Mult-DPO: Multinomial Direct Preference Optimization for Recommender Systems
Pith reviewed 2026-06-27 14:28 UTC · model grok-4.3
The pith
Mult-DPO replaces combinatorial Plackett-Luce marginalization with a multinomial surrogate that upper-bounds the DPO loss for set-wise preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the multinomial DPO loss is a tractable upper bound on the marginalized PL DPO loss for set-wise preference data. The multinomial construction, while not a true ranking distribution, operates on the reward-induced weight space and admits a closed-form DPO-style objective, allowing direct alignment of LLMs with multiple candidates through classification-style training. The tightness of the bound is characterized by the relative total weight of positives versus negatives.
What carries the argument
Multinomial surrogate likelihood over set-wise preference events defined on the reward-induced weight space
If this is right
- The method enables optimization against multiple positive and negative items without exponential complexity from ordering marginalization.
- Extension to multiple preference levels follows directly from the multinomial construction.
- Insights into bound tightness guide the selection of harder negatives to improve alignment quality.
- The closed-form objective supports classification-style training of LLM-based recommenders on set-wise data.
Where Pith is reading between the lines
- Surrogate distributions on reward spaces may suffice for alignment in other domains where exact ranking distributions lead to intractable marginalization.
- The bound-tightening mechanism suggests that deliberately sampling negatives with higher total weight could improve performance in large-scale recommendation tasks.
- This construction could extend to partial ranking feedback in conversational or session-based recommendation without requiring full orderings.
Load-bearing premise
A multinomial surrogate likelihood defined on the reward weight space can serve as a valid stand-in for alignment even though it is not itself a ranking distribution.
What would settle it
On a small candidate set where exact marginalization over positive orderings remains feasible, training with the multinomial loss and verifying whether it always exceeds the true PL loss value while producing comparable downstream ranking quality would test both the bound and its practical utility.
Figures

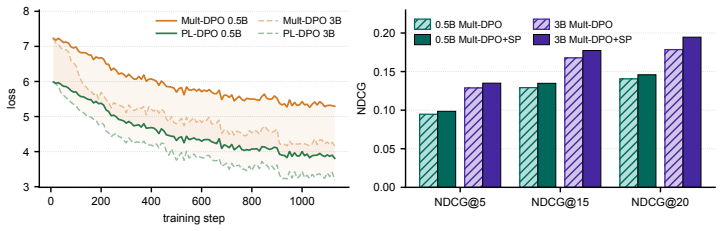
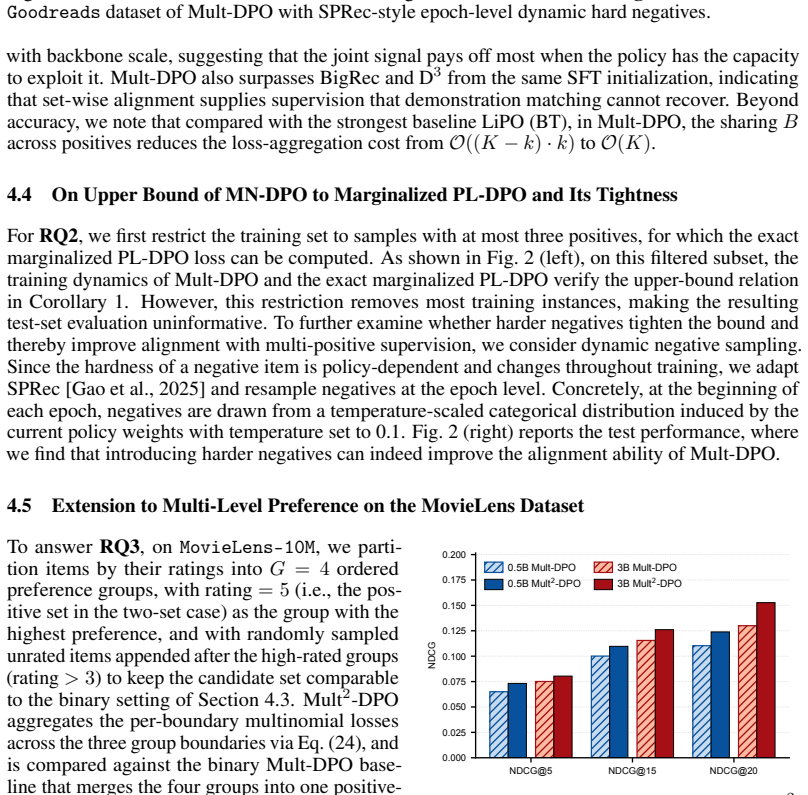
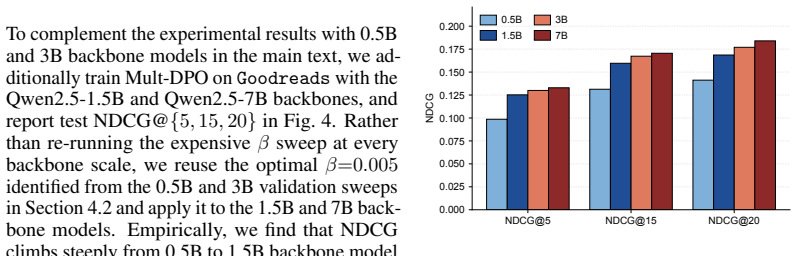
read the original abstract
Direct preference optimization (DPO) is a simple and effective alignment strategy for large language models (LLMs) based on pairwise preferences. In recommender systems, however, user feedback is rarely pairwise. For a given context, e.g., a user, a session, or a conversation, we typically observe set-wise preferences with multiple positive items, where every positive item should outrank every unobserved or explicitly negative item, with no prescribed order among the positives or the negatives themselves. A natural generalization is to use the Plackett-Luce (PL) reward model, which extends the Bradley-Terry reward model underlying vanilla DPO from pairwise preferences to full rankings of candidates. However, we show that adapting the PL model to set-wise preferences requires marginalizing over all positive orderings, where the resulting expression is combinatorial in complexity. To address this fundamental challenge, we propose Mult-DPO, a novel DPO objective with a tractable multinomial surrogate likelihood over set-wise preference events for the user-preference alignment of LLM-based recommender systems. The multinomial construction is not itself a ranking distribution, but it is defined on the same reward-induced weight space and admits a closed-form DPO-style objective, enabling direct alignment of LLMs with multiple candidates through a classification-style objective. In addition, we prove that the multinomial DPO loss is a tractable upper bound on the marginalized PL DPO loss when optimizing against the set-wise preference data. We further characterize the tightness of this bound in terms of the relative total weight of positives versus negatives, which provides insights into tightening the bound with richer or harder negatives. Finally, we extend Mult-DPO to the alignment of LLMs with multiple preference levels. Code is available at https://github.com/yaochenzhu/Mult_DPO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Mult-DPO, a novel objective for direct preference optimization in recommender systems that handles set-wise preferences using a multinomial surrogate likelihood. The authors prove that this loss serves as a tractable upper bound on the marginalized Plackett-Luce DPO loss and characterize the bound's tightness in terms of the relative total weight of positive and negative items. They also extend the method to multiple preference levels and provide open-source code.
Significance. If the upper-bound result holds, the work offers a practical advance for aligning LLM-based recommender systems with set-wise user feedback, replacing intractable PL marginalization with a closed-form classification-style objective while preserving a theoretical guarantee. Explicit credit is due for the derived bound, the tightness characterization, and the released code at https://github.com/yaochenzhu/Mult_DPO, which supports reproducibility.
minor comments (2)
- The abstract states that a proof is provided, but the main text should include an explicit theorem number and statement (e.g., Theorem 3.1) for the upper-bound property to improve traceability.
- [§3] Notation for the multinomial surrogate weights versus the true PL ranking probabilities could be clarified in §3 to avoid any reader confusion between the surrogate and a genuine ranking distribution.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of the upper-bound result and tightness characterization, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The central claim is a mathematical proof that the multinomial DPO loss upper-bounds the marginalized PL DPO loss. The abstract explicitly constructs the surrogate on the shared reward-induced weight space, states it admits a closed form, and characterizes bound tightness via relative positive/negative weights. No step reduces by definition to its inputs, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation or imported uniqueness theorem is invoked. The non-ranking nature of the surrogate is openly acknowledged rather than hidden. The derivation is therefore self-contained and independent of the target result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Plackett-Luce model is the appropriate generalization of Bradley-Terry for full rankings of candidates.
invented entities (1)
-
Multinomial surrogate likelihood
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NeurIPS , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. NeurIPS , volume=
-
[2]
NeurIPS , volume=
Training language models to follow instructions with human feedback , author=. NeurIPS , volume=
-
[3]
JMLR , volume=
Latent dirichlet allocation , author=. JMLR , volume=
-
[4]
NeurIPS , volume=
Deep reinforcement learning from human preferences , author=. NeurIPS , volume=
-
[5]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
ICLR , year=
Statistical rejection sampling improves preference optimization , author=. ICLR , year=
-
[8]
NeurIPS , volume=
Iterative reasoning preference optimization , author=. NeurIPS , volume=
-
[9]
Weyssow, Martin and Kamanda, Aton and Zhou, Xin and Sahraoui, Houari , journal=
-
[10]
AISTATS , pages=
A general theoretical paradigm to understand learning from human preferences , author=. AISTATS , pages=. 2024 , organization=
2024
-
[11]
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , journal=
-
[12]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle=
-
[13]
Wu, Junkang and Xie, Yuexiang and Yang, Zhengyi and Wu, Jiancan and Gao, Jinyang and Ding, Bolin and Wang, Xiang and He, Xiangnan , booktitle=. beta -
-
[14]
Hong, Jiwoo and Lee, Noah and Thorne, James , booktitle=
-
[15]
Contrastive Preference Optimization: Pushing the Boundaries of
Xu, Haoran and Sharaf, Amr and Chen, Yunmo and Tan, Weiting and Shen, Lingfeng and Van Durme, Benjamin and Murray, Kenton and Kim, Young Jin , booktitle=. Contrastive Preference Optimization: Pushing the Boundaries of
-
[16]
ICML , pages=
Token-level Direct Preference Optimization , author=. ICML , pages=. 2024 , organization=
2024
-
[17]
Findings of ACL , pages=
Disentangling length from quality in direct preference optimization , author=. Findings of ACL , pages=
-
[18]
ICML , year=
Generalized Preference Optimization: A Unified Approach to Offline Alignment , author=. ICML , year=
-
[19]
A comprehensive survey of
Wang, Zhichao and Bi, Bin and Pentyala, Shiva Kumar and Ramnath, Kiran and Chaudhuri, Sougata and Mehrotra, Shubham and Mao, Xiang-Bo and Asur, Sitaram and others , journal=. A comprehensive survey of
-
[20]
WWW , pages=
Embarrassingly shallow autoencoders for sparse data , author=. WWW , pages=
-
[21]
AAAI , volume=
Preference ranking optimization for human alignment , author=. AAAI , volume=
-
[22]
Liu, Tianqi and Qin, Zhen and Wu, Junru and Shen, Jiaming and Khalman, Misha and Joshi, Rishabh and Zhao, Yao and Saleh, Mohammad and Baumgartner, Simon and Liu, Jialu and others , booktitle=
-
[23]
Yuan, Hongyi and Yuan, Zheng and Tan, Chuanqi and Wang, Wei and Huang, Songfang and Huang, Fei , booktitle=
-
[24]
Zhao, Yao and Joshi, Rishabh and Liu, Tianqi and Khalman, Misha and Saleh, Mohammad and Liu, Peter J , journal=
-
[25]
Findings of ACL , pages=
K-order ranking preference optimization for large language models , author=. Findings of ACL , pages=
-
[26]
NeurIPS , volume=
On softmax direct preference optimization for recommendation , author=. NeurIPS , volume=
-
[27]
CIKM , pages=
Aligning large language model with direct multi-preference optimization for recommendation , author=. CIKM , pages=
-
[28]
Gao, Chongming and Chen, Ruijun and Yuan, Shuai and Huang, Kexin and Yu, Yuanqing and He, Xiangnan , booktitle=
-
[29]
Bao, Keqin and Zhang, Jizhi and Zhang, Yang and Wang, Wenjie and Feng, Fuli and He, Xiangnan , booktitle=
-
[30]
ACM Transactions on Recommender Systems , volume=
A bi-step grounding paradigm for large language models in recommendation systems , author=. ACM Transactions on Recommender Systems , volume=
-
[31]
Liao, Jiayi and Li, Sihang and Yang, Zhengyi and Wu, Jiancan and Yuan, Yancheng and Wang, Xiang and He, Xiangnan , booktitle=
-
[32]
ACM Transactions on Information Systems , volume=
Recommendation as instruction following: A large language model empowered recommendation approach , author=. ACM Transactions on Information Systems , volume=
-
[33]
CIKM , pages=
Large language models as zero-shot conversational recommenders , author=. CIKM , pages=
-
[34]
WWW , pages=
Collaborative large language model for recommender systems , author=. WWW , pages=
-
[35]
WWW , pages=
Collaborative retrieval for large language model-based conversational recommender systems , author=. WWW , pages=
-
[36]
Zhu, Yaochen and Steck, Harald and Liang, Dawen and He, Yinhan and Ostuni, Vito and Li, Jundong and Kallus, Nathan , booktitle=
-
[37]
The method of paired comparisons , author=
Rank analysis of incomplete block designs: I. The method of paired comparisons , author=. Biometrika , volume=
-
[38]
Journal of the Royal Statistical Society Series C , volume=
The analysis of permutations , author=. Journal of the Royal Statistical Society Series C , volume=
-
[39]
1959 , publisher=
Individual Choice Behavior , author=. 1959 , publisher=
1959
-
[40]
WWW , pages=
Variational autoencoders for collaborative filtering , author=. WWW , pages=
-
[41]
ICDM , pages=
Self-attentive sequential recommendation , author=. ICDM , pages=
-
[42]
Rendle, Steffen and Freudenthaler, Christoph and Gantner, Zeno and Schmidt-Thieme, Lars , booktitle=
-
[43]
Harper, F Maxwell and Konstan, Joseph A , journal=. The
-
[44]
NeurIPS , year=
Towards deep conversational recommendations , author=. NeurIPS , year=
-
[45]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
ECIR , year=
Large language models are zero-shot rankers for recommender systems , author=. ECIR , year=
-
[47]
Recommendation as language processing (
Geng, Shijie and Liu, Shuchang and Fu, Zuohui and Ge, Yingqiang and Zhang, Yongfeng , booktitle=. Recommendation as language processing (
-
[48]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and others , journal=
-
[49]
Lin, Jiacheng and Wang, Tian and Qian, Kun , journal=
-
[50]
EMNLP , year=
Towards knowledge-based recommender dialog system , author=. EMNLP , year=
-
[51]
KDD , pages=
Improving conversational recommender systems via knowledge graph based semantic fusion , author=. KDD , pages=
-
[52]
KDD , pages=
Towards unified conversational recommender systems via knowledge-enhanced prompt learning , author=. KDD , pages=
-
[53]
Cui, Zeyu and Ma, Jianxin and Zhou, Chang and Zhou, Jingren and Yang, Hongxia , journal=
-
[54]
ACM Transactions on Information Systems , year=
How can recommender systems benefit from large language models: A survey , author=. ACM Transactions on Information Systems , year=
-
[55]
How to index item
Hua, Wenyue and Xu, Shuyuan and Ge, Yingqiang and Zhang, Yongfeng , booktitle=. How to index item
-
[56]
NeurIPS , volume=
Learning to summarize with human feedback , author=. NeurIPS , volume=
-
[57]
arXiv preprint arXiv:2307.12966 , year=
Aligning large language models with human: A survey , author=. arXiv preprint arXiv:2307.12966 , year=
-
[58]
Wu, Junda and Chang, Cheng-Chun and Yu, Tong and He, Zhankui and Wang, Jianing and Hou, Yupeng and McAuley, Julian , booktitle=
-
[59]
RecSys , pages=
Towards open-world recommendation with knowledge augmentation from large language models , author=. RecSys , pages=
-
[60]
WWW , pages=
Representation learning with large language models for recommendation , author=. WWW , pages=
-
[61]
Zhang, Yang and Feng, Fuli and Zhang, Jizhi and Bao, Keqin and Wang, Qifan and He, Xiangnan , journal=
-
[62]
ICDE , pages=
Adapting large language models by integrating collaborative semantics for recommendation , author=. ICDE , pages=
-
[63]
World Wide Web , volume=
A survey on large language models for recommendation , author=. World Wide Web , volume=
-
[64]
RecSys , year=
Item recommendation on monotonic behavior chains , author=. RecSys , year=
-
[65]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle=
-
[66]
ICLR , year=
Decoupled weight decay regularization , author=. ICLR , year=
-
[67]
Decoding matters: Addressing amplification bias and homogeneity issue for
Bao, Keqin and Zhang, Jizhi and Zhang, Yang and Huo, Xinyue and Chen, Chong and Feng, Fuli , booktitle=. Decoding matters: Addressing amplification bias and homogeneity issue for
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.