Multi-channel Optical Vision Model
Pith reviewed 2026-06-27 15:06 UTC · model grok-4.3
The pith
Spatially multiplexed optical channels function as independent learners, structured code dimensions, and interacting feature groups in a programmable free-space processor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
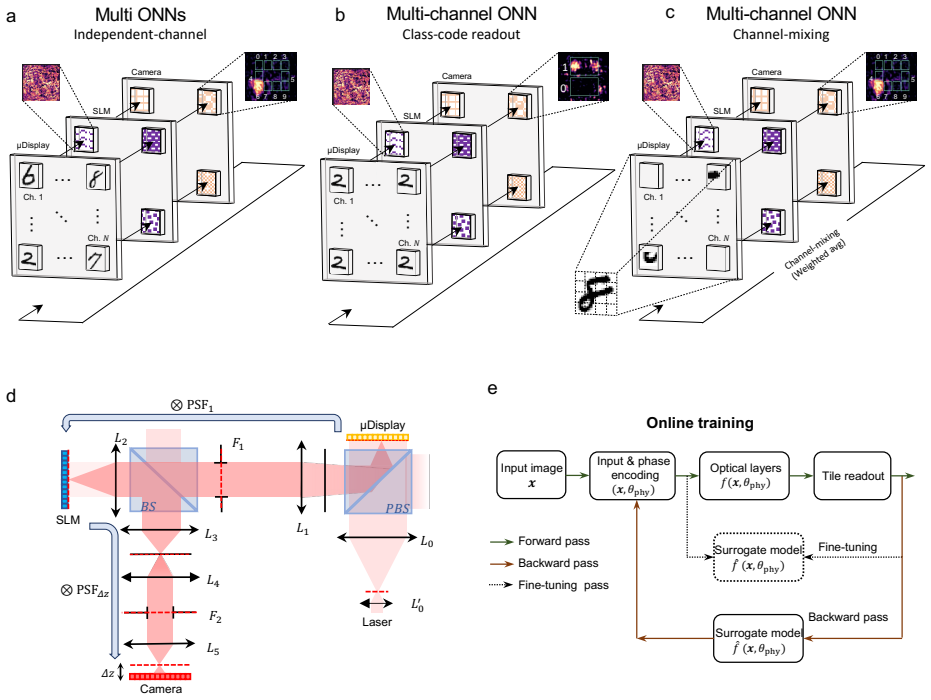
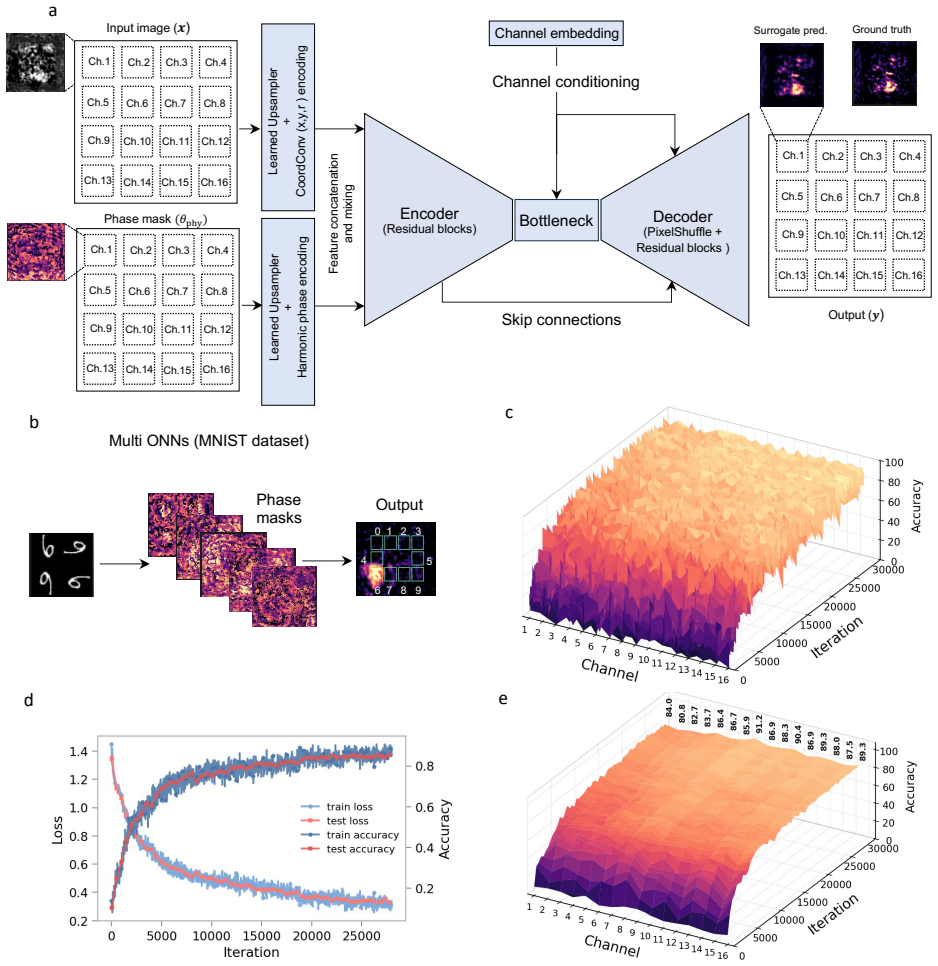
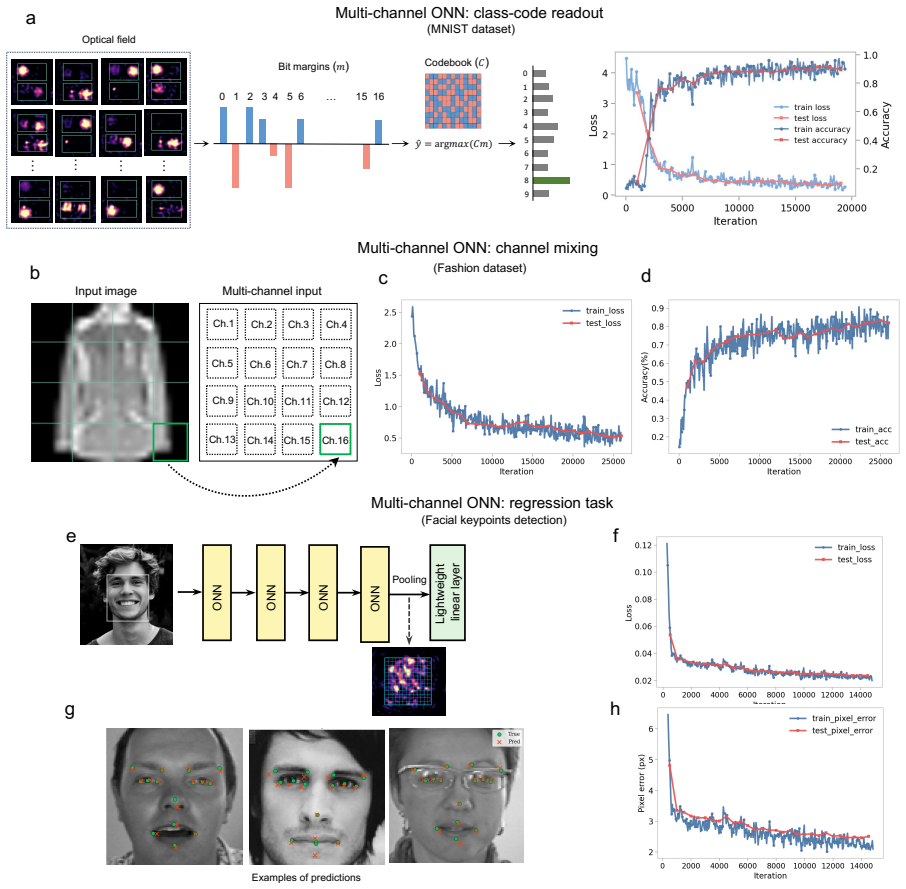
Spatial multiplexing in an optical neural network can be used not only to process multiple inputs in parallel but also to define a trainable representational coordinate of the model; in three implemented scenarios parallel-input processing, class-code readout and channel-mixed feature interaction allow the channels to act as independent learners, structured code dimensions, and interacting feature groups inside a programmable free-space optical processor trained through an online physical-forward/surrogate-backward scheme.
What carries the argument
The programmable free-space optical processor whose spatial channels are assigned the roles of independent learners, code dimensions or interacting feature groups, with measured optical outputs supplying the forward pass and a continually fine-tuned surrogate supplying gradients.
If this is right
- Parallel optical channels can be trained as independent learners for simultaneous processing of multiple inputs.
- Channels can be structured as dimensions of a class code whose readout directly yields classification or regression outputs.
- Channel-mixed interactions allow feature groups to be learned within the same optical layer stack.
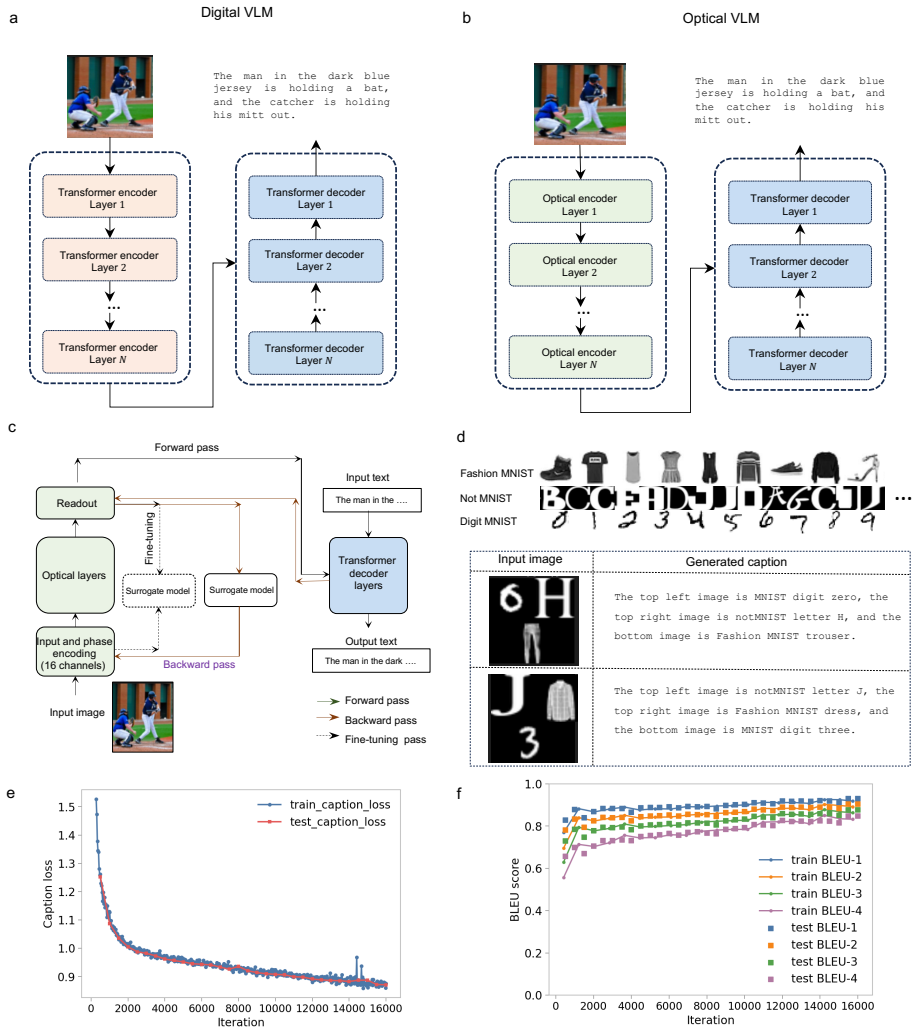
- The optical processor can supply visual tokens to a digital transformer decoder, enabling hybrid models for controlled image captioning.
- The same multi-layer architecture with over one million phase parameters supports both standalone vision tasks and the hybrid captioning pipeline.
Where Pith is reading between the lines
- If the surrogate remains reliable under continual online updates, the approach could support adaptive optical hardware that retrains on streaming real-world data without periodic full recalibration.
- The channel-role separation suggests a route to factorized optical models in which different spatial regions are optimized for distinct computational subtasks rather than uniform parallel replication.
- Extending the same multiplexing logic to other wave-based processors might allow analogous role assignments in acoustic or microwave systems for sensor fusion tasks.
Load-bearing premise
The surrogate model used for gradient estimation remains sufficiently accurate throughout training even as the physical optical hardware evolves and new data is acquired online.
What would settle it
A sustained rise in surrogate-prediction error relative to measured optical outputs that causes the learned phase configurations to produce classification or regression performance no better than an untrained processor after continued fine-tuning.
Figures
read the original abstract
Spatial multiplexing is one of the natural strengths of optics, yet in optical neural networks, it is often used mainly as parallel throughput. Here, we show that spatial multiplexing in an optical neural network can be used not only to process multiple inputs in parallel, but also to define a trainable representational coordinate of the model. In three implemented scenarios, parallel-input processing, class-code readout and channel-mixed feature interaction, spatial channels act as independent learners, structured code dimensions, and interacting feature groups. The programmable free-space optical processor is trained through an online physical-forward/surrogate-backward scheme, where measured optical outputs define the forward pass while a differentiable surrogate estimates gradients and is continually fine-tuned during training from newly acquired optical data. We demonstrate these channel roles in image classification and regression tasks using multi-layer architectures with more than one million trainable optical phase parameters. We further implement a hybrid optical-electronic vision-language model, in which the optical neural network provides visual tokens to a digital transformer decoder for controlled image-captioning tasks. These results establish spatially multiplexed optical channels as a programmable feature and readout space for hybrid optical vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that spatial multiplexing in a programmable free-space optical processor can define trainable representational coordinates, allowing channels to function as independent learners, structured code dimensions, and interacting feature groups. This is demonstrated in image classification, regression, and a hybrid optical-electronic vision-language model for captioning, using an online physical-forward/surrogate-backward training scheme on architectures with >1M trainable optical phase parameters.
Significance. If the results hold with robust validation, the work would establish spatially multiplexed channels as a programmable feature and readout space for hybrid optical vision models, extending optical neural networks beyond parallel throughput by leveraging physical forward passes as an external benchmark. The approach could influence hybrid optical-electronic computing for vision tasks.
major comments (2)
- [Training procedure] Training procedure (described in the methods and abstract): The central claim of successfully training >1M phase parameters to realize the three channel roles rests on the surrogate model providing accurate gradient estimates during online fine-tuning from measured optical data. No analysis, bounds, or experiments are presented demonstrating that surrogate approximation error remains controlled as the physical hardware drifts or the training distribution shifts, which directly affects whether the learned phase configurations correspond to the claimed functionalities.
- [Experimental results] Experimental results section: The demonstrations on classification, regression, and captioning tasks report successful outcomes but include no quantitative error bars, ablation studies on channel count or surrogate accuracy, or controls for drift, making it impossible to evaluate the robustness of the multi-channel roles or the hybrid model performance.
minor comments (2)
- [Methods] Notation for the surrogate model and phase parameters could be clarified with explicit definitions early in the methods to aid reproducibility.
- [Figures] Figure captions for the optical processor setup should include more detail on the spatial multiplexing implementation to support the channel role claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point-by-point below, providing the strongest honest defense while committing to revisions where the manuscript is lacking.
read point-by-point responses
-
Referee: [Training procedure] Training procedure (described in the methods and abstract): The central claim of successfully training >1M phase parameters to realize the three channel roles rests on the surrogate model providing accurate gradient estimates during online fine-tuning from measured optical data. No analysis, bounds, or experiments are presented demonstrating that surrogate approximation error remains controlled as the physical hardware drifts or the training distribution shifts, which directly affects whether the learned phase configurations correspond to the claimed functionalities.
Authors: The online scheme continually fine-tunes the surrogate from fresh optical measurements, which in practice adapts to hardware drift and distribution shifts by updating the model with real data. We acknowledge that the manuscript lacks explicit error bounds or dedicated experiments on approximation error. We will add this analysis to the methods section in revision, including plots of surrogate error over training and under controlled shifts. revision: yes
-
Referee: [Experimental results] Experimental results section: The demonstrations on classification, regression, and captioning tasks report successful outcomes but include no quantitative error bars, ablation studies on channel count or surrogate accuracy, or controls for drift, making it impossible to evaluate the robustness of the multi-channel roles or the hybrid model performance.
Authors: The demonstrations prioritize establishing the three channel roles over exhaustive statistical validation. We agree the results section would be strengthened by error bars, ablations, and drift controls. We will incorporate error bars from available replicate measurements, channel-count ablations, and expanded discussion of drift mitigation via online fine-tuning in the revised manuscript. revision: yes
Circularity Check
No significant circularity; training relies on external physical measurements
full rationale
The paper's core training procedure uses measured optical outputs to define the forward pass in an online physical-forward/surrogate-backward scheme, supplying an independent external benchmark from hardware rather than deriving performance from fitted parameters or self-citations. No equations or claims in the provided text reduce predictions to inputs by construction, invoke load-bearing self-citations, or smuggle ansatzes; the demonstrations of channel roles in classification, regression, and captioning tasks rest on physical experiments with >1M parameters instead of tautological redefinitions. This is the expected self-contained case for an experimental optics paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optical hardware implements a differentiable forward mapping whose measured outputs can be used to fine-tune a surrogate model in real time.
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778, 10.1109/CVPR.2016.90 (2016)
-
[2]
InInternational Conference on Learning Representations(2021)
Dosovitskiy, A.et al.An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations(2021). 2010.11929
Pith/arXiv arXiv 2021
-
[3]
Nature 521(7553), 436–444 (2015) https://doi.org/10.1038/nature14539
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning.Nat.521, 436–444, 10.1038/nature14539 (2015)
-
[4]
Sebastian,A.,LeGallo,M.,Khaddam-Aljameh,R.&Eleftheriou,E. Memorydevicesandappli- cationsforin-memorycomputing.Nat.Nanotechnol.15,529–544,10.1038/s41565-020-0655-z (2020)
-
[5]
Wetzstein, G.et al.Inference in artificial intelligence with deep optics and photonics.Nat.588, 39–47, 10.1038/s41586-020-2973-6 (2020)
-
[6]
Lin, X.et al.All-optical machine learning using diffractive deep neural networks.Sci.361, 1004–1008, 10.1126/science.aat8084 (2018)
-
[7]
Electron.5, 113–122, 10.1038/s41928-022-00719-9 (2022)
Liu, C.et al.A programmable diffractive deep neural network based on a digital-coding metasurface array.Nat. Electron.5, 113–122, 10.1038/s41928-022-00719-9 (2022)
-
[8]
Mengu, D., Luo, Y., Rivenson, Y. & Ozcan, A. Analysis of diffractive optical neural networks and their integration with electronic neural networks.IEEE J. Sel. Top. Quantum Electron.26, 1–14, 10.1109/JSTQE.2019.2921376 (2020)
-
[9]
Isil, C.et al.All-optical image denoising using a diffractive visual processor.Light. Sci. & Appl.13, 43, 10.1038/s41377-024-01385-6 (2024). 21
-
[10]
Photonics11, 441–446, 10.1038/nphoton.2017.93 (2017)
Shen, Y.et al.Deep learning with coherent nanophotonic circuits.Nat. Photonics11, 441–446, 10.1038/nphoton.2017.93 (2017)
-
[11]
Nat.589, 52–58, 10.1038/s41586-020-03070-1 (2021)
Feldmann, J.et al.Parallel convolutional processing using an integrated photonic tensor core. Nat.589, 52–58, 10.1038/s41586-020-03070-1 (2021)
-
[12]
Xu, X.et al.11 tops photonic convolutional accelerator for optical neural networks.Nat.589, 44–51, 10.1038/s41586-020-03063-0 (2021)
-
[13]
Hua, S., Divita, E., Yu, S.et al.An integrated large-scale photonic accelerator with ultralow latency.Nat.640, 361–367, 10.1038/s41586-025-08786-6 (2025)
-
[14]
Ahmed, S. R., Baghdadi, R., Bernadskiy, M.et al.Universal photonic artificial intelligence acceleration.Nat.640, 368–374, 10.1038/s41586-025-08854-x (2025)
-
[15]
Chen, Y., Nazhamaiti, M., Xu, H.et al.All-analog photoelectronic chip for high-speed vision tasks.Nat.623, 48–57, 10.1038/s41586-023-06558-8 (2023)
-
[16]
Wang, T., Sohoni, M. M., Wright, L. G.et al.Image sensing with multilayer nonlinear optical neural networks.Nat. Photonics17, 408–415, 10.1038/s41566-023-01170-8 (2023)
-
[17]
Wright, L. G., Onodera, T., Stein, M. M.et al.Deep physical neural networks trained with backpropagation.Nat.601, 549–555, 10.1038/s41586-021-04223-6 (2022)
-
[18]
632, 280–286, 10.1038/s41586-024-07687-4 (2024)
Xue, Z., Zhou, T., Xu, Z.et al.Fully forward mode training for optical neural networks.Nat. 632, 280–286, 10.1038/s41586-024-07687-4 (2024)
-
[19]
Momeni, A., Rahmani, B., Mallejac, M., del Hougne, P. & Fleury, R. Backpropagation-free training of deep physical neural networks.Sci.382, 1297–1303, 10.1126/science.adi8474 (2023)
-
[20]
Momeni, A.et al.Training of physical neural networks.Nat.645, 53–61, 10.1038/ s41586-025-09384-2 (2025). 22
2025
-
[21]
Hammami,C.etal.Expressivityofprogrammable-metasurface-basedphysicalneuralnetworks: encoding non-linearity, structural non-linearity, and depth, 10.48550/arXiv.2603.13602 (2026). 2603.13602
-
[22]
Momeni, A. & Fleury, R. Electromagnetic wave-based extreme deep learning with nonlinear time-Floquet entanglement.Nat. Commun.13, 2651, 10.1038/s41467-022-30297-5 (2022)
-
[23]
Photonics 18, 1067–1075, 10.1038/s41566-024-01493-0 (2024)
Xia, F.et al.Nonlinear optical encoding enabled by recurrent linear scattering.Nat. Photonics 18, 1067–1075, 10.1038/s41566-024-01493-0 (2024)
-
[24]
Photonics18, 1076–1082, 10.1038/s41566-024-01494-z (2024)
Yildirim, M.et al.Nonlinear processing with linear optics.Nat. Photonics18, 1076–1082, 10.1038/s41566-024-01494-z (2024)
-
[25]
Wanjura, C. C. & Marquardt, F. Fully nonlinear neuromorphic computing with linear wave scattering.Nat. Phys.20, 1434–1440, 10.1038/s41567-024-02534-9 (2024)
-
[26]
G., Ma, S.-Y., Wang, T., Wright, L
Anderson, M. G., Ma, S.-Y., Wang, T., Wright, L. G. & McMahon, P. L. Optical transformers, 10.48550/arXiv.2302.10360 (2023). 2302.10360
-
[27]
Xu, Z.et al.Large-scale photonic chiplet taichi empowers 160-tops/w artificial general intelligence.Sci.384, 202–209, 10.1126/science.adl1203 (2024)
-
[28]
Opticalgenerativemodels.Nat.644,903–911, 10.1038/s41586-025-09446-5 (2025)
Chen,S.,Li,Y.,Wang,Y.,Chen,H.&Ozcan,A. Opticalgenerativemodels.Nat.644,903–911, 10.1038/s41586-025-09446-5 (2025)
-
[29]
InAdvances in Neural Information Processing Systems, vol
Vaswani, A.et al.Attention is all you need. InAdvances in Neural Information Processing Systems, vol. 30 (2017)
2017
-
[30]
Vinyals, O., Toshev, A., Bengio, S. & Erhan, D. Show and tell: A neural image caption generator. InProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition, 3156–3164, 10.1109/CVPR.2015.7298935 (2015)
-
[31]
In Proceedingsofthe32ndInternationalConferenceonMachineLearning,vol.37ofProceedings of Machine Learning Research, 2048–2057 (2015)
Xu, K.et al.Show, attend and tell: Neural image caption generation with visual attention. In Proceedingsofthe32ndInternationalConferenceonMachineLearning,vol.37ofProceedings of Machine Learning Research, 2048–2057 (2015). 23
2048
-
[32]
In Proceedingsofthe38thInternationalConferenceonMachineLearning,vol.139ofProceedings of Machine Learning Research, 8748–8763 (2021)
Radford, A.et al.Learning transferable visual models from natural language supervision. In Proceedingsofthe38thInternationalConferenceonMachineLearning,vol.139ofProceedings of Machine Learning Research, 8748–8763 (2021). 24
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.