Provenance Tracking in AI Compilers through the Lens of Coalgebra
Pith reviewed 2026-06-27 10:58 UTC · model grok-4.3
The pith
A coalgebraic model using bisimulation tracks tensor and operator provenance in AI compilers by observing computational actions alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
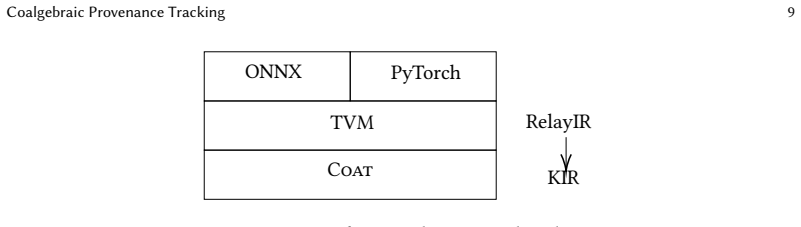
We present a lightweight, generative approach to provenance tracking based on observational semantics. Instead of propagating identifiers through compiler passes, we observe graph transformations and reason about provenance in terms of observable computational actions. We formalize this approach using a coalgebraic model and bisimulation, which preserves provenance even when intermediate nodes are eliminated. Furthermore, we implement this approach in a prototype AI compiler COVAN, demonstrating stable provenance across compilation pipelines with minimal engineering overhead.
What carries the argument
The coalgebraic model paired with bisimulation, which defines provenance equivalence through matching observable actions rather than internal node identities.
If this is right
- Provenance remains stable even under non-injective rewrites that remove intermediate nodes.
- Platform-specific postprocessing can attach reliably to final tensors based on recovered origins.
- Compiler debugging and transformation validation become possible without invasive instrumentation.
- The approach requires only minimal changes to existing compilation pipelines.
- Observational reasoning suffices to equate computations that differ only in eliminated structure.
Where Pith is reading between the lines
- The same observational technique could apply to provenance questions in database query planners that perform similar rewrites.
- Extending the bisimulation check to include timing or resource observations might handle additional compiler passes.
- If the prototype scales to full production compilers, it would reduce the need for custom provenance hooks in each new optimization.
- The method leaves open whether bisimulation can also certify that two different compiler backends produce equivalent provenance mappings.
Load-bearing premise
Provenance information can be recovered reliably from observable computational actions alone, without propagating explicit identifiers through compiler passes.
What would settle it
A concrete graph rewrite that eliminates nodes such that the final observable actions no longer uniquely determine which original tensor or operator produced a given output tensor.
Figures

read the original abstract
AI compilers aggressively rewrite computation graphs through normalization, lowering, and optimization, making it difficult to track the provenance of tensors and operators across compilation. Reliable provenance is essential for attaching platform-specific postprocessing, debugging compiler behavior, and validating transformations, yet existing solutions are either invasive or ad hoc under non-injective graph rewrites. We present a lightweight, generative approach to provenance tracking based on observational semantics. Instead of propagating identifiers through compiler passes, we observe graph transformations and reason about provenance in terms of observable computational actions. We formalize this approach using a coalgebraic model and bisimulation, which preserves provenance even when intermediate nodes are eliminated. Furthermore, we implement this approach in a prototype AI compiler COVAN, demonstrating stable provenance across compilation pipelines with minimal engineering overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that provenance tracking in AI compilers can be achieved via a lightweight observational approach rather than invasive identifier propagation. It formalizes the method with a coalgebraic model and bisimulation that is asserted to preserve provenance even under non-injective rewrites (normalization, lowering, optimization). A prototype implementation COVAN is said to demonstrate stable provenance across compilation pipelines with minimal overhead.
Significance. If the coalgebraic construction and bisimulation proof are correct, the work would supply a non-invasive, semantics-based alternative to existing provenance mechanisms in graph-rewriting compilers. This could aid debugging, post-processing attachment, and transformation validation without modifying every compiler pass. The coalgebraic framing is a potentially reusable technique for other compiler provenance problems.
major comments (2)
- [Abstract] Abstract: the central claim that 'a coalgebraic model and bisimulation... preserves provenance even when intermediate nodes are eliminated' is stated without any functor definition, observation map, bisimulation relation, or proof sketch. No equations or theorems are supplied, so the load-bearing formal result cannot be assessed for correctness or scope.
- [Abstract] Abstract / §4 (prototype): the claim of 'stable provenance across compilation pipelines' is presented without any quantitative metrics, comparison to baseline methods, or description of the observation map used in COVAN. The weakest assumption—that provenance is recoverable from observable actions alone—remains untested in the supplied text.
minor comments (1)
- [Abstract] The abstract refers to 'existing solutions' being invasive or ad hoc but supplies no citations or concrete comparison points.
Simulated Author's Rebuttal
We thank the referee for the comments. We respond point by point to the major comments and note the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'a coalgebraic model and bisimulation... preserves provenance even when intermediate nodes are eliminated' is stated without any functor definition, observation map, bisimulation relation, or proof sketch. No equations or theorems are supplied, so the load-bearing formal result cannot be assessed for correctness or scope.
Authors: The submitted manuscript presents the coalgebraic approach at a summary level in the abstract. We will revise the manuscript to include the explicit functor definition, observation map, bisimulation relation, and a proof sketch establishing that the bisimulation preserves provenance under non-injective rewrites. These additions will be placed in the main body with a brief reference added to the abstract. revision: yes
-
Referee: [Abstract] Abstract / §4 (prototype): the claim of 'stable provenance across compilation pipelines' is presented without any quantitative metrics, comparison to baseline methods, or description of the observation map used in COVAN. The weakest assumption—that provenance is recoverable from observable actions alone—remains untested in the supplied text.
Authors: The current text describes the COVAN prototype at a high level. We will revise §4 to include quantitative metrics on provenance stability and overhead, direct comparisons against identifier-propagation baselines, an explicit description of the observation map, and experiments that test recoverability of provenance from observable actions alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present a coalgebraic model and bisimulation for provenance tracking based on observational semantics, without any provided equations, self-citations, or derivation steps that reduce claims to inputs by construction. No load-bearing self-definitional, fitted-prediction, or uniqueness-imported steps are identifiable from the given text. The approach is treated as self-contained against standard coalgebra theory and external compiler benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observational semantics suffice to recover provenance without explicit identifier propagation
Reference graph
Works this paper leans on
-
[1]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: a system for...
2016
-
[2]
Apache Software Foundation. 2016. Apache Airflow. https://airflow.apache.org/ Version 2.8.2
2016
-
[3]
Apache Software Foundation. 2016. Apache Beam. https://beam.apache.org/ Version 2.54.0
2016
-
[4]
Apache Software Foundation. 2026. Apache TVM. https://tvm.apache.org/ Version 0.16.0
2026
-
[5]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. TVM: an automated end-to-end optimizing compiler for deep learning. InProceedings of the 13th USENIX Conference on Operating Systems Design and Implementation(Carlsbad, CA, USA)...
2018
-
[6]
Li Deng. 2012. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag.29, 6 (2012), 141–142. doi:10.1109/MSP.2012.2211477
-
[7]
TFRecord developers. 2026. TFRecordDataset. https://www.tensorflow.org/api_docs/python/tf/data/TFRecordDataset
2026
-
[8]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 2–14. doi:10.1109/CGO51591.2021.9370308
-
[9]
Alexandru A Ormenisan, Mahmoud Ismail, Seif Haridi, and Jim Dowling. 2020. Implicit provenance for machine learning artifacts.Proceedings of MLSys20 (2020)
2020
-
[10]
Gabriele Padovani, Valentine Anantharaj, and Sandro Fiore. 2025. Provenance Tracking in Large-Scale Machine Learning Systems.CoRRabs/2507.01075 (2025). arXiv:2507.01075 doi:10.48550/ARXIV.2507.01075
-
[11]
2019.PyTorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019.PyTorch: an imperative style, high-per...
2019
-
[12]
Nadav Rotem, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein, Jack Montgomery, Bert Maher, Satish Nadathur, Jakob Olesen, Jongsoo Park, Artem Rakhov, Misha Smelyanskiy, and Man Wang. 2019. Glow: Graph Lowering Compiler Techniques for Neural Networks. arXiv:1805.00907 [c...
Pith/arXiv arXiv 2019
-
[13]
Amit Sabne. 2020. XLA : Compiling Machine Learning for Peak Performance. Coalgebraic Provenance Tracking 13
2020
-
[14]
MobileNetV2: In- verted Residuals and Linear Bottlenecks
Mark Sandler, Andrew G. Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 4510–4520. doi:10.1109/CVPR.2018.00474
-
[15]
Marius Schlegel and Kai-Uwe Sattler. 2023. MLflow2PROV: Extracting Provenance from Machine Learning Experiments. InProceedings of the Seventh Workshop on Data Management for End-to-End Machine Learning, DEEM 2023, Seattle, W A, USA, 18 June 2023. ACM, 9:1–9:4. doi:10.1145/3595360.3595859
-
[16]
The Kubeflow Authors. 2018. Kubeflow Pipelines. https://www.kubeflow.org/docs/components/pipelines/ Version 2.0
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.