3D-CoS: A New 3D Reconstruction Paradigm Based on VLM Code Synthesis
Pith reviewed 2026-06-27 14:03 UTC · model grok-4.3
The pith
3D objects reconstructed as executable Blender code enable more precise localized edits than point clouds or meshes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce 3D-CoS, a reconstruction paradigm in which 3D assets are built as executable Blender code through VLM-driven synthesis. Systematic tests of representative VLMs and structured generation workflows demonstrate that code offers strong controllability and locality. In targeted editing evaluations this yields higher edit fidelity and better preservation of unedited regions than a point-cloud baseline.
What carries the argument
Executable Blender code as the 3D representation, which functions as both reconstruction output and an interpretable, directly editable programmatic medium.
If this is right
- Text-driven edits can be applied to specific object parts with high fidelity.
- Unedited regions remain unchanged more reliably than under point-cloud editing.
- Workflows combining planning, RAG, and agent decomposition raise the success rate of code generation.
- The same code representation supports both reconstruction and subsequent programmatic modification.
Where Pith is reading between the lines
- Improved VLM code-generation ability would directly expand the range of scenes that can be reconstructed this way.
- The format could be combined with existing scripting pipelines in animation or CAD tools.
- Performance on very large or highly detailed scenes would test whether locality advantages scale.
Load-bearing premise
Vision-language models can produce functionally correct and complete Blender code that accurately captures the geometry and appearance of input objects.
What would settle it
A rendering test in which the generated Blender scripts fail to execute without errors or produce visual output that deviates substantially from the source images or descriptions.
Figures

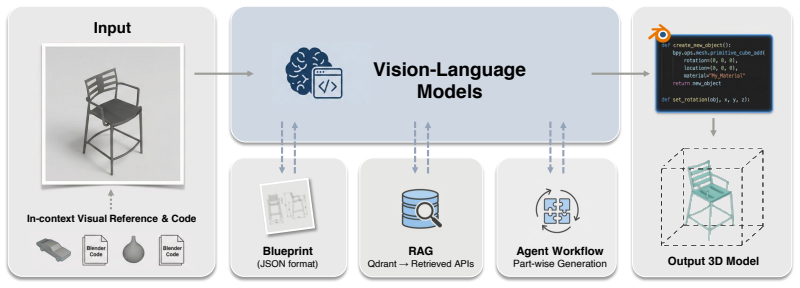
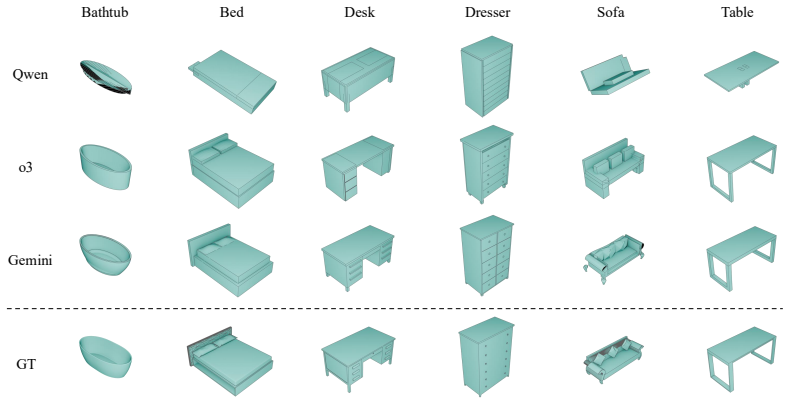
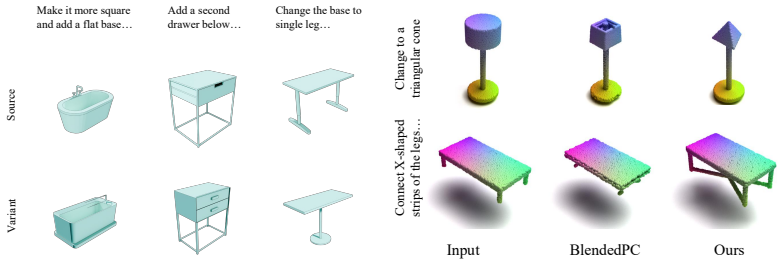


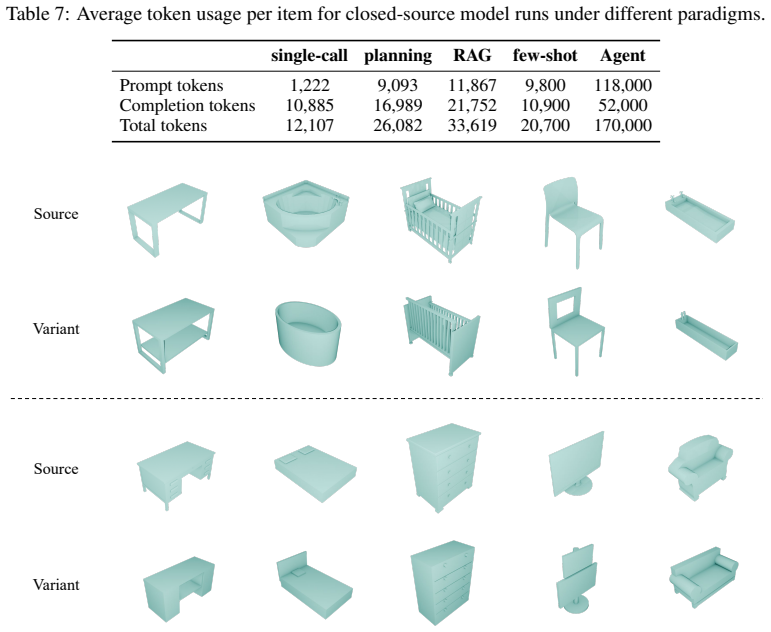




read the original abstract
Most recent 3D reconstruction and editing systems operate on implicit and explicit representations such as NeRF, point clouds, or meshes. While these representations enable high-fidelity rendering, they are fundamentally low-level and hard to control programmatically. In contrast, we propose and systematically evaluate a new 3D reconstruction paradigm, 3D Code Synthesis (3D-CoS), where 3D assets are constructed as executable Blender code, a programmatic and interpretable medium. To assess how well current VLMs can use code to represent 3D objects, we evaluate representative open-source and closed-source VLMs in code-based reconstruction under a unified protocol. We further introduce a suite of structured code-synthesis workflows, including blueprint-based planning, Retrieval-Augmented Generation (RAG) over Blender API documentation, few-shot geometric demonstrations, and a component-level Agent workflow for part-wise code generation. To demonstrate the unique advantages of this representation, we further evaluate localized text-driven modifications and compare our code-based edits with a point-cloud-based 3D editing baseline. Our study shows that code as a 3D representation offers strong controllability and locality, yielding stronger edit fidelity and better preservation of unedited regions in our targeted editing evaluation. Our work also analyzes the potential of this paradigm, delineates the current capability frontier of VLMs for programmatic 3D modeling, and highlights code synthesis as a promising direction for editable 3D reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 3D-CoS, a paradigm in which 3D assets are represented as executable Blender code synthesized by VLMs rather than implicit or explicit geometric representations. It evaluates open- and closed-source VLMs under unified protocols using workflows such as blueprint planning, RAG over Blender API docs, few-shot demonstrations, and component-level agents; it further compares code-based localized text-driven edits against a point-cloud baseline and claims superior controllability, locality, edit fidelity, and preservation of unedited regions.
Significance. If the VLM-generated code proves reliably executable and geometrically faithful, the paradigm could enable more interpretable and programmatically editable 3D assets than current NeRF/mesh/point-cloud methods. The work also maps the current capability frontier of VLMs for programmatic 3D modeling. However, the absence of any reported quantitative results on code success rates, compilation errors, or geometric deviation prevents assessment of whether the claimed editing advantages are attributable to the representation itself.
major comments (2)
- [Abstract] Abstract: the claim that 'code as a 3D representation offers strong controllability and locality, yielding stronger edit fidelity and better preservation of unedited regions' is load-bearing for the central contribution, yet the abstract (and therefore the evaluation) provides no metrics, dataset details, success rates, or error analysis to support it.
- [Evaluation section (implied by abstract)] The targeted editing evaluation rests on the untested assumption that VLM-generated Blender code is functionally correct and complete; without reported compilation success rates, runtime error statistics, or deviation from ground-truth geometry, advantages over the point-cloud baseline cannot be attributed to the code representation.
minor comments (1)
- [Abstract] The abstract refers to 'our study shows' and 'our targeted editing evaluation' without naming the specific VLMs, datasets, or quantitative protocol used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger quantitative grounding of our claims. We will revise the manuscript to incorporate additional metrics, success rates, and clarifications on the evaluation protocol while preserving the core contribution of the code-based paradigm.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'code as a 3D representation offers strong controllability and locality, yielding stronger edit fidelity and better preservation of unedited regions' is load-bearing for the central contribution, yet the abstract (and therefore the evaluation) provides no metrics, dataset details, success rates, or error analysis to support it.
Authors: We agree the abstract should summarize supporting quantitative evidence. The evaluation section already contains human-rated edit fidelity scores, locality assessments, and side-by-side comparisons across 50+ editing examples on both open- and closed-source VLMs; we will condense these into the abstract (e.g., reporting average fidelity gains and unedited-region preservation rates) along with dataset size and workflow details. This change will make the load-bearing claim directly traceable to the reported results. revision: yes
-
Referee: [Evaluation section (implied by abstract)] The targeted editing evaluation rests on the untested assumption that VLM-generated Blender code is functionally correct and complete; without reported compilation success rates, runtime error statistics, or deviation from ground-truth geometry, advantages over the point-cloud baseline cannot be attributed to the code representation.
Authors: We acknowledge the importance of explicit success metrics. In revision we will add a new subsection reporting per-workflow compilation success rates, categorized runtime errors, and the fraction of generations that produced executable, renderable code. For the editing comparison we will restrict quantitative claims to the subset of successful code outputs and will state this filtering explicitly. Geometric deviation metrics are not directly available because many test cases start from textual descriptions rather than existing meshes; we will instead report functional equivalence (e.g., render consistency before/after edit) and clarify this scope limitation. revision: yes
Circularity Check
No circularity: empirical evaluation of code-based 3D paradigm is self-contained
full rationale
The paper proposes 3D-CoS as a new paradigm using executable Blender code for 3D assets, introduces workflows (RAG, few-shot, agent), and reports empirical comparisons of editing fidelity against a point-cloud baseline. No equations, fitted parameters presented as predictions, or self-citation chains appear in the text. The controllability and locality claims are grounded in the described evaluation protocol rather than reducing to inputs by definition or prior self-work. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can be prompted to generate executable Blender code that accurately represents 3D geometry
Reference graph
Works this paper leans on
-
[1]
Blendermcp - blender model context protocol integration, 2025
Siddharth Ahuja and BlenderMCP Contributors. Blendermcp - blender model context protocol integration, 2025. URLhttps://github.com/ahujasid/blender-mcp
2025
-
[2]
Introduction to model context protocol, 2024
Anthropic PBC. Introduction to model context protocol, 2024. URL https://www. anthropic.com/news/model-context-protocol
2024
-
[3]
Claude Sonnet 4, 2025
Anthropic PBC. Claude Sonnet 4, 2025. URL https://www.anthropic.com/claude/ sonnet. Product page
2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Blender Python API reference, 2025
Blender Foundation. Blender Python API reference, 2025. URL https://docs.blender. org/api/current/index.html. Online; accessed 2025-09-18
2025
-
[6]
Blender: Open-source 3d creation suite
Blender Online Community. Blender: Open-source 3d creation suite. https://www.blender. org, 2025. Version 4.4 as used in this work
2025
-
[7]
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. Shapenet: An information-rich 3d model repository, 2015. URL https://arxiv.org/abs/ 1512.03012
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Decor-gan: 3d shape detailization by conditional refinement
Zhiqin Chen, Vladimir G Kim, Matthew Fisher, Noam Aigerman, Hao Zhang, and Siddhartha Chaudhuri. Decor-gan: 3d shape detailization by conditional refinement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15740–15749, 2021
2021
-
[9]
Text-to-3d using gaussian splatting
Zilong Chen, Feng Wang, Yikai Wang, and Huaping Liu. Text-to-3d using gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21401–21412, 2024
2024
-
[10]
Bingquan Dai, Li Ray Luo, Qihong Tang, Jie Wang, Xinyu Lian, Hao Xu, Minghan Qin, Xudong Xu, Bo Dai, Haoqian Wang, et al. Meshcoder: Llm-powered structured mesh code generation from point clouds.arXiv preprint arXiv:2508.14879, 2025
-
[11]
Blenderllm: Training large language models for computer-aided design with self-improvement, 2024
Yuhao Du, Shunian Chen, Wenbo Zan, Peizhao Li, Mingxuan Wang, Dingjie Song, Bo Li, Yan Hu, and Benyou Wang. Blenderllm: Training large language models for computer-aided design with self-improvement, 2024. URLhttps://arxiv.org/abs/2412.14203
-
[12]
Unreal engine c++ api reference, 2025
Epic. Unreal engine c++ api reference, 2025. URL https://dev.epicgames.com/ documentation/en-us/unreal-engine/API
2025
-
[13]
Unreal engine, 2025
Epic. Unreal engine, 2025. URLhttps://www.unrealengine.com/
2025
-
[14]
PAL: Program-aided Language Models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models, 2023. URL https://arxiv.org/ abs/2211.10435
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Gemini 3 Pro, 2025
Google DeepMind. Gemini 3 Pro, 2025. URL https://blog.google/products/gemini/ gemini-3/. Official blog post (Nov 18, 2025)
2025
-
[16]
Blendergym: Bench- marking foundational model systems for graphics editing
Yunqi Gu, Ian Huang, Jihyeon Je, Guandao Yang, and Leonidas Guibas. Blendergym: Bench- marking foundational model systems for graphics editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18574–18583, 2025
2025
-
[17]
Scenecraft: An llm agent for synthesizing 3d scenes as blender code
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A Ross, Cordelia Schmid, and Alireza Fathi. Scenecraft: An llm agent for synthesizing 3d scenes as blender code. In Forty-first International Conference on Machine Learning, 2024. 10
2024
-
[18]
Blenderalchemy: Editing 3d graphics with vision-language models
Ian Huang, Guandao Yang, and Leonidas Guibas. Blenderalchemy: Editing 3d graphics with vision-language models. InEuropean Conference on Computer Vision, pages 297–314. Springer, 2024
2024
-
[19]
3d shape generation with grid-based implicit functions
Moritz Ibing, Isaak Lim, and Leif Kobbelt. 3d shape generation with grid-based implicit functions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13559–13568, 2021
2021
-
[20]
Kenny Jones, Theresa Barton, Xianghao Xu, Kai Wang, Ellen Jiang, Paul Guerrero, Niloy Mitra, and Daniel Ritchie
R. Kenny Jones, Theresa Barton, Xianghao Xu, Kai Wang, Ellen Jiang, Paul Guerrero, Niloy Mitra, and Daniel Ritchie. Shapeassembly: Learning to generate programs for 3d shape structure synthesis.ACM Transactions on Graphics (TOG), Siggraph Asia 2020, 39(6):Article 234, 2020
2020
-
[21]
Shap-E: Generating Conditional 3D Implicit Functions
Heewoo Jun and Alex Nichol. Shap-e: Generating conditional 3d implicit functions.arXiv preprint arXiv:2305.02463, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[23]
Nerf-vae: A geometry aware 3d scene generative model
Adam R Kosiorek, Heiko Strathmann, Daniel Zoran, Pol Moreno, Rosalia Schneider, Sona Mokrá, and Danilo Jimenez Rezende. Nerf-vae: A geometry aware 3d scene generative model. InInternational conference on machine learning, pages 5742–5752. PMLR, 2021
2021
-
[24]
Ln3diff: Scalable latent neural fields diffusion for speedy 3d generation
Yushi Lan, Fangzhou Hong, Shuai Yang, Shangchen Zhou, Xuyi Meng, Bo Dai, Xingang Pan, and Chen Change Loy. Ln3diff: Scalable latent neural fields diffusion for speedy 3d generation. InEuropean Conference on Computer Vision, pages 112–130. Springer, 2024
2024
-
[25]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer, 2024. URL https://arxiv.org/abs/2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Chain of code: Reasoning with a language model-augmented code emulator, 2024
Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, and Brian Ichter. Chain of code: Reasoning with a language model-augmented code emulator, 2024. URLhttps://arxiv.org/abs/2312.04474
-
[27]
Sp-gan: Sphere-guided 3d shape generation and manipulation.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021
Ruihui Li, Xianzhi Li, Ka-Hei Hui, and Chi-Wing Fu. Sp-gan: Sphere-guided 3d shape generation and manipulation.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021
2021
-
[28]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control, 2023. URL https://arxiv.org/abs/2209.07753
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
LL3M: Large language 3D modelers.arXiv:2508.08228, 2025
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka. Ll3m: Large language 3d modelers.arXiv preprint arXiv:2508.08228, 2025
-
[30]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[31]
GPT-4o Technical Report.https://openai.com/index/hello-gpt-4o/, 2024
OpenAI. GPT-4o Technical Report.https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[32]
Introducing OpenAI o3 and o4-mini, 2025
OpenAI. Introducing OpenAI o3 and o4-mini, 2025. URL https://openai.com/index/ introducing-o3-and-o4-mini/. Model announcement (Apr 16, 2025)
2025
-
[33]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Qdrant: Vector database and vector search engine, 2025
Qdrant Team. Qdrant: Vector database and vector search engine, 2025. URLhttps://github. com/qdrant/qdrant. GitHub repository, Version v1.15.4
2025
-
[35]
Blended point cloud diffusion for localized text-guided shape editing, 2025
Etai Sella, Noam Atia, Ron Mokady, and Hadar Averbuch-Elor. Blended point cloud diffusion for localized text-guided shape editing, 2025. URL https://arxiv.org/abs/2507.15399
-
[36]
sphobjinv: A practical tool for manipulating sphinx objects.inv files, 2024
Brian Skinn. sphobjinv: A practical tool for manipulating sphinx objects.inv files, 2024. URL https://github.com/bskinn/sphobjinv. 11
2024
-
[37]
Sphinx documentation.https://www.sphinx-doc.org/, 2025
The Sphinx Project. Sphinx documentation.https://www.sphinx-doc.org/, 2025
2025
-
[38]
Freeman, Joshua B
Yonglong Tian, Andrew Luo, Xingyuan Sun, Kevin Ellis, William T. Freeman, Joshua B. Tenenbaum, and Jiajun Wu. Learning to infer and execute 3d shape programs. InInternational Conference on Learning Representations, 2019
2019
-
[39]
Unity real-time development platform, 2025
Unity. Unity real-time development platform, 2025. URLhttps://unity.com/
2025
-
[40]
Unity scripting api, 2025
Unity. Unity scripting api, 2025. URL https://docs.unity3d.com/6000.2/ Documentation/ScriptReference/index.html
2025
-
[41]
Clip-nerf: Text- and-image driven manipulation of neural radiance fields
Can Wang, Menglei Chai, Mingming He, Dongdong Chen, and Jing Liao. Clip-nerf: Text- and-image driven manipulation of neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3835–3844, 2022
2022
-
[42]
Rodin: A generative model for sculpting 3d digital avatars using diffusion
Tengfei Wang, Bo Zhang, Ting Zhang, Shuyang Gu, Jianmin Bao, Tadas Baltrusaitis, Jingjing Shen, Dong Chen, Fang Wen, Qifeng Chen, et al. Rodin: A generative model for sculpting 3d digital avatars using diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4563–4573, 2023
2023
-
[43]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Karl D. D. Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G. Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences.ACM Transactions on Graphics (TOG), 40(4), 2021
2021
-
[45]
Unique3d: High-quality and efficient 3d mesh generation from a single image, 2024
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, and Kaisheng Ma. Unique3d: High-quality and efficient 3d mesh generation from a single image, 2024
2024
-
[46]
Deepcad: A deep generative network for computer- aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer- aided design models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6772–6782, October 2021
2021
-
[47]
Textsplat: Text-guided semantic fusion for generalizable gaussian splatting
Zhicong Wu, Hongbin Xu, Gang Xu, Ping Nie, Zhixin Yan, Jinkai Zheng, Liangqiong Qu, Ming Li, and Liqiang Nie. Textsplat: Text-guided semantic fusion for generalizable gaussian splatting. arXiv preprint arXiv:2504.09588, 2025
-
[48]
3D ShapeNets: A Deep Representation for Volumetric Shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes, 2015. URL https://arxiv.org/abs/1406.5670
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models.arXiv preprint arXiv:2404.07191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Cad-mllm: Unifying multimodality-conditioned cad generation with mllm, 2024
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. Cad-mllm: Unifying multimodality-conditioned cad generation with mllm, 2024
2024
-
[51]
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xinggang Wang. Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6796–6807, 2024
2024
-
[52]
Lion: Latent point diffusion models for 3d shape generation
xiaohui zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. Lion: Latent point diffusion models for 3d shape generation. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems, volume 35, pages 10021–10039. Curran Associates, Inc., 2022. UR...
2022
-
[53]
Sin." stands for “single-call
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023. 13 A Appendix A.1 Reconstruction Pipeline Details ModelNet10 Easy/Hard Split.We partition ModelNet10 intoeasyandhardsubsets per category: objects wit...
2023
-
[54]
Let all the rings on the pillar sink with gravity and fit together
-
[55]
Make it smaller
The ring handle on the side of this cup is too big and does not match the cup body. Make it smaller
-
[56]
Make it thinner and longer and reduce the number to 1 and insert it in the middle of the top of the cake
The candle on this cake is too thick and short. Make it thinner and longer and reduce the number to 1 and insert it in the middle of the top of the cake
-
[57]
Change the frustum-shaped lampshade of the upper part of the table lamp into a cylindrical shape
-
[58]
Position the top layer of the burger off-center so people can see the insides
-
[59]
Turn it to the closed position
This oil-paper umbrella is open, with a cone on top. Turn it to the closed position. In Figure 4, the instructions we use are:
-
[60]
Make the bathtub more square and add a flat base for stability. 19 Input Edited All the rings sink with gravity… Make the ring handle smaller… Make the candle one and taller… Make lampshade into cylindrical… Close the oil- paper umbrella… Position the top layer off-center… Figure 10:Qualitative results for code editing.Each example shows an input and edit...
-
[61]
Add a second drawer below the existing one
-
[62]
Change the base legs to a single centered pedestal
-
[63]
Replace the cylindrical lampshade above this desk lamp with a triangular cone
-
[64]
The column mistakenly passes through the lampshade and protrudes a little from the top
Make this table lamp taller. The column mistakenly passes through the lampshade and protrudes a little from the top. Remove this small part
-
[65]
In Figure 7, the instructions we use are: • Upper part:
Lengthen the four cylindrical legs of this table and connect the legs at opposite corners at the bottom with X-shaped wooden strips to make its structure more stable. In Figure 7, the instructions we use are: • Upper part:
-
[66]
Add a lower shelf between the two legs
-
[67]
Convert the corner bath to an oval shape
-
[68]
Convert one of the crib’s sides into a removable panel
-
[69]
Cut a large opening in the middle of the backrest
-
[70]
• Lower part:
Extend the basin to double its current length. • Lower part:
-
[71]
Add a central open shelf in the knee space area for additional storage
-
[72]
Add a headboard to the bed
-
[73]
Add a fifth drawer at the bottom
-
[74]
Add a second, smaller screen on top to create a dual-monitor setup
-
[75]
In Figure 11, the instructions we use are:
Add a lower central support beam between the sofa legs. In Figure 11, the instructions we use are:
-
[76]
This sofa has armrests on only one side and the modification makes it have armrests on both sides. 20
-
[77]
The keychain circle on this cup is too big; make it smaller
-
[78]
Make it hollow
The cylindrical portion of this cup was incorrectly generated as a solid shape. Make it hollow
-
[79]
Add a handguard in the middle of this sofa to give it two separate seats
-
[80]
Separate the spherical part of this bulb from the base
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.