Coset Ensemble Decoder for Quantum Error Correction with Algorithm-Hardware Co-Design
Pith reviewed 2026-06-27 11:19 UTC · model grok-4.3
The pith
Coset ensemble decoding approximates coset-level maximum-likelihood decoding while cutting FPGA resource use for quantum error correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
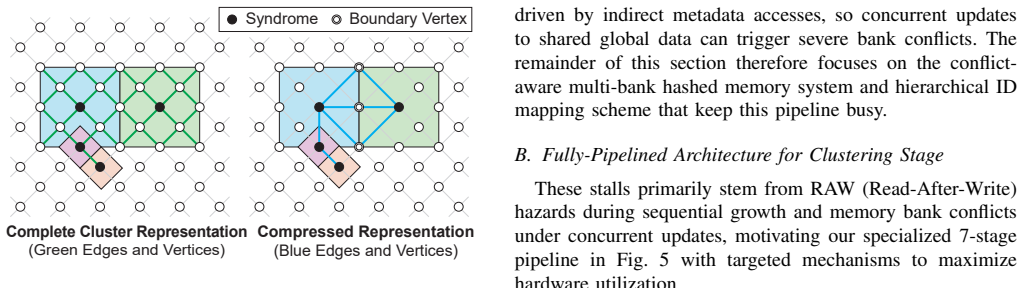
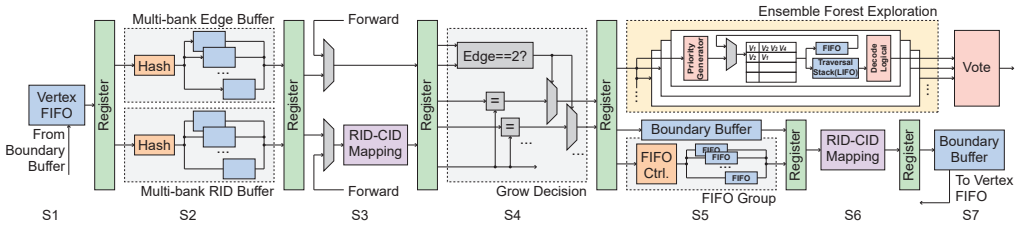
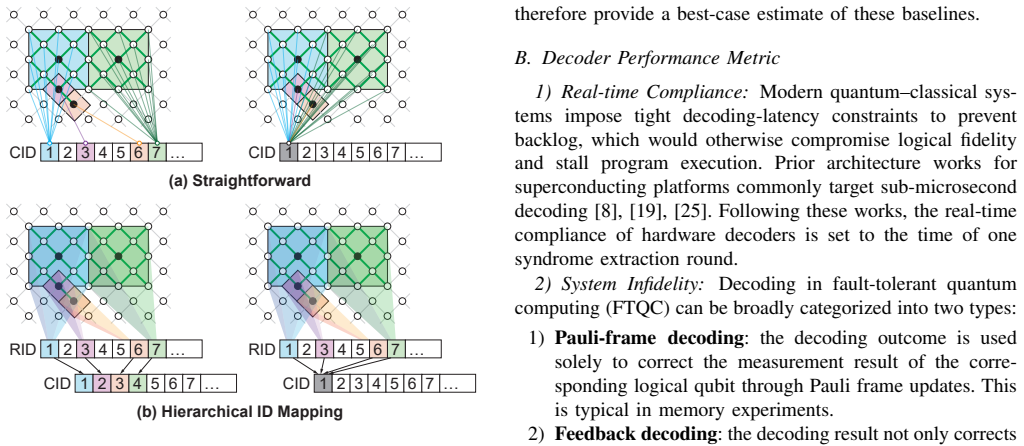
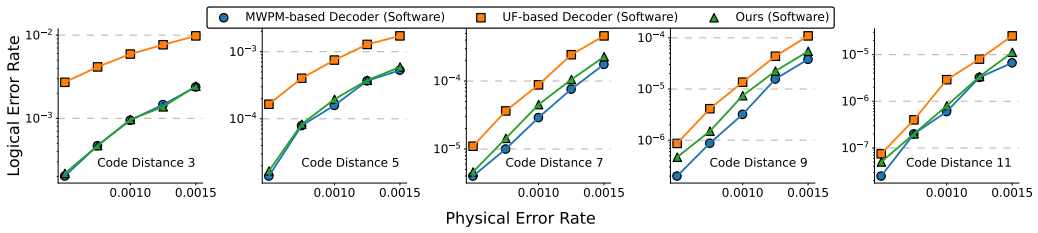
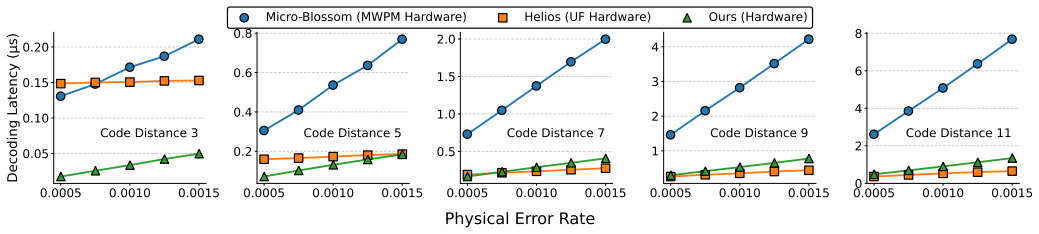
Coset ensemble decoding extends Union-Find by exploring an ensemble forest of coset-consistent candidates and aggregating them to approximate coset-level maximum-likelihood decoding; reverse-order elimination and lossless graph compression keep the overhead low. A domain-specific FPGA architecture reuses the same hardware blocks over time instead of scaling them with code distance, supported by multi-bank hashing and hierarchical ID mapping. Under circuit-level depolarizing noise this co-design yields a superior accuracy-latency trade-off and reduces LUT consumption by up to 8.2 times relative to reported Union-Find implementations, with the number of candidates serving as a tunable knob.
What carries the argument
Coset ensemble decoding: an algorithmic extension of Union-Find that generates and aggregates multiple coset-consistent error candidates to approximate coset-level maximum-likelihood decoding, paired with temporal resource reuse on FPGA.
If this is right
- The accuracy-latency operating point lies above that of both MWPM and Union-Find decoders under circuit-level depolarizing noise.
- FPGA LUT consumption drops by up to 8.2 times compared with published Union-Find decoder implementations.
- Resource usage no longer grows proportionally with code distance because of temporal rather than spatial replication.
- The candidate count acts as an explicit knob that lets the same hardware serve different fault-tolerant workload requirements.
Where Pith is reading between the lines
- Larger code distances become feasible on a fixed FPGA fabric because the architecture avoids distance-proportional replication.
- The open-source release permits direct porting to other FPGA families and direct benchmarking against future decoder proposals.
- The same ensemble-plus-compression pattern could be tested on other surface-code variants or color codes without changing the hardware template.
Load-bearing premise
The accuracy improvement from the ensemble approximation to coset-level maximum-likelihood decoding is not offset by the extra latency introduced on the target FPGA hardware.
What would settle it
A side-by-side measurement, on the same FPGA, of logical error rate versus decoding latency for a distance-5 surface code under circuit-level depolarizing noise, showing whether the coset ensemble decoder falls below the Union-Find curve.
Figures












read the original abstract
Reliable large-scale quantum computation relies on fault-tolerant architectures, where quantum error correction (QEC) continuously extracts and decodes error syndromes in real time. A critical component in QEC is the decoder, a classical subsystem that must simultaneously deliver high logical accuracy and ultra-low latency. This paper presents a novel algorithm-hardware co-design that improves the accuracy-latency trade-off over existing approaches such as vanilla Minimum-Weight Perfect Matching (MWPM) and Union-Find (UF) decoders. At the algorithmic level, we introduce coset ensemble decoding, which improves UF decoding by explicitly exploiting logically equivalent cosets. Our method performs ensemble forest exploration to generate multiple coset-consistent candidates and aggregates them to approximate coset-level maximum-likelihood decoding. We further reduce computational and memory complexity via reverse-order elimination and lossless graph compression, without sacrificing accuracy. At the hardware level, we design a domain-specific architecture that temporally reuses resources, avoiding the code-distance-proportional resource growth in prior spatial architectures. Several optimizations, such as multi-bank memory hashing and hierarchical ID mapping, are proposed to mitigate pipeline stalls and memory conflicts under highly concurrent access patterns. Under a circuit-level depolarizing noise model, our co-design approach achieves a better accuracy-latency trade-off than prior MWPM- and UF-based decoders, while reducing FPGA LUT consumption by up to 8.2 times compared with reported UF-based decoder resources. The tunable candidate number further exposes a flexible design knob, enabling users to tailor decoding performance to the requirements of different fault-tolerant workloads. Our implementation is publicly available at https://github.com/IMSeonL/coset-ensemble-decoder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces coset ensemble decoding, an extension to Union-Find decoding that performs ensemble forest exploration over coset-consistent candidates, aggregates them to approximate coset-level maximum-likelihood decoding, and applies reverse-order elimination plus lossless graph compression. This is paired with a domain-specific FPGA architecture using temporal resource reuse, multi-bank memory hashing, and hierarchical ID mapping to avoid distance-proportional resource scaling. Under circuit-level depolarizing noise, the co-design is claimed to deliver a superior accuracy-latency trade-off versus MWPM and UF baselines while reducing LUT consumption by up to 8.2×, with candidate count as a tunable knob.
Significance. If the empirical accuracy-latency curves hold after accounting for hardware pipeline and memory overheads, the work supplies a concrete, resource-efficient decoder design for real-time QEC that could be relevant to near-term fault-tolerant architectures. The public code release aids reproducibility.
major comments (2)
- [Evaluation section] Evaluation section (results and figures): the central claim that ensemble exploration yields a net accuracy gain not erased by added per-syndrome latency on the temporally-reused architecture requires explicit demonstration via logical-error-rate versus latency curves (with error bars) for multiple candidate numbers under the circuit-level depolarizing model; without these, it remains unclear whether the reported improvement survives the hardware mapping.
- [§3] §3 (algorithm description): the claim that aggregation of coset-consistent candidates approximates coset-level ML needs a quantitative bound or ablation showing that reverse-order elimination preserves the accuracy advantage rather than introducing a systematic bias that cancels the gain.
minor comments (2)
- [Abstract] Abstract: the 8.2× LUT reduction is stated without identifying the exact baseline UF implementation, code distance, or resource numbers; adding these values would make the comparison immediately verifiable.
- [§3.1] Notation: the definition of 'coset-consistent candidates' and the aggregation rule should be stated with a short pseudocode block or equation to avoid ambiguity when readers compare against standard UF.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our accuracy-latency results and the justification for the algorithmic approximations. We address each major comment below and will revise the manuscript to incorporate the requested demonstrations and ablations.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (results and figures): the central claim that ensemble exploration yields a net accuracy gain not erased by added per-syndrome latency on the temporally-reused architecture requires explicit demonstration via logical-error-rate versus latency curves (with error bars) for multiple candidate numbers under the circuit-level depolarizing model; without these, it remains unclear whether the reported improvement survives the hardware mapping.
Authors: We agree that explicit logical-error-rate versus latency curves with error bars, plotted for multiple candidate counts under the circuit-level depolarizing model, would strengthen the central claim. In the revised manuscript we will add these curves to the Evaluation section, generated from the same FPGA-mapped implementation, to show that the accuracy gain is preserved after hardware latency is accounted for. revision: yes
-
Referee: [§3] §3 (algorithm description): the claim that aggregation of coset-consistent candidates approximates coset-level ML needs a quantitative bound or ablation showing that reverse-order elimination preserves the accuracy advantage rather than introducing a systematic bias that cancels the gain.
Authors: We acknowledge the value of a quantitative check on reverse-order elimination. The revised manuscript will include an ablation study that compares logical error rates obtained with and without this step across representative noise strengths and candidate counts, thereby confirming that the elimination step does not erase the accuracy advantage of the ensemble aggregation. revision: yes
Circularity Check
No circularity; derivation is algorithmic and empirical
full rationale
The paper introduces coset ensemble decoding as an explicit algorithmic modification to UF decoding via ensemble forest exploration over coset-consistent candidates, followed by reverse-order elimination and lossless graph compression to approximate coset-level ML decoding. These steps are presented as concrete algorithmic changes with hardware co-design (temporal reuse, multi-bank hashing), not as equations or parameters that reduce to their own inputs. Claims of improved accuracy-latency trade-off rest on empirical results under circuit-level depolarizing noise, with no fitted inputs renamed as predictions, no self-definitional loops, and no load-bearing self-citations in the text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- candidate number
axioms (1)
- domain assumption Circuit-level depolarizing noise model accurately represents the dominant error processes in the target hardware.
Reference graph
Works this paper leans on
-
[1]
Superconducting qubits: Current state of play,
M. Kjaergaard, M. E. Schwartz, J. Braum ¨uller, P. Krantz, J. I.-J. Wang, S. Gustavsson, and W. D. Oliver, “Superconducting qubits: Current state of play,”Annual Review of Condensed Matter Physics, vol. 11, pp. 369– 395, 2020
2020
-
[2]
Quantum error correction for quantum memories,
B. M. Terhal, “Quantum error correction for quantum memories,” Reviews of Modern Physics, vol. 87, no. 2, p. 307, 2015
2015
-
[3]
Fault-tolerant quantum computation with constant error rate,
D. Aharonov and M. Ben-Or, “Fault-tolerant quantum computation with constant error rate,”arXiv preprint quant-ph/9611025, 1997
Pith/arXiv arXiv 1997
-
[4]
Resilient quantum compu- tation: error models and thresholds,
E. Knill, R. Laflamme, and W. H. Zurek, “Resilient quantum compu- tation: error models and thresholds,”Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences, vol. 454, no. 1969, pp. 365–384, 1998
1969
-
[5]
Surface codes: Towards practical large-scale quantum computation,
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, “Surface codes: Towards practical large-scale quantum computation,”Physical Review A, vol. 86, no. 3, p. 032324, 2012
2012
-
[6]
Topological quantum memory,
E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, “Topological quantum memory,”Journal of Mathematical Physics, vol. 43, no. 9, pp. 4452– 4505, 2002
2002
-
[7]
Almost-linear time decoding algo- rithm for topological codes,
N. Delfosse and N. H. Nickerson, “Almost-linear time decoding algo- rithm for topological codes,”Quantum, vol. 5, p. 595, 2021
2021
-
[8]
Micro blossom: Accelerated minimum-weight perfect matching decoding for quantum error cor- rection,
Y . Wu, N. Liyanage, and L. Zhong, “Micro blossom: Accelerated minimum-weight perfect matching decoding for quantum error cor- rection,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2025, pp. 639–654
2025
-
[9]
Scalable quantum error correction for surface codes using FPGA,
N. Liyanage, Y . Wu, A. Deters, and L. Zhong, “Scalable quantum error correction for surface codes using FPGA,” in2023 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2023, pp. 916–927
2023
-
[10]
J. Roffe, “Quantum error correction: an introductory guide,” Contemporary Physics, vol. 60, no. 3, pp. 226–245, Jul. 2019. [Online]. Available: http://dx.doi.org/10.1080/00107514.2019.1667078
-
[11]
On the iterative decoding of sparse quantum codes,
D. Poulin and Y . Chung, “On the iterative decoding of sparse quantum codes,” 2008. [Online]. Available: https://arxiv.org/abs/0801.1241
Pith/arXiv arXiv 2008
-
[12]
R. Acharya, D. A. Abanin, L. Aghababaie-Beni, I. Aleiner, T. I. Andersen, M. Ansmann, F. Arute, K. Arya, A. Asfaw, N. Astrakhantsev, J. Atalaya, R. Babbush, D. Bacon, B. Ballard, J. C. Bardin, J. Bausch, A. Bengtsson, A. Bilmes, S. Blackwell, S. Boixo, G. Bortoli, A. Bourassa, J. Bovaird, L. Brill, M. Broughton, D. A. Browne, B. Buchea, B. B. Buckley, D. ...
-
[13]
O. Higgott and C. Gidney, “Sparse blossom: correcting a million errors per core second with minimum-weight matching,”Quantum, vol. 9, p. 1600, Jan. 2025. [Online]. Available: http://dx.doi.org/10.22331/q- 2025-01-20-1600
work page doi:10.22331/q- 2025
-
[14]
Stabilizer codes and quantum error correction,
D. Gottesman, “Stabilizer codes and quantum error correction,” 1997. [Online]. Available: https://arxiv.org/abs/quant-ph/9705052
Pith/arXiv arXiv 1997
-
[15]
Degeneracy and its impact on the decoding of sparse quantum codes,
P. Fuentes, J. Etxezarreta Martinez, P. M. Crespo, and J. Garcia-Fr ´ıas, “Degeneracy and its impact on the decoding of sparse quantum codes,” IEEE Access, vol. 9, pp. 89 093–89 119, 2021
2021
-
[16]
Error correction and degeneracy in surface codes suffering loss,
T. M. Stace and S. D. Barrett, “Error correction and degeneracy in surface codes suffering loss,”Physical Review A, vol. 81, no. 2, Feb. 2010. [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.81. 022317
-
[17]
Fusion blossom: Fast mwpm decoders for qec,
Y . Wu and L. Zhong, “Fusion blossom: Fast mwpm decoders for qec,”
-
[18]
Available: https://arxiv.org/abs/2305.08307
[Online]. Available: https://arxiv.org/abs/2305.08307
-
[19]
Blossom v: a new implementation of a minimum cost perfect matching algorithm,
V . Kolmogorov, “Blossom v: a new implementation of a minimum cost perfect matching algorithm,”Mathematical Programming Computation, vol. 1, pp. 43–67, 2009. [Online]. Available: https://api.semanticscholar. org/CorpusID:17864814
2009
-
[20]
Afs: Accurate, fast, and scalable error- decoding for fault-tolerant quantum computers,
P. Das, C. A. Pattison, S. Manne, D. M. Carmean, K. M. Svore, M. Qureshi, and N. Delfosse, “Afs: Accurate, fast, and scalable error- decoding for fault-tolerant quantum computers,” in2022 IEEE Interna- tional Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 259–273
2022
-
[21]
FPGA-Based Distributed Union-Find Decoder for Surface Codes,
N. Liyanage, Y . Wu, S. Tagare, and L. Zhong, “FPGA-Based Distributed Union-Find Decoder for Surface Codes,”IEEE Transactions on Quantum Engineering, vol. 5, pp. 1–18, 2024. [Online]. Available: http://dx.doi.org/10.1109/TQE.2024.3467271
-
[22]
Np-hardness of decoding quantum error-correction codes,
M.-H. Hsieh and F. Le Gall, “Np-hardness of decoding quantum error-correction codes,”Physical Review A, vol. 83, no. 5, May 2011. [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.83.052331
-
[23]
Stim: a fast stabilizer circuit simulator,
C. Gidney, “Stim: a fast stabilizer circuit simulator,”Quantum, vol. 5, p. 497, 2021
2021
-
[24]
QUEKUF: an FPGA Union Find Decoder for Quantum Error Correction on the Toric Code,
F. Valentino, B. Branchini, D. Conficconi, D. Sciuto, and M. D. Santam- brogio, “QUEKUF: an FPGA Union Find Decoder for Quantum Error Correction on the Toric Code,”ACM Transactions on Reconfigurable Technology and Systems, 2025
2025
-
[25]
Threshold error rates for the toric and surface codes,
D. S. Wang, A. G. Fowler, A. M. Stephens, and L. C. Hollenberg, “Threshold error rates for the toric and surface codes,”arXiv preprint arXiv:0905.0531, 2009
Pith/arXiv arXiv 2009
-
[26]
Nisq+: Boosting quantum computing power by approximating quantum error correction,
A. Holmes, M. R. Jokar, G. Pasandi, Y . Ding, M. Pedram, and F. T. Chong, “Nisq+: Boosting quantum computing power by approximating quantum error correction,” in2020 ACM/IEEE 47th annual international symposium on computer architecture (ISCA). IEEE, 2020, pp. 556–569
2020
-
[27]
Learning to decode the surface code with a recurrent, transformer-based neural network,
J. Bausch, A. W. Senior, F. J. H. Heras, T. Edlich, A. Davies, M. New- man, C. Jones, K. Satzinger, M. Y . Niu, S. Blackwell, G. Holland, D. Kafri, J. Atalaya, C. Gidney, D. Hassabis, S. Boixo, H. Neven, and P. Kohli, “Learning to decode the surface code with a recurrent, transformer-based neural network,”arXiv preprint arXiv:2310.05900, 2023
arXiv 2023
-
[28]
Pymatching: A python package for decoding quantum codes with minimum-weight perfect matching,
O. Higgott, “Pymatching: A python package for decoding quantum codes with minimum-weight perfect matching,” 2021. [Online]. Available: https://arxiv.org/abs/2105.13082
arXiv 2021
-
[29]
Quantum ldpc codes with positive rate and minimum distance proportional to the square root of the blocklength,
J.-P. Tillich and G. Z ´emor, “Quantum ldpc codes with positive rate and minimum distance proportional to the square root of the blocklength,” IEEE Transactions on Information Theory, vol. 60, no. 2, pp. 1193– 1202, 2014
2014
-
[30]
Quantum expander codes,
A. Leverrier, J.-P. Tillich, and G. Z ´emor, “Quantum expander codes,” in2015 IEEE 56th Annual Symposium on Foundations of Computer Science. IEEE, 2015, pp. 810–824
2015
-
[31]
Constant overhead quantum fault tolerance with quantum expander codes,
O. Fawzi, A. Grospellier, and A. Leverrier, “Constant overhead quantum fault tolerance with quantum expander codes,”Communications of the ACM, vol. 64, no. 1, pp. 106–114, 2021
2021
-
[32]
Efficient decoding of random errors for quantum expander codes,
——, “Efficient decoding of random errors for quantum expander codes,” inProceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, 2018, pp. 521–534
2018
-
[33]
Quantum ldpc codes with almost linear minimum distance,
P. Panteleev and G. Kalachev, “Quantum ldpc codes with almost linear minimum distance,”IEEE Transactions on Information Theory, vol. 68, no. 1, pp. 213–229, 2022
2022
-
[34]
Degenerate quantum ldpc codes with good finite length perfor- mance,
——, “Degenerate quantum ldpc codes with good finite length perfor- mance,”Quantum, vol. 5, p. 585, 2021
2021
-
[35]
Fault-tolerant quantum computation by anyons,
A. Y . Kitaev, “Fault-tolerant quantum computation by anyons,”Annals of physics, vol. 303, no. 1, pp. 2–30, 2003
2003
-
[36]
Decoding algorithms for surface codes,
A. deMarti iOlius, P. Fuentes, R. Or ´us, P. M. Crespo, and J. Etxezarreta Martinez, “Decoding algorithms for surface codes,” Quantum, vol. 8, p. 1498, Oct. 2024. [Online]. Available: http: //dx.doi.org/10.22331/q-2024-10-10-1498
-
[37]
Lilliput: a lightweight low-latency lookup-table decoder for near-term quantum error correction,
P. Das, A. Locharla, and C. Jones, “Lilliput: a lightweight low-latency lookup-table decoder for near-term quantum error correction,” inPro- ceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2022, pp. 541–553
2022
-
[38]
Astrea: Accurate quantum error- decoding via practical minimum-weight perfect-matching,
S. Vittal, P. Das, and M. Qureshi, “Astrea: Accurate quantum error- decoding via practical minimum-weight perfect-matching,” inProceed- ings of the 50th Annual International Symposium on Computer Archi- tecture, 2023, pp. 1–16
2023
-
[39]
Pro- match: Extending the reach of real-time quantum error correction with adaptive predecoding,
N. Alavisamani, S. Vittal, R. Ayanzadeh, P. Das, and M. Qureshi, “Pro- match: Extending the reach of real-time quantum error correction with adaptive predecoding,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 818–833
2024
-
[40]
Hardware- efficient union-find decoder towards scalable topological quantum codes,
S. Liang, J. Xu, Y . Lu, H. M. Chen, B. Yuan, and H. Fan, “Hardware- efficient union-find decoder towards scalable topological quantum codes,” in2026 31st Asia and South Pacific Design Automation Confer- ence (ASP-DAC). IEEE, 2026, pp. 77–82
2026
-
[41]
Lightstim: A framework for qec protocol evaluation and prototyping with automated dem construction,
X. Fang, M. Wang, Y . Wu, S. Prabhu, D. Tullsen, N. R. Miniskar, F. Mueller, T. Humble, and Y . Ding, “Lightstim: A framework for qec protocol evaluation and prototyping with automated dem construction,” arXiv preprint arXiv:2604.21472, 2026
Pith/arXiv arXiv 2026
-
[42]
Greenpeas: Unlocking adaptive quantum error correction with just-in-time decoding hypergraphs,
A. B. Ziad, J. Xu, and H. Fan, “Greenpeas: Unlocking adaptive quantum error correction with just-in-time decoding hypergraphs,”arXiv preprint arXiv:2604.16613, 2026
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.