From Prompt to Purchase: How AI Brand Recommendations Move Consumers on the Open Web
Pith reviewed 2026-06-27 11:30 UTC · model grok-4.3
The pith
Conversational AI recommendations cause +4.3 pp rises in same-brand Google searches and +2.4 pp in site visits for users with no recent engagement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
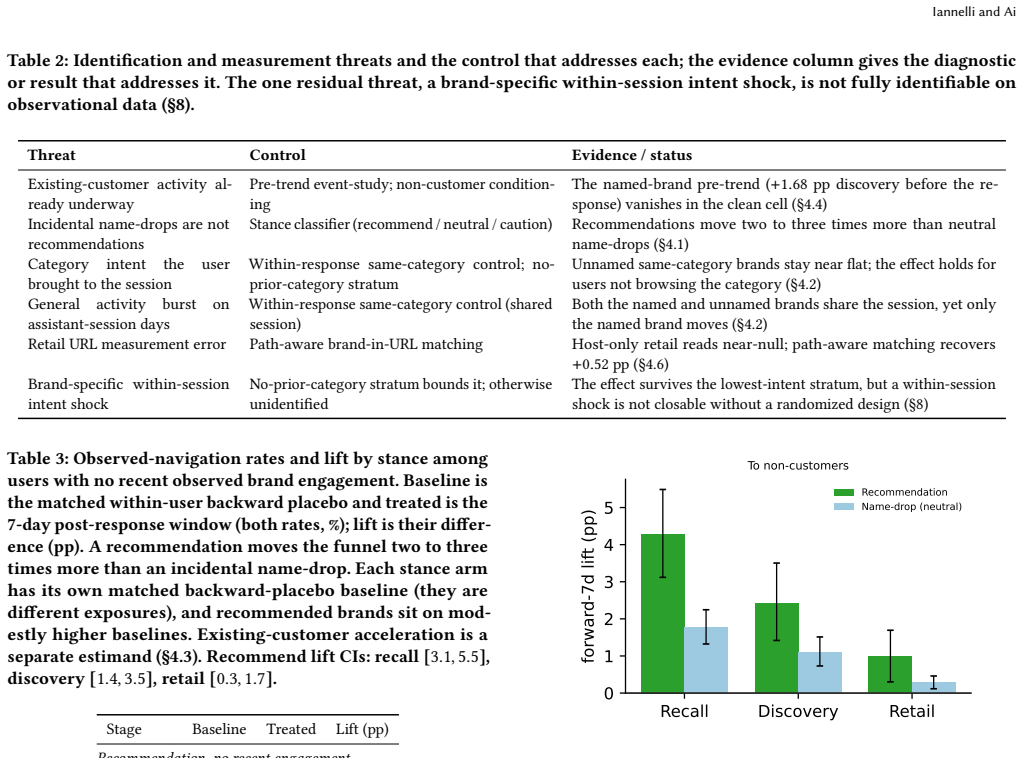
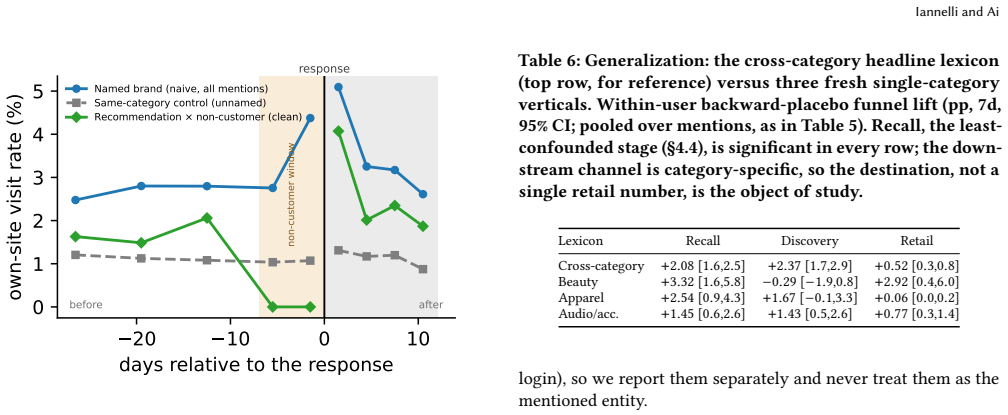
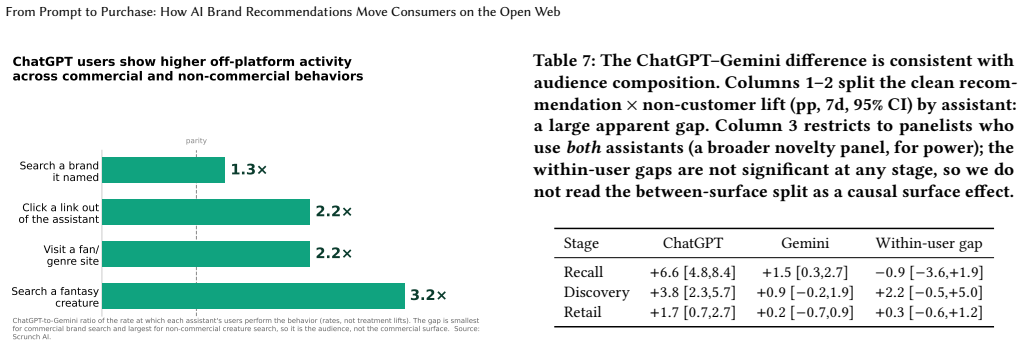
When a conversational assistant recommends a brand to a user with no recent observed engagement, that user's same-name Google search rises +4.3 percentage points [3.1, 5.5], visits to the brand's own site +2.4 pp [1.4, 3.5], and brand-specific retailer-page visits +1.0 pp [0.3, 1.7] over matched backward placebos. The mention creates a brand exposure no web log attributes to the assistant, and the naive all-mention funnel is confounded by incidental references whose downstream visits reflect existing customer behavior.
What carries the argument
Pre-trend event study combined with stance classifier, non-customer conditioning, and within-response same-category control that isolates recommendation effects from incidental mentions and pre-existing engagement.
If this is right
- The downstream path is mostly search-mediated and reaches both own sites and retailer pages with a destination mix that tracks baseline brand-directed behavior.
- Incidental name-drops move behavior far less (+1.8/+1.1/+0.3) while the named brand moves far more than unnamed same-category brands in the same response.
- Standard referrer-based and last-click measurement miss this upstream exposure because assistants move observably-unengaged users into open-web brand navigation along a path attributed elsewhere.
- The design is observational and does not observe transactions, so retail effects remain purchase-adjacent.
Where Pith is reading between the lines
- Marketers may need to incorporate AI conversation logs into attribution models rather than relying solely on web referrers.
- The effect size could vary across assistant platforms or brand categories if stance detection accuracy differs.
- If the same pattern holds for actual purchase data, assistants could function as an early-stage awareness channel that later converts through search.
Load-bearing premise
The combination of pre-trend event study, stance classifier, non-customer conditioning, and within-response same-category control is sufficient to isolate the causal effect of the recommendation from all other user-specific or time-varying factors.
What would settle it
A randomized experiment that assigns brand recommendations versus neutral responses in live conversations and tracks the same users' subsequent Google searches and site visits for the recommended brands.
Figures

read the original abstract
When a conversational assistant recommends a brand to a user with no recent observed engagement, that user's same-name Google search rises +4.3 percentage points (pp) [3.1, 5.5], visits to the brand's own site +2.4 pp [1.4, 3.5], and brand-specific retailer-page visits +1.0 pp [0.3, 1.7] over matched backward placebos. Recovering that estimate is the work. The mention creates a brand exposure no web log attributes to the assistant, and the naive all-mention funnel that seems to measure it is confounded: many mentions are incidental references to brands the user already uses ("your Netflix download"), whose downstream visits are that existing customer's own behavior and surface as a brand-specific pre-trend. We measure off-platform response on a panel that joins opt-in clickstream to the same users' ChatGPT, Claude, and Gemini conversations, and isolate the effect with a pre-trend event study, a stance classifier, non-customer conditioning, and a within-response same-category control: incidental name-drops then move behavior far less (+1.8/+1.1/+0.3), and the named brand moves far more than unnamed same-category brands in the same response. The downstream path is mostly search-mediated and reaches both own sites and retailer pages, with a destination mix that tracks baseline brand-directed behavior rather than redirecting toward either. The design is observational and we do not observe transactions, so retail is purchase-adjacent. Standard referrer-based and last-click measurement miss this upstream exposure: assistants move observably-unengaged users into open-web brand navigation along a path attributed elsewhere.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that brand recommendations from conversational AI assistants (ChatGPT, Claude, Gemini) causally increase subsequent Google searches (+4.3 pp [3.1, 5.5]), brand-site visits (+2.4 pp [1.4, 3.5]), and retailer-page visits (+1.0 pp [0.3, 1.7]) among users with no recent observed engagement. These effects are recovered from linked opt-in clickstream and conversation-log panel data by combining a pre-trend event study, a stance classifier to separate recommendations from incidental mentions, non-customer conditioning, and a within-response same-category control; incidental mentions produce smaller effects and the named brand outperforms unnamed same-category brands in the same response. The downstream path is described as mostly search-mediated and missed by standard referrer/last-click attribution.
Significance. If the identification holds, the result is significant for digital marketing attribution, consumer discovery research, and studies of AI's societal impact on open-web behavior. The design credits include the use of external web logs rather than fitted parameters, multiple identification strategies (pre-trends, stance classification, within-response controls), and the distinction between recommendation and incidental-mention effects, all of which strengthen the observational claim relative to naive all-mention analyses.
major comments (2)
- [Abstract / identification strategy] Abstract / identification strategy: the within-response same-category control and non-customer conditioning are presented as isolating the recommendation effect, yet the description gives no indication that the semantic content or intent signals of the triggering user query (e.g., embeddings or topic indicators from messages such as "best wireless earbuds") are included as covariates or used for additional matching. This is load-bearing for the central causal claim because query intent is a plausible common cause of both the specific brand mention and the subsequent search/visit behavior; without it, the +4.3 pp estimate may partly reflect selection on unobservables rather than the recommendation itself.
- [Abstract] Abstract: the stance classifier is used to separate recommendations from incidental mentions, but the manuscript provides no validation metrics, inter-annotator agreement, or robustness checks on classifier error correlated with query type or brand popularity. Because the classifier directly determines which observations enter the "recommendation" versus "incidental" contrast, any systematic misclassification would bias the reported differential effects.
minor comments (2)
- [Abstract] The abstract reports confidence intervals but does not state the underlying sample sizes, number of unique users, or number of conversations; adding these would improve interpretability of the precision.
- [Abstract] The claim that "standard referrer-based and last-click measurement miss this upstream exposure" is asserted without a direct comparison table or quantification of how much of the observed navigation would be attributed elsewhere; a small illustrative table would strengthen the point.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our identification strategy. We address each major point below, clarifying how the design elements interact and indicating where we will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / identification strategy] Abstract / identification strategy: the within-response same-category control and non-customer conditioning are presented as isolating the recommendation effect, yet the description gives no indication that the semantic content or intent signals of the triggering user query (e.g., embeddings or topic indicators from messages such as "best wireless earbuds") are included as covariates or used for additional matching. This is load-bearing for the central causal claim because query intent is a plausible common cause of both the specific brand mention and the subsequent search/visit behavior; without it, the +4.3 pp estimate may partly reflect selection on unobservables rather than the recommendation itself.
Authors: The within-response same-category control conditions directly on the user query by comparing the recommended brand against unnamed same-category brands appearing in the identical assistant response; this holds query intent, topic, and phrasing fixed while isolating the effect of explicit recommendation. Non-customer conditioning further restricts the sample to users with no recent observed brand engagement. We did not include explicit query embeddings or topic indicators as additional covariates in the primary specification. We will add a robustness check that extracts topic indicators from the user message and re-estimates the model with these as controls. revision: partial
-
Referee: [Abstract] Abstract: the stance classifier is used to separate recommendations from incidental mentions, but the manuscript provides no validation metrics, inter-annotator agreement, or robustness checks on classifier error correlated with query type or brand popularity. Because the classifier directly determines which observations enter the "recommendation" versus "incidental" contrast, any systematic misclassification would bias the reported differential effects.
Authors: The full manuscript describes the stance classifier in the methods section, but we agree that explicit validation metrics, inter-annotator agreement, and checks for error correlation with query type or brand popularity are necessary given the classifier's role in defining the treatment contrast. We will expand the appendix to report these metrics and robustness checks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central estimates derive from an observational panel joining external clickstream logs to conversation data, using pre-trend event studies, stance classification, non-customer conditioning, and within-response same-category controls compared against matched backward placebos. These steps rely on external web logs and placebo periods rather than any fitted parameter defined by the outcome data itself or self-citation chains that bear the identification load. No equations, ansatzes, or uniqueness theorems reduce the reported +4.3 pp, +2.4 pp, or +1.0 pp effects to the inputs by construction; the design remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The stance classifier and non-customer conditioning remove selection bias into brand mentions.
- domain assumption Backward placebos and same-category unnamed brands form valid counterfactuals for the treated brand mentions.
Reference graph
Works this paper leans on
-
[1]
2006.The Long Tail: Why the Future of Business Is Selling Less of More
Chris Anderson. 2006.The Long Tail: Why the Future of Business Is Selling Less of More. Hyperion, New York, NY, USA
2006
-
[2]
Eytan Bakshy, Dean Eckles, and Michael S. Bernstein. 2014. Designing and Deploying Online Field Experiments. InProceedings of the 23rd International Conference on World Wide Web (WWW). ACM, New York, NY, USA, 283–292. doi:10.1145/2566486.2567967
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He
-
[4]
Proceedings of the 17th ACM Conference on Recommender Systems , pages =
TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. InRecSys 2023. ACM, New York, NY, USA, 1007–1014. doi:10.1145/3604915.3608857
-
[5]
Ron Berman. 2018. Beyond the Last Touch: Attribution in Online Advertising. Marketing Science37, 5 (2018), 771–792. doi:10.1287/mksc.2018.1104
-
[6]
Thomas Blake, Chris Nosko, and Steven Tadelis. 2015. Consumer Heterogeneity and Paid Search Effectiveness: A Large-Scale Field Experiment.Econometrica83, 1 (2015), 155–174. doi:10.3982/ECTA12423
-
[7]
Erik Brynjolfsson, Yu Hu, and Michael D. Smith. 2003. Consumer Surplus in the Digital Economy: Estimating the Value of Increased Product Variety at Online Booksellers.Management Science49, 11 (2003), 1580–1596. doi:10.1287/mnsc.49. 11.1580.20580
-
[8]
Athena Chapekis and Anna Lieb. 2025. Google Users Are Less Likely to Click on Links When an AI Summary Appears in the Results. Pew Research Center
2025
-
[9]
Konstantina Christakopoulou, Filip Radlinski, and Katja Hofmann. 2016. Towards Conversational Recommender Systems. InKDD 2016. ACM, New York, NY, USA, From Prompt to Purchase: How AI Brand Recommendations Move Consumers on the Open Web 815–824. doi:10.1145/2939672.2939746
-
[10]
David Court, Dave Elzinga, Susan Mulder, and Ole Jørgen Vetvik. 2009. The Consumer Decision Journey. McKinsey Quarterly
2009
-
[11]
Daniel Fleder and Kartik Hosanagar. 2009. Blockbuster Culture’s Next Rise or Fall: The Impact of Recommender Systems on Sales Diversity.Management Science55, 5 (2009), 697–712. doi:10.1287/mnsc.1080.0974
-
[12]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt and Predict Paradigm (P5). InRecSys 2022. ACM, New York, NY, USA, 299–315. doi:10.1145/3523227.3546767
-
[13]
Samira Gholami, Cristiana Firullo, Cristobal Cheyre, and Alessandro Acquisti
-
[14]
Beyond Search: LLM Adoption and Web Traffic Concentration. SSRN Working Paper 6238578. doi:10.2139/ssrn.6238578
-
[15]
Gordon, Florian Zettelmeyer, Neha Bhargava, and Dan Chapsky
Brett R. Gordon, Florian Zettelmeyer, Neha Bhargava, and Dan Chapsky. 2019. A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook.Marketing Science38, 2 (2019), 193–225. doi:10. 1287/mksc.2018.1135
arXiv 2019
-
[16]
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2024. Large Language Models are Zero-Shot Rankers for Recommender Systems. InAdvances in Information Retrieval (ECIR 2024), Vol. 14609. Springer, Cham, 364–381. doi:10.1007/978-3-031-56060-6_24
-
[17]
Dietmar Jannach, Ahtsham Manzoor, Wanling Cai, and Li Chen. 2021. A Survey on Conversational Recommender Systems.Comput. Surveys54, 5 (2021), 1–36. doi:10.1145/3453154
-
[18]
Garrett A. Johnson, Randall A. Lewis, and Elmar I. Nubbemeyer. 2017. Ghost Ads: Improving the Economics of Measuring Online Ad Effectiveness.Journal of Marketing Research54, 6 (2017), 867–884. doi:10.1509/jmr.15.0297
-
[19]
Wilbur, Bo Cowgill, and Yi Zhu
Mingyu Joo, Kenneth C. Wilbur, Bo Cowgill, and Yi Zhu. 2014. Television Advertising and Online Search.Management Science60, 1 (2014), 56–73. doi:10. 1287/mnsc.2013.1741
arXiv 2014
-
[20]
Maximilian Kaiser and Christian Schulze. 2026. Frontiers: ChatGPT Referrals to E-Commerce Websites: How Do LLMs Compare Against Traditional Channels? Marketing Science(2026). doi:10.1287/mksc.2025.0489 Articles in Advance
-
[21]
Katherine N. Lemon and Peter C. Verhoef. 2016. Understanding Customer Experience Throughout the Customer Journey.Journal of Marketing80, 6 (2016), 69–96. doi:10.1509/jm.15.0420
-
[22]
Randall A. Lewis and David H. Reiley. 2014. Online Ads and Offline Sales: Measuring the Effect of Retail Advertising via a Controlled Experiment on Yahoo! Quantitative Marketing and Economics12, 3 (2014), 235–266. doi:10.1007/s11129- 014-9146-6
-
[23]
Jan Malte Lichtenberg, Alexander Buchholz, and Pola Schwöbel. 2024. Large Language Models as Recommender Systems: A Study of Popularity Bias. arXiv:2406.01285
arXiv 2024
-
[24]
OpenAI. 2026. Where the Goblins Came From. OpenAI Research blog post, April 29, 2026. https://openai.com/index/where-the-goblins-came-from/
2026
-
[25]
Tai Lam, Anja Lambrecht, and Brett Hollenbeck
Nicolas Padilla, H. Tai Lam, Anja Lambrecht, and Brett Hollenbeck. 2025. The Impact of LLM Adoption on Online User Behavior. SSRN Working Paper 5393256. doi:10.2139/ssrn.5393256
-
[26]
Navdeep S. Sahni. 2015. Effect of Temporal Spacing Between Advertising Ex- posures: Evidence from Online Field Experiments.Quantitative Marketing and Economics13, 3 (2015), 203–247. doi:10.1007/s11129-015-9159-9
-
[27]
Sylvain Sénécal and Jacques Nantel. 2004. The Influence of Online Product Recommendations on Consumers’ Online Choices.Journal of Retailing80, 2 (2004), 159–169. doi:10.1016/j.jretai.2004.04.001
-
[28]
Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Over- lapping Experiment Infrastructure: More, Better, Faster Experimentation. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). ACM, New York, NY, USA, 17–26. doi:10. 1145/1835804.1835810
arXiv 2010
-
[29]
consider the Garmin Forerunner
Peter C. Verhoef, P. K. Kannan, and J. Jeffrey Inman. 2015. From Multi-Channel Retailing to Omni-Channel Retailing.Journal of Retailing91, 2 (2015), 174–181. doi:10.1016/j.jretai.2015.02.005 A Secondary and diagnostic results Stance is classified by a small language model (recommend / neu- tral / caution) on a brand-local snippet; most mentions are neu- t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.