Earth-OneVision: Extending Remote Sensing Multimodal Large Language Models to More Sensor Modalities and Tasks
Pith reviewed 2026-06-27 13:14 UTC · model grok-4.3
The pith
A 2B-parameter model unifies six remote sensing sensor modalities and nine tasks in one autoregressive system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
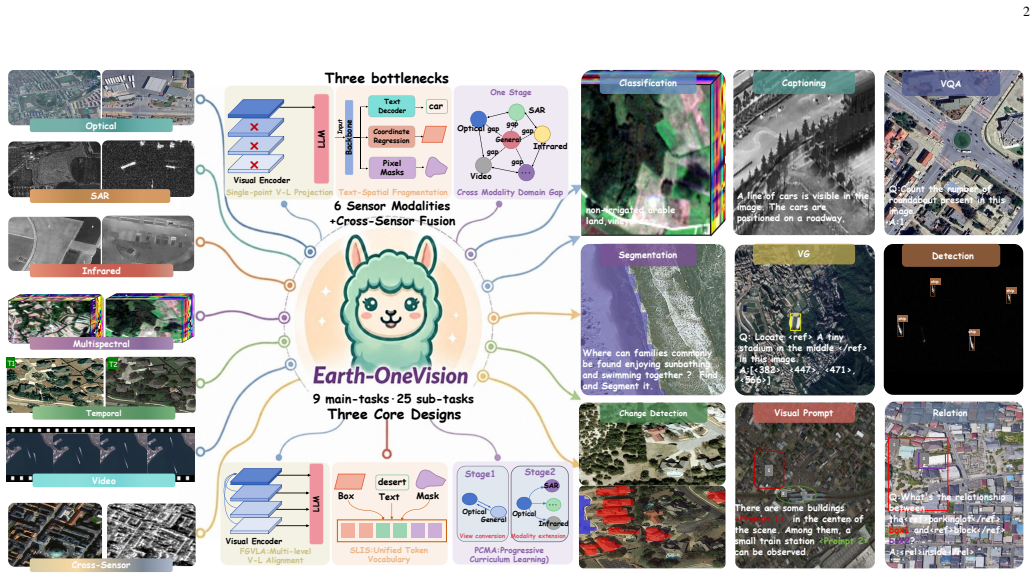
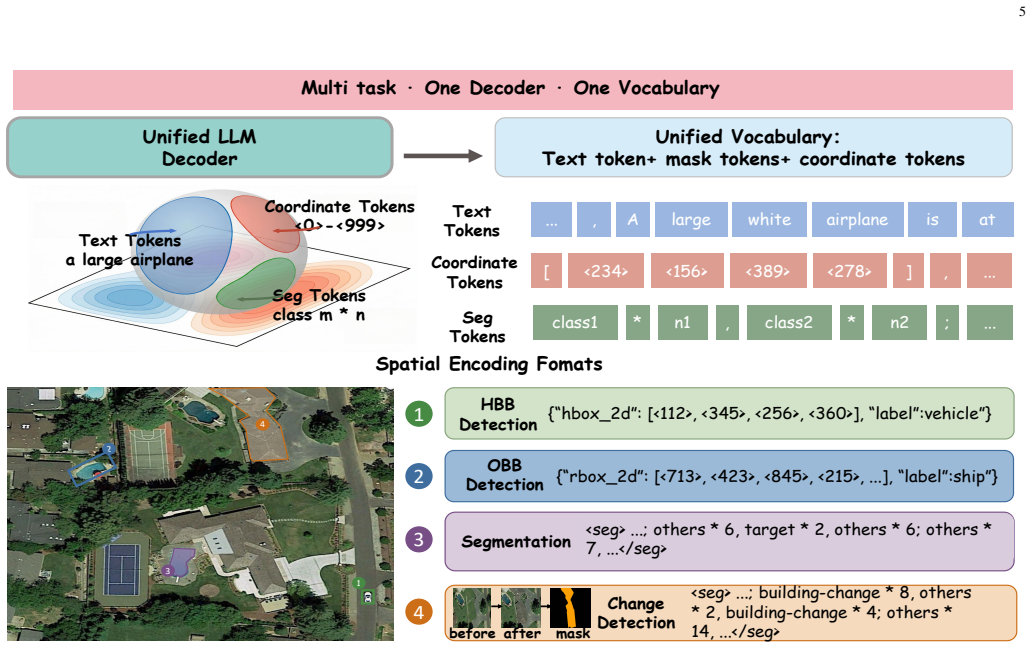
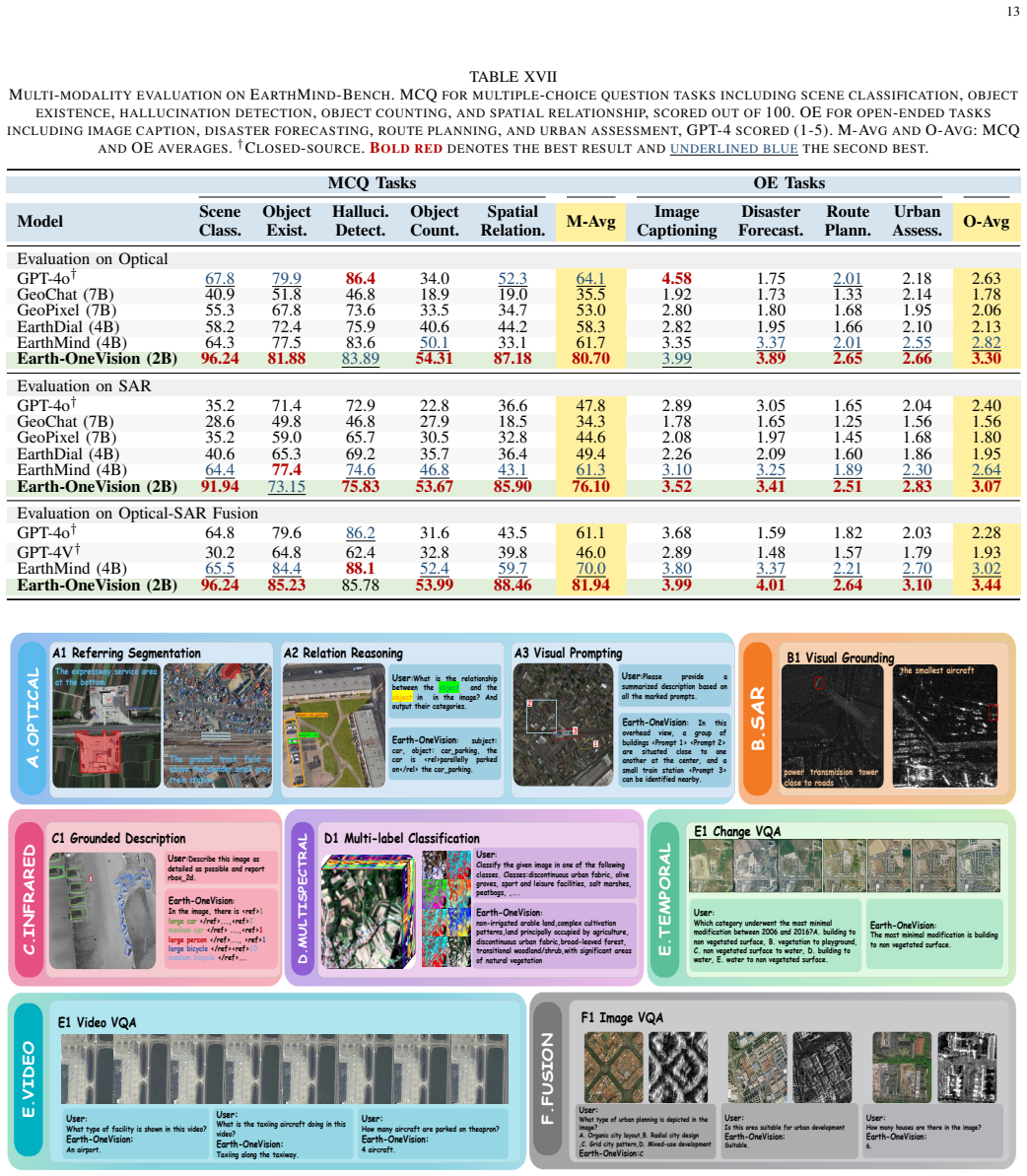
Earth-OneVision is a 2B RS-MLLM that unifies six sensor modalities and cross-sensor fusion across 9 task categories within a single autoregressive framework. Full-Granularity Vision-Language Alignment aligns multi-level visual features with multi-dimensional language space. Spatial-Linguistic Isomorphic Serialization unifies heterogeneous spatial outputs as autoregressive tokens. Progressive Cross-Modality Adaptation decomposes the domain gap into sequential stages. The MMRS-OneVision dataset of approximately 34M QA pairs enables joint training, and the model matches or exceeds 4B-72B models on benchmarks including 87.52% P@0.5 on OPT-RSVG, 80.68% on SARLANG-Bench, 75.74% recall on BigEarthN
What carries the argument
Full-Granularity Vision-Language Alignment (FGVLA), Spatial-Linguistic Isomorphic Serialization (SLIS), and Progressive Cross-Modality Adaptation (PCMA) that respectively align features, serialize outputs, and stage the modality adaptation.
If this is right
- A single model can perform optical visual grounding at 87.52% P@0.5 and SAR visual question answering at 80.68% accuracy.
- The same system reaches 75.74% recall on multispectral land-cover classification and 81.94% accuracy on cross-modality multiple-choice questions.
- Joint training across six modalities becomes feasible without separate models for each sensor type.
- Cross-sensor fusion tasks can be handled inside one autoregressive decoder rather than through post-hoc combination of outputs.
Where Pith is reading between the lines
- The unification could lower the computational cost of deploying remote-sensing language models in operational earth-observation pipelines.
- Extending the same staged adaptation to additional sensor types such as hyperspectral or LiDAR would test whether the domain-gap decomposition generalizes.
- The dataset construction method could be reused to add more task categories without retraining from scratch.
Load-bearing premise
The three mechanisms together with the new dataset close the gaps between sensor modalities without leaving biases or overfitting that would undermine joint performance.
What would settle it
A controlled ablation that removes FGVLA, SLIS, or PCMA one at a time and shows the resulting 2B model falling below the performance of 7B baselines on the SAR VQA or cross-modality reasoning benchmarks would falsify the claim.
Figures




read the original abstract
RS-MLLMs enable natural-language understanding and spatial reasoning over earth observation imagery. However, existing models support only a narrow range of sensor types and tasks, yielding a fragmented view of the earth and leaving cross-modal geoscientific knowledge largely unexploited. This work presents Earth-OneVision, a 2B RS-MLLM that unifies six sensor modalities (i.e., optical, SAR, infrared, multispectral, temporal, and video) and cross-sensor fusion across 9 task categories within a single autoregressive framework. Three dedicated mechanisms address three bottlenecks. Full-Granularity Vision-Language Alignment (FGVLA) aligns multi-level visual features with the multi-dimensional language space. Spatial-Linguistic Isomorphic Serialization (SLIS) unifies heterogeneous spatial outputs as autoregressive tokens. Progressive Cross-Modality Adaptation (PCMA) decomposes the compound domain gap into sequential stages, tackling the viewpoint and imaging physics gaps in turn. To support joint training, MMRS-OneVision is constructed with ~34M QA pairs spanning all six sensor modalities and cross-sensor fusion across 9 task categories, substantially exceeding existing RS multimodal instruction datasets. With only 2B parameters, Earth-OneVision achieves competitive or state-of-the-art results across extensive benchmarks, consistently matching or outperforming 4B-72B RS-MLLMs. It achieves 87.52% P@0.5 on the OPT-RSVG testset for optical visual grounding and 80.68% on the SAR VQA benchmark SARLANG-Bench, exceeding 7B models by over 7%. It further achieves 75.74% recall on the BigEarthNet-MS testset for multispectral classification, and 81.94% MCQ accuracy on EarthMind-Bench for cross-modality reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Earth-OneVision, a 2B-parameter remote sensing multimodal large language model (RS-MLLM) that unifies six sensor modalities (optical, SAR, infrared, multispectral, temporal, video) and nine task categories in a single autoregressive framework. It introduces three mechanisms—Full-Granularity Vision-Language Alignment (FGVLA) for multi-level visual-language feature alignment, Spatial-Linguistic Isomorphic Serialization (SLIS) for serializing heterogeneous spatial outputs as tokens, and Progressive Cross-Modality Adaptation (PCMA) for staged resolution of viewpoint and imaging-physics domain gaps—supported by the new MMRS-OneVision dataset of ~34M QA pairs. The central claim is that this compact model achieves competitive or state-of-the-art results across benchmarks, matching or exceeding 4B–72B RS-MLLMs (e.g., 87.52% P@0.5 on OPT-RSVG, 80.68% on SARLANG-Bench exceeding 7B models by >7%, 75.74% recall on BigEarthNet-MS, 81.94% MCQ accuracy on EarthMind-Bench).
Significance. If the empirical claims are robustly supported by controlled experiments, this would constitute a meaningful advance in remote sensing MLLMs by demonstrating effective joint handling of multiple sensor modalities and cross-modal tasks in a parameter-efficient model. The construction of the large-scale MMRS-OneVision dataset and the decomposition of domain gaps via PCMA represent concrete contributions that could enable more unified earth-observation reasoning; the reported ability of a 2B model to match larger ones on modality-specific and cross-modal benchmarks would be noteworthy if substantiated.
major comments (1)
- [Abstract] Abstract: the reported benchmark scores (87.52% P@0.5 on OPT-RSVG, 80.68% on SARLANG-Bench, 75.74% recall on BigEarthNet-MS, 81.94% on EarthMind-Bench) are presented without any mention of experimental controls, error bars, ablation studies, data splits, or baseline implementation details. Because these numbers are the sole quantitative support for the claim that the 2B model matches or exceeds 4B–72B models via FGVLA/SLIS/PCMA, the absence of such information is load-bearing for the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need for greater transparency around experimental details in the abstract. We address the comment directly below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benchmark scores (87.52% P@0.5 on OPT-RSVG, 80.68% on SARLANG-Bench, 75.74% recall on BigEarthNet-MS, 81.94% on EarthMind-Bench) are presented without any mention of experimental controls, error bars, ablation studies, data splits, or baseline implementation details. Because these numbers are the sole quantitative support for the claim that the 2B model matches or exceeds 4B–72B models via FGVLA/SLIS/PCMA, the absence of such information is load-bearing for the central empirical claim.
Authors: We agree that the abstract, constrained by length, does not explicitly reference experimental controls, error bars, ablation studies, data splits, or baseline implementation details. These elements are provided in full in the manuscript: Section 4.1 details dataset splits and preprocessing for all benchmarks; Section 4.2 describes baseline re-implementations and training protocols; Section 4.3 presents ablation studies isolating FGVLA, SLIS, and PCMA; and multiple-run statistics with standard deviations are reported for key metrics to indicate variability. All evaluations follow the official test splits and evaluation protocols of the cited benchmarks (OPT-RSVG, SARLANG-Bench, BigEarthNet-MS, EarthMind-Bench). To address the concern, we will revise the abstract to include a concise qualifier such as “Results are from controlled experiments with ablations and implementation details in Section 4.” This change preserves the abstract’s brevity while directing readers to the supporting evidence. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical construction: three architectural mechanisms (FGVLA, SLIS, PCMA) plus the MMRS-OneVision dataset are used to train a 2B-parameter model, with all performance numbers (e.g., 87.52% P@0.5, 80.68% on SARLANG-Bench) reported as measured outcomes on external benchmarks. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain; the central claims rest on observable benchmark results rather than any quantity defined in terms of itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Integrating machine learning and remote sensing in disaster management: A decadal review of post-disaster building damage assessment,
S. Al Shafian and D. Hu, “Integrating machine learning and remote sensing in disaster management: A decadal review of post-disaster building damage assessment,”Buildings, vol. 14, no. 8, p. 2344, 2024
2024
-
[2]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savareseet al., “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 730–19 742. 15
2023
-
[3]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Liet al., “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 296–26 306
2024
-
[4]
J. Bai, S. Bai, Y . Chuet al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Z. Chen, W. Wang, Y . Caoet al., “Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling,”arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Llava-onevision: Easy visual task transfer,
B. Li, Y . Zhang, D. Guoet al., “Llava-onevision: Easy visual task transfer,”Transactions on Machine Learning Research, 2024
2024
-
[7]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chenet al., “Lisa: Reasoning segmentation via large language model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9579–9589
2024
-
[8]
Rsgpt: A remote sensing vision language model and benchmark,
Y . Hu, J. Yuan, C. Wenet al., “Rsgpt: A remote sensing vision language model and benchmark,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 224, pp. 272–286, 2025
2025
-
[9]
Geochat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseeret al., “Geochat: Grounded large vision-language model for remote sensing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 831–27 840
2024
-
[10]
Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,
W. Zhang, M. Cai, T. Zhanget al., “Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,”IEEE Transactions on Geoscience and Remote Sens- ing, vol. 62, pp. 1–20, 2024
2024
-
[11]
arXiv preprint arXiv:2406.10100 , year=
J. Luo, Z. Pang, Y . Zhang, T. Wang, L. Wang, B. Dang, J. Lao, J. Wang, J. Chen, Y . Tan, and Y . Li, “Skysensegpt: A fine-grained instruction tuning dataset and model for remote sensing vision-language under- standing,”arXiv preprint arXiv:2406.10100, 2024
-
[12]
UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
S. Ni, D. Wang, H. Chenet al., “Unigeoseg: Towards uni- fied open-world segmentation for geospatial scenes,”arXiv preprint arXiv:2511.23332, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Dynamicvl: Benchmarking multimodal large language models for dynamic city understanding,
W. Xuan, J. Wang, H. Qi, Z. Chen, Z. Zheng, Y . Zhong, J. Xia, and N. Yokoya, “Dynamicvl: Benchmarking multimodal large language models for dynamic city understanding,”Advances in Neural Infor- mation Processing Systems, vol. 38, 2026
2026
-
[14]
Earthdial: Turning multi- sensory earth observations to interactive dialogues,
S. Soni, A. Dudhane, H. Debaryet al., “Earthdial: Turning multi- sensory earth observations to interactive dialogues,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 14 303–14 313
2025
-
[15]
Teochat: A large vision-language assistant for temporal earth observation data,
J. Irvin, E. Liu, J. Chen, I. Dormoy, J. Kim, S. Khanna, Z. Zheng, and S. Ermon, “Teochat: A large vision-language assistant for temporal earth observation data,” inInternational Conference on Learning Representations, 2025, pp. 68 883–68 911
2025
-
[16]
Earthmarker: A visual prompting multimodal large language model for remote sensing,
W. Zhang, M. Cai, T. Zhang, Y . Zhuang, J. Li, and X. Mao, “Earthmarker: A visual prompting multimodal large language model for remote sensing,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–19, 2024
2024
-
[17]
Earthgpt-x: A spatial mllm for multilevel multisource remote sensing imagery understanding with visual prompting,
W. Zhang, M. Cai, Y . Ning, T. Zhang, Y . Zhuang, S. Lu, H. Chen, J. Li, and X. Mao, “Earthgpt-x: A spatial mllm for multilevel multisource remote sensing imagery understanding with visual prompting,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–21, 2025
2025
-
[18]
arXiv preprint arXiv:2509.22221 , year=
J. Liu, L. Sun, R. Fuet al., “Towards faithful reasoning in remote sens- ing: A perceptually-grounded geospatial chain-of-thought for vision- language models,”arXiv preprint arXiv:2509.22221, 2025
-
[19]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacardet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
S. Bai, K. Chen, X. Liuet al., “Qwen2.5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Dota: A large-scale dataset for object detection in aerial images,
G.-S. Xia, X. Bai, J. Dinget al., “Dota: A large-scale dataset for object detection in aerial images,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 3974–3983
2018
-
[23]
Deep learning in remote sensing: A comprehensive review and list of resources,
X. X. Zhu, D. Tuia, L. Mou, G.-S. Xia, L. Zhang, F. Xu, and F. Fraundorfer, “Deep learning in remote sensing: A comprehensive review and list of resources,”IEEE Geoscience and Remote Sensing Magazine, vol. 5, no. 4, pp. 8–36, 2017
2017
-
[24]
Deep learning in remote sensing applications: A meta-analysis and review,
L. Ma, Y . Liu, X. Zhanget al., “Deep learning in remote sensing applications: A meta-analysis and review,”ISPRS Journal of Pho- togrammetry and Remote Sensing, vol. 152, pp. 166–177, 2019
2019
-
[25]
Deep learning meets sar: Concepts, models, pitfalls, and perspectives,
X. X. Zhu, S. Montazeri, M. Aliet al., “Deep learning meets sar: Concepts, models, pitfalls, and perspectives,”IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 4, pp. 143–172, 2021
2021
-
[26]
Oriented r-cnn for object detec- tion,
X. Xie, G. Cheng, J. Wanget al., “Oriented r-cnn for object detec- tion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3520–3529
2021
-
[27]
A fusion encoder with multi-task guidance for cross-modal text–image retrieval in remote sensing,
X. Zhang, W. Li, X. Wang, L. Wang, F. Zheng, L. Wang, and H. Zhang, “A fusion encoder with multi-task guidance for cross-modal text–image retrieval in remote sensing,”Remote Sensing, vol. 15, no. 18, p. 4637, 2023
2023
-
[28]
Skyeyegpt: Unifying remote sens- ing vision-language tasks via instruction tuning with large language model,
Y . Zhan, Z. Xiong, and Y . Yuan, “Skyeyegpt: Unifying remote sens- ing vision-language tasks via instruction tuning with large language model,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 221, pp. 64–77, 2025
2025
-
[29]
arXiv preprint arXiv:2506.01667 , year=
Y . Shu, B. Ren, Z. Xionget al., “Earthmind: Leveraging cross- sensor data for advanced earth observation interpretation with a unified multimodal llm,”arXiv preprint arXiv:2506.01667, 2025
-
[30]
Croma: Remote sensing represen- tations with contrastive radar-optical masked autoencoders,
A. Fuller, K. Millard, and J. Green, “Croma: Remote sensing represen- tations with contrastive radar-optical masked autoencoders,”Advances in Neural Information Processing Systems, vol. 36, pp. 5506–5538, 2023
2023
-
[31]
Skyscript: A large and se- mantically diverse vision-language dataset for remote sensing,
Z. Wang, R. Prabha, T. Huanget al., “Skyscript: A large and se- mantically diverse vision-language dataset for remote sensing,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5805–5813
2024
-
[32]
A unified sequence interface for vision tasks,
T. Chen, S. Saxena, L. Liet al., “A unified sequence interface for vision tasks,”Advances in Neural Information Processing Systems, vol. 35, pp. 31 333–31 346, 2022
2022
-
[33]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
K. Chen, Z. Zhang, W. Zenget al., “Shikra: Unleashing multimodal llm’s referential dialogue magic,”arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Ferret: Refer and ground anything anywhere at any granularity,
H. You, H. Zhang, Z. Ganet al., “Ferret: Refer and ground anything anywhere at any granularity,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[35]
Polyformer: Referring image segmenta- tion as sequential polygon generation,
J. Liu, H. Ding, Z. Caiet al., “Polyformer: Referring image segmenta- tion as sequential polygon generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 653–18 663
2023
-
[36]
Detect anything via next point prediction,
Q. Jiang, J. Huo, X. Chenet al., “Detect anything via next point prediction,”arXiv preprint arXiv:2510.12798, 2025
-
[37]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms,
L. Meng, J. Yang, R. Tianet al., “Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms,”Advances in Neural Information Processing Systems, vol. 37, pp. 23 464–23 487, 2024
2024
-
[39]
S. Bai, Y . Cai, R. Chenet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding,
Y . Wei, A. Xiao, Y . Ren, Y . Zhu, H. Chen, J. Xia, and N. Yokoya, “SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding,”IEEE Transactions on Geoscience and Remote Sensing, 2026
2026
-
[41]
Vrsbench: A versatile vision- language benchmark dataset for remote sensing image understanding,
X. Li, J. Ding, and M. Elhoseiny, “Vrsbench: A versatile vision- language benchmark dataset for remote sensing image understanding,” Advances in Neural Information Processing Systems, vol. 37, pp. 3229– 3242, 2024
2024
-
[42]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shaoet al., “Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Nwpu- captions dataset and mlca-net for remote sensing image captioning,
Q. Cheng, H. Huang, Y . Xu, Y . Zhou, H. Li, and Z. Wang, “Nwpu- captions dataset and mlca-net for remote sensing image captioning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–19, 2022
2022
-
[44]
Exploring models and data for remote sensing image caption generation,
X. Lu, B. Wang, X. Zheng, and X. Li, “Exploring models and data for remote sensing image caption generation,”IEEE Transactions on Geoscience and Remote Sensing, vol. 56, no. 4, pp. 2183–2195, 2017
2017
-
[45]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1– 16, 2024
2024
-
[46]
Y . He, J. Zhu, Y . Li, X. Zhang, C. Qiu, J. Wang, Q. Huang, and K. Yang, “Enhancing remote sensing vision-language models through mllm and llm-based high-quality image-text dataset generation,”arXiv preprint arXiv:2507.16716, 2025
-
[47]
Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,
M. Chu, Z. Zheng, W. Ji, T. Wang, and T.-S. Chua, “Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 213–231
2024
-
[48]
Accurate object localization in remote sensing images based on convolutional neural networks,
Y . Long, Y . Gong, Z. Xiao, and Q. Liu, “Accurate object localization in remote sensing images based on convolutional neural networks,”IEEE 16 Transactions on Geoscience and Remote Sensing, vol. 55, no. 5, pp. 2486–2498, 2017
2017
-
[49]
Object detection in optical remote sensing images: A survey and a new benchmark,
K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,”ISPRS journal of photogrammetry and remote sensing, vol. 159, pp. 296–307, 2020
2020
-
[50]
Whu-rs19 abzsl: An attribute-based dataset for remote sensing image understanding,
M. Balestra, M. Paolanti, and R. Pierdicca, “Whu-rs19 abzsl: An attribute-based dataset for remote sensing image understanding,”Re- mote Sensing, vol. 17, no. 14, p. 2384, 2025
2025
-
[51]
Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery?
F. Wang, H. Wang, Z. Guo, D. Wang, Y . Wang, M. Chen, Q. Ma, L. Lan, W. Yang, J. Zhanget al., “Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery?” inProceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 14 325–14 336
2025
-
[52]
Irgpt: Understanding real-world infrared image with bi-cross-modal curriculum on large-scale bench- mark,
Z. Cao, J. Zhang, and R. Zhang, “Irgpt: Understanding real-world infrared image with bi-cross-modal curriculum on large-scale bench- mark,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 166–176
2025
-
[53]
Y . He, X. Cheng, J. Zhu, C. Qiu, J. Wang, X. Zhang, Q. Huang, and K. Yang, “Sar-text: A large-scale sar image-text dataset built with sar- narrator and a progressive learning strategy for downstream tasks,” arXiv preprint arXiv:2507.18743, 2025
-
[54]
Sarclip: A multimodal foundation framework for sar imagery via contrastive language-image pre-training,
C. Jiang, C. Wang, F. Wu, P. Ma, L. Zou, T. Li, J. Ning, and Y . Tang, “Sarclip: A multimodal foundation framework for sar imagery via contrastive language-image pre-training,”ISPRS Journal of Photogram- metry and Remote Sensing, vol. 231, pp. 17–34, 2026
2026
-
[55]
The qxs-saropt dataset for deep learning in sar-optical data fusion,
M. Huang, Y . Xu, L. Qian, W. Shi, Y . Zhang, W. Bao, N. Wang, X. Liu, and X. Xiang, “The qxs-saropt dataset for deep learning in sar-optical data fusion,”arXiv preprint arXiv:2103.08259, 2021
-
[56]
arXiv preprint arXiv:2502.01002 , year=
W. Zhang, R. Zhao, Y . Yao, Y . Wan, P. Wu, J. Li, Y . Li, and Y . Zhang, “Multi-resolution sar and optical remote sensing image registration methods: A review, datasets, and future perspectives,”arXiv preprint arXiv:2502.01002, 2025
-
[57]
Mgfnet: An mlp-dominated gated fusion network for semantic segmentation of high-resolution multi- modal remote sensing images,
K. Wei, J. Dai, D. Hong, and Y . Ye, “Mgfnet: An mlp-dominated gated fusion network for semantic segmentation of high-resolution multi- modal remote sensing images,”International Journal of Applied Earth Observation and Geoinformation, vol. 135, p. 104241, 2024
2024
-
[58]
Chatearthnet: A global- scale image-text dataset empowering vision-language geo-foundation models,
Z. Yuan, Z. Xiong, L. Mou, and X. X. Zhu, “Chatearthnet: A global- scale image-text dataset empowering vision-language geo-foundation models,”Earth System Science Data Discussions, vol. 2024, pp. 1–24, 2024
2024
-
[59]
Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
2024
-
[60]
A multitask network and two large-scale datasets for change detection and captioning in remote sensing images,
J. Shi, M. Zhang, Y . Hou, R. Zhi, and J. Liu, “A multitask network and two large-scale datasets for change detection and captioning in remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–17, 2024
2024
-
[61]
Asymmetric siamese networks for semantic change detection in aerial images,
K. Yang, G.-S. Xia, Z. Liu, B. Du, W. Yang, M. Pelillo, and L. Zhang, “Asymmetric siamese networks for semantic change detection in aerial images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2022
2022
-
[62]
S2looking: A satellite side-looking dataset for building change detection,
L. Shen, Y . Lu, H. Chen, H. Wei, D. Xie, J. Yue, R. Chen, S. Lv, and B. Jiang, “S2looking: A satellite side-looking dataset for building change detection,”Remote Sensing, vol. 13, no. 24, p. 5094, 2021
2021
-
[63]
A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection,
Q. Shi, M. Liu, S. Li, X. Liu, F. Wang, and L. Zhang, “A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection,”IEEE transactions on geoscience and remote sensing, vol. 60, pp. 1–16, 2021
2021
-
[64]
Hi-ucd: A large-scale dataset for urban semantic change detection in remote sensing imagery,
S. Tian, A. Ma, Z. Zheng, and Y . Zhong, “Hi-ucd: A large-scale dataset for urban semantic change detection in remote sensing imagery,”arXiv preprint arXiv:2011.03247, 2020
-
[65]
Multi-temporal urban semantic understanding based on gf-2 remote sensing imagery: from tri-temporal datasets to multi-task mapping,
S. Shi, Y . Zhong, Y . Liu, J. Wang, Y . Wan, J. Zhao, P. Lv, L. Zhang, and D. Li, “Multi-temporal urban semantic understanding based on gf-2 remote sensing imagery: from tri-temporal datasets to multi-task mapping,”International Journal of Digital Earth, vol. 16, no. 1, pp. 3321–3347, 2023
2023
-
[66]
TAMMs: Change understanding and forecasting in satellite image time series with temporal-aware multimodal models,
Z. Guo, Y . Wang, P. Jian, C. Li, X. Chen, Z. Yang, and E. E, “TAMMs: Change understanding and forecasting in satellite image time series with temporal-aware multimodal models,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[67]
Rsvg: Exploring data and models for visual grounding on remote sensing data,
Y . Zhan, Z. Xiong, and Y . Yuan, “Rsvg: Exploring data and models for visual grounding on remote sensing data,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–13, 2023
2023
-
[68]
Language-guided progressive attention for visual grounding in remote sensing images,
K. Li, D. Wang, H. Xu, H. Zhong, and C. Wang, “Language-guided progressive attention for visual grounding in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–13, 2024
2024
-
[69]
Language query- based transformer with multiscale cross-modal alignment for visual grounding on remote sensing images,
M. Lan, F. Rong, H. Jiao, Z. Gao, and L. Zhang, “Language query- based transformer with multiscale cross-modal alignment for visual grounding on remote sensing images,”IEEE Transactions on Geo- science and Remote Sensing, vol. 62, pp. 1–13, 2024
2024
-
[70]
Vgrss: Datasets and models for visual grounding in remote sensing ship images,
Y . Chen, L. Zhan, Y . Zhao, S. Xiong, and X. Lu, “Vgrss: Datasets and models for visual grounding in remote sensing ship images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–11, 2025
2025
-
[71]
Describeearth: Describe anything for remote sensing images,
K. Li, Z. Jiang, X. Cao, J. Wang, X. Yuchen, D. Meng, and Z. Wang, “Describeearth: Describe anything for remote sensing images,”arXiv preprint arXiv:2509.25654, 2025
-
[72]
Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,
P. Deng, W. Zhou, and H. Wu, “Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[73]
Robust change captioning in remote sensing: Second-cc dataset and mmodalcc framework,
A. C. Karaca, E. Ozelbas, S. Berber, O. Karimli, T. Yildirim, and M. F. Amasyali, “Robust change captioning in remote sensing: Second-cc dataset and mmodalcc framework,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 18, pp. 21 494– 21 513, 2025
2025
-
[74]
Rscc: A large-scale remote sensing change caption dataset for disaster events,
Z. Chen, C. Wang, N. Zhang, and F. Zhang, “Rscc: A large-scale remote sensing change caption dataset for disaster events,”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[75]
H. Elgendy, A. Sharshar, A. Aboeitta, Y . Ashraf, and M. Guizani, “Geollava: Efficient fine-tuned vision-language models for temporal change detection in remote sensing,” 2024. [Online]. Available: https://arxiv.org/abs/2410.19552
-
[76]
Disasterm3: A remote sensing vision-language dataset for disaster damage assessment and response,
J. Wang, W. Xuan, H. Qi, Z. Liu, K. Liu, Y . Wu, H. Chen, J. Song, J. Xia, Z. Zhenget al., “Disasterm3: A remote sensing vision-language dataset for disaster damage assessment and response,”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[77]
Landsat30-au: A vision-language dataset for australian landsat imagery,
S. Ma, Z. Li, and J. A. Taylor, “Landsat30-au: A vision-language dataset for australian landsat imagery,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 10, 2026, pp. 7809– 7817
2026
-
[78]
Hit-uav: A high-altitude infrared thermal dataset for unmanned aerial vehicle- based object detection,
J. Suo, T. Wang, X. Zhang, H. Chen, W. Zhou, and W. Shi, “Hit-uav: A high-altitude infrared thermal dataset for unmanned aerial vehicle- based object detection,”Scientific Data, vol. 10, no. 1, p. 227, 2023
2023
-
[79]
Capera: Captioning events in aerial videos,
L. Bashmal, Y . Bazi, M. M. Al Rahhal, M. Zuair, and F. Melgani, “Capera: Captioning events in aerial videos,”Remote Sensing, vol. 15, no. 8, p. 2139, 2023
2023
-
[80]
Satellite video multi- label scene classification with spatial and temporal feature cooperative encoding: A benchmark dataset and method,
W. Guo, S. Li, F. Chen, Y . Sun, and Y . Gu, “Satellite video multi- label scene classification with spatial and temporal feature cooperative encoding: A benchmark dataset and method,”IEEE Transactions on Image Processing, vol. 33, pp. 2238–2251, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.