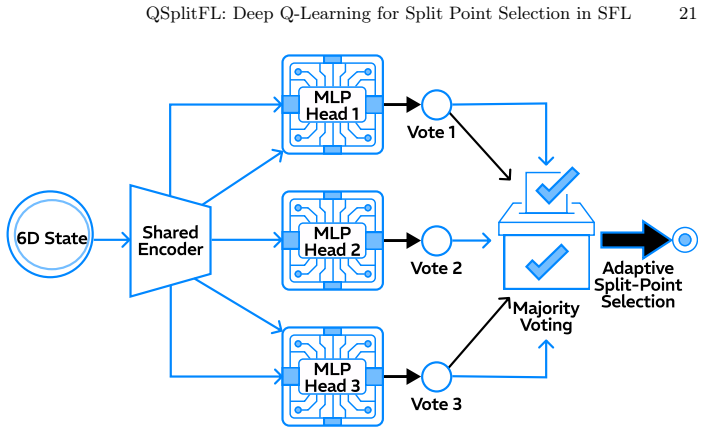
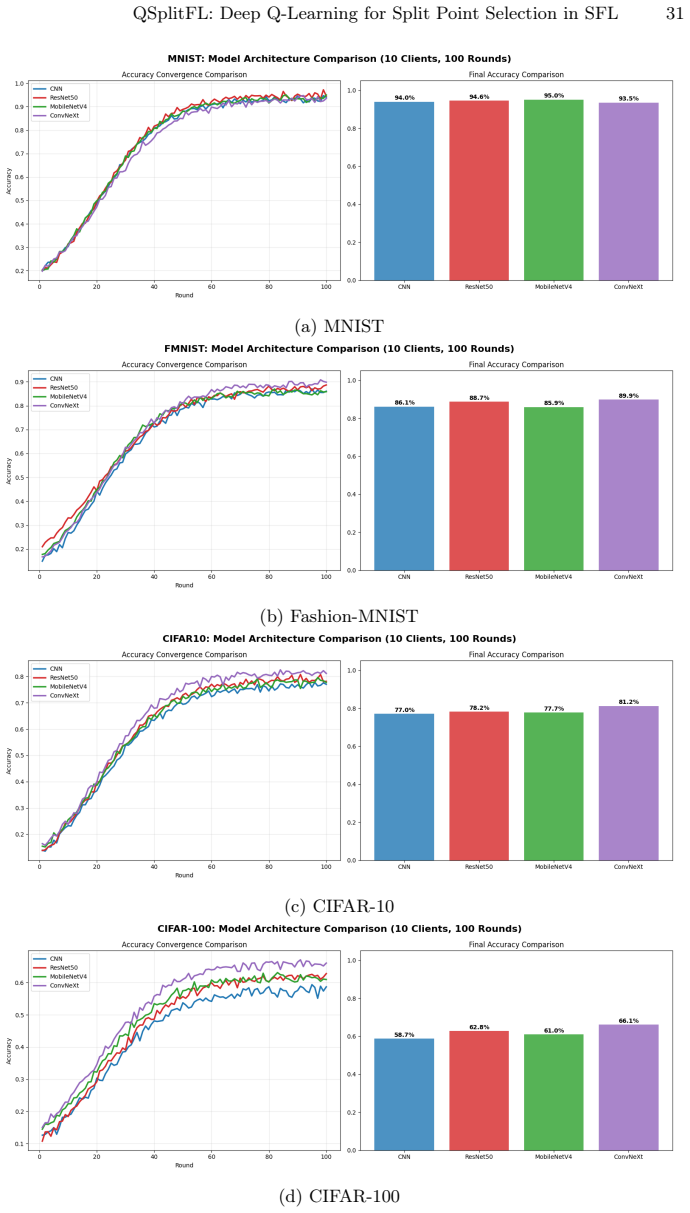
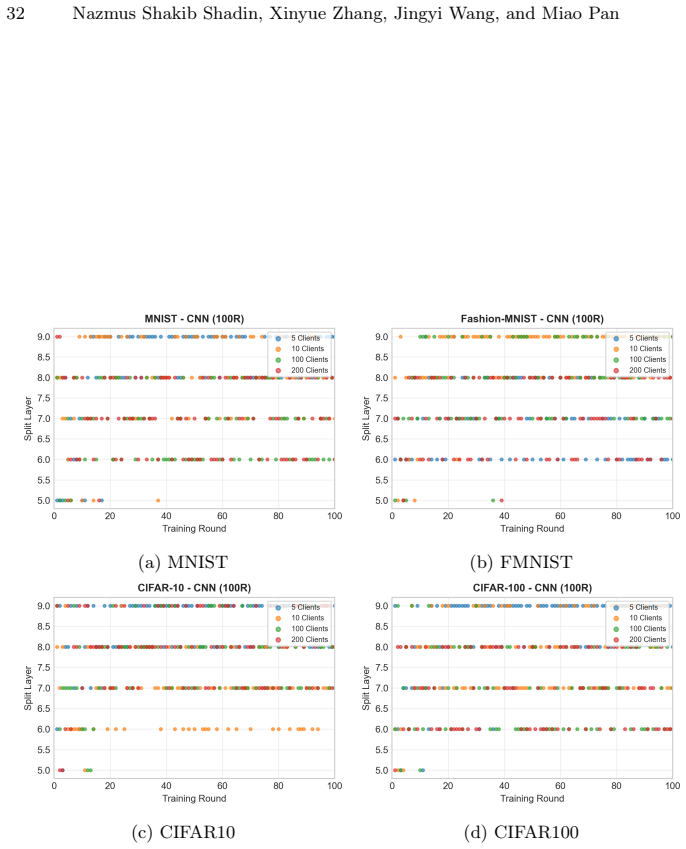
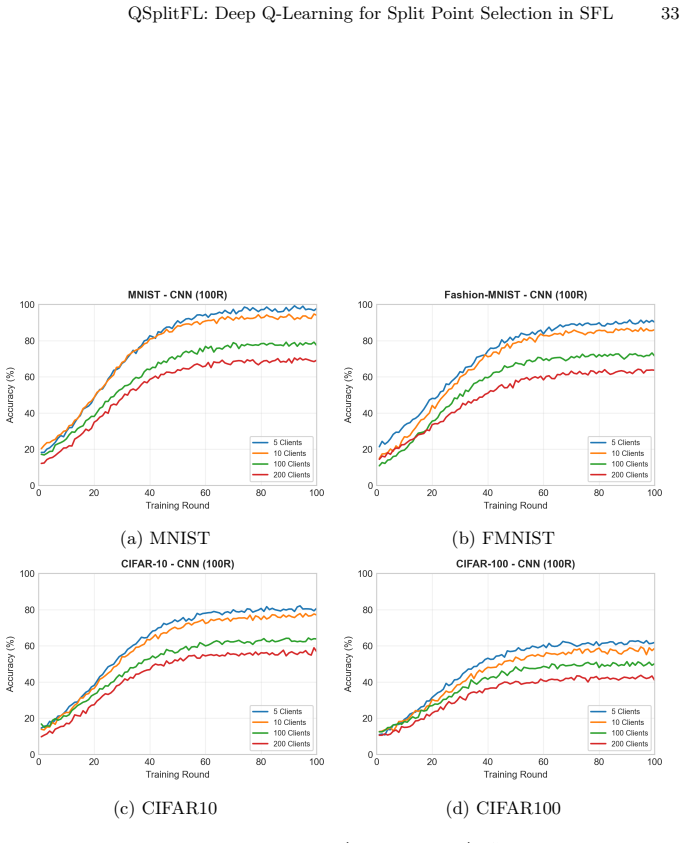
QSplitFL is a capability-aware Deep Q-Network framework for optimal split point selection in Split learning based Federated Learning. It uses a lightweight state representation from client hardware metrics and a decayed loss-drop reward function with a committee-based DQN architecture. Extensive experiments demonstrate better convergence and higher accuracy compared to existing methods while adapting to heterogeneous device resources on multiple datasets and architectures.
What carries the argument
The Deep Q-Network that takes hardware metrics as state input and outputs split point actions, trained with decayed loss-drop rewards and committee voting.
If this is right
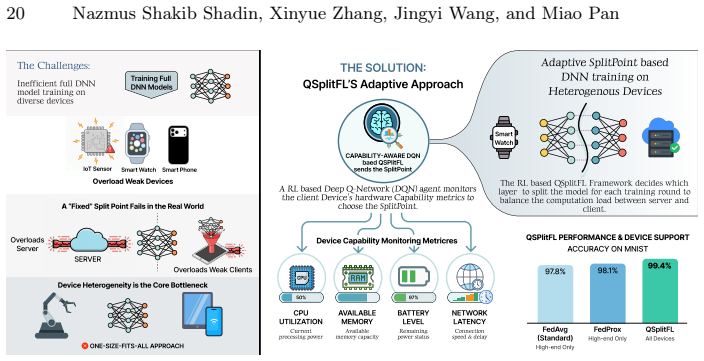
- Split points adapt dynamically to device capabilities, reducing overload on weak clients.
- Convergence speeds up and final accuracy increases on standard benchmarks.
- The approach works across CNNs to modern architectures like ConvNeXt without model weight inputs.
- Reward design prioritizes early training progress over later stages.
Where Pith is reading between the lines
- The method may extend to other split decisions in distributed training beyond federated settings.
- Hardware-only states could enable privacy benefits by avoiding sharing model internals.
- Testing on real mobile hardware rather than simulated metrics would strengthen the results.
Load-bearing premise
Client hardware metrics alone provide sufficient information for the DQN to learn optimal split points without access to model weights or internal states.
What would settle it
Running the trained QSplitFL agent on a new device fleet whose hardware distributions differ markedly from the training set and observing that the chosen splits yield slower convergence or lower accuracy than a fixed middle-layer split would falsify the claim.
Figures

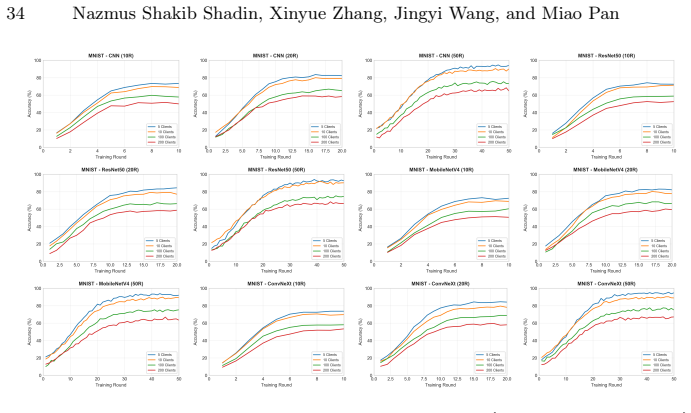
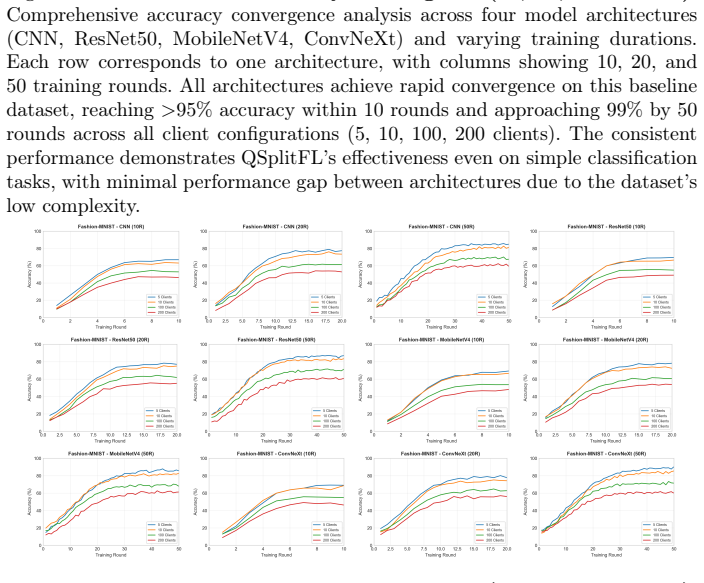

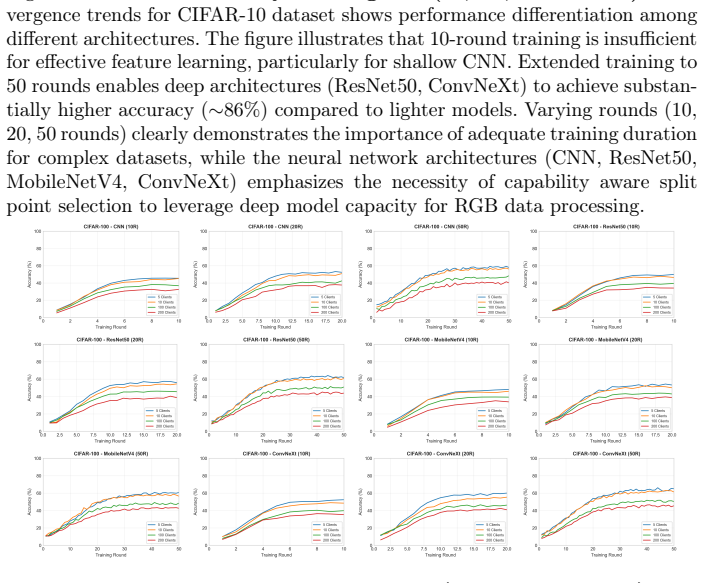
read the original abstract
Federated Learning (FL) combined with Split Learning (SL) is a privacy preserving paradigm that enables training deep neural networks (DNNs) on resource constrained devices while reducing overall training cost. However, determining the optimal split point, meaning the layer where the model is divided still remains a critical challenge, especially when clients have heterogeneous hardware capabilities. Fixed split points can overload weak devices and increase the communication and server load, which slows convergence and reduces stability. This paper introduces QSplitFL, a novel capability-aware Deep Q-Network (DQN) framework for optimal split point selection in Split learning based Federated Learning (SFL) environments. Unlike existing approaches that rely on high-dimensional model weight representations, QSplitFL employs a lightweight state representation derived directly from client hardware metrics, including CPU utilization, memory, battery level, and network latency. The proposed framework incorporates a decayed loss-drop reward function that prioritizes early convergence, and a committee-based DQN architecture with majority voting to mitigate reward hacking. Extensive experiments on MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100 datasets using CNN, ResNet50, MobileNetV4, and ConvNeXt architectures demonstrate that our approach achieves better convergence and higher accuracy compared to existing methods, while effectively adapting to heterogeneous device resources. The source code is publicly available at https://github.com/AIPO-Lab/QSplitFL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QSplitFL, a Deep Q-Network framework for optimal split-point selection in Split Federated Learning. It replaces high-dimensional model-weight states with a lightweight representation using only client hardware metrics (CPU utilization, memory, battery level, network latency). A decayed loss-drop reward prioritizes early convergence and a committee-based DQN with majority voting mitigates reward hacking. Experiments across MNIST, Fashion-MNIST, CIFAR-10, CIFAR-100 and CNN/ResNet50/MobileNetV4/ConvNeXt architectures are asserted to yield faster convergence and higher accuracy than existing methods while adapting to device heterogeneity; source code is released publicly.
Significance. If the empirical claims hold with verifiable metrics, the work would be significant for practical SFL on heterogeneous edge devices by demonstrating that low-dimensional hardware states suffice for effective RL-based split selection, reducing communication and compute overhead. Public code availability is a clear strength supporting reproducibility. The result would be less impactful if the hardware-only state proves architecture-specific, limiting transfer to new models.
major comments (3)
- [Abstract] Abstract: the central claim that QSplitFL 'achieves better convergence and higher accuracy' rests on 'extensive experiments' yet no quantitative tables, accuracy values, convergence curves, baseline definitions, or statistical tests are referenced; this absence is load-bearing because the empirical superiority cannot be assessed.
- [Method] Method (state representation): the DQN state is defined solely from hardware metrics with no layer descriptors or model features. Because per-layer compute costs vary sharply across architectures (early conv layers vs. later FC layers in ResNet50 vs. ConvNeXt), the learned mapping from hardware state to split point is likely tied to the four training architectures; this directly undermines the claim of effective adaptation under heterogeneity for unseen models.
- [Method] Reward design: the decayed loss-drop reward and committee voting mechanism are introduced to favor early convergence and prevent hacking, yet both contain free parameters (decay schedule, voting threshold) that can be tuned post-hoc to observed training curves, introducing circularity between the modeling choices and the reported performance.
minor comments (1)
- [Abstract] Abstract: nomenclature 'MobileNetV4' is non-standard; confirm whether this refers to MobileNetV2, V3, or a custom variant.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, with clarifications and planned revisions where appropriate to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that QSplitFL 'achieves better convergence and higher accuracy' rests on 'extensive experiments' yet no quantitative tables, accuracy values, convergence curves, baseline definitions, or statistical tests are referenced; this absence is load-bearing because the empirical superiority cannot be assessed.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revision we will insert concise references to key results (e.g., accuracy gains and convergence epochs versus baselines) together with pointers to the corresponding tables and figures. revision: yes
-
Referee: [Method] Method (state representation): the DQN state is defined solely from hardware metrics with no layer descriptors or model features. Because per-layer compute costs vary sharply across architectures (early conv layers vs. later FC layers in ResNet50 vs. ConvNeXt), the learned mapping from hardware state to split point is likely tied to the four training architectures; this directly undermines the claim of effective adaptation under heterogeneity for unseen models.
Authors: Hardware metrics were selected precisely because they are architecture-agnostic and reflect device capability. Experiments show the policy adapts across the four evaluated architectures under heterogeneous conditions. We will add an explicit limitations paragraph noting that generalization to entirely new architectures would require retraining and is not claimed in the current work. revision: partial
-
Referee: [Method] Reward design: the decayed loss-drop reward and committee voting mechanism are introduced to favor early convergence and prevent hacking, yet both contain free parameters (decay schedule, voting threshold) that can be tuned post-hoc to observed training curves, introducing circularity between the modeling choices and the reported performance.
Authors: The decay schedule and voting threshold were fixed after preliminary validation runs conducted before the final experiments. We will report the exact values used and include a sensitivity study demonstrating that performance remains stable under modest perturbations of these parameters. revision: yes
Circularity Check
No circularity: empirical RL method with independent experimental validation
full rationale
The paper proposes a DQN-based framework for split-point selection whose state uses only client hardware metrics and whose reward is a decayed loss-drop function. These are explicit design choices in the RL formulation, not a claimed first-principles derivation. Performance claims rest on direct empirical comparisons across four datasets and four architectures; no equation or theorem is shown to reduce the reported accuracy or convergence gains to the reward definition or state representation by algebraic identity. No self-citation chain is invoked to justify uniqueness or load-bearing assumptions. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- decayed loss-drop reward decay schedule
- DQN training hyperparameters
axioms (1)
- domain assumption Client hardware metrics are a sufficient state representation for optimal split-point decisions
invented entities (1)
-
Committee-based DQN with majority voting
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security
Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with differential privacy. In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. pp. 308–318 (2016)
2016
-
[2]
Sensors22(2), 450 (2022) QSplitFL: Deep Q-Learning for Split Point Selection in SFL 17
Abreha, H.G., Hayajneh, M., Serhani, M.A.: Federated learning in edge computing: a systematic survey. Sensors22(2), 450 (2022) QSplitFL: Deep Q-Learning for Split Point Selection in SFL 17
2022
-
[3]
Journal of Network and Computer Applications236, 104105 (2025)
Arafeh, M., Wazzeh, M., Sami, H., Ould-Slimane, H., Talhi, C., Mourad, A., Otrok, H.: Efficient privacy-preserving ml for iot: Cluster-based split federated learning scheme for non-iid data. Journal of Network and Computer Applications236, 104105 (2025)
2025
-
[4]
Flower: A Friendly Federated Learning Research Framework
Beutel, D.J., Topal, T., Mathur, A., Qiu, X., Fernandez-Marques, J., Gao, Y., Sani, L., Li, K.H., Parcollet, T., de Gusmão, P.P.B., et al.: Flower: A friendly federated learning research framework. arXiv preprint arXiv:2007.14390 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[5]
In: 2024 19th International Symposium on Wireless Communication Systems (ISWCS)
Binucci, F., Merluzzi, M., Banelli, P., Strinati, E.C., Di Lorenzo, P.: Enabling edge artificial intelligence via goal-oriented deep neural network splitting. In: 2024 19th International Symposium on Wireless Communication Systems (ISWCS). pp. 1–6. IEEE (2024)
2024
-
[6]
Sensors24(1), 88 (2023)
Chen, H., Chen, X., Peng, L., Bai, Y.: Personalized fair split learning for resource- constrained internet of things. Sensors24(1), 88 (2023)
2023
-
[7]
IEEE Internet of Things Journal12(15), 30460–30474 (2025).https://doi.org/10.1109/JIOT.2025.3572393
Chen, X., Li, J., Fan, D., Chakrabarti, C.: Heterosfl: Split federated learning with heterogeneous clients and non-iid data. IEEE Internet of Things Journal12(15), 30460–30474 (2025).https://doi.org/10.1109/JIOT.2025.3572393
-
[8]
arXiv preprint arXiv:2412.15536 (2024)
Dachille, J., Huang, C., Liu, X.: The impact of cut layer selection in split federated learning. arXiv preprint arXiv:2412.15536 (2024)
-
[9]
IEEE Transactions on Mobile Computing (2025)
Fan, W., Chen, P., Chun, X., Liu, Y.: Madrl-based model partitioning, aggregation control, and resource allocation for cloud-edge-device collaborative split federated learning. IEEE Transactions on Mobile Computing (2025)
2025
-
[10]
Journal of Network and Computer Applications116, 1–8 (2018)
Gupta, O., Raskar, R.: Distributed learning of deep neural network over multiple agents. Journal of Network and Computer Applications116, 1–8 (2018)
2018
-
[11]
International Journal of Computing and Digital Sys- tems11(1), 541–552 (2022)
Hariharan, N., Paavai, A.G.: A brief study of deep reinforcement learning with epsilon-greedy exploration. International Journal of Computing and Digital Sys- tems11(1), 541–552 (2022)
2022
-
[12]
IEEE Access13, 46312 (2025)
Hukkeri,G.S.,Goudar,R.,Dhananjaya,G.,Rathod,V.N.:Acomprehensivesurvey on split-fed learning: methods, innovations, and future directions. IEEE Access13, 46312 (2025)
2025
-
[13]
IEEE Com- munications Surveys & Tutorials23(3), 1759–1799 (2021)
Khan, L.U., Saad, W., Han, Z., Hossain, E., Hong, C.S.: Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Com- munications Surveys & Tutorials23(3), 1759–1799 (2021)
2021
-
[14]
In: 2019 Asia-Pacific signal and information processing association annual summit and conference (APSIPA ASC)
Lee, Y.L., Qin, D.: A survey on applications of deep reinforcement learning in resource management for 5g heterogeneous networks. In: 2019 Asia-Pacific signal and information processing association annual summit and conference (APSIPA ASC). pp. 1856–1862. IEEE (2019)
2019
-
[15]
In: 2024 IEEE International Conference on E-health Networking, Application & Services (HealthCom)
Li, J., Yu, S.: Integrity verifiable privacy-preserving federated learning for healthcare-iot. In: 2024 IEEE International Conference on E-health Networking, Application & Services (HealthCom). pp. 1–6. IEEE (2024)
2024
-
[16]
arXiv preprint arXiv:2102.08504 (2021)
Li, O., Sun, J., Yang, X., Gao, W., Zhang, H., Xie, J., Smith, V., Wang, C.: Label leakage and protection in two-party split learning. arXiv preprint arXiv:2102.08504 (2021)
-
[17]
Proceedings of Machine learning and sys- tems2, 429–450 (2020)
Li, T., Sahu, A.K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V.: Federated optimization in heterogeneous networks. Proceedings of Machine learning and sys- tems2, 429–450 (2020)
2020
-
[18]
arXiv preprint arXiv:1905.10497 (2019)
Li, T., Sanjabi, M., Beirami, A., Smith, V.: Fair resource allocation in federated learning. arXiv preprint arXiv:1905.10497 (2019)
-
[19]
Li, X., Huang, K., Yang, W., Wang, S., Zhang, Z.: On the convergence of fedavg on non-iid data. arXiv preprint arXiv:1907.02189 (2019) 18 Nazmus Shakib Shadin, Xinyue Zhang, Jingyi Wang, and Miao Pan
-
[20]
arXiv preprint arXiv:2501.01078 (2025)
Liang, Y., Chen, Q., Zhu, G., Awan, M.K., Jiang, H.: Communication-and- computation efficient split federated learning: Gradient aggregation and resource management. arXiv preprint arXiv:2501.01078 (2025)
-
[21]
IEEE Transactions on Wireless Communications 22(4), 2650–2665 (2022)
Liu, X., Deng, Y., Mahmoodi, T.: Wireless distributed learning: A new hybrid split and federated learning approach. IEEE Transactions on Wireless Communications 22(4), 2650–2665 (2022)
2022
-
[22]
Nixon, J., Lakshminarayanan, B., Tran, D.: Why are bootstrapped deep ensembles not better? In: ”I Can’t Believe It’s Not Better!” NeurIPS 2020 workshop (2020)
2020
-
[23]
Advances in neural information processing systems29(2016)
Osband, I., Blundell, C., Pritzel, A., Van Roy, B.: Deep exploration via boot- strapped dqn. Advances in neural information processing systems29(2016)
2016
-
[24]
Computer Networks218, 109380 (2022)
Samikwa, E., Di Maio, A., Braun, T.: Ares: Adaptive resource-aware split learning for internet of things. Computer Networks218, 109380 (2022)
2022
-
[25]
Schaul, T., Quan, J., Antonoglou, I., Silver, D.: Prioritized experience replay. arXiv preprint arXiv:1511.05952 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
arXiv preprint arXiv:1909.09145 (2019)
Singh, A., Vepakomma, P., Gupta, O., Raskar, R.: Detailed comparison of com- munication efficiency of split learning and federated learning. arXiv preprint arXiv:1909.09145 (2019)
-
[27]
In: Proceedings of the AAAI conference on artificial intelligence
Thapa, C., Arachchige, P.C.M., Camtepe, S., Sun, L.: Splitfed: When federated learning meets split learning. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 8485–8493 (2022)
2022
-
[28]
arXiv preprint arXiv:2508.08339 (2025)
Tran, D.T., Ha, N.B., Nguyen, V.D., Wong, K.S.: Sherl-fl: When representation learning meets split learning in hierarchical federated learning. arXiv preprint arXiv:2508.08339 (2025)
-
[29]
Split learning for health: Distributed deep learning without sharing raw patient data
Vepakomma, P., Gupta, O., Swedish, T., Raskar, R.: Split learning for health: Distributed deep learning without sharing raw patient data. arXiv preprint arXiv:1812.00564 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
In: IEEE INFOCOM 2020-IEEE conference on computer communications
Wang, H., Kaplan, Z., Niu, D., Li, B.: Optimizing federated learning on non-iid data with reinforcement learning. In: IEEE INFOCOM 2020-IEEE conference on computer communications. pp. 1698–1707. IEEE (2020)
2020
-
[31]
IEEE Internet of Things Journal9(21), 20889–20901 (2022)
Wu, D., Ullah, R., Harvey, P., Kilpatrick, P., Spence, I., Varghese, B.: Fedadapt: Adaptive offloading for iot devices in federated learning. IEEE Internet of Things Journal9(21), 20889–20901 (2022)
2022
-
[32]
arXiv preprint arXiv:2407.03038 (2024)
Wu, F., Liu, X., Wang, H., Wang, X., Su, L., Gao, J.: Towards federated rlhf with aggregated client preference for llms. arXiv preprint arXiv:2407.03038 (2024)
-
[33]
IEEE Wireless Communications31(3), 177–184 (2023)
Wu, M., Cheng, G., Li, P., Yu, R., Wu, Y., Pan, M., Lu, R.: Split learning with differential privacy for integrated terrestrial and non-terrestrial networks. IEEE Wireless Communications31(3), 177–184 (2023)
2023
-
[34]
Electronics12(11), 2478 (2023)
Yan, S., Zhang, P., Huang, S., Wang, J., Sun, H., Zhang, Y., Tolba, A.: Node selection algorithm for federated learning based on deep reinforcement learning for edge computing in iot. Electronics12(11), 2478 (2023)
2023
-
[35]
IEEE Transactions on Intelligent Trans- portation Systems (2025)
Yu, L., Chang, Z., Jia, Y., Min, G.: Model partition and resource allocation for split learning in vehicular edge networks. IEEE Transactions on Intelligent Trans- portation Systems (2025)
2025
-
[36]
IEEE Transactions on Network Science and Engineering10(3), 1339–1351 (2022)
Yuan, X., Zhang, Z., Feng, C., Cui, Y., Garg, S., Kaddoum, G., Yu, K.: A dqn- based frame aggregation and task offloading approach for edge-enabled iomt. IEEE Transactions on Network Science and Engineering10(3), 1339–1351 (2022)
2022
-
[37]
F i x e d
Zhu, G., Deng, Y., Chen, X., Zhang, H., Fang, Y., Wong, T.F.: Esfl: Efficient split federated learning over resource-constrained heterogeneous wireless devices. IEEE Internet of Things Journal11(16), 27153–27166 (2024) QSplitFL: Deep Q-Learning for Split Point Selection in SFL 19 A Appendix This appendix provides detailed supplementary materials that corr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.