Game-Theoretic Multi-Agent Control for Robust Contextual Reasoning in LLMs
Pith reviewed 2026-06-27 13:03 UTC · model grok-4.3
The pith
GT-MCP coordinates three LLM agents with a trust function to bound contextual drift in 99.6 percent of turns under adaptive adversarial attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
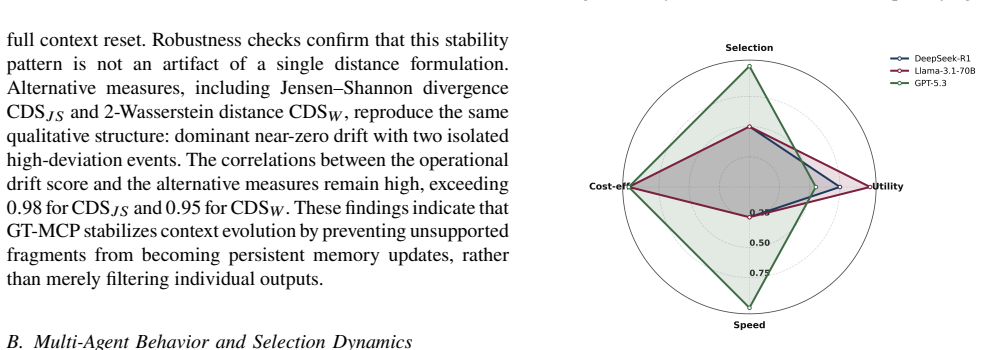
GT-MCP coordinates three heterogeneous LLM agents and selects outputs through a trust function that jointly evaluates causal consistency against a validated context graph, semantic agreement among agents, and distributional drift over time. When instability is detected, a rollback-based self-healing mechanism restores the validated context and prevents unsupported fragments from propagating.
What carries the argument
The trust function that combines causal consistency, semantic agreement, and distributional drift checks to select agent outputs and trigger rollbacks.
If this is right
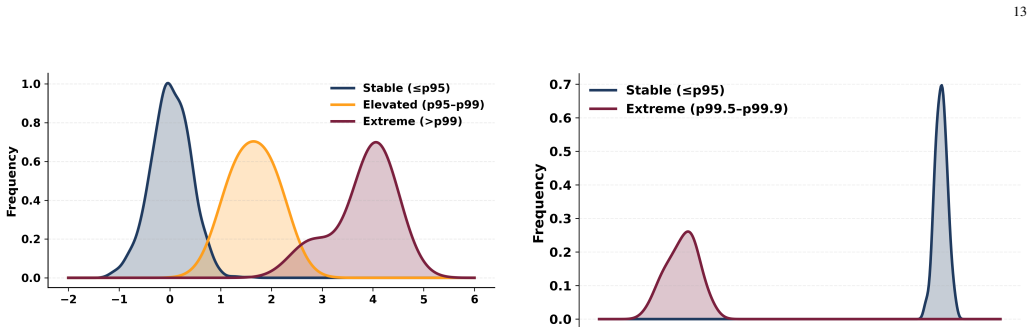
- Contextual drift remains bounded in 99.6 percent of interaction turns.
- Recovery via rollback is required in only 0.4 percent of turns.
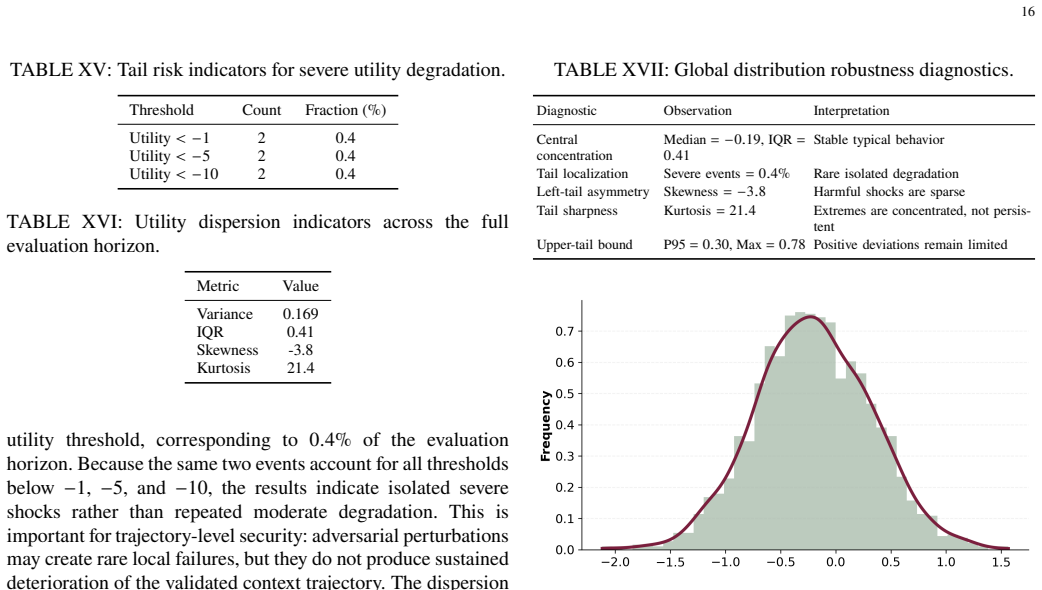
- Per-turn utility stays tightly concentrated with severe degradation in only 0.4 percent of cases.
- No injection attempt succeeds at the controller level.
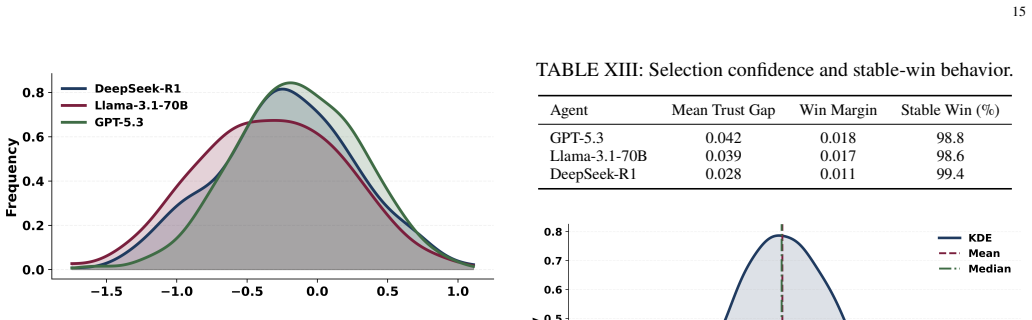
- Selected outputs maintain stable win rates above 98 percent.
Where Pith is reading between the lines
- The same closed-loop controller structure could be tested on sequential reasoning tasks outside language models, such as tool-use chains or planning agents.
- The validated context graph would need an independent verification method if the initial context itself contains errors.
- The low reported latency overhead suggests the method could run continuously without changing user-perceived response times.
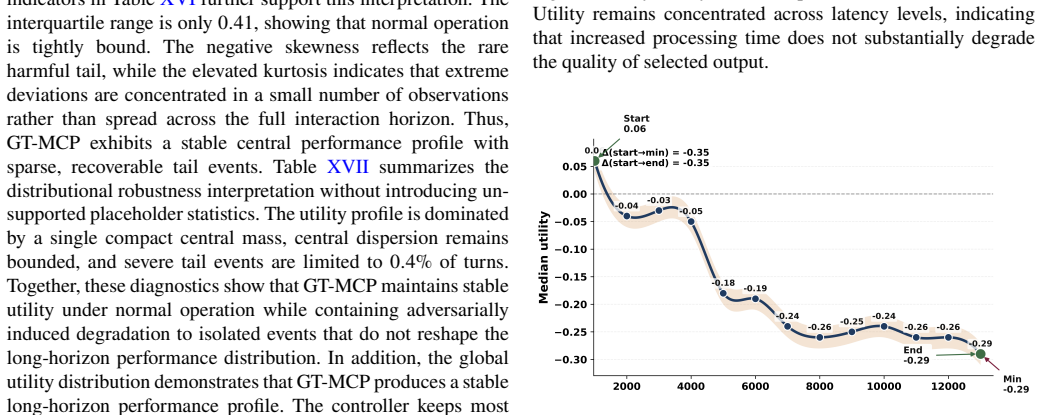
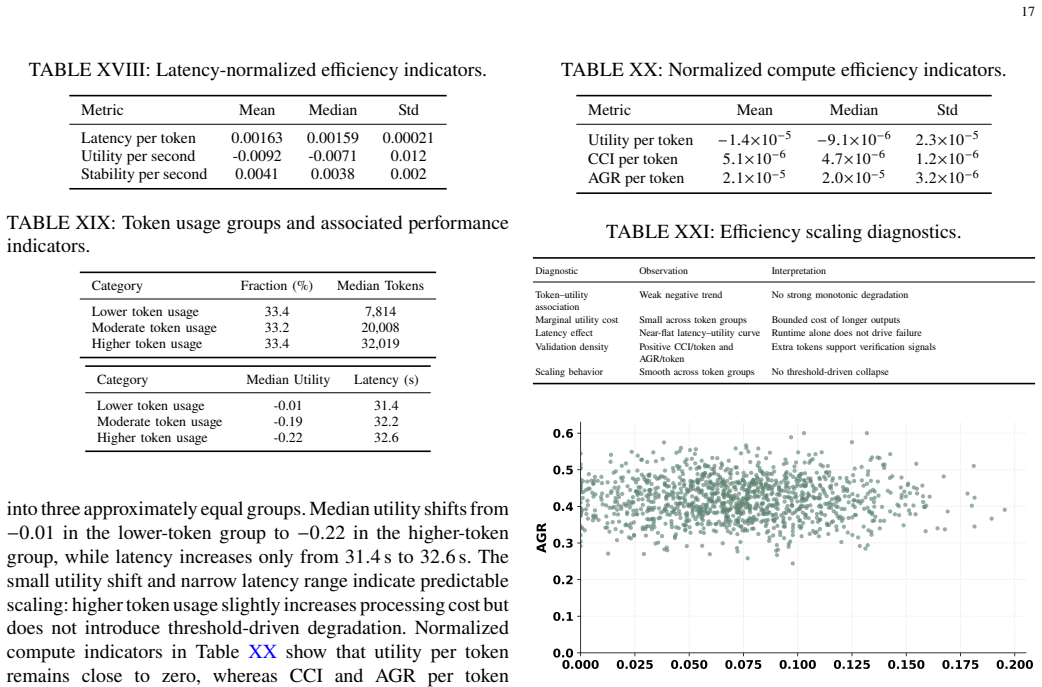
Load-bearing premise
The trust function jointly evaluating causal consistency against a validated context graph, semantic agreement among agents, and distributional drift over time accurately detects instability and enables effective rollback without allowing adversarial fragments to propagate.
What would settle it
An adaptive adversary that causes contextual drift to exceed bounds in more than 1 percent of turns or succeeds in propagating an injection at the controller level would falsify the central claim.
Figures



read the original abstract
Large Language Models (LLMs) in multi-turn interactions maintain evolving context rather than generating isolated responses, making them vulnerable to prompt-injection and context-poisoning attacks in which locally plausible adversarial fragments gradually distort reasoning trajectories. Existing defenses mainly filter individual outputs and often ignore context evolution across turns, leaving long-horizon reasoning exposed. Although the Model Context Protocol (MCP) standardizes context exchange and tool invocation, it functions as a passive routing layer and does not enforce contextual stability. To address these limitations, we introduce the Game-Theoretic Secure Model Context Protocol (GT-MCP), a controller-driven multi-agent method that treats context management as a closed-loop dynamical process. GT-MCP coordinates three heterogeneous LLM agents and selects outputs through a trust function that jointly evaluates causal consistency against a validated context graph, semantic agreement among agents, and distributional drift over time. When instability is detected, a rollback-based self-healing mechanism restores the validated context and prevents unsupported fragments from propagating. Empirical evaluation over 500 interaction turns under an adaptive adversarial threat model shows that contextual drift remains bounded in 99.6% of turns, with recovery required in only 0.4%. Per-turn utility remains tightly concentrated, with median = -0.19, P05 = -0.72, and P95 = 0.30; severe degradation below -1 occurs in only 0.4% of cases, and no injection attempt succeeds at the controller level. Selected outputs maintain stable win rates above 98%, and computational overhead remains predictable, with latency per token = 1.63e-3 s.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the Game-Theoretic Secure Model Context Protocol (GT-MCP), a controller-driven multi-agent method coordinating three heterogeneous LLM agents for context management in multi-turn interactions. It uses a trust function jointly evaluating causal consistency against a validated context graph, semantic agreement among agents, and distributional drift over time; instability triggers rollback self-healing. The central empirical claim is that over 500 interaction turns under an adaptive adversarial threat model, contextual drift remains bounded in 99.6% of turns (recovery in 0.4%), per-turn utility is stable (median -0.19, P05 -0.72, P95 0.30), severe degradation occurs in only 0.4% of cases, selected outputs maintain >98% win rates, and no injection succeeds at the controller level.
Significance. If the trust function and reported results hold with full verification, the work could provide a meaningful advance in robust LLM context handling by treating context evolution as a closed-loop dynamical process with active self-healing, going beyond passive filtering in existing protocols like MCP. The multi-agent coordination under adversarial conditions would be of interest for secure multi-turn LLM applications.
major comments (2)
- [Abstract] Abstract (trust function description): The trust function is the load-bearing component for the self-healing claim and all reported performance numbers (99.6% bounded drift, 0% controller-level injections), yet it is described only qualitatively with no equations, thresholds, context-graph construction procedure, causal-consistency metric, semantic-agreement measure, or distributional-drift definition supplied. An adaptive adversary could in principle craft fragments satisfying the three criteria while still distorting downstream reasoning; nothing in the reported numbers rules this out.
- [Abstract] Abstract (empirical evaluation): The abstract reports quantitative results over 500 turns (bounded drift 99.6%, utility percentiles, win rates >98%) but supplies no experimental setup, threat-model implementation details, baselines, agent role definitions, context-graph validation method, or statistical tests. This makes it impossible to verify whether the data support the stated performance.
minor comments (1)
- [Abstract] The title and abstract invoke 'game-theoretic' control, but no game formulation, payoff structure, or equilibrium analysis appears; this could be clarified if the multi-agent coordination is intended to rest on such concepts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional detail is needed for verifiability and will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract (trust function description): The trust function is the load-bearing component for the self-healing claim and all reported performance numbers (99.6% bounded drift, 0% controller-level injections), yet it is described only qualitatively with no equations, thresholds, context-graph construction procedure, causal-consistency metric, semantic-agreement measure, or distributional-drift definition supplied. An adaptive adversary could in principle craft fragments satisfying the three criteria while still distorting downstream reasoning; nothing in the reported numbers rules this out.
Authors: We agree that the abstract describes the trust function only qualitatively. In the revision we will incorporate concise definitions and key equations for the trust function (including context-graph construction via causal inference on conversation history, causal-consistency metric via graph-edit distance, semantic-agreement measure via embedding cosine similarity, and distributional-drift via KL divergence on token distributions), along with the chosen thresholds. We will also add a brief discussion of how the joint evaluation is intended to counter adaptive adversaries that attempt to satisfy the criteria while distorting reasoning, supported by the reported results under the adaptive threat model. revision: yes
-
Referee: [Abstract] Abstract (empirical evaluation): The abstract reports quantitative results over 500 turns (bounded drift 99.6%, utility percentiles, win rates >98%) but supplies no experimental setup, threat-model implementation details, baselines, agent role definitions, context-graph validation method, or statistical tests. This makes it impossible to verify whether the data support the stated performance.
Authors: We agree that the abstract omits the experimental details. In the revision we will add a concise summary of the experimental setup to the abstract (adaptive adversarial threat model, three agent roles, context-graph validation procedure, baselines, and statistical tests with bootstrap intervals) or provide explicit cross-references to the methods section so that the performance claims can be verified. revision: yes
Circularity Check
No circularity; empirical measurements only
full rationale
The paper reports direct empirical outcomes (99.6% bounded drift over 500 turns, 0% controller-level injections) from running the described GT-MCP controller under an adaptive adversary. No equations, derivations, fitted parameters, or self-citations appear in the provided text. The trust function is introduced as a joint evaluator of three criteria but is not defined in terms of the reported metrics, nor are any results shown to be constructed from it by algebraic identity. The evaluation is therefore an external measurement rather than a self-referential renaming or fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A comprehensive overview of large language models,
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, and A. Mian, “A comprehensive overview of large language models,”ACM Transactions on Intelligent Systems and Technology, vol. 16, no. 5, pp. 1–72, 2025
2025
-
[2]
When large language models meet personalization: Perspectives of challenges and opportunities,
J. Chen, Z. Liu, X. Huang, C. Wu, Q. Liu, G. Jiang, Y. Pu, Y. Lei, X. Chen, X. Wanget al., “When large language models meet personalization: Perspectives of challenges and opportunities,”World wide web, vol. 27, no. 4, p. 42, 2024
2024
-
[3]
From system 1 to system 2: A survey of reasoning large language models,
Z.-Z. Li, D. Zhang, M.-L. Zhang, J. Zhang, Z. Liu, Y. Yao, H. Xu, J. Zheng, P.-J. Wang, X. Chenet al., “From system 1 to system 2: A survey of reasoning large language models,”arXiv preprint arXiv:2502.17419, 2025
Pith/arXiv arXiv 2025
-
[4]
Llm applications: Current paradigms and the next frontier,
X. Hou, Y. Zhao, and H. Wang, “Llm applications: Current paradigms and the next frontier,”arXiv preprint arXiv:2503.04596, 2025
arXiv 2025
-
[5]
A survey on model context protocol: Architecture, state-of-the- art, challenges and future directions,
P. P. Ray, “A survey on model context protocol: Architecture, state-of-the- art, challenges and future directions,”Authorea Preprints, 2025
2025
-
[6]
Beyond vulnerabilities: A comprehensive survey of adversarial attacks across domains
D. C. Asimopoulos, P. Radoglou-Grammatikis, G. T. Papadopoulos, and P. Sarigiannidis, “Beyond vulnerabilities: A comprehensive survey of adversarial attacks across domains.”
-
[7]
Formalizing and benchmarking prompt injection attacks and defenses,
Y. Liu, Y. Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” inUSENIX Security Symposium, 2024
2024
-
[8]
Prompt injection attacks on large language models: A survey of attack methods and defense strategies,
T. Geng, Z. Xu, and Y. Qu, “Prompt injection attacks on large language models: A survey of attack methods and defense strategies,”Computers, Materials & Continua, vol. 87, no. 1, pp. 1–10, 2025
2025
-
[9]
From prompt injections to protocol exploits: Threats in retrieval-augmented and llm-agent systems,
M. A. Ferraget al., “From prompt injections to protocol exploits: Threats in retrieval-augmented and llm-agent systems,”arXiv preprint arXiv:2502.XXXX, 2025
2025
-
[10]
Agentlab: Benchmarking llm agents against long-horizon attacks,
T. Jiang, Y. Wang, J. Liang, and T. Wang, “Agentlab: Benchmarking llm agents against long-horizon attacks,”Technical Report, 2025
2025
-
[11]
Struq: Defending against prompt injection with structured queries,
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “Struq: Defending against prompt injection with structured queries,” inUSENIX Security Symposium, 2025
2025
-
[12]
Model context protocol (mcp): Landscape, security threats, and future research directions,
X. Hou, Y. Zhao, S. Wang, and H. Wang, “Model context protocol (mcp): Landscape, security threats, and future research directions,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[13]
Prompt injection attacks in large language models and their defense mechanisms,
S. Sasalet al., “Prompt injection attacks in large language models and their defense mechanisms,” inProceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), 2025
2025
-
[14]
Universal and transferable adversarial attacks on aligned language models,
A. Zouet al., “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023. [Online]. Available: https://arxiv.org/abs/2307.15043
Pith/arXiv arXiv 2023
-
[15]
Benchmarking and defending against indirect prompt injection attacks on large language models,
Y. Liuet al., “Benchmarking and defending against indirect prompt injection attacks on large language models,”arXiv preprint arXiv:2312.14197, 2023. [Online]. Available: https://arxiv.org/abs/2312. 14197
arXiv 2023
-
[16]
W. Shiet al., “Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models,”arXiv preprint arXiv:2402.07867, 2024. [Online]. Available: https://arxiv.org/abs/2402. 07867
arXiv 2024
-
[17]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
F. Debenedettiet al., “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,” arXiv preprint arXiv:2406.13352, 2024. [Online]. Available: https: //arxiv.org/abs/2406.13352 23
Pith/arXiv arXiv 2024
-
[18]
Targeting the core: Understanding attacks on retrieval- augmented agents,
X. Liuet al., “Targeting the core: Understanding attacks on retrieval- augmented agents,”arXiv preprint arXiv:2412.04415, 2024. [Online]. Available: https://arxiv.org/abs/2412.04415
arXiv 2024
-
[20]
Defeating prompt injections by design,
S. Williamset al., “Defeating prompt injections by design,” arXiv preprint arXiv:2503.18813, 2025. [Online]. Available: https: //arxiv.org/abs/2503.18813
Pith/arXiv arXiv 2025
-
[21]
Defending against indirect prompt injection by instruction isolation,
J. Schuteraet al., “Defending against indirect prompt injection by instruction isolation,”arXiv preprint arXiv:2505.06311, 2025. [Online]. Available: https://arxiv.org/abs/2505.06311
arXiv 2025
-
[22]
Design patterns for securing llm applications against prompt injections,
L. Beurer-Kellneret al., “Design patterns for securing llm applications against prompt injections,”arXiv preprint arXiv:2506.08837, 2025. [Online]. Available: https://arxiv.org/abs/2506.08837
arXiv 2025
-
[23]
Scalability via sparsity in stackelberg security games: An augmented decision space approach,
A. ˙Zychowski, A. Gupta, Y.-S. Ong, and J. Ma ´ndziuk, “Scalability via sparsity in stackelberg security games: An augmented decision space approach,”ACM Transactions on Evolutionary Learning, 2026
2026
-
[24]
Defending against indirect prompt injection attacks with spotlighting,
K. Hines, G. Lopez, M. Hall, and E. Kiciman, “Defending against indirect prompt injection attacks with spotlighting,”arXiv preprint arXiv:2403.14720, 2024
Pith/arXiv arXiv 2024
-
[25]
The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents,
F. Jia, T. Wu, X. Qin, and A. Squicciarini, “The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents,” arXiv preprint arXiv:2412.16682, 2024
arXiv 2024
-
[26]
Secinfer: Preventing prompt injection via inference-time scaling,
Y. Liu, Y. Wang, Y. Jia, and N. Z. Gong, “Secinfer: Preventing prompt injection via inference-time scaling,”arXiv preprint arXiv:2509.24967, 2025
arXiv 2025
-
[27]
A multi-agent llm defense pipeline against prompt injection attacks,
S. M. A. Hossain, R. K. Shayoni, M. R. Ameenet al., “A multi-agent llm defense pipeline against prompt injection attacks,”arXiv preprint arXiv:2509.14285, 2025
arXiv 2025
-
[28]
A systematic literature review on llm defenses against prompt injection and jailbreaking,
P. H. B. Correia, R. W. Achjian, D. E. G. Caetano de Oliveiraet al., “A systematic literature review on llm defenses against prompt injection and jailbreaking,”arXiv preprint arXiv:2601.22240, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.