From Data Heterogeneity to Convergence: A Data-Centric Review of Federated Learning
Pith reviewed 2026-06-27 12:40 UTC · model grok-4.3
The pith
This survey ranks non-IID data traits by influence on federated learning convergence and makes the convergence-robustness trade-off explicit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The survey claims to deliver the first complete understanding of data-related challenges that govern federated learning by analyzing non-IID traits and ranking their convergence influence, connecting splitting practices to real phenomena while exposing artifacts, and reporting how defenses affect convergence and robustness in clean versus adversarial settings, with clear takeaways for each concern.
What carries the argument
The ranking of non-IID traits by convergence influence (strong, medium, light) together with the explicit mapping of splitting practices to real phenomena and the convergence-robustness trade-off analysis.
If this is right
- Practitioners gain prioritized guidance on which data traits to address first to improve convergence speed and stability.
- Data splitting protocols can be selected to reduce artifacts and better align experimental accuracy with target real-world performance.
- Defenses can be evaluated and chosen with explicit knowledge of their effects on convergence under both clean and attack conditions.
- System designs can incorporate the ranked traits and trade-off information to achieve more predictable federated training results.
Where Pith is reading between the lines
- The trait-ranking approach could be tested as a diagnostic tool when deploying federated systems on new data modalities beyond the surveyed domains.
- Reconciling results across data types suggests the value of developing standardized heterogeneity metrics that generalize beyond images, text, and graphs.
- The explicit convergence-robustness mapping points toward hybrid defense strategies that optimize both objectives simultaneously rather than treating them separately.
- Connections drawn between splitting artifacts and accuracy could motivate creation of benchmark datasets that reduce emulation gaps.
Load-bearing premise
The selected literature and experimental evidence across images, texts, and graphs are representative enough to support general rankings of trait influence and to reconcile conflicting results without systematic omission of counter-evidence.
What would settle it
A new review or set of experiments that produces materially different rankings of non-IID trait influences or reveals unaddressed conflicts across data types would falsify the claimed synthesis.
Figures

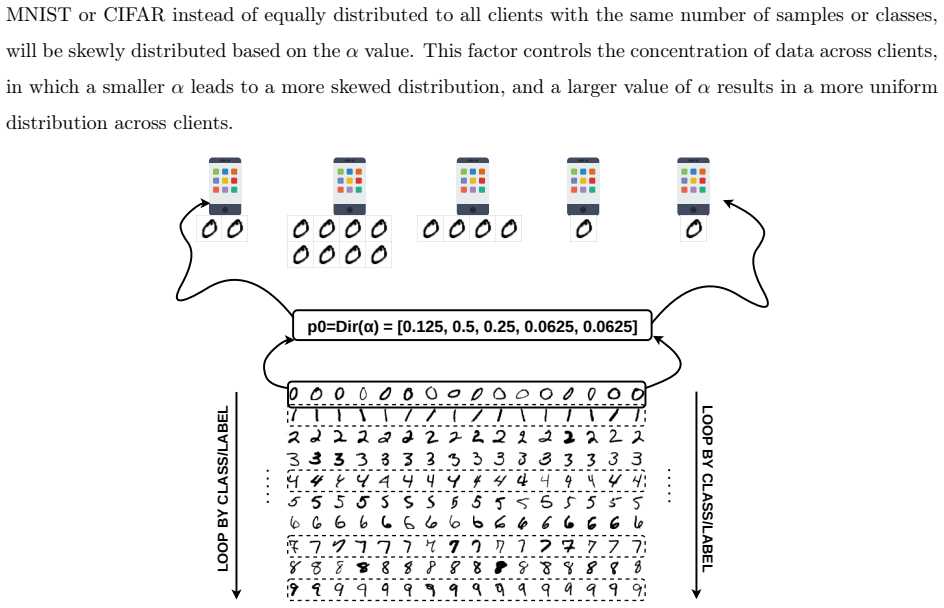





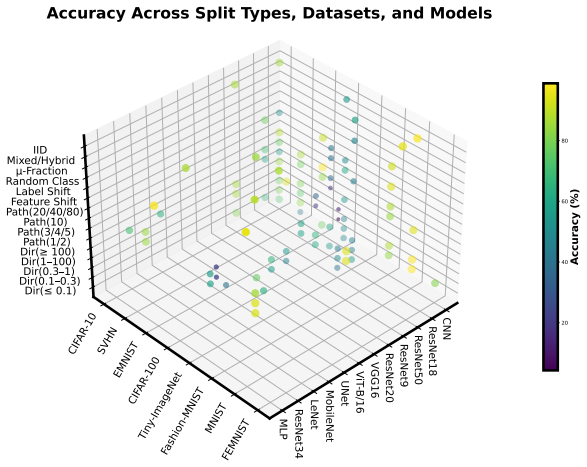
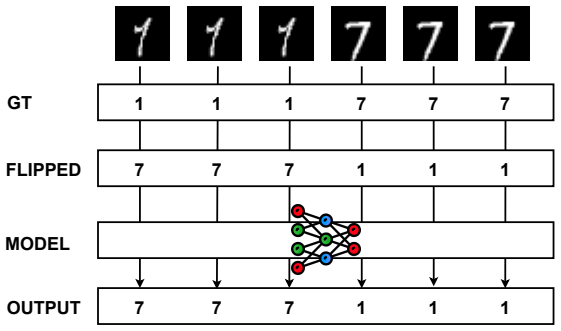
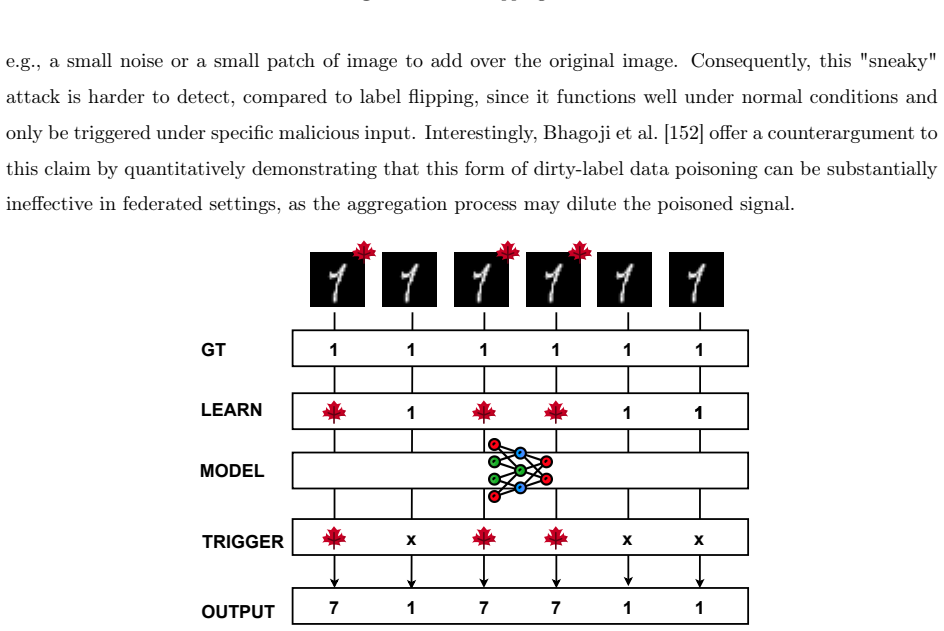




read the original abstract
Federated Learning (FL) has emerged as a promising solution for data hunger in centralized learning. This paradigm enables privacy with multiple clients to train a shared-task model collaboratively without exposing their local data. While being a key component in any learning system, data is also a primary source of vulnerabilities and challenges, and a major determinant of a stable and well-converged training. Existing FL reviews describe general foundations, security practices, opportunities, challenges, and applications, without delving into diverse aspects of data and considering problems from the data perspective. They rarely provide a data-lens synthesis that links concrete data properties, split protocols, and defenses to convergence speed and stability. This survey fills that gap with three advances. First, we analyze non-IID into measurable traits and rank their influence on convergence as strong, medium, or light, explaining the mechanisms behind each and reconciling evidence across images, texts, and graphs. Second, we connect experimental splitting practices to the real phenomena they emulate, expose the artifacts they introduce, and show how those artifacts affect target accuracy. Third, we analyze how data-related vulnerabilities and their proposed defenses affect convergence, reporting performance under clean and adversarial conditions to make the convergence-robustness trade-off explicit. To our knowledge, this is the first survey to provide a complete understanding of data-related challenges that govern FL. With clear takeaways distilled for each concern, our work serves as actionable guidance, helping practitioners design their system with predictable convergence and stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey claiming to be the first data-centric review of Federated Learning that fully addresses data-related challenges governing convergence. It advances three contributions: (1) decomposing non-IID into measurable traits and ranking their influence on convergence (strong/medium/light) while explaining mechanisms and reconciling evidence across images, texts, and graphs; (2) mapping experimental data-splitting practices to the real-world phenomena they emulate, exposing introduced artifacts, and showing effects on target accuracy; (3) analyzing data vulnerabilities and defenses under both clean and adversarial conditions to make the convergence-robustness trade-off explicit. The work distills actionable takeaways for practitioners.
Significance. If the literature synthesis and rankings are comprehensive and reproducible, the survey would provide useful guidance by making explicit how specific data properties and defenses affect FL convergence and stability. Credit is due for the multi-modality coverage and for attempting to link splitting artifacts and adversarial settings to convergence outcomes. As a synthesis without new derivations or primary experiments, its value hinges on transparent selection and accurate reconciliation of prior results.
major comments (2)
- [Abstract and Introduction] Abstract and Introduction: The central claims of providing a 'complete understanding' and ranking non-IID traits by influence rest on the representativeness of the cited studies. No systematic review protocol, search strategy, inclusion/exclusion criteria, or time frame is described, so the qualitative reconciliation of conflicting results across modalities cannot be verified for completeness or bias. This is load-bearing for the ranking taxonomy and the 'first such survey' assertion.
- [Trait-ranking section] Trait-ranking section (the section presenting the strong/medium/light classification): The rankings are derived from narrative synthesis of selected papers rather than quantitative aggregation such as effect-size meta-analysis. Without an explicit protocol, omitted counter-evidence (e.g., recent graph-FL or transformer-client studies) could alter the relative influence ordering, undermining the general claim.
minor comments (1)
- [Abstract] Abstract: The claim of being the 'first' survey would benefit from a brief comparison table or sentence distinguishing it from the 'existing FL reviews' mentioned, to clarify novelty without relying solely on author knowledge.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our literature synthesis. We agree that explicitly documenting the review process will strengthen the verifiability of the trait rankings and the 'first such survey' claim. We will add a dedicated 'Review Methodology' subsection (approximately 400 words) in the Introduction that details search strategy, databases, time frame, inclusion/exclusion criteria, and reconciliation approach. This revision directly addresses both major comments without altering the core contributions. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and Introduction: The central claims of providing a 'complete understanding' and ranking non-IID traits by influence rest on the representativeness of the cited studies. No systematic review protocol, search strategy, inclusion/exclusion criteria, or time frame is described, so the qualitative reconciliation of conflicting results across modalities cannot be verified for completeness or bias. This is load-bearing for the ranking taxonomy and the 'first such survey' assertion.
Authors: We acknowledge the absence of an explicit protocol description, which limits independent verification of completeness. In revision we will insert a new 'Review Methodology' subsection that specifies: (i) search terms and databases (Google Scholar, arXiv, IEEE Xplore with keywords 'federated learning non-IID data heterogeneity convergence' 2017–2024); (ii) inclusion criteria (empirical studies reporting convergence metrics under controlled data traits across vision, language, and graph modalities); (iii) exclusion criteria (purely theoretical works without empirical validation, non-peer-reviewed preprints after 2023); and (iv) the narrative reconciliation process used to resolve conflicting modality-specific findings. We will also qualify the 'complete understanding' phrasing to 'comprehensive synthesis of key empirical evidence' to avoid overstatement. These changes make the synthesis reproducible while preserving the multi-modality scope. revision: yes
-
Referee: [Trait-ranking section] Trait-ranking section (the section presenting the strong/medium/light classification): The rankings are derived from narrative synthesis of selected papers rather than quantitative aggregation such as effect-size meta-analysis. Without an explicit protocol, omitted counter-evidence (e.g., recent graph-FL or transformer-client studies) could alter the relative influence ordering, undermining the general claim.
Authors: The rankings are intentionally qualitative because standardized effect sizes are unavailable across the heterogeneous experimental setups in the cited literature; a formal meta-analysis would require re-implementation of dozens of studies, which exceeds survey scope. We will revise the section to: (a) explicitly state the narrative synthesis protocol (same as the new methodology subsection); (b) add a limitations paragraph acknowledging that recent graph-FL and transformer-client papers (e.g., post-2023 works) were reviewed but did not overturn the ordering; and (c) include a sensitivity note that future quantitative aggregation could refine the strong/medium/light labels. This maintains the contribution while addressing reproducibility concerns. revision: partial
Circularity Check
No circularity: literature synthesis without derivations or self-referential reductions
full rationale
This survey synthesizes external literature on FL data heterogeneity without introducing equations, fitted parameters, predictions, or ansatzes. Claims such as trait rankings and convergence-robustness trade-offs are presented as distillations from reviewed papers rather than derived internally. No self-citation chain is load-bearing for a mathematical result, and no step reduces by construction to the paper's own inputs. The work is self-contained as a review against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Yan, B. Gong, Y. Wei, Y. Gao, Deep multi-view enhancement hashing for image retrieval, IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (4) (2020) 1445–1451
2020
-
[2]
C. Yan, Z. Li, Y. Zhang, Y. Liu, X. Ji, Y. Zhang, Depth image denoising using nuclear norm and learn- ing graph model, ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 16 (4) (2020) 1–17
2020
-
[3]
McMahan, E
B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in: Artificial intelligence and statistics, PMLR, 2017, pp. 1273–1282
2017
-
[4]
D. C. Nguyen, M. Ding, P. N. Pathirana, A. Seneviratne, J. Li, H. V. Poor, Federated learning for internet of things: A comprehensive survey, IEEE Communications Surveys & Tutorials 23 (3) (2021) 1622–1658
2021
-
[5]
Zhang, Y
C. Zhang, Y. Xie, H. Bai, B. Yu, W. Li, Y. Gao, A survey on federated learning, Knowledge-Based Systems 216 (2021) 106775
2021
-
[6]
J. Wen, Z. Zhang, Y. Lan, Z. Cui, J. Cai, W. Zhang, A survey on federated learning: challenges and applications, International Journal of Machine Learning and Cybernetics 14 (2) (2023) 513–535. 46
2023
-
[7]
J. Liu, J. Huang, Y. Zhou, X. Li, S. Ji, H. Xiong, D. Dou, From distributed machine learning to federated learning: A survey, Knowledge and Information Systems 64 (4) (2022) 885–917
2022
-
[8]
Aledhari, R
M. Aledhari, R. Razzak, R. M. Parizi, F. Saeed, Federated learning: A survey on enabling technologies, protocols, and applications, IEEE Access 8 (2020) 140699–140725
2020
-
[9]
AbdulRahman, H
S. AbdulRahman, H. Tout, H. Ould-Slimane, A. Mourad, C. Talhi, M. Guizani, A survey on federated learning: The journey from centralized to distributed on-site learning and beyond, IEEE Internet of Things Journal 8 (7) (2020) 5476–5497
2020
-
[10]
H. Zhu, J. Xu, S. Liu, Y. Jin, Federated learning on non-iid data: A survey, Neurocomputing 465 (2021) 371–390
2021
-
[11]
Mothukuri, R
V. Mothukuri, R. M. Parizi, S. Pouriyeh, Y. Huang, A. Dehghantanha, G. Srivastava, A survey on security and privacy of federated learning, Future Generation Computer Systems 115 (2021) 619–640
2021
-
[12]
J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y. Yang, Y. Zhou, Deep learning scaling is predictable, empirically, arXiv preprint arXiv:1712.00409 (2017)
Pith/arXiv arXiv 2017
-
[13]
C. Sun, A. Shrivastava, S. Singh, A. Gupta, Revisiting unreasonable effectiveness of data in deep learning era, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 843–852
2017
-
[14]
X. Zhu, C. Vondrick, D. Ramanan, C. C. Fowlkes, Do we need more training data or better models for object detection?., in: BMVC, Vol. 3, Citeseer, 2012
2012
-
[15]
Parsons, F
Z. Parsons, F. Dou, H. Du, Z. Song, J. Lu, Mobilizing personalized federated learning in infrastructure- less and heterogeneous environments via random walk stochastic admm, Advances in Neural Informa- tion Processing Systems 36 (2023) 36726–36737
2023
-
[16]
Chen, H.-W
Y.-C. Chen, H.-W. Chen, S.-G. Wang, M.-S. Chen, Space: Single-round participant amalgamation for contribution evaluation in federated learning, Advances in Neural Information Processing Systems 36 (2023) 6422–6441
2023
-
[17]
J. Jia, Z. Yuan, D. Sahabandu, L. Niu, A. Rajabi, B. Ramasubramanian, B. Li, R. Poovendran, Fedgame: a game-theoretic defense against backdoor attacks in federated learning, Advances in Neural Information Processing Systems 36 (2023) 53090–53111
2023
-
[18]
Y. Sun, L. Shen, D. Tao, Understanding how consistency works in federated learning via stage-wise relaxed initialization, Advances in Neural Information Processing Systems 36 (2023) 80543–80574. 47
2023
-
[19]
H. Wang, P. Zheng, X. Han, W. Xu, R. Li, T. Zhang, Fednlr: Federated learning with neuron-wise learning rates, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3069–3080
2024
-
[20]
J. Xu, S. Wan, Y. Li, S. Luo, Z. Chen, Y. Shao, Z. Chen, S.-L. Huang, L. Song, Cooperative multi- modeltrainingforpersonalizedfederatedlearningoverheterogeneousdevices, IEEEJournalofSelected Topics in Signal Processing (2024)
2024
-
[21]
X. Yang, W. Huang, M. Ye, Dynamic personalized federated learning with adaptive differential privacy, Advances in Neural Information Processing Systems 36 (2023) 72181–72192
2023
-
[22]
I. Wang, P. Nair, D. Mahajan, Fluid: Mitigating stragglers in federated learning using invariant dropout, Advances in Neural Information Processing Systems 36 (2023) 73258–73273
2023
-
[23]
Crawshaw, Y
M. Crawshaw, Y. Bao, M. Liu, Federated learning with client subsampling, data heterogeneity, and un- bounded smoothness: A new algorithm and lower bounds, Advances in Neural Information Processing Systems 36 (2023) 6467–6508
2023
-
[24]
M. Shi, Y. Zhou, K. Wang, H. Zhang, S. Huang, Q. Ye, J. Lv, Prior: Personalized prior for reactivating the information overlooked in federated learning., Advances in Neural Information Processing Systems 36 (2023) 28378–28392
2023
-
[25]
Panchal, S
K. Panchal, S. Choudhary, S. Mitra, K. Mukherjee, S. Sarkhel, S. Mitra, H. Guan, Flash: concept drift adaptation in federated learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 26931–26962
2023
-
[26]
G. Wan, Z. Shi, W. Huang, G. Zhang, D. Tao, M. Ye, Energy-based backdoor defense against federated graph learning, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
S. Kim, Y. Lee, Y. Oh, N. Lee, S. Yun, J. Lee, S. Kim, C. Yang, C. Park, Subgraph federated learning for local generalization, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
X. Li, K. Huang, W. Yang, S. Wang, Z. Zhang, On the convergence of fedavg on non-iid data, arXiv preprint arXiv:1907.02189 (2019)
arXiv 1907
-
[29]
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, V. Smith, Federated optimization in hetero- geneous networks, Proceedings of Machine learning and systems 2 (2020) 429–450
2020
-
[30]
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, A. T. Suresh, Scaffold: Stochastic controlled averaging for federated learning, in: International conference on machine learning, PMLR, 2020, pp. 5132–5143. 48
2020
-
[31]
S. U. Stich, Local sgd converges fast and communicates little, arXiv preprint arXiv:1805.09767 (2018)
Pith/arXiv arXiv 2018
-
[32]
Y. Tan, C. Chen, W. Zhuang, X. Dong, L. Lyu, G. Long, Is heterogeneity notorious? taming het- erogeneity to handle test-time shift in federated learning, Advances in neural information processing systems 36 (2023) 27167–27180
2023
-
[33]
M. M. Rahimi, H. I. Bhatti, Y. Park, H. Kousar, J. Moon, Evofed: leveraging evolutionary strategies for communication-efficient federated learning, Advances in Neural Information Processing Systems 36 (2023) 62428–62441
2023
-
[34]
H. Zhou, T. Lan, G. P. Venkataramani, W. Ding, Every parameter matters: Ensuring the convergence of federated learning with dynamic heterogeneous models reduction, Advances in Neural Information Processing Systems 36 (2024)
2024
-
[35]
Nguyen, H.-T
H. Nguyen, H.-T. Nguyen, L. Lovén, S. Pirttikangas, Stake-driven rewards and log-based free rider detection in federated learning, in: 2024 21st Annual International Conference on Privacy, Security and Trust (PST), IEEE, 2024, pp. 1–10
2024
-
[36]
J. Ma, T. Zhou, G. Long, J. Jiang, C. Zhang, Structured federated learning through clustered additive modeling, Advances in Neural Information Processing Systems 36 (2023) 43097–43107
2023
-
[37]
Z. Yang, Y. Zhang, Y. Zheng, X. Tian, H. Peng, T. Liu, B. Han, Fedfed: Feature distillation against data heterogeneity in federated learning, Advances in neural information processing systems 36 (2023) 60397–60428
2023
-
[38]
Zehtabi, D.-J
S. Zehtabi, D.-J. Han, R. Parasnis, S. Hosseinalipour, C. G. Brinton, Decentralized sporadic fed- erated learning: A unified algorithmic framework with convergence guarantees, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[39]
Z. Wang, Z. Wang, L. Lyu, Z. Peng, Z. Yang, C. Wen, R. Yu, C. Wang, X. Fan, Fedsac: Dynamic submodel allocation for collaborative fairness in federated learning, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3299–3310
2024
-
[40]
D. Chen, L. Yao, D. Gao, B. Ding, Y. Li, Efficient personalized federated learning via sparse model- adaptation, in: International conference on machine learning, PMLR, 2023, pp. 5234–5256
2023
-
[41]
Panchal, S
K. Panchal, S. Choudhary, N. Parikh, L. Zhang, H. Guan, Flow: per-instance personalized federated learning, Advances in Neural Information Processing Systems 36 (2024)
2024
-
[42]
Dorfman, S
R. Dorfman, S. Vargaftik, Y. Ben-Itzhak, K. Y. Levy, Docofl: Downlink compression for cross-device federated learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 8356–8388. 49
2023
-
[43]
W. Yan, K. Zhang, X. Wang, X. Cao, Problem-parameter-free federated learning, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[44]
39879–39902
R.Ye, M.Xu, J.Wang, C.Xu, S.Chen, Y.Wang, Feddisco: Federatedlearningwithdiscrepancy-aware collaboration, in: International Conference on Machine Learning, PMLR, 2023, pp. 39879–39902
2023
-
[45]
H. Yan, W. Zhang, Q. Chen, X. Li, W. Sun, H. Li, X. Lin, Recess vaccine for federated learning: Proactivedefenseagainstmodelpoisoningattacks, AdvancesinNeuralInformationProcessingSystems 36 (2023) 8702–8713
2023
-
[46]
T. Xia, A. Ghosh, X. Qiu, C. Mascolo, Flea: Addressing data scarcity and label skew in federated learning via privacy-preserving feature augmentation, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3484–3494
2024
-
[47]
W. Bao, H. Wang, J. Wu, J. He, Optimizing the collaboration structure in cross-silo federated learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 1718–1736
2023
-
[48]
X. An, L. Shen, H. Hu, Y. Luo, Federated learning with manifold regularization and normalized update reaggregation, Advances in Neural Information Processing Systems 36 (2023) 55097–55109
2023
-
[49]
Zhang, X
F. Zhang, X. Liu, S. Lin, G. Wu, X. Zhou, J. Jiang, X. Ji, No one idles: Efficient heterogeneous federated learning with parallel edge and server computation, in: International Conference on Machine Learning, PMLR, 2023, pp. 41399–41413
2023
-
[50]
H. Chen, M. Hao, H. Li, K. Chen, G. Xu, T. Zhang, X. Zhang, Guardhfl: privacy guardian for heterogeneous federated learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 4566–4584
2023
-
[51]
M. Hu, Z. Yue, X. Xie, C. Chen, Y. Huang, X. Wei, X. Lian, Y. Liu, M. Chen, Is aggregation the only choice? federated learning via layer-wise model recombination, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 1096–1107
2024
-
[52]
Z.Liu, Z. Xu, B. Coleman, A.Shrivastava, One-pass distributionsketch for measuring dataheterogene- ity in federated learning, Advances in Neural Information Processing Systems 36 (2023) 15660–15679
2023
-
[53]
3667–3678
G.Yan, H.Wang, X.Yuan, J.Li, Fedrola: Robustfederatedlearningagainstmodelpoisoningvialayer- based aggregation, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3667–3678
2024
-
[54]
Y. Wu, S. Zhang, W. Yu, Y. Liu, Q. Gu, D. Zhou, H. Chen, W. Cheng, Personalized federated learning under mixture of distributions, in: International Conference on Machine Learning, PMLR, 2023, pp. 37860–37879. 50
2023
-
[55]
Z. Guo, D. Yao, Q. Yang, H. Liu, Hifgl: A hierarchical framework for cross-silo cross-device federated graph learning, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 968–979
2024
-
[56]
Kairouz, H
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, et al., Advances and open problems in federated learning, Foundations and trends®in machine learning 14 (1–2) (2021) 1–210
2021
-
[57]
Bonawitz, H
K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konečn` y, S. Mazzocchi, B. McMahan, et al., Towards federated learning at scale: System design, Proceedings of machine learning and systems 1 (2019) 374–388
2019
-
[58]
J. Wang, Q. Liu, H. Liang, G. Joshi, H. V. Poor, Tackling the objective inconsistency problem in heterogeneous federated optimization, Advances in neural information processing systems 33 (2020) 7611–7623
2020
-
[59]
Darzidehkalani, M
E. Darzidehkalani, M. Ghasemi-Rad, P. Van Ooijen, Federated learning in medical imaging: part i: toward multicentral health care ecosystems, Journal of the american college of radiology 19 (8) (2022) 969–974
2022
-
[60]
Linardos, K
A. Linardos, K. Kushibar, S. Walsh, P. Gkontra, K. Lekadir, Federated learning for multi-center imaging diagnostics: a simulation study in cardiovascular disease, Scientific Reports 12 (1) (2022) 3551
2022
-
[61]
11814–11827
F.Lai, Y.Dai, S.Singapuram, J.Liu, X.Zhu, H.Madhyastha, M.Chowdhury, Fedscale: Benchmarking model and system performance of federated learning at scale, in: International conference on machine learning, PMLR, 2022, pp. 11814–11827
2022
-
[62]
Ślazyk, P
F. Ślazyk, P. Jabłecki, A. Lisowska, M. Malawski, S. Płotka, Cxr-fl: deep learning-based chest x- ray image analysis using federated learning, in: International Conference on Computational Science, Springer, 2022, pp. 433–440
2022
-
[63]
C. Yan, L. Meng, L. Li, J. Zhang, Z. Wang, J. Yin, J. Zhang, Y. Sun, B. Zheng, Age-invariant face recognition by multi-feature fusionand decomposition with self-attention, ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 18 (1s) (2022) 1–18
2022
-
[64]
Medar, V
R. Medar, V. S. Rajpurohit, B. Rashmi, Impact of training and testing data splits on accuracy of time series forecasting in machine learning, in: 2017 International Conference on Computing, Communica- tion, Control and Automation (ICCUBEA), IEEE, 2017, pp. 1–6. 51
2017
-
[65]
B. Vrigazova, The proportion for splitting data into training and test set for the bootstrap in clas- sification problems, Business Systems Research: International Journal of the Society for Advancing Innovation and Research in Economy 12 (1) (2021) 228–242
2021
-
[66]
A.Rácz, D.Bajusz, K.Héberger, Effectofdatasetsizeandtrain/testsplitratiosinqsar/qsprmulticlass classification, Molecules 26 (4) (2021) 1111
2021
-
[67]
J. Tan, J. Yang, S. Wu, G. Chen, J. Zhao, A critical look at the current train/test split in machine learning, arXiv preprint arXiv:2106.04525 (2021)
arXiv 2021
-
[68]
K. M. Kahloot, P. Ekler, Algorithmic splitting: A method for dataset preparation, IEEE Access 9 (2021) 125229–125237
2021
-
[69]
J. J. Salazar, L. Garland, J. Ochoa, M. J. Pyrcz, Fair train-test split in machine learning: Mitigating spatialautocorrelationforimprovedpredictionaccuracy, JournalofPetroleumScienceandEngineering 209 (2022) 109885
2022
-
[70]
I. Muraina, Ideal dataset splitting ratios in machine learning algorithms: general concerns for data scientists and data analysts, in: 7th international Mardin Artuklu scientific research conference, 2022, pp. 496–504
2022
-
[71]
V. R. Joseph, A. Vakayil, Split: An optimal method for data splitting, Technometrics 64 (2) (2022) 166–176
2022
-
[72]
Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, V. Chandra, Federated learning with non-iid data, arXiv preprint arXiv:1806.00582 (2018)
Pith/arXiv arXiv 2018
-
[73]
T. Li, A. K. Sahu, A. Talwalkar, V. Smith, Federated learning: Challenges, methods, and future directions, IEEE signal processing magazine 37 (3) (2020) 50–60
2020
-
[74]
A. Khan, M. Ten Thij, A. Wilbik, Vertical federated learning: A structured literature review, Knowl- edge and Information Systems 67 (4) (2025) 3205–3243
2025
-
[75]
Y. Liu, Y. Kang, T. Zou, Y. Pu, Y. He, X. Ye, Y. Ouyang, Y.-Q. Zhang, Q. Yang, Vertical federated learning: Concepts, advances, and challenges, IEEE Transactions on Knowledge and Data Engineering (2024)
2024
-
[76]
M. Ye, W. Shen, B. Du, E. Snezhko, V. Kovalev, P. C. Yuen, Vertical federated learning for effective- ness, security, applicability: A survey, ACM Computing Surveys 57 (9) (2025) 1–32. 52
2025
-
[77]
T. Feng, D. Bose, T. Zhang, R. Hebbar, A. Ramakrishna, R. Gupta, M. Zhang, S. Avestimehr, S. Narayanan, Fedmultimodal: A benchmark for multimodal federated learning, in: Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, 2023, pp. 4035–4045
2023
-
[78]
Zhang, L
T. Zhang, L. Gao, C. He, M. Zhang, B. Krishnamachari, A. S. Avestimehr, Federated learning for the internet of things: Applications, challenges, and opportunities, IEEE Internet of Things Magazine 5 (1) (2022) 24–29
2022
-
[79]
C. Xu, Y. Qu, Y. Xiang, L. Gao, Asynchronous federated learning on heterogeneous devices: A survey, Computer Science Review 50 (2023) 100595
2023
-
[80]
Y. Liu, C. Wang, X. Yuan, Badsampler: Harnessing the power of catastrophic forgetting to poi- son byzantine-robust federated learning, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 1944–1955
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.