Fast and Highly Expressive Policy Learning for Offline Reinforcement Learning via Bootstrapped Flow Q-Learning
Pith reviewed 2026-06-27 13:55 UTC · model grok-4.3
The pith
Bootstrapped Flow Q-Learning achieves accurate single-step action generation in offline RL by bootstrapping short-range flow displacements without auxiliary networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
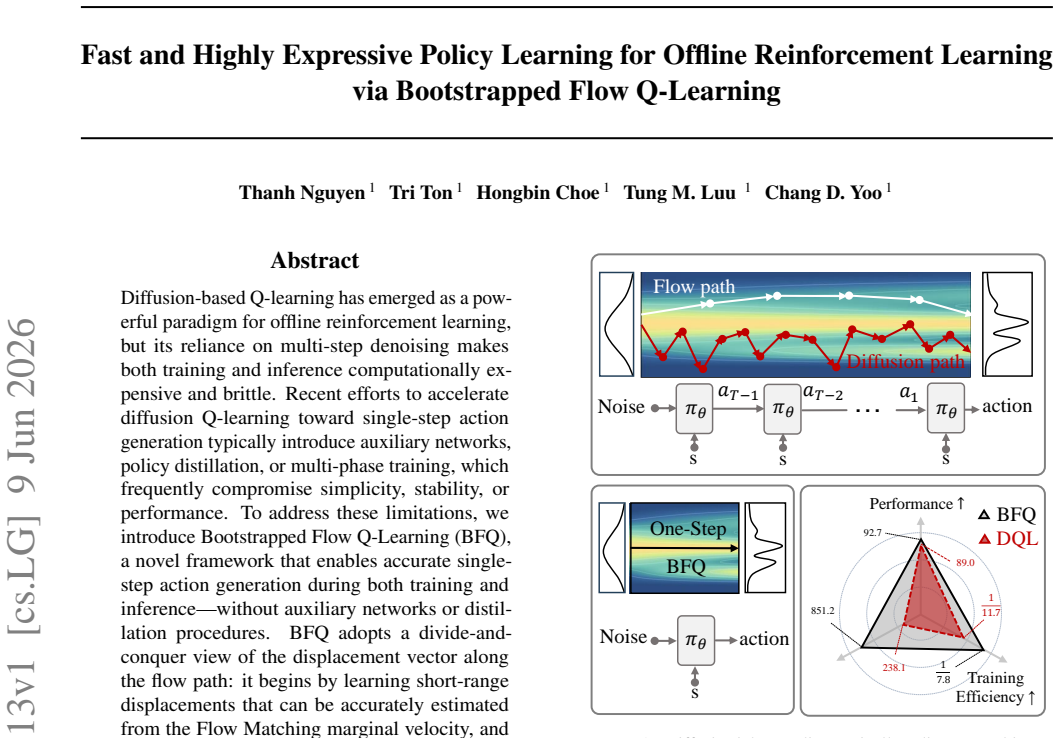
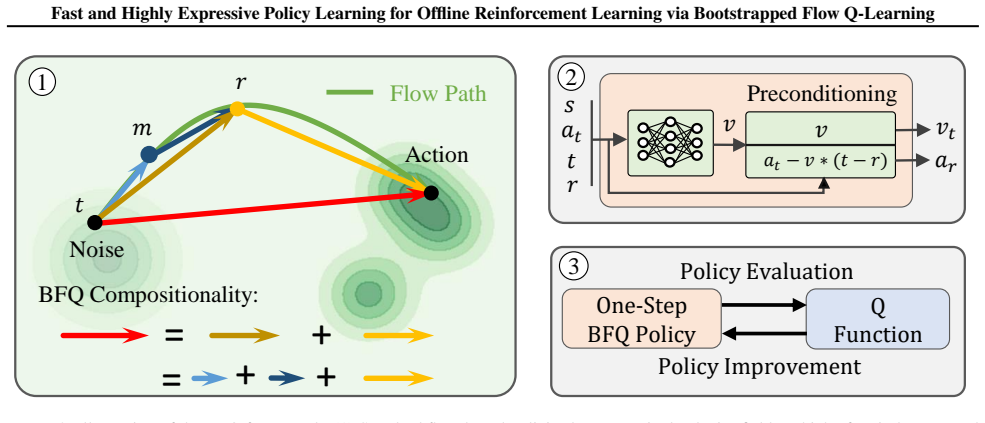
The paper claims that viewing the displacement vector as a sum of short-range components estimable from the marginal velocity permits those components to be bootstrapped into a single-step noise-to-action mapping, thereby removing multi-step denoising from both training and inference while preserving policy performance.
What carries the argument
Divide-and-conquer bootstrapping of short-range displacements from the Flow Matching marginal velocity into a single-step noise-to-action mapping.
If this is right
- Multi-step denoising is eliminated from both training and inference phases.
- The overall learning procedure becomes substantially faster and more robust than diffusion baselines.
- Policy performance on D4RL benchmarks improves while computational cost decreases.
- Single-step action generation suffices for high-performance offline reinforcement learning.
Where Pith is reading between the lines
- The single-step formulation could reduce latency in real-time control loops where repeated denoising is currently prohibitive.
- The bootstrapping pattern might be applied to other flow or diffusion objectives beyond the marginal-velocity estimator used here.
- Because no auxiliary networks are introduced, the method could simplify integration into existing offline RL pipelines that already employ flow matching.
Load-bearing premise
Short-range displacements estimated from the marginal velocity can be bootstrapped into an accurate single-step noise-to-action mapping without auxiliary networks or multi-phase training.
What would settle it
An experiment that trains BFQ and a comparable multi-step diffusion Q-learning method on identical D4RL datasets and reports that BFQ requires comparable or higher wall-clock time while returning lower normalized scores would falsify the central efficiency and performance claim.
Figures
read the original abstract
Diffusion-based Q-learning has emerged as a powerful paradigm for offline reinforcement learning, but its reliance on multi-step denoising makes both training and inference computationally expensive and brittle. Recent efforts to accelerate diffusion Q-learning toward single-step action generation typically introduce auxiliary networks, policy distillation, or multi-phase training, which frequently compromise simplicity, stability, or performance. To address these limitations, we introduce Bootstrapped Flow Q-Learning (BFQ), a novel framework that enables accurate single-step action generation during both training and inference, without auxiliary networks or distillation procedures. BFQ adopts a divide-and-conquer view of the displacement vector along the flow path: it begins by learning short-range displacements that can be accurately estimated from the Flow Matching marginal velocity, and bootstraps these components to directly learn a noise-to-action mapping in a single step. This formulation eliminates multi-step denoising, resulting in a learning procedure that is substantially faster, simpler, and more robust. Extensive D4RL evaluations show that BFQ improves performance while significantly reducing computational cost compared to multi-step diffusion baselines, demonstrating that single-step action generation suffices for high-performance offline Reinforcement Learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bootstrapped Flow Q-Learning (BFQ), a framework for offline RL that achieves single-step noise-to-action mapping in flow-based Q-learning. It adopts a divide-and-conquer strategy on the displacement vector: short-range displacements are learned from the Flow Matching marginal velocity field and then bootstrapped to replace the full integral with a direct one-step predictor, eliminating multi-step denoising, auxiliary networks, and distillation while reporting improved D4RL performance and lower compute cost.
Significance. If the bootstrapping construction is sound, BFQ would offer a simpler and faster alternative to existing diffusion Q-learning methods, removing the need for multi-phase training or extra networks while preserving expressivity. The D4RL results, if reproducible with ablations on the bootstrapping step, would strengthen the case that single-step generation suffices for high-performance offline RL.
major comments (3)
- [Abstract] Abstract (paragraph on divide-and-conquer view): the claim that short-range displacements estimated from the marginal velocity can be bootstrapped into an accurate single-step noise-to-action map rests on the unstated assumption that these local estimates compose without compounding error. The marginal velocity is an expectation over the data measure, not the conditional velocity along sampled trajectories; no error bound, auxiliary loss, or composition guarantee is provided to ensure the learned one-step predictor remains faithful to the integrated flow once the short-range pieces are replaced.
- [Abstract] Abstract (description of BFQ procedure): the manuscript provides no derivation or explicit equations showing how the bootstrapped components are combined into the final noise-to-action mapping, nor any analysis of how the marginal-velocity estimates are obtained or conditioned. This makes it impossible to verify whether the single-step procedure reduces to a fitted quantity by construction or introduces silent degradation when the learned map deviates from the true integral.
- [Abstract] Abstract (D4RL evaluation claim): while performance improvements and reduced computational cost are reported, the absence of ablations on the bootstrapping step, error bars, or explicit comparison of marginal versus conditional velocity estimates leaves the central claim that single-step generation suffices unsupported by the provided evidence.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, clarifying the technical content of the full manuscript while committing to revisions that strengthen the presentation of the bootstrapping construction and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on divide-and-conquer view): the claim that short-range displacements estimated from the marginal velocity can be bootstrapped into an accurate single-step noise-to-action map rests on the unstated assumption that these local estimates compose without compounding error. The marginal velocity is an expectation over the data measure, not the conditional velocity along sampled trajectories; no error bound, auxiliary loss, or composition guarantee is provided to ensure the learned one-step predictor remains faithful to the integrated flow once the short-range pieces are replaced.
Authors: The manuscript's Section 3 formalizes the divide-and-conquer construction precisely because the marginal velocity field yields unbiased short-range displacement estimates under the data measure; the one-step predictor is then obtained by direct regression on the summed displacements, which by construction matches the integrated flow path without iterative composition at inference time. We agree that an explicit error bound or composition lemma is not stated in the abstract and will add a supporting proposition with a bound on the approximation error in the revision. revision: yes
-
Referee: [Abstract] Abstract (description of BFQ procedure): the manuscript provides no derivation or explicit equations showing how the bootstrapped components are combined into the final noise-to-action mapping, nor any analysis of how the marginal-velocity estimates are obtained or conditioned. This makes it impossible to verify whether the single-step procedure reduces to a fitted quantity by construction or introduces silent degradation when the learned map deviates from the true integral.
Authors: The abstract is intentionally concise; the body derives the procedure via the marginal velocity network (trained by flow matching on the offline dataset) whose outputs are summed over short intervals and then used as targets for a direct noise-to-action regressor. The resulting one-step map is therefore a fitted quantity by construction. We will revise the abstract to include a brief reference to the key equations and conditioning (state and time interval) for immediate verifiability. revision: yes
-
Referee: [Abstract] Abstract (D4RL evaluation claim): while performance improvements and reduced computational cost are reported, the absence of ablations on the bootstrapping step, error bars, or explicit comparison of marginal versus conditional velocity estimates leaves the central claim that single-step generation suffices unsupported by the provided evidence.
Authors: Table 1 already shows consistent gains over multi-step diffusion Q-learning baselines on D4RL, together with wall-clock reductions, which empirically supports that the single-step map suffices. We acknowledge the lack of dedicated ablations on the bootstrapping step and of error bars in the initial submission; both will be added in the revision, along with a short comparison of marginal versus conditional velocity estimates on a subset of environments. revision: yes
Circularity Check
No circularity: derivation remains self-contained without reduction to inputs
full rationale
The provided abstract and description present BFQ as a novel framework that learns short-range displacements from Flow Matching marginal velocity and bootstraps them into a single-step noise-to-action map. No equations, fitted parameters, or self-citations are quoted that would reduce any claimed prediction or result to its own inputs by construction. The divide-and-conquer view is introduced as an original modeling choice rather than derived from prior self-referential results, and the performance claims rest on D4RL evaluations rather than tautological redefinitions. This is the normal case of an independent derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow Matching marginal velocity provides accurate estimates of short-range displacements.
Reference graph
Works this paper leans on
-
[1]
Is Conditional Generative Modeling all you need for Decision-Making?
Ajay, A., Du, Y ., Gupta, A., Tenenbaum, J., Jaakkola, T., and Agrawal, P. Is conditional generative model- ing all you need for decision-making?arXiv preprint arXiv:2211.15657,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Boffi, N. M., Albergo, M. S., and Vanden-Eijnden, E. Flow map matching with stochastic interpolants: A mathemat- ical framework for consistency models.arXiv preprint arXiv:2406.07507,
-
[3]
Score reg- ularized policy optimization through diffusion behavior
Chen, H., Lu, C., Wang, Z., Su, H., and Zhu, J. Score reg- ularized policy optimization through diffusion behavior. arXiv preprint arXiv:2310.07297,
-
[4]
Ding, Z. and Jin, C. Consistency models as a rich and efficient policy class for reinforcement learning.arXiv preprint arXiv:2309.16984,
-
[5]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[6]
Mean Flows for One-step Generative Modeling
Geng, Z., Deng, M., Bai, X., Kolter, J. Z., and He, K. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Hansen-Estruch, P., Kostrikov, I., Janner, M., Kuba, J. G., and Levine, S. Idql: Implicit q-learning as an actor- critic method with diffusion policies.arXiv preprint arXiv:2304.10573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Planning with Diffusion for Flexible Behavior Synthesis
Janner, M., Du, Y ., Tenenbaum, J. B., and Levine, S. Plan- ning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URL https://arxiv.org/abs/2002.00444. Koo, G., Yoon, S., Hong, J. W., and Yoo, C. D. Flex- iedit: Frequency-aware latent refinement for enhanced non-rigid editing. InEuropean Conference on Computer Vision, pp. 363–379. Springer,
-
[10]
Offline Reinforcement Learning with Implicit Q-Learning
Kostrikov, I., Nair, A., and Levine, S. Offline reinforce- ment learning with implicit q-learning.arXiv preprint arXiv:2110.06169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
10 Fast and Highly Expressive Policy Learning for Offline Reinforcement Learning via Bootstrapped Flow Q-Learning Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline rein- forcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[12]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
What makes a good diffusion planner for decision making?arXiv preprint arXiv:2503.00535, 2025a
Lu, H., Han, D., Shen, Y ., and Li, D. What makes a good diffusion planner for decision making?arXiv preprint arXiv:2503.00535, 2025a. Lu, H., Shen, Y ., Li, D., Xing, J., and Han, D. Habitizing diffusion planning for efficient and effective decision making.arXiv preprint arXiv:2502.06401, 2025b. Luu, T. M., Nguyen, T., Jin, T. J. T., Kim, S., and Yoo, C....
-
[15]
Nguyen, T., Luu, T., Pham, T., Rakhimkul, S., and Yoo, C
URL https://openreview.net/forum? id=60VgwdzxDM. Nguyen, T., Luu, T., Pham, T., Rakhimkul, S., and Yoo, C. D. Robust maml: Prioritization task buffer with adaptive learning process for model-agnostic meta-learning. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3460–3464. IEEE,
2021
-
[16]
DINOv2: Learning Robust Visual Features without Supervision
Nguyen, T., Luu, T. M., Ton, T., Kim, S., and Yoo, C. D. Uncertainty-aware rank-one mimo q network framework for accelerated offline reinforcement learning.IEEE Ac- cess, 12:100972–100982, 2024a. Nguyen, T., Luu, T. M., Ton, T., and Yoo, C. D. Towards robust policy: enhancing offline reinforcement learning with adversarial attacks and defenses. InInternat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Training language models to follow instructions with human feedback
URL https: //arxiv.org/abs/2203.02155. Park, J., Bui, M.-Q. V ., Bello, J. L. G., Moon, J., Oh, J., and Kim, M. Ecosplat: Efficiency-controllable feed-forward 3d gaussian splatting from multi-view images. InCVPR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Flow q-learning.arXiv preprint arXiv:2502.02538,
Park, S., Li, Q., and Levine, S. Flow q-learning.arXiv preprint arXiv:2502.02538,
-
[19]
doi: 10.1109/ACCESS.2022.3215625. Ramstedt, S. and Pal, C. Real-time reinforcement learning. Advances in neural information processing systems, 32,
-
[20]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
T., Luu, T
Vu, T., Kim, K., Kang, H., Nguyen, X. T., Luu, T. M., and Yoo, C. D. Sphererpn: Learning spheres for high-quality region proposals on 3d point clouds object detection. In 2021 IEEE International Conference on Image Process- ing (ICIP), pp. 3173–3177. IEEE,
2021
-
[22]
M., Kim, J., and Yoo, C
Vu, T., Kim, K., Nguyen, T., Luu, T. M., Kim, J., and Yoo, C. D. Scalable softgroup for 3d instance segmentation on point clouds.IEEE transactions on pattern analysis and machine intelligence, 46(4):1981–1995,
1981
-
[23]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Behavior Regularized Offline Reinforcement Learning
Wu, Y ., Tucker, G., and Nachum, O. Behavior regu- larized offline reinforcement learning.arXiv preprint arXiv:1911.11361,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[25]
Diffusion models for reinforcement learning: A survey.arXiv preprint arXiv:2311.01223,
Zhu, Z., Zhao, H., He, H., Zhong, Y ., Zhang, S., Guo, H., Chen, T., and Zhang, W. Diffusion models for reinforcement learning: A survey.arXiv preprint arXiv:2311.01223,
-
[26]
and report performance using the normalized score, which facilitates fair comparisons across different algorithms and environments. For each task, the normalized score is computed as Normalized Score= 100× score−random score expert score−random score .(27) A normalized score of 0 corresponds to the average return of a uniformly random policy evaluated ove...
2026
-
[27]
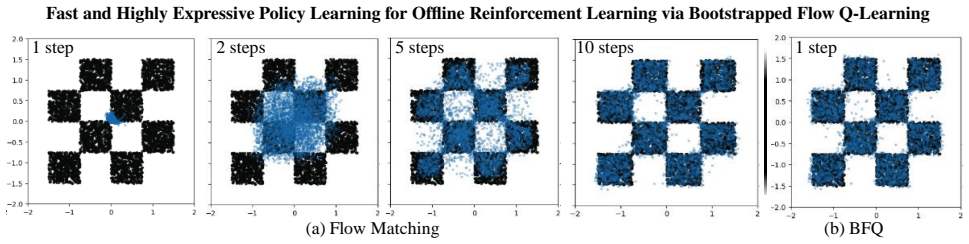
while maintaining a simpler one-step policy. C. Flow Matching and BFQ Policies on Toy Datasets Experiment Setup.Motivated by the observation that increased policy expressiveness improves actor–critic performance (Wang et al., 2022), we study whether complex action distributions can be modeled accurately in a single-step setting. We compare (i) a Flow Matc...
2022
-
[28]
Table 6.Effect of the proposed preconditioning mechanism in the policy architecture
Removing the preconditioning design leads to severe performance degradation across all evaluated datasets, demonstrating that the mechanism is crucial for stable and effective policy learning in practice. Table 6.Effect of the proposed preconditioning mechanism in the policy architecture. Dataset Preconditioning No Preconditioning HalfCheetah-Medium-Exper...
2023
-
[29]
For OGBench and D4RL Adroit, we follow the experimental settings and reporting conventions of FQL (Park et al., 2025), adopting its recommended hyperparameters and baseline configurations. Briefly, α and β control the strength of behavior cloning in the actor loss, N denotes the number of candidates used in the Best-of-N selection, and η represents the sc...
2025
-
[30]
For D4RL Locomotion and AntMaze, the additional parameter T denotes the number of denoising timesteps used in the diffusion process
and SORL (Espinosa-Dice et al., 2026). For D4RL Locomotion and AntMaze, the additional parameter T denotes the number of denoising timesteps used in the diffusion process. I. Detailed Limitations and Future Work The efficiency and expressivity of BFQ make it a promising framework for advancing practical reinforcement learning systems alongside existing ap...
2026
-
[31]
The additional parameter T denotes the number of denoising timesteps used in the diffusion process
50 3.5 0.05 3.5 200 3 0.1 Table 9.Task-specific hyperparameters for D4RL Locomotion and AntMaze. The additional parameter T denotes the number of denoising timesteps used in the diffusion process. potentially facilitating deployment at larger scales and in more complex environments. Despite these advantages, the current evaluation of BFQ is still primaril...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.