APEX: Automated Prompt Engineering eXpert with Dynamic Data Selection
Pith reviewed 2026-06-27 13:00 UTC · model grok-4.3
The pith
APEX improves automatic prompt optimization by dynamically selecting which data to evaluate during the search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
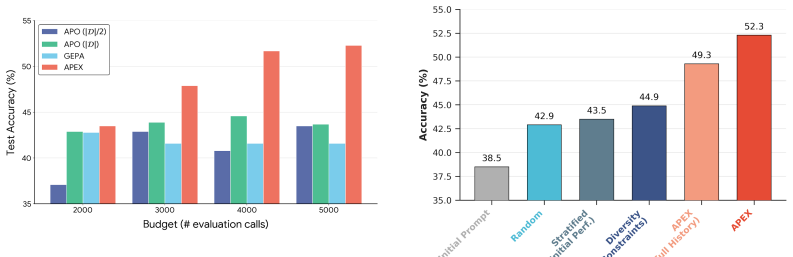
APEX dynamically stratifies the dataset into Easy, Hard, and Mixed tiers based on the optimization lineage. Prioritizing the Mixed tier identifies the addressable frontier for generating informative mutations and the rank-sensitive frontier for distinguishing candidate quality, which together yield higher performance than static data usage under the same evaluation budget.
What carries the argument
Dynamic stratification of the evaluation set into Easy, Hard, and Mixed tiers based on optimization lineage, used to select addressable and rank-sensitive data subsets.
If this is right
- Prompt search can be made substantially more efficient without changing the underlying mutation operators.
- Performance gains appear on instruction-following, question-answering, and grounding tasks when the same budget is used.
- The same data-tiering idea could be applied to other iterative optimization loops that consume evaluation calls.
Where Pith is reading between the lines
- The approach may reduce the total number of model calls needed to reach a target prompt quality in production settings.
- If the tiering logic proves stable across different base models, it could become a standard module in prompt-optimization libraries.
Load-bearing premise
That splitting data into easy, hard, and mixed tiers according to the optimization history reliably marks the subsets that best support mutation generation and candidate ranking.
What would settle it
Running the same evolutionary search with random data selection under the identical 5,000-call budget and obtaining equal or larger gains on the three benchmarks.
Figures



read the original abstract
Large Language Models are highly sensitive to prompt formulation, necessitating automatic prompt optimization to unlock their full potential. While evolutionary algorithms have emerged as the dominant paradigm, they suffer from a critical bottleneck: data efficiency. Current methods treat the development dataset as a static benchmark, wasting significant compute budget on uninformative data. In this work, we introduce APEX (Automatic Prompt Engineering eXpert), a novel framework that optimizes the data usage alongside the prompt search. APEX dynamically stratifies the dataset into Easy, Hard, and Mixed tiers based on the optimization lineage. By prioritizing the Mixed tier, which identifies the data where the LLM has mixed performance, we identify two high-leverage subsets: the addressable frontier for generating informative mutations and the rank-sensitive frontier for distinguishing candidate quality. We evaluate APEX across three diverse benchmarks: IFBench, SimpleQA Verified, and FACTS Grounding. Under a fixed budget of 5,000 evaluation calls, due to its data efficiency, APEX outperforms the initial prompt by an average of 11.2% on Gemini 2.5 Flash and 6.8% on Gemma 3 27B, demonstrating that a data-centric approach is key to efficient and effective prompt optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces APEX, a framework for automatic prompt optimization that dynamically stratifies the development dataset into Easy, Hard, and Mixed tiers based on optimization lineage. By prioritizing the Mixed tier (instances with mixed LLM performance), it targets two high-leverage subsets: the addressable frontier for generating informative mutations and the rank-sensitive frontier for distinguishing candidate quality. Under a fixed budget of 5,000 evaluation calls, APEX is reported to outperform the initial prompt by 11.2% on Gemini 2.5 Flash and 6.8% on Gemma 3 27B across IFBench, SimpleQA Verified, and FACTS Grounding.
Significance. If the lineage-based tiering is shown to isolate genuinely high-leverage subsets and the efficiency gains are reproducible, the work would meaningfully advance data-efficient prompt optimization, a practical bottleneck in evolutionary methods. The explicit focus on data usage alongside prompt search is a clear conceptual contribution, though the absence of validation for the core stratification mechanism limits current assessment of impact.
major comments (2)
- [Abstract / Methods (dynamic stratification)] The central efficiency claim (abstract) rests on the assertion that the Mixed tier 'identifies the data where the LLM has mixed performance' and thereby surfaces the addressable and rank-sensitive frontiers. No ablation, metric, or derivation is supplied showing that Mixed instances exhibit measurably higher mutation informativeness or rank sensitivity than random or static subsets; without this, performance gains under the 5,000-call budget cannot be confidently attributed to the claimed data-centric mechanism rather than implicit selection.
- [Abstract / Experimental results] The reported improvements (11.2% and 6.8%) are stated without accompanying experimental details, baseline definitions, error bars, or ablation results on the tiering component. This makes it impossible to verify whether the gains are load-bearing on the Mixed-tier prioritization or could arise from other factors in the evolutionary loop.
minor comments (1)
- [Abstract] The abstract supplies performance numbers but omits any description of the three benchmarks, the initial prompt, or how the 5,000-call budget is allocated across tiers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important gaps in validation and reporting that we will address through targeted revisions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Methods (dynamic stratification)] The central efficiency claim (abstract) rests on the assertion that the Mixed tier 'identifies the data where the LLM has mixed performance' and thereby surfaces the addressable and rank-sensitive frontiers. No ablation, metric, or derivation is supplied showing that Mixed instances exhibit measurably higher mutation informativeness or rank sensitivity than random or static subsets; without this, performance gains under the 5,000-call budget cannot be confidently attributed to the claimed data-centric mechanism rather than implicit selection.
Authors: We agree that the current manuscript lacks direct empirical validation isolating the properties of the Mixed tier. The methods section defines the lineage-based stratification and the prioritization rule, but does not include quantitative comparisons of mutation success rates or ranking correlation on Mixed versus random/static subsets. In the revision we will add a dedicated ablation subsection that reports (i) the fraction of successful mutations generated from each tier and (ii) Spearman rank correlation between per-instance scores on the tier and final prompt ranking accuracy, all under controlled budgets. This will allow readers to assess whether the observed gains are attributable to the data-centric mechanism. revision: yes
-
Referee: [Abstract / Experimental results] The reported improvements (11.2% and 6.8%) are stated without accompanying experimental details, baseline definitions, error bars, or ablation results on the tiering component. This makes it impossible to verify whether the gains are load-bearing on the Mixed-tier prioritization or could arise from other factors in the evolutionary loop.
Authors: The abstract necessarily summarizes results at a high level; the full manuscript contains the experimental protocol, baseline prompt definitions, and per-benchmark tables. However, we acknowledge that error bars, multiple-run statistics, and an explicit ablation isolating the tiering component are not presented with sufficient prominence. The revised version will (a) report mean and standard deviation across three independent runs for all main results, (b) add a table that ablates the Mixed-tier prioritization against a random-subset baseline under the same 5,000-call budget, and (c) move key experimental details from the appendix into the main experimental section for easier verification. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a methodological framework for dynamic dataset stratification into Easy/Hard/Mixed tiers based on optimization lineage, then claims empirical gains under a fixed 5,000-call budget. No equations, fitted parameters, or self-citations appear in the provided text. The central claims rest on experimental results rather than any derivation that reduces by construction to its own inputs or renames a fitted quantity as a prediction. The stratification is presented as an independent design choice whose validity is asserted via downstream performance, not via self-definition or load-bearing self-citation. This is the common case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Instructzero: Efficient instruction optimization for black-box large language models
Lichang Chen, Jiuhai Chen, Tom Goldstein, Heng Huang, and Tianyi Zhou. Instructzero: Efficient instruction optimization for black-box large language models. InInternational Conference on Machine Learning, pages 6503–6518. PMLR, 2024a. Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng...
2024
-
[3]
URLhttps://openreview.net/forum?id=zPKeJAEo27. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Rlprompt: Optimizing discrete text prompts with reinforcement learning
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. Rlprompt: Optimizing discrete text prompts with reinforcement learning. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 3369–3391,
2022
-
[5]
Model performance-guided evaluation data selection for effective prompt optimization
Ximing Dong, Shaowei Wang, Dayi Lin, and Ahmed Hassan. Model performance-guided evaluation data selection for effective prompt optimization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2844–2859,
2025
-
[6]
Lukas Haas, Gal Yona, Giovanni D’Antonio, Sasha Goldshtein, and Dipanjan Das
URLhttps://openreview.net/forum?id=ZG3RaNIsO8. Lukas Haas, Gal Yona, Giovanni D’Antonio, Sasha Goldshtein, and Dipanjan Das. Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge.arXiv preprint arXiv:2509.07968,
-
[7]
Instruction induction: From few examples to natural language task descriptions
Or Honovich, Uri Shaham, Samuel Bowman, and Omer Levy. Instruction induction: From few examples to natural language task descriptions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1935–1952,
1935
-
[8]
Automatic engineering of long prompts
Cho-Jui Hsieh, Si Si, Felix Yu, and Inderjit Dhillon. Automatic engineering of long prompts. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10672–10685,
2024
-
[9]
Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, et al. The facts grounding leaderboard: Benchmarking llms’ ability to ground responses to long-form input.arXiv preprint arXiv:2501.03200,
-
[10]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wag- ner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphae- volve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Optimizing instructions and demonstrations for multi-stage language model programs
Krista Opsahl-Ong, Michael Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340–9366,
2024
-
[12]
gradient descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957–7968,
2023
-
[13]
Generalizing Verifiable Instruction Following
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Taylor Shin, Yasaman Razeghi, Robert L Logan IV , Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts.arXiv preprint arXiv:2010.15980,
-
[15]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
11 Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InInternational Conference on Learning Representations, volume 2025, pages 10131–10165,
2025
-
[16]
Team Gemma, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Xingchen Wan, Han Zhou, Ruoxi Sun, Hootan Nakhost, Ke Jiang, Rajarishi Sinha, and Sercan Ö Arık. Maestro: Self-improving text-to-image generation via agent orchestration.arXiv preprint arXiv:2509.10704,
-
[18]
Data advisor: Dynamic data curation for safety alignment of large language models
Fei Wang, Ninareh Mehrabi, Palash Goyal, Rahul Gupta, Kai-Wei Chang, and Aram Galstyan. Data advisor: Dynamic data curation for safety alignment of large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8089–8100, 2024a. Xinyuan Wang, Chenxi Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, ...
2024
-
[19]
Prompt engineering a prompt engineer
Qinyuan Ye, Mohamed Ahmed, Reid Pryzant, and Fereshte Khani. Prompt engineering a prompt engineer. InFindings of the Association for Computational Linguistics: ACL 2024, pages 355–385,
2024
-
[20]
G r o u n d i n g
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. InAdvances in Neural Information Processing Systems, volume 36, pages 55006–55021, 2023a. Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Larg...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.