TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
Pith reviewed 2026-06-27 13:53 UTC · model grok-4.3
The pith
TRACE allocates rollout budgets to intermediate prefixes in tree-structured agentic rollouts to raise reward contrast at fixed sampling cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
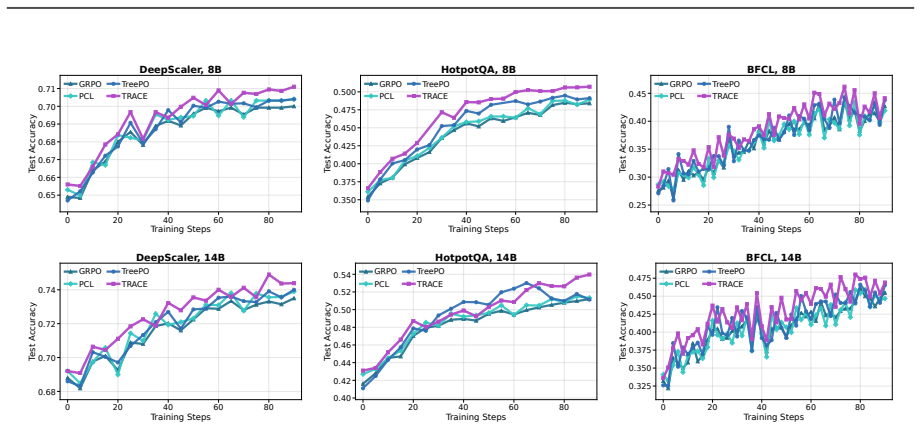
TRACE allocates rollout budget to both prompt roots and intermediate prefixes that are most likely to yield mixed terminal rewards. A shared generalizable predictor estimates conditional success probability at these anchors from prefix histories to guide this allocation. The resulting adaptive tree structure enriches outcome-only feedback and amplifies the policy-update signal.
What carries the argument
Tree Rollout Allocation for Contrastive Exploration (TRACE), the mechanism that extends budget decisions from whole prompts to turn-level prefixes inside tree-structured rollouts by using a predictor to target nodes expected to produce mixed terminal rewards.
If this is right
- Performance and efficiency gains appear on typical agentic benchmarks at equal sampling cost.
- Qwen3-14B Multi-Hop QA accuracy rises by 2.8 points over competitive baselines.
- Outcome-only rewards become more informative because allocation favors prefixes with uncertain futures.
- Adaptive tree structures form that supply stronger gradients for policy updates within the same total rollout count.
Where Pith is reading between the lines
- The same prefix-level predictor could be reused across different tasks or models without retraining from scratch, lowering the overhead of the method.
- Applying the tree allocation idea to non-agentic chain-of-thought training might reduce wasted samples on easy or impossible prompts in ordinary reasoning benchmarks.
- Longer-horizon agent tasks with dozens of turns would likely benefit most, because the number of candidate prefixes grows and the predictor has more opportunities to prune low-contrast branches.
Load-bearing premise
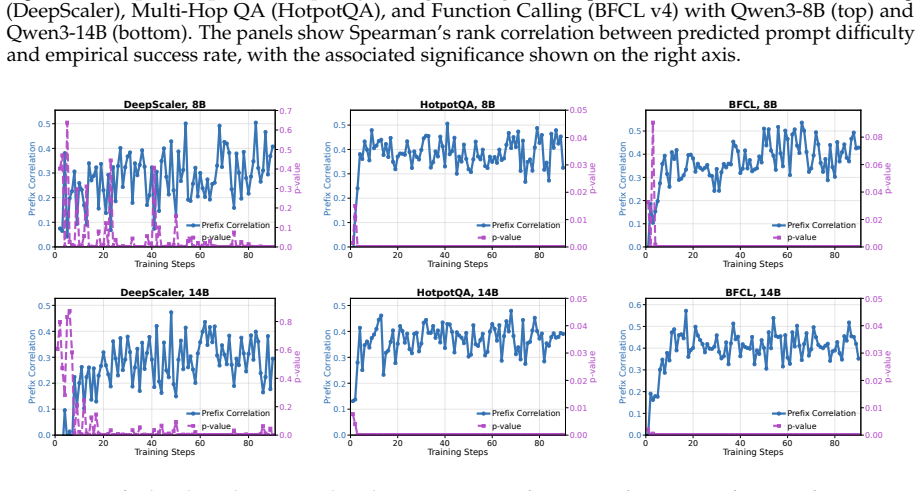
A shared generalizable predictor can accurately estimate conditional success probability at intermediate prefixes from prefix histories and thereby guide allocation to nodes that produce mixed terminal rewards.
What would settle it
Measure the actual rate of mixed terminal rewards among predictor-chosen prefixes versus randomly chosen prefixes in the same rollout trees; if the predictor-selected prefixes do not show reliably higher variance, the allocation advantage disappears.
Figures










read the original abstract
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for enhancing reasoning and agentic behavior in large language models. However, rollout-intensive policy optimization is often limited by insufficient reward contrast, arising when overly simple or complex prompts generate low-variance feedback and when outcome-only rewards assign the same terminal assessment to every decision in a multi-turn rollout. Past efforts have focused on allocating available rollout resources to promising prompts, yet they only leverage sample informativeness at the prompt level and neglect variation in prefix-level informativeness across turns within the same rollout. This work targets multi-turn agentic RL by modeling each ReAct-style thought-action-observation turn as a semantically distinct node, allowing budget allocation to extend from prompt roots to turn-level prefixes with further continuations, which naturally forms tree-structured rollouts. We introduce Tree Rollout Allocation for Contrastive Exploration (TRACE), a unified rollout allocation framework that enhances reward contrast within a fixed sampling budget. Technically, TRACE allocates rollout budget to both prompt roots and intermediate prefixes that are most likely to yield mixed terminal rewards. A shared generalizable predictor estimates conditional success probability at these anchors from prefix histories to guide this allocation. The resulting adaptive tree structure enriches outcome-only feedback and amplifies the policy-update signal. Empirically, TRACE achieves competitive performance and efficiency gains on typical agentic benchmarks, e.g., improving Qwen3-14B Multi-Hop QA average accuracy by 2.8 points over competitive baselines at equal sampling cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRACE, a unified rollout budget allocation framework for efficient agentic RLVR. It models ReAct-style multi-turn rollouts as tree-structured graphs with semantically distinct turn-level nodes, extending allocation beyond prompt roots to intermediate prefixes. A shared generalizable predictor estimates conditional success probability from prefix histories to allocate budget preferentially to nodes likely to produce mixed terminal rewards, thereby enriching outcome-only feedback and amplifying the policy-update signal within a fixed sampling budget. Empirically, TRACE is reported to achieve competitive performance and efficiency gains on agentic benchmarks, including a 2.8-point average accuracy improvement for Qwen3-14B on Multi-Hop QA over competitive baselines at equal sampling cost.
Significance. If the predictor reliably identifies mixed-reward prefixes and the resulting tree allocation demonstrably increases reward contrast without introducing systematic bias, the framework could provide a practical, generalizable improvement in sample efficiency for multi-turn agentic RLVR, addressing limitations of prompt-level allocation methods. The explicit tree modeling of turn-level nodes and the predictor-guided allocation represent a coherent extension of existing rollout strategies.
major comments (2)
- [Abstract] Abstract: The claim of a 2.8-point accuracy improvement on Qwen3-14B Multi-Hop QA supplies no experimental protocol, baseline definitions, statistical tests, ablation results, or variance estimates, rendering the reported gain unverifiable against the method's contribution.
- [Abstract] Abstract: The shared generalizable predictor that estimates P(success | prefix history) to guide allocation to mixed-reward nodes is load-bearing for the claimed contrast improvement; however, no details on training data, architecture, calibration, or measured error rates are provided. Systematic bias in the predictor would collapse the tree allocation to near-random or prompt-level selection, erasing the reported efficiency gains.
minor comments (1)
- [Abstract] Abstract: The phrase 'ReAct-style thought-action-observation turn' is introduced without a citation or one-sentence definition, which may reduce accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's conciseness. We agree that the reported gains and the predictor require clearer context for verifiability and will revise the abstract accordingly while preserving its length constraints. Details supporting the claims appear in the experimental sections of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 2.8-point accuracy improvement on Qwen3-14B Multi-Hop QA supplies no experimental protocol, baseline definitions, statistical tests, ablation results, or variance estimates, rendering the reported gain unverifiable against the method's contribution.
Authors: We acknowledge the abstract's brevity omits these elements. The evaluation protocol (including Qwen3-14B, Multi-Hop QA task, equal-cost sampling, and competitive baselines such as uniform rollout allocation), statistical tests, ablations, and variance estimates are detailed in Section 4 and Appendix C. We will revise the abstract to include a brief statement of the evaluation setting and reference to the main results table for verification. revision: yes
-
Referee: [Abstract] Abstract: The shared generalizable predictor that estimates P(success | prefix history) to guide allocation to mixed-reward nodes is load-bearing for the claimed contrast improvement; however, no details on training data, architecture, calibration, or measured error rates are provided. Systematic bias in the predictor would collapse the tree allocation to near-random or prompt-level selection, erasing the reported efficiency gains.
Authors: The abstract summarizes the high-level approach. Predictor specifics (training on prefix histories from warm-up rollouts, shared MLP architecture, calibration procedure, and validation error rates) are provided in Section 3.2, with empirical checks against bias in Section 4.3. We will expand the abstract with one sentence on the predictor to address potential concerns about its reliability and role in the allocation. revision: yes
Circularity Check
No circularity: allocation rule and predictor are independent of reported gains
full rationale
The abstract and description present TRACE as an empirical allocation procedure that trains a separate predictor on prefix histories to estimate conditional success probabilities, then uses those estimates to select nodes. No equations, derivations, or self-citations are shown that would make the reported 2.8-point gain or contrast improvement reduce by construction to a fitted parameter or input quantity defined within the method itself. The framework is self-contained against external benchmarks with no load-bearing self-referential steps visible.
Axiom & Free-Parameter Ledger
free parameters (1)
- predictor parameters
axioms (1)
- domain assumption Allocating samples to prefixes expected to yield mixed terminal rewards enriches the policy-update signal
invented entities (1)
-
Tree-structured rollouts with turn-level nodes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[2]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[3]
5: Scaling reinforcement learning with llms , author=
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
-
[4]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[5]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[6]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[7]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[8]
Notion Blog , volume=
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl , author=. Notion Blog , volume=
-
[9]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[10]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[14]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[15]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[16]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[17]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[18]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[19]
arXiv preprint arXiv:2212.03533 , year=
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
-
[20]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[21]
arXiv preprint arXiv:2510.01135 , year=
Prompt curriculum learning for efficient llm post-training , author=. arXiv preprint arXiv:2510.01135 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2509.25849 , year=
Knapsack rl: Unlocking exploration of llms via optimizing budget allocation , author=. arXiv preprint arXiv:2509.25849 , year=
-
[24]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Cppo: Accelerating the training of group relative policy optimization-based reasoning models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Online difficulty filtering for reasoning oriented reinforcement learning , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
arXiv preprint arXiv:2509.21240 , year=
Tree search for llm agent reinforcement learning , author=. arXiv preprint arXiv:2509.21240 , year=
-
[29]
arXiv preprint arXiv:2506.05183 , year=
Treerpo: Tree relative policy optimization , author=. arXiv preprint arXiv:2506.05183 , year=
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Treerl: Llm reinforcement learning with on-policy tree search , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
arXiv preprint arXiv:2502.03387 , year=
LIMO: Less is More for Reasoning , author=. arXiv preprint arXiv:2502.03387 , year=
-
[32]
arXiv preprint arXiv:2502.11886 , year=
Limr: Less is more for rl scaling , author=. arXiv preprint arXiv:2502.11886 , year=
-
[33]
arXiv preprint arXiv:2503.10460 , year=
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond , author=. arXiv preprint arXiv:2503.10460 , year=
-
[34]
arXiv preprint arXiv:2503.24290 , year=
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. arXiv preprint arXiv:2503.24290 , year=
-
[35]
5-math technical report: Toward mathematical expert model via self-improvement , author=
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
-
[36]
arXiv preprint arXiv:2504.05185 , year=
Concise reasoning via reinforcement learning , author=. arXiv preprint arXiv:2504.05185 , year=
-
[37]
arXiv preprint arXiv:2504.20571 , year=
Reinforcement learning for reasoning in large language models with one training example , author=. arXiv preprint arXiv:2504.20571 , year=
-
[38]
2025 , eprint=
Can Prompt Difficulty be Online Predicted for Accelerating RL Finetuning of Reasoning Models? , author=. 2025 , eprint=
2025
-
[39]
arXiv preprint arXiv:2505.24864 , year=
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models , author=. arXiv preprint arXiv:2505.24864 , year=
-
[40]
arXiv preprint arXiv:2502.01456 , year=
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
-
[41]
CoRR , year=
Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning , author=. CoRR , year=
-
[42]
arXiv preprint arXiv:2504.14286 , year=
Srpo: A cross-domain implementation of large-scale reinforcement learning on llm , author=. arXiv preprint arXiv:2504.14286 , year=
-
[43]
2025 , eprint=
CurES: From Gradient Analysis to Efficient Curriculum Learning for Reasoning LLMs , author=. 2025 , eprint=
2025
-
[44]
arXiv preprint arXiv:2505.14970 , year=
Self-Evolving Curriculum for LLM Reasoning , author=. arXiv preprint arXiv:2505.14970 , year=
-
[45]
arXiv preprint arXiv:2603.10887 , year=
Dynamics-predictive sampling for active RL finetuning of large reasoning models , author=. arXiv preprint arXiv:2603.10887 , year=
-
[46]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[47]
arXiv preprint arXiv:2305.08291 , year=
Large language model guided tree-of-thought , author=. arXiv preprint arXiv:2305.08291 , year=
-
[48]
arXiv preprint arXiv:2408.03314 , year=
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[49]
arXiv preprint arXiv:2407.01476 , year=
Tree search for language model agents , author=. arXiv preprint arXiv:2407.01476 , year=
-
[50]
arXiv preprint arXiv:2310.04406 , year=
Language agent tree search unifies reasoning acting and planning in language models , author=. arXiv preprint arXiv:2310.04406 , year=
-
[51]
5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search , author=
Deepseek-prover-v1. 5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search , author=. International Conference on Learning Representations , volume=
-
[52]
arXiv preprint arXiv:2309.17179 , year=
Alphazero-like tree-search can guide large language model decoding and training , author=. arXiv preprint arXiv:2309.17179 , year=
-
[53]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Advancing process verification for large language models via tree-based preference learning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[54]
arXiv preprint arXiv:2405.00451 , year=
Monte carlo tree search boosts reasoning via iterative preference learning , author=. arXiv preprint arXiv:2405.00451 , year=
-
[55]
outcome reward: Which is better for agentic rag reinforcement learning , author=
Process vs. outcome reward: Which is better for agentic rag reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2406.18629 , year=
Step-dpo: Step-wise preference optimization for long-chain reasoning of llms , author=. arXiv preprint arXiv:2406.18629 , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Iterative tool usage exploration for multimodal agents via step-wise preference tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Rest-mcts*: Llm self-training via process reward guided tree search , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment , author=
-
[60]
Advances in Neural Information Processing Systems , volume=
Segment policy optimization: Effective segment-level credit assignment in rl for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[62]
Advances in neural information processing systems , volume=
Hindsight experience replay , author=. Advances in neural information processing systems , volume=
-
[63]
Icml , volume=
Policy invariance under reward transformations: Theory and application to reward shaping , author=. Icml , volume=. 1999 , organization=
1999
-
[64]
Advances in Neural Information Processing Systems , volume=
Rudder: Return decomposition for delayed rewards , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Bmj , volume=
Spearman's rank correlation coefficient , author=. Bmj , volume=. 2014 , publisher=
2014
-
[66]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[67]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[68]
2025 , note=
rLLM: A Framework for Post-Training Language Agents , author=. 2025 , note=
2025
-
[69]
Advances in Neural Information Processing Systems , volume=
Group-in-group policy optimization for llm agent training , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
arXiv preprint arXiv:2603.10848 , year=
V\_ \ 0.5 \ : Generalist Value Model as a Prior for Sparse RL Rollouts , author=. arXiv preprint arXiv:2603.10848 , year=
-
[71]
arXiv preprint arXiv:2602.01970 , year=
Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models , author=. arXiv preprint arXiv:2602.01970 , year=
-
[72]
arXiv preprint arXiv:2603.24840 , year=
Prune as you generate: Online rollout pruning for faster and better rlvr , author=. arXiv preprint arXiv:2603.24840 , year=
-
[73]
arXiv preprint arXiv:2602.03048 , year=
CoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs , author=. arXiv preprint arXiv:2602.03048 , year=
-
[74]
arXiv preprint arXiv:2511.18902 , year=
VADE: Variance-Aware Dynamic Sampling via Online Sample-Level Difficulty Estimation for Multimodal RL , author=. arXiv preprint arXiv:2511.18902 , year=
-
[75]
arXiv preprint arXiv:2602.14338 , year=
Train less, learn more: Adaptive efficient rollout optimization for group-based reinforcement learning , author=. arXiv preprint arXiv:2602.14338 , year=
-
[76]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[77]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[78]
arXiv preprint arXiv:2502.01427 , year=
Structural features of the fly olfactory circuit mitigate the stability-plasticity dilemma in continual learning , author=. arXiv preprint arXiv:2502.01427 , year=
-
[79]
Heming Zou and Yunliang Zang and Wutong Xu and Xiangyang Ji , booktitle=. Fly-. 2026 , url=
2026
-
[80]
arXiv preprint arXiv:2603.19145 , year=
Enhancing pretrained model-based continual representation learning via guided random projection , author=. arXiv preprint arXiv:2603.19145 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.