Benchmarking Knowledge Editing using Logical Rules
Pith reviewed 2026-06-27 13:25 UTC · model grok-4.3
The pith
Knowledge editing methods insert direct facts into LLMs but fail to propagate the logical consequences of those edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
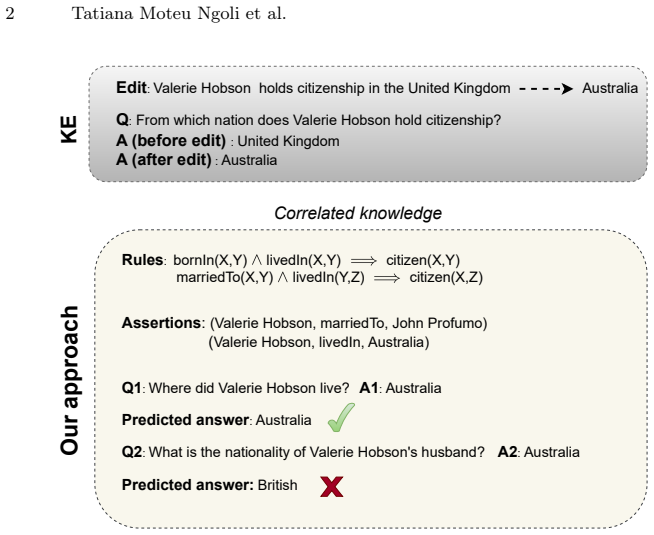
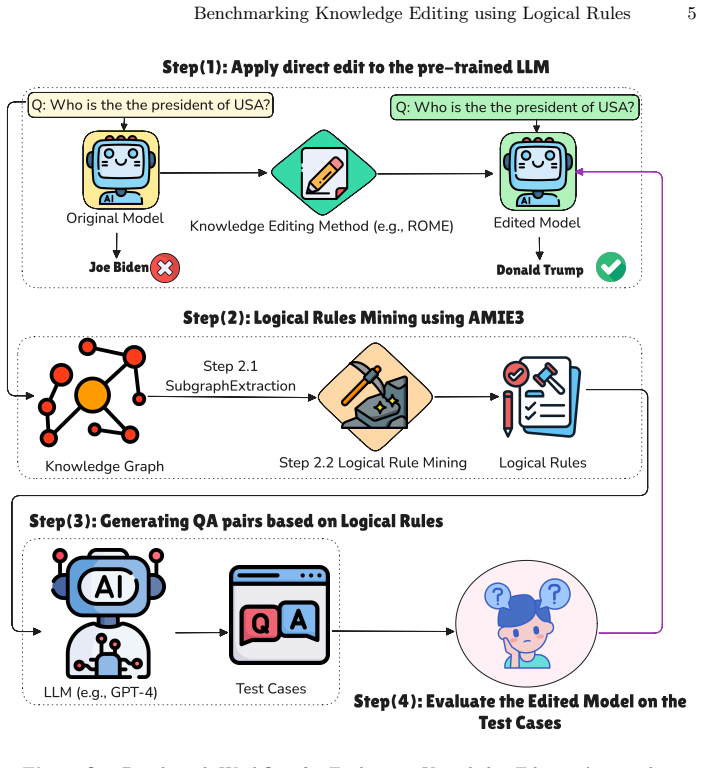
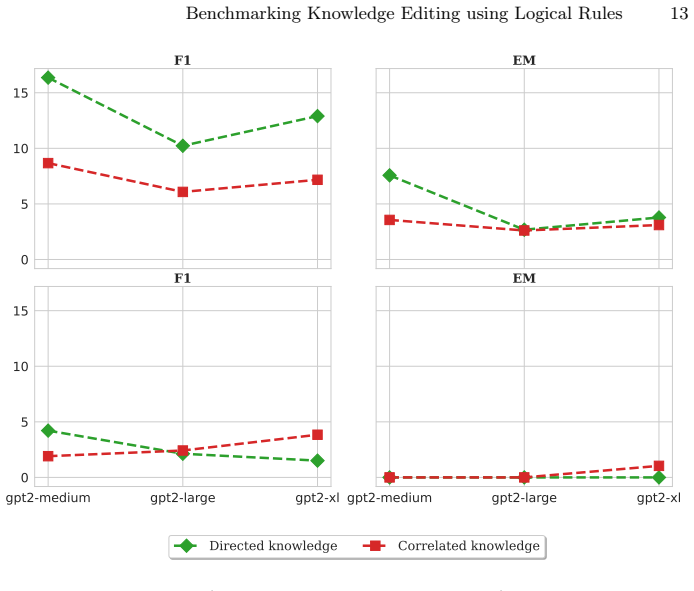
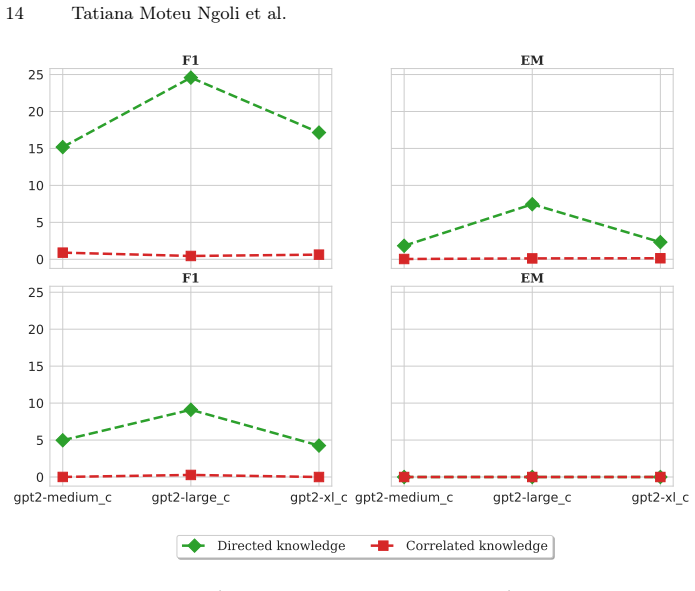
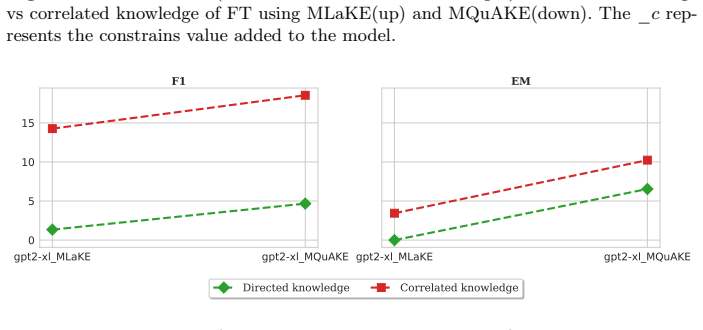
The benchmark extracts relevant logical rules from a knowledge graph for a given edit, generates multi-hop questions based on these rules, and measures whether editing methods propagate the entailed knowledge. Results indicate that existing approaches accurately insert the direct assertion yet frequently fail to inject the entailed knowledge, producing a performance gap of up to 24 percent between direct and entailed evaluations.
What carries the argument
A benchmark that extracts logical rules from a knowledge graph for each edit and generates multi-hop questions to assess impact on logical consequences.
If this is right
- Knowledge editing evaluations must incorporate tests for logical entailment beyond single-fact recall.
- Methods such as ROME and fine-tuning require extensions that propagate edits through logical rules.
- Semantics-aware evaluation frameworks become necessary for reliable knowledge updates in LLMs.
Where Pith is reading between the lines
- If the observed gap persists across additional models and editing techniques, future methods may need to incorporate explicit reasoning components during the edit process.
- The benchmark construction could be applied to other knowledge graphs to test whether the failure to handle entailment is domain-specific.
- Applications that rely on multi-hop consistency after model updates may currently produce logically inconsistent outputs even when direct facts are correctly edited.
Load-bearing premise
The logical rules extracted from the knowledge graph for a given edit correctly identify the multi-hop consequences that should be entailed after the edit.
What would settle it
Running the benchmark on a set of edits and finding no substantial performance gap between direct assertions and the multi-hop entailed questions would falsify the claim that existing methods fail to inject entailed knowledge.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly deployed in real-world applications that require access to up-to-date knowledge. However, retraining LLMs is computationally expensive. Therefore, knowledge editing techniques are crucial for maintaining current information and correcting erroneous assertions within pre-trained models. Current benchmarks for knowledge editing primarily focus on recalling edited facts, often neglecting their logical consequences. To address this limitation, we introduce a new benchmark designed to evaluate how knowledge editing methods handle the logical consequences of a single fact edit. Our benchmark extracts relevant logical rules from a knowledge graph for a given edit. Then, it generates multi-hop questions based on these rules to assess the impact on logical consequences. Our findings indicate that while existing knowledge editing approaches can accurately insert direct assertions into LLMs, they frequently fail to inject entailed knowledge. Specifically, experiments with popular methods like ROME and FT reveal a substantial performance gap, up to 24%, between evaluations on directly edited knowledge and on entailed knowledge. This highlights the critical need for semantics-aware evaluation frameworks in knowledge editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark for evaluating knowledge editing methods in LLMs by extracting logical rules from a knowledge graph for a given fact edit and generating multi-hop questions to test whether the edit propagates to entailed knowledge. Experiments on methods such as ROME and FT show that while direct edited facts are recalled accurately, performance on entailed knowledge drops by up to 24%, indicating that current editing techniques fail to handle logical consequences.
Significance. If the benchmark construction is sound, the result identifies a substantive limitation in existing knowledge editing approaches, which have focused narrowly on direct fact recall. This provides an empirical demonstration of the gap and motivates semantics-aware evaluation frameworks, with potential impact on applications requiring consistent knowledge propagation.
major comments (2)
- [Abstract] Abstract (benchmark construction paragraph): The central 24% performance gap claim depends on the extracted logical rules correctly identifying only those multi-hop entailments that should follow from the single edited fact. No description is given of validation for rule correctness (e.g., human judgment, consistency checks against the KG, or comparison to an independent entailment engine), leaving open the possibility that the measured gap arises from incomplete or non-strict rules rather than editing method shortcomings.
- [Abstract] Abstract (experiments paragraph): The reported gap is presented without accompanying details on dataset construction, rule extraction parameters, question generation procedure, or statistical significance testing. These omissions make it impossible to assess whether the 24% figure is robust or sensitive to choices in the benchmark pipeline.
minor comments (1)
- [Abstract] The abstract refers to 'popular methods like ROME and FT' but does not specify the full set of baselines or hyperparameter settings used in the comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to strengthen the presentation of our benchmark. We address each major comment below and will revise the manuscript accordingly to provide greater transparency on rule validation and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract (benchmark construction paragraph): The central 24% performance gap claim depends on the extracted logical rules correctly identifying only those multi-hop entailments that should follow from the single edited fact. No description is given of validation for rule correctness (e.g., human judgment, consistency checks against the KG, or comparison to an independent entailment engine), leaving open the possibility that the measured gap arises from incomplete or non-strict rules rather than editing method shortcomings.
Authors: The rules are extracted directly from the knowledge graph structure for each edited fact, ensuring they encode valid entailments by construction from the KG. This design choice reduces the chance of spurious rules. We acknowledge that the current manuscript provides limited explicit discussion of validation procedures. We will add a dedicated paragraph in the benchmark construction section describing the extraction algorithm, any automated consistency checks performed against the KG, and results from a human validation study on a random sample of 100 rules (reporting inter-annotator agreement). revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): The reported gap is presented without accompanying details on dataset construction, rule extraction parameters, question generation procedure, or statistical significance testing. These omissions make it impossible to assess whether the 24% figure is robust or sensitive to choices in the benchmark pipeline.
Authors: The full manuscript contains a Methods section that specifies the KG used, rule extraction parameters (e.g., rule length and confidence thresholds), the question generation template, and the evaluation protocol. The abstract is intentionally concise. We will revise the abstract to include a brief pointer to these details and add a new table reporting statistical significance (paired t-tests and confidence intervals) for the performance gaps across methods. We will also release the full benchmark construction code and hyperparameters to enable reproducibility. revision: yes
Circularity Check
No significant circularity in empirical benchmark
full rationale
The paper introduces an empirical benchmark for knowledge editing by extracting logical rules from a knowledge graph and generating multi-hop questions. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains are present that reduce any claimed result to its inputs by construction. The central findings (performance gaps between direct and entailed knowledge) rest on experimental comparisons rather than tautological definitions or renamings. The benchmark construction step is described procedurally but does not exhibit self-definitional or fitted-input patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Logical rules extracted from the knowledge graph for a given edit correctly identify the multi-hop consequences that should be entailed after the edit.
Reference graph
Works this paper leans on
-
[2]
arXiv preprint arXiv:2405.15452 (2024)
Cheng, K., Ali, M.A., Yang, S., Lin, G., Zhai, Y., Fei, H., Xu, K., Yu, L., Hu, L., Wang, D.: Leveraging logical rules in knowledge editing: A cherry on the top. arXiv preprint arXiv:2405.15452 (2024)
- [3]
-
[4]
MedCLIP: Contrastive learning from unpaired medical images and text
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., Wei, F.: Knowledge neurons in pretrained transformers. In: Muresan, S., Nakov, P., Villavicencio, A. (eds.) Pro- ceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). pp. 8493–8502. Association for Computational Linguistics, Dublin, Ireland (May 2022)...
-
[5]
In: Proceedings of the 22nd International Conference on World Wide Web
Galárraga, L.A., Teflioudi, C., Hose, K., Suchanek, F.: Amie: association rule min- ing under incomplete evidence in ontological knowledge bases. In: Proceedings of the 22nd International Conference on World Wide Web. p. 413–422. WWW ’13, Association for Computing Machinery, New York, NY, USA (2013).https://doi. org/10.1145/2488388.2488425,https://doi.org...
-
[6]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) (2024)
Gu, Y., et al.: Programmable knowledge editing for multi-hop question answering. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) (2024)
2024
-
[7]
Locating and Editing Factual Associations in GPT
Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and editing factual asso- ciations in gpt. arXiv preprint arXiv:2202.05262 (2022),https://arxiv.org/abs/ 2202.05262 10 https://github.com/dice-group/Benchmarking-KE/tree/main 16 Tatiana Moteu Ngoli et al
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Meng, K., Sharma, A.S., Andonian, A., Belinkov, Y., Bau, D.: Mass-editing mem- oryinatransformer.arXivpreprintarXiv:2210.07229(2022),https://arxiv.org/ abs/2210.07229
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [9]
-
[10]
ACM Transactions on Database Systems (TODS)34(3), 1–45 (2009)
Pérez, J., Arenas, M., Gutierrez, C.: Semantics and complexity of sparql. ACM Transactions on Database Systems (TODS)34(3), 1–45 (2009)
2009
-
[11]
Rae, J.W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides, J., Henderson, S., Ring, R., Young, S., Rutherford, E., Hennigan, T., Menick, J., Cassirer, A., Powell, R., van den Driessche, G., Hendricks, L.A., Rauh, M., Huang, P.S., Glaese, A., Welbl, J., Dathathri, S., Huang, S., Uesato, J., Mellor, J., Higgins, I., Creswell, A., McA...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
In: NeurIPS 2022 Foundation Models for Decision Making Workshop (2022),https://openreview.net/forum?id=wUU-7XTL5XO
Valmeekam, K., Olmo, A., Sreedharan, S., Kambhampati, S.: Large language mod- els still can’t plan (a benchmark for LLMs on planning and reasoning about change). In: NeurIPS 2022 Foundation Models for Decision Making Workshop (2022),https://openreview.net/forum?id=wUU-7XTL5XO
2022
-
[13]
No Starch Press (2020)
Vasiliev, Y.: Natural language processing with Python and spaCy: A practical introduction. No Starch Press (2020)
2020
-
[14]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Wei, J., Wang, X., Schuurmans, D., Bosma, M., brian ichter, Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain of thought prompting elicits reasoning in large language models. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neu- ral Information Processing Systems (2022),https://openreview.net/forum?id= _VjQlMeSB_J
2022
-
[15]
In: Rambow, O., Wanner, L.,Apidianaki,M.,Al-Khalifa,H.,Eugenio,B.D.,Schockaert,S.(eds.)Proceedings of the 31st International Conference on Computational Linguistics
Wei, Z., Deng, J., Pang, L., Ding, H., Shen, H., Cheng, X.: MLaKE: Multilingual knowledge editing benchmark for large language models. In: Rambow, O., Wanner, L.,Apidianaki,M.,Al-Khalifa,H.,Eugenio,B.D.,Schockaert,S.(eds.)Proceedings of the 31st International Conference on Computational Linguistics. pp. 4457–4473. Association for Computational Linguistics...
2025
-
[16]
In: Proceedings of the 31st International Conference on Computational Linguistics
Wei, Z., Deng, J., Pang, L., Ding, H., Shen, H., Cheng, X.: Mlake: Multilingual knowledge editing benchmark for large language models. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 4457–4473. Asso- ciation for Computational Linguistics (2025)
2025
- [17]
- [19]
- [20]
-
[21]
A comprehensive study of knowledge editing for large language models,
Zhang, J., et al.: A comprehensive study of knowledge editing for large language models. arXiv preprint arXiv:2401.01286 (2024)
-
[22]
Zhang, Z., Li, Y., Kan, Z., Cheng, K., Hu, L., Wang, D.: Locate-then-edit for multi- hop factual recall under knowledge editing (2025),https://arxiv.org/abs/2410. 06331
2025
-
[23]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2024)
Zhong, X., et al.: Assessing knowledge editing in language models via multi-hop questions. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2024)
2024
-
[24]
Zhu, C., Rawat, A.S., Zaheer, M., Bhojanapalli, S., Li, D., Yu, F., Kumar, S.: Modifyingmemoriesintransformermodels(2020),https://arxiv.org/abs/2012. 00363
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.