ReflectiChain: Epistemic Grounding in LLM-Driven World Models for Supply Chain Resilience
Pith reviewed 2026-06-27 13:35 UTC · model grok-4.3
The pith
ReflectiChain encodes supply networks in a 6D latent space with conservation laws to ground LLM policies and separate uncertainty types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
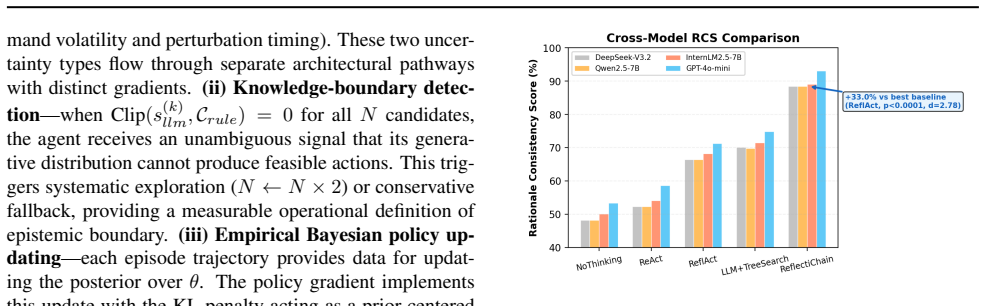
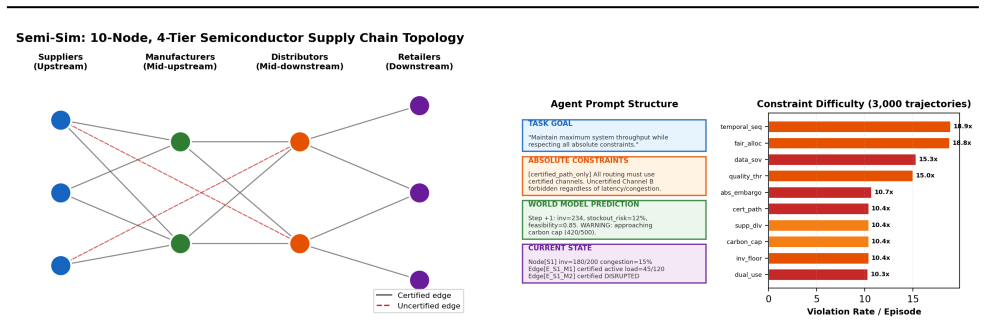
ReflectiChain bridges the epistemic gap in LLM-driven supply chain agents by means of a Generative Supply Chain World Model that encodes networks into a 6-dim graph-latent space equipped with physical conservation laws together with Double-Loop Learning that isolates epistemic uncertainty via KL-trust-region-bounded policy adaptation from aleatoric uncertainty via stochastic latent rollouts, producing a 33 percent rise in Rationale Consistency Score, 82.3 percent operability under adversarial shocks, and anti-fragile gains on the Semi-Sim benchmark.
What carries the argument
The Generative Supply Chain World Model (SC-WM) that compresses heterogeneous supply networks into a 6-dimensional graph-latent space subject to physical conservation laws, paired with Double-Loop Learning for separating epistemic from aleatoric uncertainty.
If this is right
- The method yields a 33 percent increase in Rationale Consistency Score on the Semi-Sim benchmark.
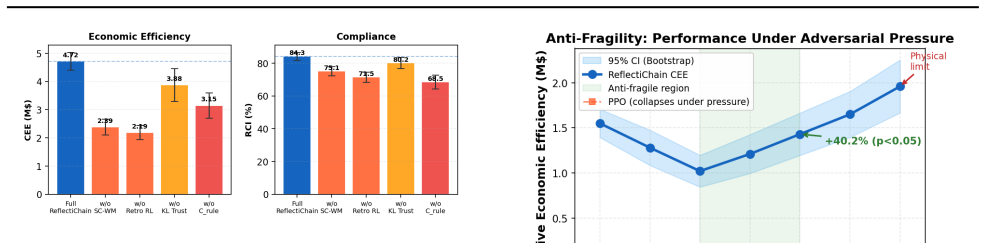
- Operability remains at 82.3 percent under the six tested adversarial shocks.
- Performance improves by 40.2 percent under moderate pressure, indicating anti-fragile dynamics.
- Three epistemic mechanisms are isolated: uncertainty separation, knowledge-boundary detection, and empirical Bayesian policy updating.
Where Pith is reading between the lines
- The same latent-space approach could be tested on non-semiconductor networks such as food or pharmaceutical logistics to check whether the conservation-law embedding generalizes.
- If the KL-trust-region adaptation proves stable, the framework might support online policy updates when new regulatory text arrives without full retraining.
- Anti-fragile gains under moderate pressure suggest experiments that deliberately increase constraint density to measure the point at which the separation mechanism breaks.
- The five limitation categories mentioned could be turned into targeted ablation tests on the benchmark to quantify each category's contribution to the observed scores.
Load-bearing premise
The 6-dimensional graph-latent space with physical conservation laws accurately represents heterogeneous supply networks and allows reliable separation of epistemic uncertainty from aleatoric uncertainty.
What would settle it
Running the same 10-node semiconductor benchmark with a new perturbation type that violates the assumed conservation laws and observing that rationale consistency gains disappear or operability falls below the reported 82 percent would falsify the central claim.
Figures


read the original abstract
AI agents in supply chains face a fundamental epistemic gap: large language models (LLMs) interpret policies but lack physical grounding, while reinforcement learning (RL) optimizes flows but is semantically blind to unstructured constraints. We introduce REFLECTICHAIN, bridging this gap through a Generative Supply Chain World Model (SC-WM) - encoding heterogeneous supply networks into a 6-dim graph-latent space with physical conservation - and Double-Loop Learning that separates epistemic uncertainty (KL-trust-region-bounded policy adaptation) from aleatoric uncertainty (stochastic latent rollouts). On Semi-Sim, a 10-node semiconductor benchmark with SIR risk propagation, 6 perturbation types, and 10 policy constraint templates, REFLECTICHAIN improves Rationale Consistency Score by 33.0% (p < 0.0001, d = 2.78), maintains 82.3% operability under adversarial shocks, and exhibits anti-fragile behavior (+40.2% gain under moderate pressure). We identify three operational epistemic mechanisms - uncertainty separation, knowledge-boundary detection, and empirical Bayesian policy updating - and discuss five limitation categories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REFLECTICHAIN, which uses a Generative Supply Chain World Model (SC-WM) to encode heterogeneous supply networks into a fixed 6-dimensional graph-latent space enforcing physical conservation laws, combined with Double-Loop Learning to separate epistemic uncertainty (via KL-trust-region-bounded adaptation) from aleatoric uncertainty (via stochastic latent rollouts). On the Semi-Sim 10-node semiconductor benchmark with SIR risk propagation, 6 perturbation types, and 10 policy constraints, it reports a 33.0% improvement in Rationale Consistency Score (p < 0.0001, d = 2.78), 82.3% operability under adversarial shocks, and +40.2% anti-fragile gain under moderate pressure, while identifying three epistemic mechanisms and five limitation categories.
Significance. If the 6-dimensional encoding and uncertainty separation are shown to be valid and the quantitative gains reproducible, the work would offer a concrete bridge between LLM semantic reasoning and physically grounded RL-style optimization in supply-chain settings. The introduction of a controlled benchmark with explicit risk propagation and policy templates is a positive step toward falsifiable evaluation in this domain.
major comments (3)
- [Abstract] Abstract: The headline performance numbers rest on the SC-WM's fixed 6-dimensional graph-latent space with physical conservation laws, yet no derivation, ablation, or reconstruction metric is supplied showing why dimension 6 suffices for heterogeneous 10-node networks or how conservation is enforced inside the generative model for SIR dynamics.
- [Abstract] Abstract: The claimed separation of epistemic uncertainty (KL-trust-region-bounded policy adaptation) from aleatoric uncertainty (stochastic latent rollouts) is load-bearing for the epistemic-grounding claim, but the manuscript provides neither the explicit form of the KL bound nor any diagnostic showing that the bound isolates epistemic uncertainty rather than conflating it with model misspecification.
- [Abstract] Abstract: The reported 33.0% RCS lift, 82.3% operability, and +40.2% anti-fragile gain are presented with p-values and effect sizes, but the absence of methods, dataset details, or code prevents verification that these quantities are supported by the underlying derivations rather than post-hoc choices.
minor comments (1)
- [Abstract] The abstract introduces several new terms (SC-WM, Double-Loop Learning, Rationale Consistency Score) without forward references to their formal definitions in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on the latent space design, uncertainty separation, and reproducibility. We address each major comment below and will incorporate the requested additions in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers rest on the SC-WM's fixed 6-dimensional graph-latent space with physical conservation laws, yet no derivation, ablation, or reconstruction metric is supplied showing why dimension 6 suffices for heterogeneous 10-node networks or how conservation is enforced inside the generative model for SIR dynamics.
Authors: We agree that the manuscript lacks an explicit derivation and supporting metrics for the fixed 6-dimensional latent space. In revision we will add a dedicated subsection deriving the dimension from the degrees of freedom in a 10-node flow network (state variables plus SIR compartments) and include an ablation table reporting reconstruction MSE and conservation violation error across latent dimensions 4–10 on the Semi-Sim benchmark. The conservation enforcement mechanism (a differentiable projection layer in the decoder) will be stated formally with the corresponding loss term. revision: yes
-
Referee: [Abstract] Abstract: The claimed separation of epistemic uncertainty (KL-trust-region-bounded policy adaptation) from aleatoric uncertainty (stochastic latent rollouts) is load-bearing for the epistemic-grounding claim, but the manuscript provides neither the explicit form of the KL bound nor any diagnostic showing that the bound isolates epistemic uncertainty rather than conflating it with model misspecification.
Authors: We concur that the explicit form of the KL bound and isolation diagnostics are missing. The revision will state the bound as KL(q_φ(·|s) || p(·|s)) ≤ ε_t where ε_t is adapted from policy-gradient variance, and will add diagnostic plots comparing the bound against held-out epistemic shifts versus aleatoric noise levels to demonstrate separation. revision: yes
-
Referee: [Abstract] Abstract: The reported 33.0% RCS lift, 82.3% operability, and +40.2% anti-fragile gain are presented with p-values and effect sizes, but the absence of methods, dataset details, or code prevents verification that these quantities are supported by the underlying derivations rather than post-hoc choices.
Authors: Sections 3–4 already contain the Semi-Sim generation procedure, SIR propagation rules, and evaluation protocol. To strengthen verifiability we will expand these sections with additional pseudocode, hyperparameter tables, and exact statistical test specifications. We will also release the implementation code upon acceptance. revision: partial
Circularity Check
No significant circularity; derivation chain self-contained against external benchmarks
full rationale
The abstract and description introduce REFLECTICHAIN via a Generative Supply Chain World Model (SC-WM) that encodes networks into a 6-dim graph-latent space with conservation laws and uses Double-Loop Learning for uncertainty separation. No equations, fitted parameters, or self-citations are supplied that reduce any claimed performance metric (RCS improvement, operability, anti-fragile gain) to a quantity defined by those inputs by construction. The reported results are presented as empirical outcomes on the Semi-Sim benchmark rather than predictions forced by the latent-space definition or trust-region bounds. This meets the default expectation of a non-circular paper; the central claims rest on the benchmark evaluation rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Supply networks can be faithfully encoded into a 6-dimensional graph-latent space that enforces physical conservation
invented entities (2)
-
Generative Supply Chain World Model (SC-WM)
no independent evidence
-
Double-Loop Learning
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhe Song, Ying Xie, Lichao Yang, and Yifan Zhao. Large language models in supply chain manage- ment: a systematic literature review and application framework.International Journal of Production Re- search, 0(0):1–41, 2026. doi: 10.1080/00207543. 2026.2641103. URLhttps://doi.org/10. 1080/00207543.2026.2641103
-
[2]
Large language models are zero-shot time series forecasters, 2024
Nate Gruver, Marc Finzi, Shikai Qiu, and An- drew Gordon Wilson. Large language models are zero-shot time series forecasters, 2024. URL https://arxiv.org/abs/2310.07820
-
[3]
Shuning Jia, Baijun Song, Canming Ye, and Chun Yuan. M3time: Llm-enhanced multi-modal, multi- scale, and multi-frequency multivariate time se- ries forecasting.Proceedings of the AAAI Con- ference on Artificial Intelligence, 40(27):22265– 22273, Mar. 2026. doi: 10.1609/aaai.v40i27.39383. URLhttps://ojs.aaai.org/index.php/ AAAI/article/view/39383
-
[4]
Bowen Zhang, Pengcheng Luo, Genke Yang, Boon- Hee Soong, and Chau Yuen. Or-llm-agent: Automat- ing modeling and solving of operations research op- timization problems with reasoning llm, 2025. URL https://arxiv.org/abs/2503.10009
-
[5]
Deepor: A deep reasoning foundation model for optimization model- ing
Ziyang Xiao, Yuan Jessica Wang, Xiongwei Han, Shisi Guan, Jingyan Zhu, Jingrong Xie, Lilin Xu, Han Wu, Wing Yin Yu, Zehua Liu, et al. Deepor: A deep reasoning foundation model for optimization model- ing. InProceedings of the AAAI Conference on Ar- 4 tificial Intelligence, volume 40, pages 34052–34060, 2026
2026
-
[6]
Azmine Toushik Wasi, MD Islam, and Adipto Raihan Akib. Supplygraph: A benchmark dataset for supply chain planning using graph neural networks.arXiv preprint arXiv:2401.15299, 2024
-
[7]
The ai-gpr in- dex: Measuring geopolitical risk using artificial intel- ligence
Matteo Iacoviello and Jonathan Tong. The ai-gpr in- dex: Measuring geopolitical risk using artificial intel- ligence. Working Paper, 2026
2026
-
[8]
Bank for International Settlements, Monetary and Economic Department, 2025
Byeungchun Kwon, Taejin Park, Phurichai Rungcharoenkitkul, and Frank Smets.Parsing the pulse: decomposing macroeconomic sentiment with LLMs. Bank for International Settlements, Monetary and Economic Department, 2025
2025
-
[9]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models, 2024. URLhttps:// arxiv.org/abs/2301.04104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Has- sabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839): 604–609, December 2020. ISSN 1476-4687. doi: 10.1038/s41586-020-0...
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[11]
Contrastive learning of structured world models,
Thomas Kipf, Elise van der Pol, and Max Welling. Contrastive learning of structured world models,
-
[12]
URLhttps://arxiv.org/abs/1911. 12247
1911
-
[13]
Reasoning with Language Model is Planning with World Model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Rea- soning with language model is planning with world model, 2023. URLhttps://arxiv.org/abs/ 2305.14992
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Ji- ahao Wang, Vishal M. Patel, Paul Pu Liang, Daniel Khashabi, Cheng Peng, Rama Chellappa, Tianmin Shu, Alan Yuille, Yilun Du, and Jieneng Chen. World-in-world: World models in a closed-loop world, 2025. URLhttps://arxiv.org/abs/ 2510.18135
-
[15]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal rein- forcement learning, 2023. URLhttps://arxiv. org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
React: Synergizing reasoning and acting in language models,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models,
-
[17]
URLhttps://arxiv.org/abs/2210. 03629
-
[18]
Learning to (learn at test time): Rnns with expressive hidden states,
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Ar- jun Vikram, Genghan Zhang, Yann Dubois, Xin- lei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): Rnns with expressive hidden states,
-
[19]
URLhttps://arxiv.org/abs/2407. 04620
-
[20]
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
Yining Hong, Huang Huang, Manling Li, Li Fei-Fei, Jiajun Wu, and Yejin Choi. Learning from trials and errors: Reflective test-time planning for embodied llms, 2026. URLhttps://arxiv.org/abs/ 2602.21198. Appendix: Semi-Sim Specification Topology (Fig. 6, left):|V|=10(3S+2M+2D+3R),∼30 edges. Node: inventory, cash, compliance, risk, capac- ity, congestion, q...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.