Signed Compression Progress on a Sealed Audit is Goodhart-Resistant
Pith reviewed 2026-06-27 13:50 UTC · model grok-4.3
The pith
Signed decrease of a fixed sealed audit loss makes cumulative intrinsic reward telescope exactly to endpoint audit improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Defining intrinsic reward as r_t = E(theta_{t-1}) - E(theta_t) where E is a fixed sealed audit loss causes the cumulative reward sum to telescope directly to E(theta_0) - E(theta_T). For finite audits the empirical version of this sum is bounded by the true improvement plus 2 Delta_n(F, delta), the uniform deviation of the model class. The guarantee is therefore horizon-free once the sealed panel controls the class uniformly.
What carries the argument
The signed decrease r_t = E(theta_{t-1}) - E(theta_t) of the fixed sealed audit loss E, which produces exact telescoping of cumulative reward.
If this is right
- Cumulative reward cannot grow indefinitely without corresponding audit improvement.
- The bound holds regardless of training horizon or policy adaptivity.
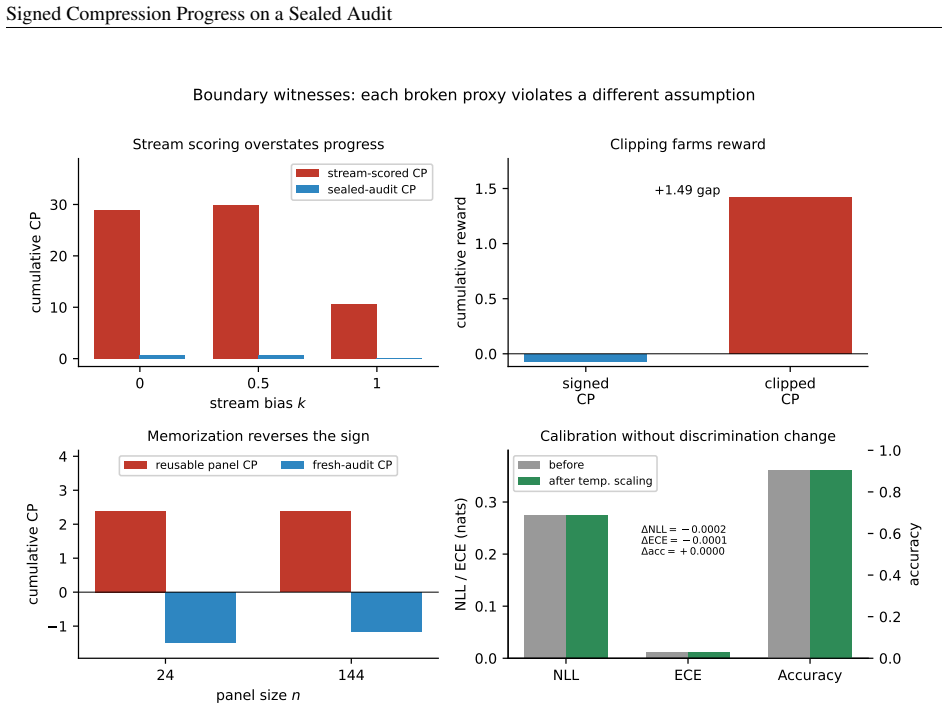
- Clipping the progress signal, reusing the audit panel, or applying it to a neural class with vacuous Delta_n removes the guarantee.
- Experiments on ARC-TGI confirm that deviation scales roughly as n to the minus 0.5 and that the signed signal resists clip-farming and stream-leakage attacks.
Where Pith is reading between the lines
- The same telescoping construction could be tested on other intrinsic signals such as prediction error or empowerment.
- Designing new sealed-audit protocols for larger model classes would make the deviation bound practical for modern reinforcement learning.
- The failure-mode list suggests concrete defenses such as one-time panels and capacity-limited auditors that could be validated on additional benchmarks.
Load-bearing premise
The audit loss E must stay fixed and sealed while the model class admits a non-vacuous uniform deviation bound over the audit panel.
What would settle it
An agent that collects cumulative signed reward exceeding the observed audit improvement by more than twice the measured uniform deviation on the given panel size.
Figures






read the original abstract
Compression progress is a long-standing proposal for intrinsic motivation: reward an agent when its world model becomes better at predicting or compressing experience. The folk claim is that this reward is "credible" because it is paid only for learning. We make this precise and prove it. If intrinsic reward is the signed decrease of a fixed sealed-audit loss, r_t = E(theta_{t-1}) - E(theta_t), then cumulative reward telescopes exactly to endpoint audit improvement, so no policy can push reward up indefinitely while true audit performance stagnates or degrades. For finite audit panels the same result holds with a sharp false-positive budget: cumulative empirical reward is at most true audit improvement plus 2 Delta_n(F, delta), the uniform audit deviation of the model class. This is horizon-free: adaptivity over time costs nothing once the sealed panel uniformly controls the class. The theorem also identifies the failure modes: the guarantee disappears if progress is clipped, scored on the agent's own stream, exposed to a high-capacity model on a reusable panel, or applied to a neural class that makes Delta_n vacuous. We give a Lean 4 mechanization of the structural core (telescoping, the finite-audit bound, finite Gibbs, and the entropy floor) and an experiment suite on ARC-TGI grid-transformation generators with adaptive holdout attacks. Experiments confirm the theory: finite-audit deviation scales as n^{-0.527}; signed progress resists clip-farming, stream leakage, and noisy-TV curiosity; naive reusable audits are exploitable by black-box scalar feedback, while standard release defenses keep the attack below the 2 Delta_n threshold. Signed compression progress on a sealed audit is an accounting signal of genuine improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that if intrinsic reward is defined as the signed decrease of a fixed sealed-audit loss E, r_t = E(θ_{t-1}) - E(θ_t), then cumulative reward telescopes exactly to endpoint audit improvement, preventing indefinite reward inflation without genuine progress. For finite audit panels the same identity holds up to a uniform deviation bound of 2Δ_n(F, δ). The work supplies a Lean 4 mechanization of the telescoping identity, finite-audit bound, finite Gibbs, and entropy floor, together with ARC-TGI experiments that test clipping, stream leakage, reusable panels, and noisy-TV attacks, explicitly listing the conditions (clipping, reusable panel, vacuous Δ_n) under which the guarantee fails.
Significance. If the central telescoping identity and uniform bound hold, the result supplies a parameter-free, horizon-free accounting identity that converts a sealed audit into a Goodhart-resistant intrinsic reward, with machine-checked proofs and targeted experiments that directly probe the listed failure modes. This strengthens the theoretical basis for compression-progress rewards in RL by making the resistance claim falsifiable and by quantifying the false-positive budget for finite panels.
minor comments (3)
- [§3] §3 (uniform deviation): the statement of Δ_n(F, δ) should explicitly reference the covering-number or Rademacher complexity argument used to obtain the n^{-0.527} empirical rate, so readers can verify the constant factors in the 2Δ_n budget.
- [Table 1] Table 1 (ARC-TGI results): the reusable-panel attack row reports deviation above 2Δ_n; confirm that the black-box scalar feedback is exactly the setting excluded by the sealed-audit assumption, or add a column showing the defended release case.
- The Lean mechanization is cited but the repository or theorem names are not listed in the main text; add a short appendix table mapping each mechanized lemma to the corresponding paper equation.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly captures the telescoping identity, the 2 Delta_n bound, the Lean mechanization, and the enumerated failure modes.
Circularity Check
No significant circularity identified
full rationale
The paper defines intrinsic reward explicitly as the signed decrease r_t = E(theta_{t-1}) - E(theta_t) on a fixed sealed audit loss and shows that the cumulative sum therefore equals the total endpoint improvement by the telescoping property of summation. This is presented as a direct algebraic identity (with an added uniform deviation bound for finite panels), not as a derived prediction or first-principles result obtained from other inputs. The paper states the conditions under which the guarantee holds or fails, supplies a Lean 4 mechanization of the identity and bounds, and reports experiments testing the listed failure modes. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or smuggled ansatz; the derivation is self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The audit loss E is a fixed, sealed function independent of the agent's policy and data stream.
- domain assumption The model class F admits a uniform deviation bound Delta_n(F, delta) that holds simultaneously for all models in the class.
Reference graph
Works this paper leans on
-
[1]
Schapire
Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E. Schapire. The nonstochastic multiarmed bandit problem.SIAM Journal on Computing, 32(1):48–77, 2002
2002
-
[2]
The Ladder: A reliable leaderboard for machine learning competitions
Avrim Blum and Moritz Hardt. The Ladder: A reliable leaderboard for machine learning competitions. arXiv:1502.04585, 2015
Pith/arXiv arXiv 2015
-
[3]
Exploration by random network distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation. arXiv:1810.12894, 2018
Pith/arXiv arXiv 2018
-
[4]
ARC Prize 2025: Technical report
François Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. ARC Prize 2025: Technical report. arXiv:2601.10904, 2026
arXiv 2025
-
[5]
Generalization in adaptive data analysis and holdout reuse
Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Roth. Generalization in adaptive data analysis and holdout reuse. arXiv:1506.02629, 2015
Pith/arXiv arXiv 2015
-
[6]
Zarin Nishat, Dhananjay Bhandiwad, Andrei Aioanei, and Sahar Vahdati
Jens Lehmann, Syeda Khushbakht, Nikoo Salehfard, Nur A. Zarin Nishat, Dhananjay Bhandiwad, Andrei Aioanei, and Sahar Vahdati. ARC-TGI: Human-validated task generators with reasoning chain templates for ARC-AGI. arXiv:2603.05099, 2026
arXiv 2026
-
[7]
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven exploration by self- supervised prediction. arXiv:1705.05363, 2017
Pith/arXiv arXiv 2017
-
[8]
A possibility for implementing curiosity and boredom in model-building neural controllers
Jürgen Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. InFrom Animals to Animats: Proceedings of the First International Conference on Simulation of Adaptive Behavior, MIT Press/Bradford Books, 1991
1991
-
[9]
Jürgen Schmidhuber. Driven by compression progress: A simple principle explains essential aspects of subjective beauty, novelty, surprise, interestingness, attention, curiosity, creativity, art, science, music, jokes. arXiv:0812.4360, 2008
Pith/arXiv arXiv 2008
-
[10]
Formal theory of creativity, fun, and intrinsic motivation (1990–2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247, 2010
Jürgen Schmidhuber. Formal theory of creativity, fun, and intrinsic motivation (1990–2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247, 2010
1990
-
[11]
Concrete problems in AI safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety. arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[12]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[13]
Joel Lehman, Jeff Clune, Dusan Misevic, and others. The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities.Artificial Life, 26(2):274– 306, 2020
2020
-
[14]
Categorizing variants of Goodhart’s law
David Manheim and Scott Garrabrant. Categorizing variants of Goodhart’s law. arXiv:1803.04585, 2018
Pith/arXiv arXiv 2018
-
[15]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[16]
Do ImageNet classifiers generalize to ImageNet? InInternational Conference on Machine Learning (ICML), 2019
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do ImageNet classifiers generalize to ImageNet? InInternational Conference on Machine Learning (ICML), 2019
2019
-
[17]
A meta-analysis of overfitting in machine learning
Rebecca Roelofs, Vaishaal Shankar, Benjamin Recht, Sara Fridovich-Keil, Moritz Hardt, John Miller, and Ludwig Schmidt. A meta-analysis of overfitting in machine learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[18]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 16
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.