RAIL: Rethinking Auditory Intelligence in Large Audio-Language Models with a CHC-Grounded Benchmark
Pith reviewed 2026-06-27 12:10 UTC · model grok-4.3
The pith
Current large audio-language models perform unevenly across five core auditory cognitive abilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
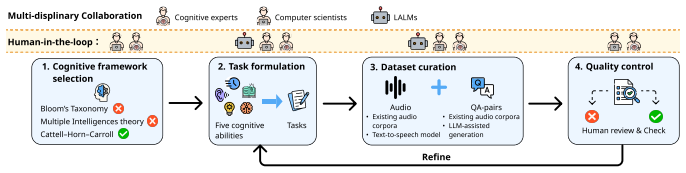
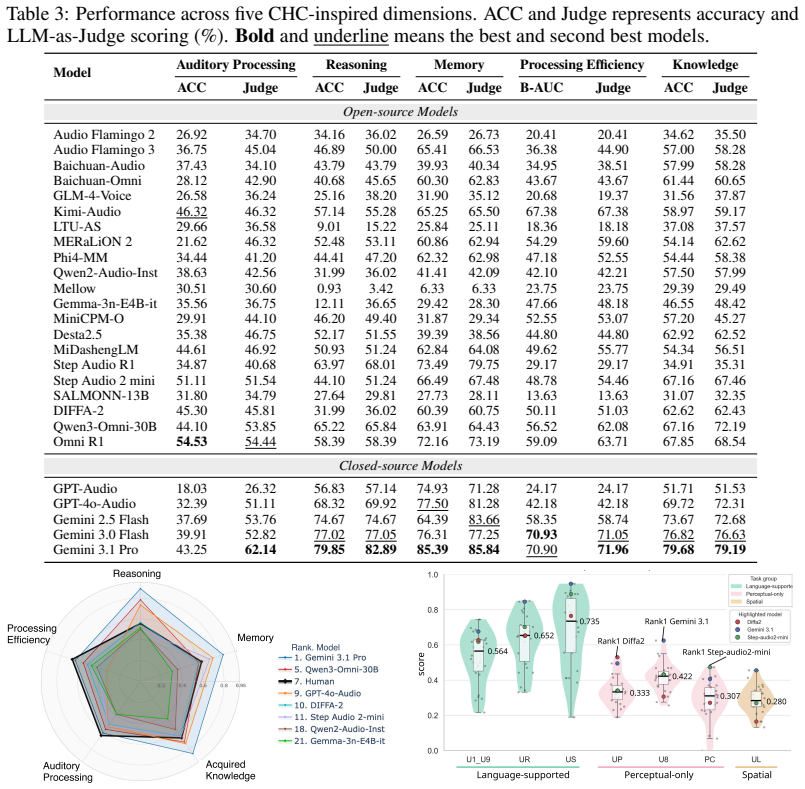
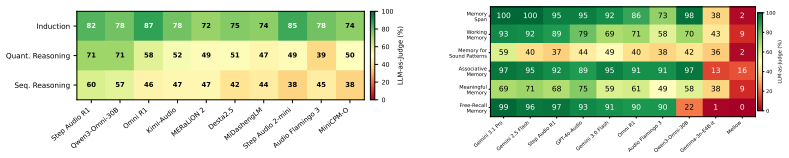
RAIL formalises auditory cognition into five core capabilities and develops them into structured evaluation tasks that probe how models process, retain, and integrate auditory information. It constructs a cognitively grounded benchmark with principled data curation and human-aligned evaluation protocols. Evaluating twenty-six state-of-the-art large audio-language models reveals that current models exhibit highly uneven performance across cognitive abilities. This establishes a new evaluation paradigm that moves beyond task-centric benchmarking toward cognitively grounded assessment of auditory intelligence.
What carries the argument
The CHC-grounded framework that divides auditory cognition into five core capabilities and turns them into tasks for measuring model processing, retention, and integration of auditory information.
If this is right
- Model evaluation must separate performance on individual cognitive abilities rather than report only aggregate task scores.
- Development of new large audio-language models should target balanced results across perception, reasoning, memory, and integration.
- Benchmark construction will shift toward tasks that follow human cognitive categories and use aligned scoring methods.
- Gaps in auditory intelligence that remain hidden under current task-focused tests will become visible and measurable.
Where Pith is reading between the lines
- Designers could use the same five-capability structure to guide training objectives that improve weaker areas first.
- The approach might extend to testing how well models handle mixed audio and visual inputs using the same cognitive breakdown.
- Repeated use of the benchmark over time could track whether new models close specific cognitive gaps or simply improve on average.
Load-bearing premise
The five core capabilities drawn from the CHC framework can be turned into evaluation tasks that measure model auditory cognition without direct comparison to human behavior or existing audio benchmarks.
What would settle it
A result showing that the twenty-six models achieve nearly identical scores across all five capabilities or that those scores match performance on existing task-only audio benchmarks.
Figures






read the original abstract
Humans process rich auditory environments through tightly integrated cognitive capabilities such as audio perception, audio reasoning, and memory. Despite recent progress in large audio-language models (LALMs) across speech understanding and multimodal audio reasoning, current evaluation paradigms remain largely task- or modality-centric, focusing on end performance while overlooking underlying auditory cognitive behaviours. This reveals a fundamental gap between how auditory cognition is understood in humans and how it is evaluated in LALMs, particularly in the lack of frameworks that operationalise cognitive principles beyond task-level metrics to systematically capture model behaviour. In this work, we introduce RAIL, a human-centric evaluation paradigm grounded in the Cattell-Horn-Carroll (CHC) cognitive framework. RAIL formalises auditory cognition into five core capabilities and develop them into structured evaluation tasks that probe how models process, retain, and integrate auditory information. We further construct a cognitively grounded benchmark with principled data curation and human-aligned evaluation protocols. Evaluating 26 state-of-the-art LALMs, we find that current models exhibit highly uneven performance across cognitive abilities. RAIL establishes a new evaluation paradigm that moves beyond task-centric benchmarking toward cognitively grounded assessment of auditory intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RAIL, a CHC-grounded benchmark for large audio-language models (LALMs). It formalizes auditory cognition into five core capabilities, develops them into structured evaluation tasks, constructs a benchmark via principled data curation and human-aligned protocols, evaluates 26 state-of-the-art LALMs, and reports highly uneven performance across abilities, positioning this as a shift from task-centric to cognitively grounded assessment of auditory intelligence.
Significance. If the CHC-derived tasks are shown to validly capture auditory cognition (via human data or existing-benchmark correlations), the work could provide a more principled evaluation framework. The broad evaluation of 26 models is a strength, but the absence of validation evidence limits the ability to interpret uneven performance as evidence of cognitive differences rather than surface task effects.
major comments (2)
- [Abstract] Abstract: The claim that RAIL offers 'cognitively grounded' assessment and 'human-aligned evaluation protocols' is load-bearing for the central contribution, yet the abstract provides no details on task design, data sources, exclusion criteria, inter-rater reliability, human behavioral data collection on the same tasks, or correlation analysis against existing audio benchmarks. Without these, it is impossible to assess whether the reported uneven performance across the five CHC capabilities reflects genuine differences in model auditory cognition.
- [Abstract] Abstract: The weakest assumption—that the five CHC capabilities can be operationalized into tasks that validly capture model auditory cognition without direct human validation or benchmark correlation—is not addressed, undermining the interpretation that current models exhibit 'highly uneven performance across cognitive abilities' as opposed to task-specific performance.
minor comments (1)
- [Abstract] Abstract: The five core capabilities are referenced but not named, which would improve clarity for readers assessing the scope of the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to substantiate claims of cognitive grounding. We address each point below, clarifying where details appear in the manuscript and proposing targeted revisions to the abstract and discussion sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that RAIL offers 'cognitively grounded' assessment and 'human-aligned evaluation protocols' is load-bearing for the central contribution, yet the abstract provides no details on task design, data sources, exclusion criteria, inter-rater reliability, human behavioral data collection on the same tasks, or correlation analysis against existing audio benchmarks. Without these, it is impossible to assess whether the reported uneven performance across the five CHC capabilities reflects genuine differences in model auditory cognition.
Authors: We agree the abstract is too concise to preview the supporting methodology. Task design follows the CHC framework (detailed in Section 3), data sources and exclusion criteria are described in Section 4.1, and inter-rater reliability plus human-aligned protocols appear in Section 4.2. We will revise the abstract to include a one-sentence summary of these elements. Direct human behavioral data collection on the RAIL tasks and explicit correlation analyses against prior audio benchmarks are not included in the current study; the grounding instead derives from the established CHC theoretical structure and curation principles. revision: partial
-
Referee: [Abstract] Abstract: The weakest assumption—that the five CHC capabilities can be operationalized into tasks that validly capture model auditory cognition without direct human validation or benchmark correlation—is not addressed, undermining the interpretation that current models exhibit 'highly uneven performance across cognitive abilities' as opposed to task-specific performance.
Authors: This assumption is addressed through the CHC framework's established validity in cognitive psychology and the principled mapping of capabilities to tasks in Section 3. However, we do not present new human validation data or benchmark correlations in the manuscript. We will add an explicit limitations paragraph discussing this assumption and its implications for result interpretation, and we will qualify the abstract language accordingly. revision: yes
- Direct human behavioral data collection on the RAIL tasks or correlation analyses against existing audio benchmarks, as these were outside the scope of the presented study.
Circularity Check
No circularity: benchmark construction applies external CHC framework without self-referential derivations or fitted predictions
full rationale
The paper constructs and applies the RAIL benchmark by operationalizing the established external Cattell-Horn-Carroll (CHC) cognitive framework into five capabilities and tasks. No equations, parameter fitting, or predictions are described that reduce to inputs by construction. The central contribution is the benchmark itself and its application to 26 models, which does not rely on self-citation chains or imported uniqueness theorems for its claims. This is a standard benchmark paper whose derivation chain is self-contained against external psychological literature.
Axiom & Free-Parameter Ledger
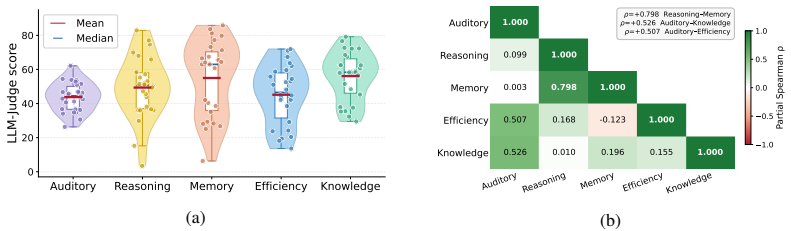
Reference graph
Works this paper leans on
-
[1]
Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems, 36: 18090–18108, 2023
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems, 36: 18090–18108, 2023
2023
-
[2]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models.arXiv preprint arXiv:2310.13289, 2023
Pith/arXiv arXiv 2023
-
[3]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023
Pith/arXiv arXiv 2023
-
[4]
Wavllm: Towards robust and adaptive speech large language model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, et al. Wavllm: Towards robust and adaptive speech large language model. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4552–4572, 2024
2024
-
[5]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
Pith/arXiv arXiv 2024
-
[6]
Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities. arXiv preprint arXiv:2402.01831, 2024
arXiv 2024
-
[7]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities.arXiv preprint arXiv:2503.03983, 2025
arXiv 2025
-
[8]
Audiobench: A universal benchmark for audio large language models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy Chen. Audiobench: A universal benchmark for audio large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
2025
-
[9]
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168, 2024. 10
Pith/arXiv arXiv 2024
-
[10]
Mmau- pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence
Sonal Kumar, Šimon Sedlá ˇcek, Vaibhavi Lokegaonkar, Fernando López, Wenyi Yu, Nishit Anand, Hyeonggon Ryu, Lichang Chen, Maxim Pli ˇcka, Miroslav Hlavá ˇcek, et al. Mmau- pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2...
2026
-
[11]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, et al. Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix.arXiv preprint arXiv:2505.13032, 2025
arXiv 2025
-
[12]
Wanqi Yang, Yanda Li, Yunchao Wei, Meng Fang, and Ling Chen. Speechr: A benchmark for speech reasoning in large audio-language models.arXiv preprint arXiv:2508.02018, 2025
arXiv 2025
-
[13]
Air-bench: Benchmarking large audio-language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, and Jingren Zhou. Air-bench: Benchmarking large audio-language models via generative comprehension. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1979–1998, 2024
1979
-
[14]
The cattell-horn-carroll theory of cognitive abilities
W Joel Schneider and Kevin S McGrew. The cattell-horn-carroll theory of cognitive abilities. Contemporary intellectual assessment: Theories, tests, and issues, 733:163, 2018
2018
-
[15]
Bloom’s taxonomy, 1956
Benjamin Bloom. Bloom’s taxonomy, 1956
1956
-
[16]
Chc theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research, 2009
Kevin S McGrew. Chc theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research, 2009
2009
-
[17]
Jewsbury, Stephen C
Paul A. Jewsbury, Stephen C. Bowden, and Kevin Duff. The cattell–horn–carroll model of cognition for clinical assessment.Journal of Psychoeducational Assessment, 35(6):547–567, 2016
2016
-
[18]
Caemmerer, Timothy Z
Jacqueline M. Caemmerer, Timothy Z. Keith, and Matthew R. Reynolds. Beyond individual intelligence tests: Application of cattell-horn-carroll theory.Intelligence, 79:101433, 2020
2020
-
[19]
Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[20]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
Pith/arXiv arXiv 2026
-
[21]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[22]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[23]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[24]
A survey on speech large language models for understanding.IEEE Journal of Selected Topics in Signal Processing, 2025
Jing Peng, Yucheng Wang, Bohan Li, Yiwei Guo, Hankun Wang, Yangui Fang, Yu Xi, Haoyu Li, Xu Li, Ke Zhang, et al. A survey on speech large language models for understanding.IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[25]
Blab: Brutally long audio bench.arXiv preprint arXiv:2505.03054, 2025
Orevaoghene Ahia, Martijn Bartelds, Kabir Ahuja, Hila Gonen, Valentin Hofmann, Siddhant Arora, Shuyue Stella Li, Vishal Puttagunta, Mofetoluwa Adeyemi, Charishma Buchireddy, et al. Blab: Brutally long audio bench.arXiv preprint arXiv:2505.03054, 2025
arXiv 2025
-
[26]
Peize He, Zichen Wen, Yubo Wang, Yuxuan Wang, Xiaoqian Liu, Jiajie Huang, Zehui Lei, Zhuangcheng Gu, Xiangqi Jin, Jiabing Yang, et al. Audiomarathon: A comprehensive bench- mark for long-context audio understanding and efficiency in audio llms.arXiv preprint arXiv:2510.07293, 2025. 11
arXiv 2025
-
[27]
The cattell-horn-carroll model of intelligence
W Joel Schneider and Kevin S McGrew. The cattell-horn-carroll model of intelligence. 2012
2012
-
[28]
Number 1
John Bissell Carroll.Human cognitive abilities: A survey of factor-analytic studies. Number 1. Cambridge university press, 1993
1993
-
[29]
Dingdong W ANG, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen M. Meng. MMSU: A massive multi-task spoken language understanding and reasoning benchmark. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[30]
SAKURA: on the multi-hop reasoning of large audio-language models based on speech and audio information
Chih-Kai Yang, Neo Ho, Yen-Ting Piao, and Hung-yi Lee. SAKURA: on the multi-hop reasoning of large audio-language models based on speech and audio information. InProc. Interspeech, pages 1788–1792, 2025
2025
-
[31]
The muse benchmark: Probing music perception and auditory relational reasoning in audio llms
Brandon James Carone, Iran R Roman, and Pablo Ripollés. The muse benchmark: Probing music perception and auditory relational reasoning in audio llms. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 16097–16101. IEEE, 2026
2026
-
[32]
Yirong Sun, Yanjun Chen, Xin Qiu, Gang Zhang, Hongyu Chen, Daokuan Wu, Chengming Li, Min Yang, Dawei Zhu, Wei Zhang, and Xiaoyu Shen. Sonicbench: Dissecting the physical perception bottleneck in large audio language models.arXiv preprint arXiv:2601.11039, 2026
arXiv 2026
-
[33]
Zihan Liu, Zhikang Niu, Qiuyang Xiao, Zhisheng Zheng, Ruoqi Yuan, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Jianze Liang, Xie Chen, et al. Star-bench: Probing deep spatio-temporal reasoning as audio 4d intelligence.arXiv preprint arXiv:2510.24693, 2025
arXiv 2025
-
[34]
Educational implications of the theory of multiple intelligences.Educational researcher, 18(8):4–10, 1989
Howard Gardner and Thomas Hatch. Educational implications of the theory of multiple intelligences.Educational researcher, 18(8):4–10, 1989
1989
-
[35]
The theory of multiple intelligences.Davis, K., Christodoulou, J., Seider, S., & Gardner, H.(2011)
Katie Davis, Joanna Christodoulou, Scott Seider, and Howard Earl Gardner. The theory of multiple intelligences.Davis, K., Christodoulou, J., Seider, S., & Gardner, H.(2011). The theory of multiple intelligences. In RJ Sternberg & SB Kaufman (Eds.), Cambridge Handbook of Intelligence, pages 485–503, 2011
2011
-
[36]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[37]
Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
Pith/arXiv arXiv 2025
-
[38]
Diffa-2: A practical diffusion large language model for general audio understanding
Jiaming Zhou, Xuxin Cheng, Shiwan Zhao, Yuhang Jia, Cao Liu, Ke Zeng, Xunliang Cai, and Yong Qin. Diffa-2: A practical diffusion large language model for general audio understanding. arXiv preprint arXiv:2601.23161, 2026
arXiv 2026
-
[39]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, et al. Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025
arXiv 2025
-
[40]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[41]
Omni-R1: do you really need audio to fine-tune your audio llm? In2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–7, 2025
Andrew Rouditchenko, Saurabhchand Bhati, Edson Araujo, Samuel Thomas, Hilde Kuehne, Rogerio Feris, and James Glass. Omni-R1: do you really need audio to fine-tune your audio llm? In2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–7, 2025. 12 Appendix A Experimental Setup & Implementation A.1 Evaluated Models Details Model ...
2025
-
[42]
Identify the final answer expressed in the model response
-
[43]
The final answer may be expressed directly, indirectly, or as a paraphrase
-
[44]
Compare the model’s final answer with the gold answer for semantic equivalence
-
[45]
What are the most probable general rules that indicate these audio samples should be classified as expressing surprise?
Do not grade reasoning quality. Only judge whether the final answer matches the gold answer. Respond with EXACTLY one word – nothing else: true – the model’s final answer matches the gold answer false – the model’s final answer does not match, or no definite answer was given LLM-as-Judge User Message Gold answer: {reference} Model response: {prediction} D...
-
[46]
Different question types require attending to different kinds of acoustic evidence
-
[47]
reverse the sequence
The answer should be based on the audio cues most relevant to the asked property, not on unrelated details. Decision Rule: IF the question specifies a target property, THEN first identify what type of acoustic evidence is relevant to that property, then use the audio to confirm, compare, or rule out candidate interpretations, and choose the answer best su...
-
[48]
If the audio clip could be classified as male speaking, reverse the sequence
-
[49]
Ignoring the repeated major third chord at the end of the audio, how many times did it modulate in total? Select the correct answer from the following choices: A) 2 B) 4 C) 5 D) 3
If the audio clip could be classified as female speaking, repeat each element so that each item appears twice. Statement: Sequence start with <Apple, Banana, Pear>. The audio contains 2 clips separated by 1 second of silence. Each clip is a speaker utterance. Apply the corresponding rule to transform the start sequence. Question: Which of the following is...
-
[50]
The correlation is close to zero and not significant. This supports the claim that efficiency is shaped more by generation strategy, output discipline, and training behavior than by parameter count alone. C.3 Open-source versus closed-source models This test supports the conclusion in Section 5 that closed-source models outperform open-source models overa...
arXiv 2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.