VFUSE: Virulent Feature Understanding with Sparse autoEncoders
Pith reviewed 2026-06-27 16:55 UTC · model grok-4.3
The pith
Sparse autoencoders on protein model activations identify monosemantic features specific to hazardous designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
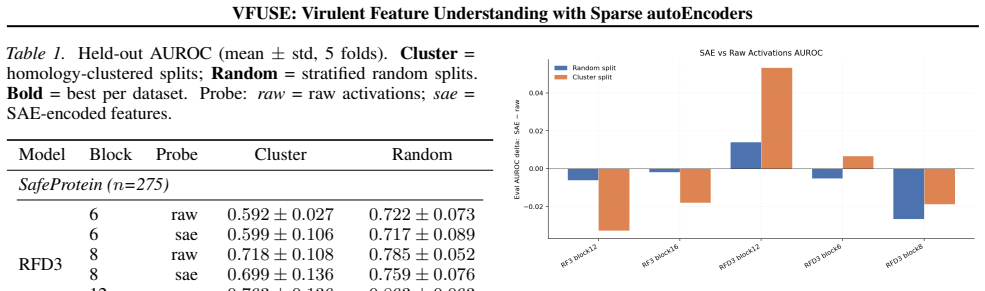
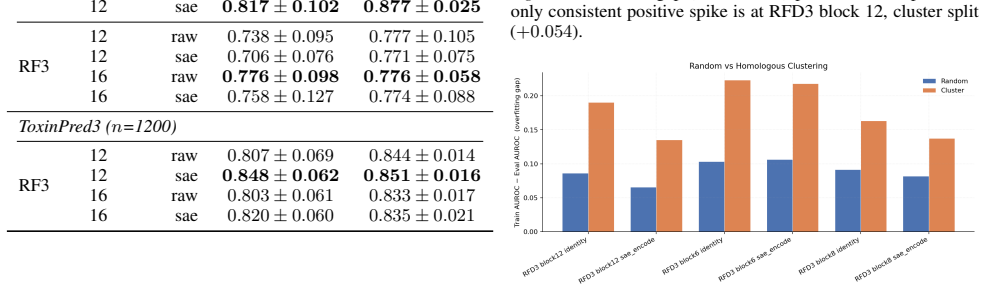
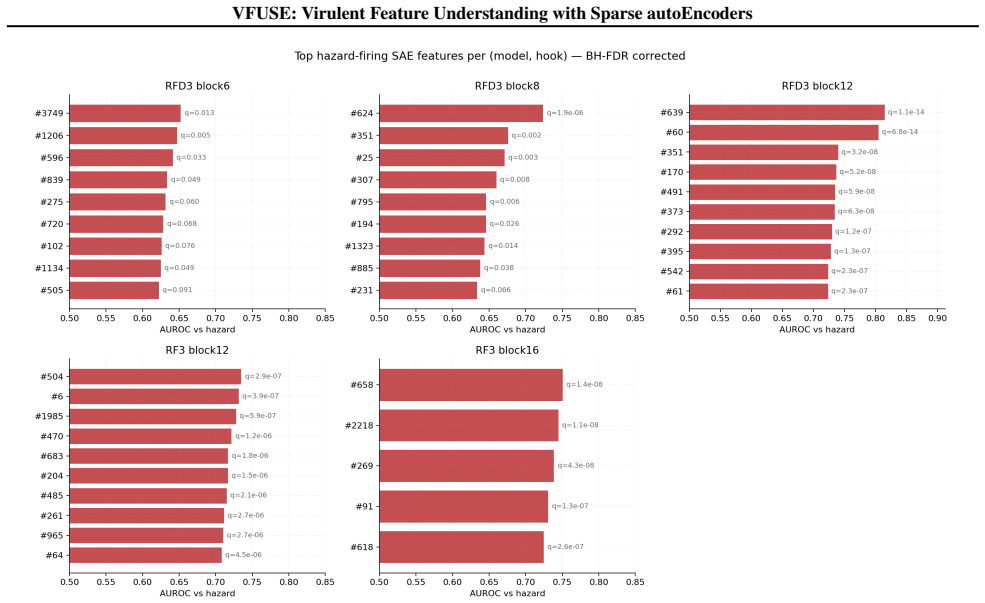
VFUSE trains sparse autoencoders on diffusion-transformer activations to audit protein models for hazard-aware features. For certain blocks, linear probes detect hazardous designs significantly better when fit in the SAE latent space over the original model's representations. The approach also identifies monosemantic features from the SAE that fire only on hazardous designs at up to AUROC 0.84.
What carries the argument
Sparse autoencoders trained on diffusion-transformer activations to extract monosemantic features for auditing virulence in protein design models.
If this is right
- Linear probes detect hazardous designs significantly better when fit in the SAE latent space over the original model's representations.
- Monosemantic features from the SAE fire only on hazardous designs at up to AUROC 0.84.
- The SAE approach improves interpretability on all-atom diffusion models without sacrificing model performance.
- This constitutes the first feature-level virulence audit of a protein design model.
Where Pith is reading between the lines
- If these features prove causal, targeted edits to the SAE latents might suppress generation of hazardous proteins.
- The technique could extend to auditing generative models in other domains for safety-related features.
- Validation on broader sets of designs might allow the method to guide safety filters in protein design pipelines.
Load-bearing premise
The labeled hazardous designs used for probing and feature analysis are both representative and correctly classified, and that improved linear probe performance in SAE space reflects genuine mechanistic understanding rather than dataset artifacts.
What would settle it
A held-out test set of protein designs where linear probes trained on SAE latents show no significant improvement over probes trained on original activations, or where the high-AUROC SAE features activate at comparable rates on non-hazardous designs.
Figures


read the original abstract
Generative models have shown remarkable progress in a variety of domains such as protein design, but such power enables the opaque generation of hazardous proteins. In this work, we introduce VFUSE (Virulent Feature Understanding with Sparse autoEncoders), a mechanistic interpretability approach that trains SAEs on diffusion-transformer activations to audit protein models for hazard-aware features. We apply VFUSE to RoseTTAFold3 and RFDiffusion3, popular open-weight models for protein folding and synthesis. We find that for certain blocks, linear probes detect hazardous designs significantly better when fit in the SAE latent space over the original model's representations: improving interpretability without sacrificing model performance. Furthermore, we identify monosemantic features from the SAE that fire only on hazardous designs at up to AUROC $0.84$ ($q < 10^{-13}$). To our knowledge this is the first SAE trained on an all-atom diffusion model and the first feature-level virulence audit of a protein design model, paving the way towards safe and interpretable protein design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VFUSE, a method that trains sparse autoencoders (SAEs) on activations from diffusion-transformer components of protein design models (RoseTTAFold3 and RFDiffusion3) to identify monosemantic, hazard-aware features. It reports that linear probes for hazardous vs. non-hazardous designs achieve higher performance when trained in SAE latent space than in the original model representations, and identifies individual SAE features that fire selectively on hazardous designs with AUROC up to 0.84 (q < 10^{-13}). The work positions itself as the first SAE application to an all-atom diffusion model and the first feature-level virulence audit of such models.
Significance. If the quantitative claims hold after addressing label validation, the result would be moderately significant for mechanistic interpretability in generative biology: it demonstrates that SAE latents can surface more interpretable signals for a safety-relevant downstream task without apparent loss in probe accuracy, and supplies the first concrete example of monosemantic features tied to virulence in diffusion-based protein generators. This could inform auditing pipelines, though the absolute performance numbers remain modest and the approach has not yet been shown to generalize beyond the specific models and label set examined.
major comments (3)
- [Abstract and §3] Abstract and §3 (Methods): the binary hazardous/non-hazardous labels used for both the linear-probe AUROC comparisons and the monosemantic-feature AUROC calculations lack any reported provenance, inter-rater reliability, external validation (e.g., sequence similarity to known toxins, experimental assays, or expert curation), or description of how they were generated. Because every reported statistic (probe AUROC gains, feature AUROC 0.84, q < 10^{-13}) is computed against these labels, the absence of validation is load-bearing; if labels were produced by a simple computational filter already correlated with the diffusion-transformer activations, the SAE could merely sparsify that same signal rather than reveal genuine mechanistic hazard understanding.
- [§4] §4 (Results) and any supplementary tables reporting AUROC/q-values: no description is given of the train/test splits used for the linear probes, whether the same data were used to select the reported SAE features, or any correction for multiple testing across the large number of SAE latents examined. Without these details it is impossible to assess whether the reported q < 10^{-13} reflects genuine feature selectivity or post-hoc selection bias.
- [§2 and §3] §2 (Background) and §3: the manuscript supplies no equations or pseudocode for the SAE training objective, the precise definition of the diffusion-transformer activations being reconstructed, or the criteria used to declare a feature “monosemantic.” This prevents evaluation of whether the reported probe improvement is an artifact of the SAE fitting procedure itself.
minor comments (2)
- [Figures] Figure captions and axis labels should explicitly state the number of hazardous and non-hazardous designs in each evaluation set and whether the AUROC values are computed on held-out data.
- [Abstract and §4] The claim that the approach improves “interpretability without sacrificing model performance” should be supported by a quantitative comparison of original-model vs. SAE-probe accuracy on the same held-out set, not merely a qualitative statement.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the clarity and rigor of our manuscript. We address each major comment point-by-point below and will incorporate revisions to address the identified gaps.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): the binary hazardous/non-hazardous labels used for both the linear-probe AUROC comparisons and the monosemantic-feature AUROC calculations lack any reported provenance, inter-rater reliability, external validation (e.g., sequence similarity to known toxins, experimental assays, or expert curation), or description of how they were generated. Because every reported statistic (probe AUROC gains, feature AUROC 0.84, q < 10^{-13}) is computed against these labels, the absence of validation is load-bearing; if labels were produced by a simple computational filter already correlated with the diffusion-transformer activations, the SAE could merely sparsify that same signal rather than reveal genuine mechanistic hazard understanding.
Authors: We agree that the provenance and validation details for the hazardous/non-hazardous labels must be explicitly reported. In the revised manuscript we will add a dedicated paragraph in §3 describing the exact procedure used to generate the labels (including any computational filters or curation steps) along with available supporting evidence such as sequence similarity checks against known toxins. This addition will allow readers to evaluate the extent to which the reported SAE features reflect mechanistic signals versus label-generation artifacts. revision: yes
-
Referee: [§4] §4 (Results) and any supplementary tables reporting AUROC/q-values: no description is given of the train/test splits used for the linear probes, whether the same data were used to select the reported SAE features, or any correction for multiple testing across the large number of SAE latents examined. Without these details it is impossible to assess whether the reported q < 10^{-13} reflects genuine feature selectivity or post-hoc selection bias.
Authors: We acknowledge that these experimental and statistical details were omitted. The revised §4 and supplementary material will specify the train/test split protocol for the linear probes, clarify whether SAE feature selection occurred on held-out data, and document the multiple-testing correction procedure (including the exact method and adjusted significance thresholds) applied to the q-values. revision: yes
-
Referee: [§2 and §3] §2 (Background) and §3: the manuscript supplies no equations or pseudocode for the SAE training objective, the precise definition of the diffusion-transformer activations being reconstructed, or the criteria used to declare a feature “monosemantic.” This prevents evaluation of whether the reported probe improvement is an artifact of the SAE fitting procedure itself.
Authors: We will expand §2 and §3 to include the full SAE training objective (with equations), pseudocode for the training loop, the exact layer and token positions from which diffusion-transformer activations are extracted, and the quantitative criteria (sparsity level, selectivity threshold, and any additional metrics) used to designate a feature as monosemantic. revision: yes
Circularity Check
No significant circularity; SAE training and label-based evaluation remain independent.
full rationale
The paper trains SAEs in an unsupervised manner on diffusion-transformer activations from RoseTTAFold3 and RFDiffusion3, then computes linear probe AUROCs and identifies monosemantic features by their correlation with separately provided hazardous/non-hazardous labels. No equations, fitting procedures, or self-citations are described that would make the reported AUROC 0.84 or the probe improvement reduce to the SAE inputs or labels by construction. The derivation chain is self-contained: unsupervised sparsity objective on activations is distinct from post-hoc supervised evaluation against external labels, satisfying the criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Hume, Tristan and Carter, Shan and Henighan, Tom and Olah, Christopher , title =
Bricken, Trenton and Templeton, Adly and Batson, Joshua and Chen, Brian and Jermyn, Adam and Conerly, Tom and Turner, Nick and Anil, Cem and Denison, Carson and Askell, Amanda and Lasenby, Robert and Wu, Yifan and Kravec, Shauna and Schiefer, Nicholas and Maxwell, Tim and Joseph, Nicholas and Hatfield-Dodds, Zac and Tamkin, Alex and Nguyen, Karina and McL...
-
[2]
Journal of Molecular Biology , volume =
A Brief History of De Novo Protein Design: Minimal, Rational, and Computational , author =. Journal of Molecular Biology , volume =. 2021 , month = oct, doi =
2021
-
[3]
CVPR 2025 Workshop on Mechanistic Interpretability in Vision (MIV) , year =
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video , author =. CVPR 2025 Workshop on Mechanistic Interpretability in Vision (MIV) , year =. 2504.19475 , archivePrefix =
-
[4]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , author =. Workshop at the International Conference on Learning Representations (ICLR) , year =. 1312.6034 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
Ben Melech Stan, Gabriela and Aflalo, Estelle and Rohekar, Raanan Yehezkel and Bhiwandiwalla, Anahita and Tseng, Shao-Yen and Olson, Matthew Lyle and Gurwicz, Yaniv and Wu, Chenfei and Duan, Nan and Lal, Vasudev , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =. 2024 , pages =
2024
-
[6]
Makhzani, Alireza and Frey, Brendan , title =. International Conference on Learning Representations , year =. 1312.5663 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher , title =. Transformer Circuits Thread , year =...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , title =. International Conference on Learning Representations , year =. 2309.08600 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Transformer Circuits Thread , year =
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jermyn, Adam and Olsson, Catherine and Gopal, Anand and Hauksson, Yahoshua and Hatfield-Dodds, Zac and Schiefer, Nicholas and Brown, Tom and Kaplan, Jared and Batson, Joshua and Chughtai, ...
-
[10]
Improving Sparse Decomposition of Language Model Activations with Gated Sparse Autoencoders , booktitle =
Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Lieberum, Tom and Varma, Vikrant and Kram\'. Improving Sparse Decomposition of Language Model Activations with Gated Sparse Autoencoders , booktitle =. 2024 , eprint =
2024
-
[11]
Scaling and Evaluating Sparse Autoencoders , booktitle =
Gao, Leo and Dupr\'. Scaling and Evaluating Sparse Autoencoders , booktitle =. 2025 , eprint =
2025
-
[12]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Rajamanoharan, Senthooran and Lieberum, Tom and Sonnerat, Nicolas and Conmy, Arthur and Varma, Vikrant and Kram\'. Jumping Ahead: Improving Reconstruction Fidelity with. arXiv preprint arXiv:2407.14435 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
NeurIPS Workshop on Attributing Model Behavior at Scale , year =
Bussmann, Bart and Leask, Patrick and Nanda, Neel , title =. NeurIPS Workshop on Attributing Model Behavior at Scale , year =. 2412.06410 , archivePrefix =
-
[14]
ICLR Workshop on Building Trust in Language Models and Applications , year =
Bussmann, Bart and Nabeshima, Noa and Karvonen, Adam and Nanda, Neel , title =. ICLR Workshop on Building Trust in Language Models and Applications , year =. 2503.17547 , archivePrefix =
-
[15]
Highly accurate protein structure prediction with
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and. Highly accurate protein structure prediction with. Nature , volume =
-
[16]
Science , volume =
Lin, Zeming and Akin, Halil and Rao, Roshan and Hie, Brian and Zhu, Zhongkai and Lu, Wenting and Smetanin, Nikita and Verkuil, Robert and Kabeli, Ori and Shmueli, Yaniv and dos Santos Costa, Allan and Fazel-Zarandi, Maryam and Sercu, Tom and Candido, Salvatore and Rives, Alexander , title =. Science , volume =
-
[17]
and Juergens, David and Bennett, Nathaniel R
Watson, Joseph L. and Juergens, David and Bennett, Nathaniel R. and Trippe, Brian L. and Yim, Jason and Eisenach, Helen E. and Ahern, Woody and Borst, Andrew J. and Ragotte, Robert J. and Milles, Lukas F. and Wicky, Basile I. M. and Hanikel, Nikita and Pellock, Samuel J. and Courbet, Alexis and Sheffler, William and Wang, Jue and Venkatesh, Preetham and S...
-
[18]
and Anishchenko, Ivan and Humphreys, Ian R
Krishna, Rohith and Wang, Jue and Ahern, Woody and Sturmfels, Pascal and Venkatesh, Preetham and Kalvet, Indrek and Lee, Gyu Rie and Morey-Burrows, Felix S. and Anishchenko, Ivan and Humphreys, Ian R. and McHugh, Ryan and Vafeados, Dionne and Li, Xinting and Sutherland, George A. and Hitchcock, Andrew and Hunter, C. Neil and Kang, Alex and Brackenbrough, ...
-
[19]
and Bambrick, Joshua and Bodenstein, Sebastian W
Abramson, Josh and Adler, Jonas and Dunger, Jack and Evans, Richard and Green, Tim and Pritzel, Alexander and Ronneberger, Olaf and Willmore, Lindsay and Ballard, Andrew J. and Bambrick, Joshua and Bodenstein, Sebastian W. and Evans, David A. and Hung, Chia-Chun and O'Neill, Michael and Reiman, David and Tunyasuvunakool, Kathryn and Wu, Zachary and Bapst,...
-
[20]
Butcher, Jasper and Krishna, Rohith and Mitra, Raktim and Brent, Rafael I. and Li, Yanjing and Corley, Nathaniel and Kim, Paul and Funk, Jonathan and Mathis, Simon and Salike, Saman and Muraishi, Aiko and Eisenach, Helen and Thompson, Tuscan Rock and Chen, Jie and Politanska, Yuliya and Sehgal, Enisha and Coventry, Brian and Zhang, Odin and Qiang, Bo and ...
-
[21]
and Milles, Lukas F
Dauparas, Justas and Anishchenko, Ivan and Bennett, Nathaniel and Bai, Hua and Ragotte, Robert J. and Milles, Lukas F. and Wicky, Basile I. M. and Courbet, Alexis and de Haas, Rob J. and Bethel, Neville and Leung, Philip J. Y. and Huddy, Timothy F. and Pellock, Sam and Tischer, Doug and Chan, Frederick and Koepnick, Brian and Nguyen, Hannah and Kang, Alex...
-
[22]
Biopolymers , volume =
Kabsch, Wolfgang and Sander, Christian , title =. Biopolymers , volume =
-
[23]
and Tumescheit, Charlotte and Mirdita, Milot and Lee, Jeongjae and Gilchrist, Cameron L
van Kempen, Michel and Kim, Stephanie S. and Tumescheit, Charlotte and Mirdita, Milot and Lee, Jeongjae and Gilchrist, Cameron L. M. and S\"oding, Johannes and Steinegger, Martin , title =. Nature Biotechnology , volume =
-
[24]
Nature Methods , volume =
Simon, Elana and Zou, James , title =. Nature Methods , volume =. 2025 , doi =
2025
-
[25]
International Conference on Machine Learning , year =
Adams, Etowah and Bai, Liam and Lee, Minji and Yu, Yiyang and AlQuraishi, Mohammed , title =. International Conference on Machine Learning , year =
-
[26]
Parsan, Nithin and Yang, David J. and Yang, John J. , title =. ICLR Workshop on Generative and Experimental Perspectives for Biomolecular Design , year =. 2503.08764 , archivePrefix =
-
[27]
dictionary
Marks, Samuel and Karvonen, Adam and Mueller, Aaron , year =. dictionary
-
[28]
BMC Bioinformatics , volume =
Garg, Aarti and Gupta, Dinesh , title =. BMC Bioinformatics , volume =
-
[29]
Computers in Biology and Medicine , volume =
Singh, Shreya and Le, Nguyen Quoc Khanh and Wang, Cheng , title =. Computers in Biology and Medicine , volume =
-
[30]
Genes , volume =
Sun, Jiawei and Yin, Hongbo and Ju, Chenxiao and Wang, Yongheng and Yang, Zhiyuan , title =. Genes , volume =
-
[31]
Briefings in Bioinformatics , volume =
Chen, Chen and Xu, Yong and Ouyang, Jian and Xiong, Xiangyi and. Briefings in Bioinformatics , volume =
-
[32]
Advances in Neural Information Processing Systems , year =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , title =. Advances in Neural Information Processing Systems , year =
-
[33]
Classifier-Free Diffusion Guidance
Ho, Jonathan and Salimans, Tim , title =. arXiv preprint arXiv:2207.12598 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Nature Biotechnology , volume =
Steinegger, Martin and S\". Nature Biotechnology , volume =
-
[35]
Journal of the Royal Statistical Society: Series B , volume =
Benjamini, Yoav and Hochberg, Yosef , title =. Journal of the Royal Statistical Society: Series B , volume =
-
[36]
and Whitney, Donald R
Mann, Henry B. and Whitney, Donald R. , title =. Annals of Mathematical Statistics , volume =
-
[37]
Nucleic Acids Research , volume =
-
[38]
NeurIPS Workshop on Biosafe GenAI , year =
Fan, Jigang and Zhou, Zhenghong and Zhang, Zaixi and Jin, Ruofan and Cong, Le and Wang, Mengdi , title =. NeurIPS Workshop on Biosafe GenAI , year =
-
[39]
FoldSAE: Learning to Steer Protein Folding Through Sparse Representations
Zarzecki, Wojciech and Szymczak, Paulina and Szczurek, Ewa and Deja, Kamil , title =. arXiv preprint arXiv:2511.22519 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Gorton, Liv and Wang, Nicholas and Nguyen, Nam and Deng, Myra and Ho, Eric and Balsam, Daniel and McGrath, Thomas , title =. Goodfire Research , year =. doi:10.5281/zenodo.14895891 , url =
-
[41]
arXiv preprint arXiv:2502.04382 , year =
Movva, Rajiv and Peng, Kenny and Garg, Nikhil and Kleinberg, Jon and Pierson, Emma , title =. arXiv preprint arXiv:2502.04382 , year =
-
[42]
Steering Language Models With Activation Engineering
Turner, Alex and Thiergart, Lisa and Udell, David and Leech, Gavin and Mini, Ulisse and MacDiarmid, Monte , title =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems , year =
Li, Kenneth and Patel, Oam and Vi\'egas, Fernanda and Pfister, Hanspeter and Wattenberg, Martin , title =. Advances in Neural Information Processing Systems , year =
-
[44]
Goodfire Research , year =
Hazra, Dron and Bissell, Mark and Balsam, Daniel and Kolluru, Adeesh and McGrath, Delia and Colindres, Jorge , title =. Goodfire Research , year =
-
[45]
Rathore, Anand Singh and Choudhury, Shubham and Arora, Akanksha and Tijare, Purva and Raghava, Gajendra P. S. , title =. Computers in Biology and Medicine , volume =
-
[46]
Nucleic Acids Research , volume =
Liu, Bo and Zheng, Dandan and Jin, Qi and Chen, Lihong and Yang, Jian , title =. Nucleic Acids Research , volume =
-
[47]
ICML Workshop on Mechanistic Interpretability , year =
Karvonen, Adam and Wright, Benjamin and Rager, Can and Angell, Rico and Brinkmann, Jannik and Smith, Logan and Mayrink Verdun, Claudio and Bau, David and Marks, Samuel , title =. ICML Workshop on Mechanistic Interpretability , year =
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Probing the representational power of sparse autoencoders in vision models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[49]
bioRxiv , year=
Accelerating biomolecular modeling with atomworks and rf3 , author=. bioRxiv , year=
-
[50]
Nature Methods , pages=
Atomic context-conditioned protein sequence design using LigandMPNN , author=. Nature Methods , pages=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.