The Empirically Grounded Adaptive Virtual Patient for Psychotherapy Training: Disclosure That Responds to Therapist Micro-Skills
Pith reviewed 2026-06-27 14:37 UTC · model grok-4.3
The pith
Virtual patient adapts disclosure level to therapist empathy and exploration
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
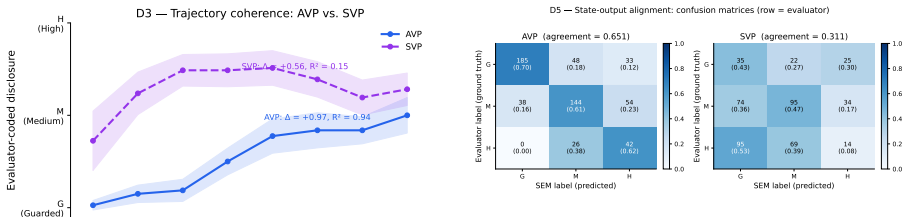
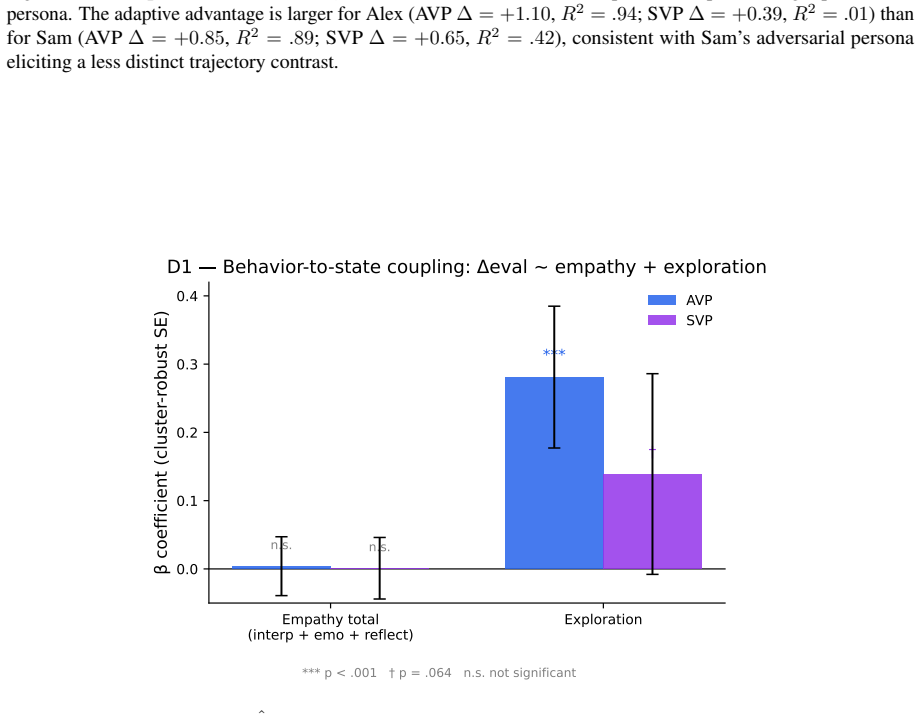
The AVP conditions LLM-generated responses on a disclosure level that is updated each turn by a structural equation model fitted to real transcripts, which quantifies how therapist empathy and exploration shift patient openness. In 1,033 turns of testing the AVP's disclosure rose in response to these skills while baselines did not, with exploration carrying most of the signal and the full parameterization outperforming ablated versions.
What carries the argument
Structural equation model that quantifies how therapist empathy and exploration shift patient openness over time, used to update the disclosure level that conditions LLM utterances.
If this is right
- AVP disclosure increases with therapist empathy and exploration while prompt-only versions stay flat.
- Exploration supplies the strongest adaptive signal according to the model and ablations.
- The empirically fitted parameters outperform other ways of controlling the LLM behavior.
- The system maintains consistent adaptation across long sessions of over 1,000 turns.
Where Pith is reading between the lines
- The same modeling approach could be used to adapt other patient behaviors such as emotional expression or resistance.
- Training programs could add real-time scoring of micro-skills to give trainees immediate feedback on what increases disclosure.
- The model might need re-fitting or testing when applied to therapy styles or patient populations not well represented in the original transcripts.
Load-bearing premise
The relationships between therapist micro-skills and patient openness measured in real transcripts can be applied directly to adjust disclosure in LLM responses without losing validity.
What would settle it
New sessions in which high therapist empathy and exploration scores produce no corresponding rise in AVP disclosure level, or produce the same flat pattern as the prompt-only baseline.
Figures








read the original abstract
Simulated patients offer a scalable way to train psychotherapy micro-skills such as empathic responding and exploratory probing, but current systems either follow fixed scripts or rely on LLMs that drift unpredictably over long sessions. We present the Adaptive Virtual Patient (AVP), which adapts its disclosure behavior -- from guarded, through moderate openness, to full disclosure -- in response to trainee skill. The AVP is grounded in a structural equation model fit to nearly 2{,}000 hours of real-world psychotherapy transcripts, which quantifies how therapist empathy and exploration shift a patient's openness over time. An LLM generates the AVP's utterances conditioned on a disclosure level that the dynamics module updates each turn. In an evaluation with 20 clinicians and trainees over 80 sessions (1{,}033 turns), the AVP's disclosure rises in response to therapist empathy and exploration, while a prompt-only baseline stays flat; ablations confirm that the empirically motivated parameterization outperforms alternatives, with exploration carrying most of the adaptive signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Adaptive Virtual Patient (AVP), an LLM-based simulated patient for psychotherapy training whose disclosure level (guarded to full) is dynamically updated each turn by a structural equation model (SEM) fitted to real psychotherapy transcripts. The SEM quantifies effects of therapist empathy and exploration on patient openness; the resulting scalar conditions the LLM prompt. A study with 20 clinicians/trainees across 80 sessions (1,033 turns) reports that AVP disclosure rises appropriately with therapist skill while a prompt-only baseline remains flat; ablations indicate the empirical parameterization (especially exploration) drives the adaptation.
Significance. If the SEM-to-LLM transfer is shown to preserve the fitted causal relationships in generated text, the work supplies a concrete, data-grounded mechanism for controllable long-horizon patient simulation that outperforms prompt engineering alone. This directly addresses a practical bottleneck in scalable micro-skill training and supplies an explicit, falsifiable link between transcript-derived parameters and system behavior.
major comments (3)
- [§5, §4.2] §5 (Evaluation) and §4.2 (Dynamics module): The reported adaptation is measured solely via the internal disclosure scalar and participant ratings of session quality; no independent coding or quantitative analysis of the generated utterances' actual disclosure/openness content (e.g., via blinded raters applying the same openness scale used to fit the SEM) is presented. This leaves the central claim—that LLM outputs respect the SEM coefficients—unverified and vulnerable to prompt artifacts.
- [§3.1] §3.1 (SEM construction): The manuscript states the model was fit to “nearly 2,000 hours” of transcripts but supplies neither the exact sample size (sessions/transcripts), fitting procedure (e.g., maximum likelihood, estimator), goodness-of-fit indices (CFI, RMSEA, SRMR), nor any cross-validation or sensitivity checks on the empathy/exploration coefficients. These parameters are load-bearing for the adaptation rule and must be reported for reproducibility and credibility assessment.
- [§5.3] §5.3 (Quantitative results) and Table 2/3 (if present): The comparison of AVP vs. baseline and ablations reports directional changes in disclosure but omits the statistical tests employed, exact p-values or confidence intervals, effect sizes, and any correction for multiple comparisons across the 1,033 turns. Without these, the strength of evidence that “exploration carries most of the adaptive signal” cannot be evaluated.
minor comments (2)
- [Abstract, §2] Abstract and §2: The phrase “nearly 2,000 hours” should be replaced by the precise figure and a citation to the transcript corpus once the fitting details are added.
- [Figure 1] Figure 1 (system diagram): The arrow from “Dynamics module” to “LLM prompt” should explicitly label the disclosure scalar and note whether it is normalized or passed raw.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5, §4.2] §5 (Evaluation) and §4.2 (Dynamics module): The reported adaptation is measured solely via the internal disclosure scalar and participant ratings of session quality; no independent coding or quantitative analysis of the generated utterances' actual disclosure/openness content (e.g., via blinded raters applying the same openness scale used to fit the SEM) is presented. This leaves the central claim—that LLM outputs respect the SEM coefficients—unverified and vulnerable to prompt artifacts.
Authors: We agree that direct coding of generated utterances against the openness scale would provide stronger verification that LLM outputs respect the SEM coefficients. The current evaluation centers on the disclosure scalar (the explicit mechanism) and clinician ratings of session quality as external indicators of adaptation. In the revision we will add a post-hoc blinded coding analysis on a sample of utterances to quantify alignment with predicted disclosure levels and address potential prompt artifacts. revision: yes
-
Referee: [§3.1] §3.1 (SEM construction): The manuscript states the model was fit to “nearly 2,000 hours” of transcripts but supplies neither the exact sample size (sessions/transcripts), fitting procedure (e.g., maximum likelihood, estimator), goodness-of-fit indices (CFI, RMSEA, SRMR), nor any cross-validation or sensitivity checks on the empathy/exploration coefficients. These parameters are load-bearing for the adaptation rule and must be reported for reproducibility and credibility assessment.
Authors: We will expand §3.1 to report the exact sample size, estimation procedure, all goodness-of-fit indices, cross-validation results, and sensitivity checks on the key coefficients. These details were generated during model development but omitted for brevity; including them will support reproducibility and credibility assessment of the adaptation rule. revision: yes
-
Referee: [§5.3] §5.3 (Quantitative results) and Table 2/3 (if present): The comparison of AVP vs. baseline and ablations reports directional changes in disclosure but omits the statistical tests employed, exact p-values or confidence intervals, effect sizes, and any correction for multiple comparisons across the 1,033 turns. Without these, the strength of evidence that “exploration carries most of the adaptive signal” cannot be evaluated.
Authors: We will revise §5.3 and associated tables to report the statistical tests used (linear mixed-effects models), exact p-values, confidence intervals, effect sizes, and a note on multiple-comparison handling for the pre-specified contrasts. This will allow full evaluation of the evidence strength regarding the role of exploration. revision: yes
Circularity Check
No significant circularity; derivation relies on external transcript data and human evaluation
full rationale
The structural equation model is fitted to an independent corpus of ~2000 hours of real psychotherapy transcripts (external to the present LLM system). The adaptation mechanism updates a disclosure scalar from this model and conditions LLM generation on it; the central empirical claim is then tested via a separate human evaluation (20 clinicians, 80 sessions, 1033 turns) that compares against a prompt-only baseline and ablations. No equation or claim reduces by construction to its own fitted inputs or to a self-citation chain; the evaluation provides an external benchmark that is not tautological with the parameterization.
Axiom & Free-Parameter Ledger
free parameters (1)
- SEM coefficients for empathy and exploration effects on openness
axioms (1)
- domain assumption Therapist empathy and exploration causally influence patient openness in a manner quantifiable by a linear structural equation model that generalizes beyond the original transcripts.
Reference graph
Works this paper leans on
-
[1]
and Cooper, Janice L
Patel, Vikram and Saxena, Shekhar and Lund, Crick and Thornicroft, Graham and Baingana, Florence and Bolton, Paul and Chisholm, Dan and Collins, Pamela Y. and Cooper, Janice L. and Eaton, Julian and Herrman, Helen and Herzallah, Mohammad M. and Huang, Yueqin and Jordans, Mark J. D. and Kleinman, Arthur and Medina-Mora, Maria Elena and Morgan, Ellen and Ni...
2018
-
[2]
and Desiraju, Keshav and Morris, Jodi E
Kakuma, Ritsuko and Minas, Harry and van Ginneken, Nadja and Dal Poz, Mario R. and Desiraju, Keshav and Morris, Jodi E. and Saxena, Shekhar and Scheffler, Richard M. , title =. The Lancet , volume =. 2011 , doi =
2011
-
[3]
, title =
Barrows, Howard S. , title =. Academic Medicine , volume =. 1993 , doi =
1993
-
[4]
and Watson, Jeanne C
Elliott, Robert and Bohart, Arthur C. and Watson, Jeanne C. and Greenberg, Leslie S. , title =. Psychotherapy Relationships That Work: Evidence-Based Responsiveness , edition =
-
[5]
, title =
Bordin, Edward S. , title =. Psychotherapy: Theory, Research and Practice , volume =. 1979 , doi =
1979
-
[6]
The alliance in adult psychotherapy: A meta-analytic synthesis , journal =
Fl. The alliance in adult psychotherapy: A meta-analytic synthesis , journal =. 2018 , doi =
2018
-
[7]
, title =
Bollen, Kenneth A. , title =. 1989 , doi =
1989
-
[8]
, title =
Kline, Rex B. , title =. 2023 , isbn =
2023
-
[9]
JMIR Medical Education , volume =
Holderried, Friederike and Stegemann-Philipps, Christian and Herrmann-Werner, Anne and Festl-Wietek, Teresa and Holderried, Martin and Eickhoff, Carsten and Mahling, Moritz , title =. JMIR Medical Education , volume =. 2024 , doi =
2024
-
[10]
and Zhi, Jiayin and Eack, Shaun M
Wang, Ruiyi and Milani, Stephanie and Chiu, Jamie C. and Zhi, Jiayin and Eack, Shaun M. and Labrum, Travis and Murphy, Samuel M and Jones, Nev and Hardy, Kate V and Shen, Hong and Fang, Fei and Chen, Zhiyu , booktitle =. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.711 , pages =
-
[11]
2021 , isbn =
Ethics and Governance of Artificial Intelligence for Health:. 2021 , isbn =
2021
-
[12]
2023 , doi =
Tabassi, Elham , title =. 2023 , doi =
2023
-
[13]
and Triola, Marc M
Cook, David A. and Triola, Marc M. , title =. Medical Education , volume =. 2009 , doi =
2009
-
[14]
and Woodham, Luke A
Kononowicz, Andrzej A. and Woodham, Luke A. and Edelbring, Samuel and Stathakarou, Natalia and Davies, David and Saxena, Nakul and Tudor Car, Lorainne and Carlstedt-Duke, Jan and Car, Josip and Zary, Nabil , title =. Journal of Medical Internet Research , volume =. 2019 , doi =
2019
-
[15]
and Hatala, Rose and Brydges, Ryan and Zendejas, Benjamin and Szostek, Jason H
Cook, David A. and Hatala, Rose and Brydges, Ryan and Zendejas, Benjamin and Szostek, Jason H. and Wang, Amy T. and Erwin, Patricia J. and Hamstra, Stanley J. , title =. JAMA , volume =. 2011 , doi =
2011
-
[16]
Computers & Education , volume =
Consorti, Fabrizio and Mancuso, Rosaria and Nocioni, Martina and Piccolo, Annalisa , title =. Computers & Education , volume =. 2012 , doi =
2012
-
[17]
and Tong, Huong Ly and Kocaballi, Ahmet Baki and Chen, Jessica and Bashir, Rabia and Surian, Didi and Gallego, Blanca and Magrabi, Farah and Lau, Annie Y
Laranjo, Liliana and Dunn, Adam G. and Tong, Huong Ly and Kocaballi, Ahmet Baki and Chen, Jessica and Bashir, Rabia and Surian, Didi and Gallego, Blanca and Magrabi, Farah and Lau, Annie Y. S. and Coiera, Enrico , title =. Journal of the American Medical Informatics Association , volume =. 2018 , doi =
2018
-
[18]
2009 , doi =
Pearl, Judea , title =. 2009 , doi =
2009
-
[19]
arXiv preprint arXiv:2303.08774 , year =
-
[20]
Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and others , title =
Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, S. Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and others , title =. Nature , volume =. 2023 , doi =
2023
-
[21]
and Larsson, Staffan , title =
Traum, David R. and Larsson, Staffan , title =. Current and New Directions in Discourse and Dialogue , series =. 2003 , doi =
2003
-
[22]
and Picard, Rosalind W
Bickmore, Timothy W. and Picard, Rosalind W. , title =. ACM Transactions on Computer-Human Interaction , volume =. 2005 , doi =
2005
-
[23]
arXiv preprint arXiv:2602.12450 , year=
Empirical Modeling of Therapist-Client Dynamics in Psychotherapy Using LLM-Based Assessments , author=. arXiv preprint arXiv:2602.12450 , year=
-
[24]
Louie, Ryan and Nandi, Ananjan and Fang, William and Chang, Cheng and Brunskill, Emma and Yang, Diyi. Roleplay-doh: Enabling Domain-Experts to Create LLM -simulated Patients via Eliciting and Adhering to Principles. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.591
-
[25]
Proceedings of the 36th Annual
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual. 2023 , publisher =
2023
-
[26]
and Xiong, Caiming and Socher, Richard , journal =
Keskar, Nitish Shirish and McCann, Bryan and Varshney, Lav R. and Xiong, Caiming and Socher, Richard , journal =. 2019 , url =
2019
-
[27]
Personalizing Dialogue Agents:
Zhang, Saizheng and Dinan, Emily and Urbanek, Jack and Szlam, Arthur and Kiela, Douwe and Weston, Jason , booktitle =. Personalizing Dialogue Agents:. 2018 , publisher =
2018
-
[28]
Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue (
Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey , author =. Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue (. 2021 , publisher =
2021
-
[29]
Psychological Review , volume =
The Role of Deliberate Practice in the Acquisition of Expert Performance , author =. Psychological Review , volume =. 1993 , publisher =
1993
-
[30]
International workshop on intelligent virtual agents , pages=
Virtual patients for clinical therapist skills training , author=. International workshop on intelligent virtual agents , pages=. 2007 , organization=
2007
-
[31]
Journal of medical Internet research , volume=
Development and evaluation of ClientBot: Patient-like conversational agent to train basic counseling skills , author=. Journal of medical Internet research , volume=. 2019 , publisher=
2019
-
[32]
JMIR Medical Education , volume=
Leveraging large language models for simulated psychotherapy client interactions: Development and usability study of client101 , author=. JMIR Medical Education , volume=. 2025 , publisher=
2025
-
[33]
Journal of medical Internet research , volume=
Medical student and tutor perceptions of video versus text in an interactive online virtual patient for problem-based learning: a pilot study , author=. Journal of medical Internet research , volume=. 2015 , publisher=
2015
-
[34]
Partial least squares structural equation modeling (PLS-SEM) using R: a workbook , pages=
An introduction to structural equation modeling , author=. Partial least squares structural equation modeling (PLS-SEM) using R: a workbook , pages=. 2021 , publisher=
2021
-
[35]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Learning discourse-level diversity for neural dialog models using conditional variational autoencoders , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Proceedings of the AAAI conference on artificial intelligence , volume=
A hierarchical latent variable encoder-decoder model for generating dialogues , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[37]
Character- LLM : A Trainable Agent for Role-Playing
Shao, Yunfan and Li, Linyang and Dai, Junqi and Qiu, Xipeng. Character- LLM : A Trainable Agent for Role-Playing. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[38]
Can LLM s Effectively Simulate Human Learners? Teachers' Insights from Tutoring LLM Students
Martynova, Daria and Macina, Jakub and Daheim, Nico and Yalcin, Nilay and Zhang, Xiaoyu and Sachan, Mrinmaya. Can LLM s Effectively Simulate Human Learners? Teachers' Insights from Tutoring LLM Students. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.8
-
[39]
Wang, Noah and Peng, Z.y. and Que, Haoran and Liu, Jiaheng and Zhou, Wangchunshu and Wu, Yuhan and Guo, Hongcheng and Gan, Ruitong and Ni, Zehao and Yang, Jian and Zhang, Man and Zhang, Zhaoxiang and Ouyang, Wanli and Xu, Ke and Huang, Wenhao and Fu, Jie and Peng, Junran. R ole LLM : Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large L...
-
[40]
2024 , eprint=
Measuring and Controlling Instruction (In)Stability in Language Model Dialogs , author=. 2024 , eprint=
2024
-
[41]
P ersona G ym: Evaluating Persona Agents and LLM s
Samuel, Vinay and Zou, Henry Peng and Zhou, Yue and Chaudhari, Shreyas and Kalyan, Ashwin and Rajpurohit, Tanmay and Deshpande, Ameet and Narasimhan, Karthik R and Murahari, Vishvak. P ersona G ym: Evaluating Persona Agents and LLM s. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.368
-
[42]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[43]
Review of Educational Research , volume =
John Hattie and Helen Timperley , title =. Review of Educational Research , volume =. 2007 , doi =
2007
-
[44]
Mcgaghie, William and Issenberg, Barry and Cohen, Elaine and Barsuk, Jeffrey and Wayne, Diane , year =. Does Simulation-Based Medical Education With Deliberate Practice Yield Better Results Than Traditional Clinical Education? A Meta-Analytic Comparative Review of the Evidence , volume =. Academic medicine : journal of the Association of American Medical ...
-
[45]
Journal of Medical Internet Research , author =
Kononowicz, Andrzej A and Woodham, Luke A and Edelbring, Samuel and Stathakarou, Natalia and Davies, David and Saxena, Nakul and Tudor Car, Lorainne and Carlstedt-Duke, Jan and Car, Josip and Zary, Nabil. Virtual Patient Simulations in Health Professions Education: Systematic Review and Meta-Analysis by the Digital Health Education Collaboration. J Med In...
-
[46]
, journal=
Young, Steve and Gašić, Milica and Thomson, Blaise and Williams, Jason D. , journal=. POMDP-Based Statistical Spoken Dialog Systems: A Review , year=
-
[47]
Jacqmin, L \'e o and Rojas Barahona, Lina M. and Favre, Benoit. ``Do you follow me?'': A Survey of Recent Approaches in Dialogue State Tracking. Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2022. doi:10.18653/v1/2022.sigdial-1.33
-
[48]
2025 , eprint=
Adaptive-VP: A Framework for LLM-Based Virtual Patients that Adapts to Trainees' Dialogue to Facilitate Nurse Communication Training , author=. 2025 , eprint=
2025
-
[49]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
A Computational Approach to Understanding Empathy Expressed in Text-Based Mental Health Support , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[50]
2023 , publisher =
Motivational Interviewing: Helping People Change and Grow , author =. 2023 , publisher =
2023
-
[51]
Self-disclosure Topic Model for Classifying and Analyzing
Bak, JinYeong and Lin, Chin-Yew and Oh, Alice , booktitle =. Self-disclosure Topic Model for Classifying and Analyzing. 2014 , pages =
2014
-
[52]
Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems (CHI EA '15) , year =
Detecting and Characterizing Mental Health Related Self-Disclosure in Social Media , author =. Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems (CHI EA '15) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.