Enhancing Spectral Embedding through Robust and Flexible Knowledge Transfer in Electronic Health Records
Pith reviewed 2026-06-27 08:34 UTC · model grok-4.3
The pith
A spectral embedding method improves low-dimensional representations for rare-disease electronic health records by transferring knowledge from larger populations under flexible partial alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By relaxing restrictive one-to-one signal-alignment assumptions between the latent data matrix and knowledge matrix, a two-step spectral embedding procedure can identify and remove irrelevant components from the knowledge matrix and then apply projection-based recovery of shared and heterogeneous components, yielding improved low-dimensional embeddings for rare-disease cohorts.
What carries the argument
Two-step spectral embedding procedure that first removes irrelevant components from the knowledge matrix then projects to recover shared and heterogeneous components separately.
If this is right
- Embeddings remain useful when shared signals are weak and only partially aligned, which is typical for rare-disease data.
- The method separates shared structure from cohort-specific structure without forcing exact matching.
- Performance gains appear in both simulated data and a real multiple sclerosis electronic health record cohort.
Where Pith is reading between the lines
- The same two-step removal-plus-projection logic could be tested on other small-cohort settings that have access to a related larger dataset.
- If the removal step proves reliable, downstream tasks such as clustering or prediction on rare-disease records may improve without needing larger local samples.
- The approach suggests examining whether the same relaxation of alignment assumptions helps in other high-dimensional unsupervised settings beyond electronic health records.
Load-bearing premise
A knowledge matrix from a broader population shares a partially overlapping subspace with the rare-disease cohort and irrelevant components can be identified and removed before projection.
What would settle it
In a simulation with weak shared signals and partial alignment, the method fails to produce higher-quality patient or concept embeddings than standard spectral embedding without the knowledge transfer step.
Figures

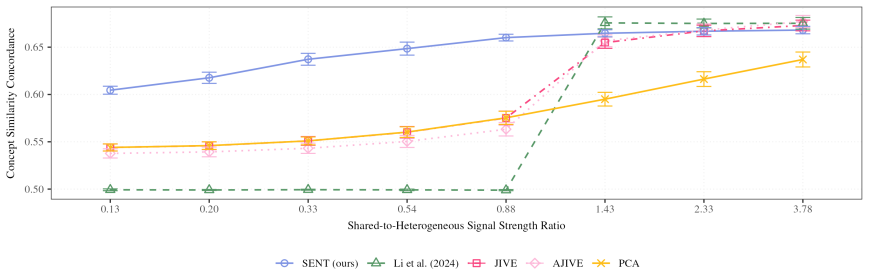
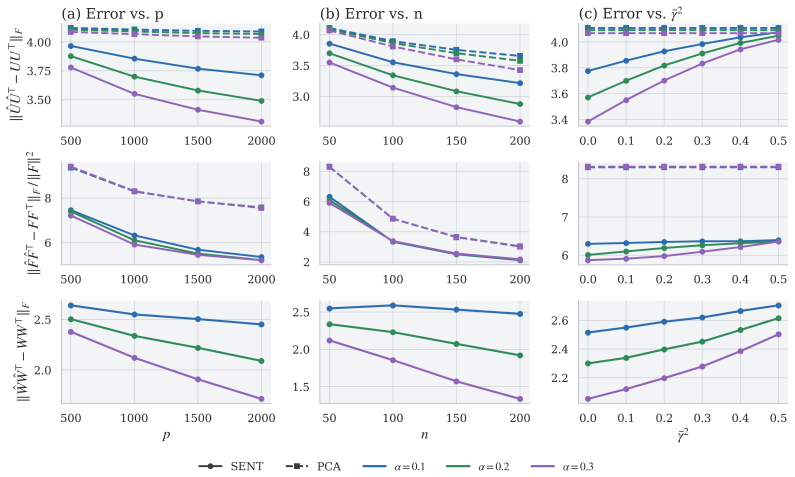
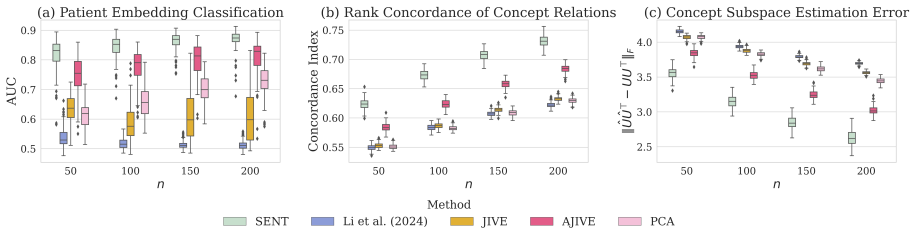
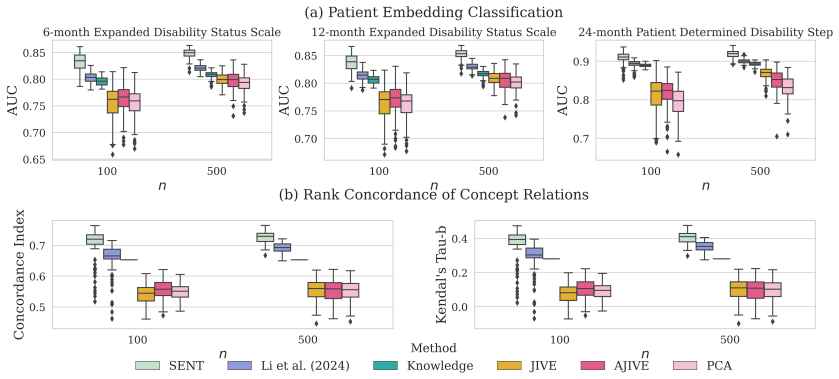

read the original abstract
We propose a spectral-based, unsupervised representation learning framework to derive low-dimensional embeddings for clinical concepts and patients in rare disease cohorts from electronic health records, where data are high-dimensional but sample sizes are limited. To overcome this challenge, we incorporate a knowledge matrix extracted from a broader population that shares a partially overlapping subspace with the rare-disease cohort. Our method departs from existing approaches by relaxing restrictive one-to-one signal-alignment assumptions between the latent data matrix and knowledge matrix, allowing more flexible and realistic forms of structured sharing. We introduce a novel two-step spectral embedding procedure: first, we identify and remove irrelevant components from the knowledge matrix; then, we apply a projection-based method to separately recover shared and heterogeneous components. Simulations and an analysis of a real-world multiple sclerosis cohort show that the proposed method outperforms competing approaches, particularly in challenging scenarios where shared signals are weak and only partially aligned, as is common in rare-disease data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a spectral-based unsupervised representation learning framework for deriving low-dimensional embeddings of clinical concepts and patients in rare-disease EHR cohorts. It incorporates a knowledge matrix from a broader population sharing a partially overlapping subspace, relaxing one-to-one signal-alignment assumptions via a novel two-step spectral procedure: first identifying and removing irrelevant components from the knowledge matrix, then applying projection to recover shared versus heterogeneous components. Simulations and a real-world multiple sclerosis cohort analysis are presented as evidence that the method outperforms competing approaches, especially under weak and only partially aligned shared signals.
Significance. If the empirical claims hold under rigorous verification, the work could advance representation learning for data-scarce rare-disease settings by enabling more flexible knowledge transfer from larger populations, addressing a practical limitation of existing spectral methods that assume strict alignment.
minor comments (2)
- [Abstract] The abstract states that the method 'outperforms competing approaches' but does not name the specific baselines or report quantitative metrics (e.g., embedding quality or downstream task performance); the results section should include these details for direct comparison.
- [Methods] The description of the two-step procedure would benefit from an explicit algorithmic outline or pseudocode to clarify the identification of irrelevant components and the projection step.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents a procedural two-step spectral embedding algorithm that first removes irrelevant components from an external knowledge matrix and then projects to recover shared versus heterogeneous signals. This is an algorithmic proposal whose validity is assessed via separate simulations and a real-world MS cohort analysis; no equations, fitted parameters, or self-citations are shown to reduce the claimed performance gains to the inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2011 , publisher=
Latent variable models and factor analysis: A unified approach , author=. 2011 , publisher=
2011
-
[2]
International Conference on Machine Learning , pages=
Geometric Autoencoders-What You See is What You Decode , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[3]
Matrix estimation by universal singular value thresholding , author=
-
[4]
, author=
Structural equation modeling in practice: A review and recommended two-step approach. , author=. Psychological bulletin , volume=. 1988 , publisher=
1988
-
[5]
psychometrika , volume=
A penalized likelihood method for structural equation modeling , author=. psychometrika , volume=. 2017 , publisher=
2017
-
[6]
psychometrika , volume=
Computation for latent variable model estimation: A unified stochastic proximal framework , author=. psychometrika , volume=. 2022 , publisher=
2022
-
[7]
The Annals of Statistics , number =
Lingzhou Xue and Hui Zou and Tianxi Cai , title =. The Annals of Statistics , number =
-
[8]
Estimation of Sparse Binary Pairwise Markov Networks using Pseudo-likelihoods , journal =
Holger H. Estimation of Sparse Binary Pairwise Markov Networks using Pseudo-likelihoods , journal =. 2009 , volume =
2009
-
[9]
High-dimensional covariance estimation by minimizing L1-penalized log-determinant divergence , author=
-
[10]
Psychometrika , volume=
Statistical analysis of sets of congeneric tests , author=. Psychometrika , volume=. 1971 , publisher=
1971
-
[11]
Frontiers in Ecology and Evolution , volume=
The Poisson-lognormal model as a versatile framework for the joint analysis of species abundances , author=. Frontiers in Ecology and Evolution , volume=. 2021 , publisher=
2021
-
[12]
Artificial intelligence and statistics , pages=
Stick-breaking construction for the Indian buffet process , author=. Artificial intelligence and statistics , pages=. 2007 , organization=
2007
-
[13]
British Journal of Mathematical and Statistical Psychology , volume=
An improved stochastic EM algorithm for large-scale full-information item factor analysis , author=. British Journal of Mathematical and Statistical Psychology , volume=. 2020 , publisher=
2020
-
[14]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=
Adaptive rejection sampling for Gibbs sampling , author=. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=. 1992 , publisher=
1992
-
[15]
Machine learning , volume=
Learning a factor model via regularized PCA , author=. Machine learning , volume=. 2013 , publisher=
2013
-
[16]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Probabilistic principal component analysis , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1999 , publisher=
1999
-
[17]
The Journal of Machine Learning Research , volume=
Inference for the case probability in high-dimensional logistic regression , author=. The Journal of Machine Learning Research , volume=. 2021 , publisher=
2021
-
[18]
Journal of Machine Learning Research , volume=
Multi-source Learning via Completion of Block-wise Overlapping Noisy Matrices , author=. Journal of Machine Learning Research , volume=
-
[19]
Journal of the American Statistical Association , volume=
Exponential-family embedding with application to cell developmental trajectories for single-cell RNA-seq data , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[20]
Bioinformatics , volume=
Probabilistic count matrix factorization for single cell expression data analysis , author=. Bioinformatics , volume=. 2019 , publisher=
2019
-
[21]
Genome biology , volume=
ZIFA: Dimensionality reduction for zero-inflated single-cell gene expression analysis , author=. Genome biology , volume=. 2015 , publisher=
2015
-
[22]
Bioinformatics , volume=
Poisson factor models with applications to non-normalized microRNA profiling , author=. Bioinformatics , volume=. 2013 , publisher=
2013
-
[23]
Bernoulli , volume=
Detecting approximate replicate components of a high-dimensional random vector with latent structure , author=. Bernoulli , volume=. 2023 , publisher=
2023
-
[24]
Advances in neural information processing systems , volume=
Distance metric learning with application to clustering with side-information , author=. Advances in neural information processing systems , volume=
-
[25]
Foundations of Computational mathematics , volume=
Exact matrix completion via convex optimization , author=. Foundations of Computational mathematics , volume=. 2009 , publisher=
2009
-
[26]
The Annals of Statistics , volume=
Heteroskedastic PCA: Algorithm, optimality, and applications , author=. The Annals of Statistics , volume=. 2022 , publisher=
2022
-
[27]
Incoherence-Optimal Matrix Completion , year=
Chen, Yudong , journal=. Incoherence-Optimal Matrix Completion , year=
-
[28]
Journal of Multivariate Analysis , volume=
Estimation of the number of spikes, possibly equal, in the high-dimensional case , author=. Journal of Multivariate Analysis , volume=. 2014 , publisher=
2014
-
[29]
Entropic Optimal Transport Eigenmaps for Nonlinear Alignment and Joint Embedding of High-Dimensional Datasets , author=. arXiv preprint arXiv:2407.01718 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Journal of the American Statistical Association , number=
Kernel spectral joint embeddings for high-dimensional noisy datasets using duo-landmark integral operators , author=. Journal of the American Statistical Association , number=. 2025 , publisher=
2025
-
[31]
arXiv preprint arXiv:2507.22170 , year=
Stacked SVD or SVD stacked? A Random Matrix Theory perspective on data integration , author=. arXiv preprint arXiv:2507.22170 , year=
-
[32]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Robust angle-based transfer learning in high dimensions , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2025 , publisher=
2025
-
[33]
Journal of the American Statistical Association , volume=
Estimation of the number of spiked eigenvalues in a covariance matrix by bulk eigenvalue matching analysis , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
2023
-
[34]
The Annals of Statistics , pages=
Selecting the number of principal components: Estimation of the true rank of a noisy matrix , author=. The Annals of Statistics , pages=. 2017 , publisher=
2017
-
[35]
and Zhang, Anru , title =
Cai, Tony T. and Zhang, Anru , title =. The Annals of Statistics , number =. 2018 , volume =
2018
-
[36]
SIAM Journal on Matrix Analysis and Applications , volume=
On the singular values of matrices with displacement structure , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2017 , publisher=
2017
-
[37]
SIAM Journal on Mathematics of Data Science , volume=
Why are big data matrices approximately low rank? , author=. SIAM Journal on Mathematics of Data Science , volume=. 2019 , publisher=
2019
-
[38]
Computer Science and Scientific Computing/Academic Press, Inc , year=
Matrix Perturbation Theory , author=. Computer Science and Scientific Computing/Academic Press, Inc , year=
-
[39]
Numerische Mathematik , volume=
Convergence of the block Lanczos method for eigenvalue clusters , author=. Numerische Mathematik , volume=. 2015 , publisher=
2015
-
[40]
Numerical Algorithms , volume=
Computing the complete CS decomposition , author=. Numerical Algorithms , volume=. 2009 , publisher=
2009
-
[41]
Journal of Numerical Mathematics , volume=
Angles between subspaces and their tangents , author=. Journal of Numerical Mathematics , volume=. 2013 , publisher=
2013
-
[42]
Mathematics of computation , volume=
Numerical methods for computing angles between linear subspaces , author=. Mathematics of computation , volume=
-
[43]
The annals of applied statistics , volume=
Joint and individual variation explained (JIVE) for integrated analysis of multiple data types , author=. The annals of applied statistics , volume=. 2013 , publisher=
2013
-
[44]
Journal of multivariate analysis , volume=
Angle-based joint and individual variation explained , author=. Journal of multivariate analysis , volume=. 2018 , publisher=
2018
-
[45]
Journal of the American Statistical Association , volume=
D-CCA: A decomposition-based canonical correlation analysis for high-dimensional datasets , author=. Journal of the American Statistical Association , volume=. 2020 , publisher=
2020
-
[46]
Journal of machine learning research , volume=
Optimal structured principal subspace estimation: Metric entropy and minimax rates , author=. Journal of machine learning research , volume=
-
[47]
Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Flexible constrained spectral clustering , author=. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[48]
Proceedings of the ACM on Web Conference 2025 , pages=
Unveiling Discrete Clues: Superior Healthcare Predictions for Rare Diseases , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[49]
Proceedings of the 2013 SIAM International Conference on Data Mining , pages=
Constrained spectral clustering using l1 regularization , author=. Proceedings of the 2013 SIAM International Conference on Data Mining , pages=. 2013 , organization=
2013
-
[50]
International conference on machine learning , pages=
Guarantees for spectral clustering with fairness constraints , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[51]
arXiv preprint arXiv:2403.07431 , year=
Knowledge Transfer across Multiple Principal Component Analysis Studies , author=. arXiv preprint arXiv:2403.07431 , year=
-
[52]
Asian Conference on Machine Learning , pages=
Multitask principal component analysis , author=. Asian Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[53]
The Annals of Statistics , volume=
Minimax risk of matrix denoising by singular value thresholding , author=. The Annals of Statistics , volume=. 2014 , publisher=
2014
-
[54]
International Conference on Machine Learning , pages=
Inductive matrix completion: No bad local minima and a fast algorithm , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[55]
Journal of Machine Learning Research , volume=
Using side information to reliably learn low-rank matrices from missing and corrupted observations , author=. Journal of Machine Learning Research , volume=
-
[56]
Davis, Chandler and Kahan, W. M. , year =. The. SIAM Journal on Numerical Analysis , volume =
-
[57]
Linear algebra and its applications , volume=
A note on eigenvalues of perturbed Hermitian matrices , author=. Linear algebra and its applications , volume=. 2005 , publisher=
2005
-
[58]
Biometrika , volume=
A useful variant of the Davis--Kahan theorem for statisticians , author=. Biometrika , volume=. 2015 , publisher=
2015
-
[59]
Estimating Shared Subspace with
Yang, Yuepeng and Ma, Cong , year =. Estimating Shared Subspace with. 2501.09336 , primaryclass =
-
[60]
2013 , month = sep, journal =
Principal Components Estimation and Identification of Static Factors , author =. 2013 , month = sep, journal =
2013
-
[61]
Rudelson, Mark and Vershynin, Roman , year =. Hanson-. Electronic Communications in Probability , volume =
-
[62]
Journal of the American statistical association , volume=
Forecasting using principal components from a large number of predictors , author=. Journal of the American statistical association , volume=. 2002 , publisher=
2002
-
[63]
Linear algebra and its applications , volume=
Some inequalities for the eigenvalues of the product of positive semidefinite Hermitian matrices , author=. Linear algebra and its applications , volume=. 1992 , publisher=
1992
-
[64]
RGMIA research report collection , volume=
Further reverse results for Jensen's discrete inequality and applications in information theory , author=. RGMIA research report collection , volume=
-
[65]
Econometrica , volume=
Determining the number of factors in approximate factor models , author=. Econometrica , volume=. 2002 , publisher=
2002
-
[66]
Journal of Econometrics , volume=
Approximate factor models with weaker loadings , author=. Journal of Econometrics , volume=. 2023 , publisher=
2023
-
[67]
arXiv preprint arXiv:2407.03616 , year=
When can weak latent factors be statistically inferred? , author=. arXiv preprint arXiv:2407.03616 , year=
-
[68]
Clinical chemistry , volume=
LOINC, a universal standard for identifying laboratory observations: a 5-year update , author=. Clinical chemistry , volume=. 2003 , publisher=
2003
-
[69]
IT professional , volume=
RxNorm: prescription for electronic drug information exchange , author=. IT professional , volume=. 2005 , publisher=
2005
-
[70]
The Review of Economics and Statistics , volume=
Determining the number of factors from empirical distribution of eigenvalues , author=. The Review of Economics and Statistics , volume=. 2010 , publisher=
2010
-
[71]
Asymptotics of the principal components estimator of large factor models with weakly influential factors , journal =. 2012 , issn =. doi:https://doi.org/10.1016/j.jeconom.2012.01.034 , url =
-
[72]
Journal of computational and graphical statistics , volume=
Sparse principal component analysis , author=. Journal of computational and graphical statistics , volume=. 2006 , publisher=
2006
-
[73]
MedRxiv , author=
Knowledge-driven online multimodal automated phenotyping system. MedRxiv , author=. Published online , volume=
-
[74]
Nature Biomedical Engineering , volume=
Graph representation learning in biomedicine and healthcare , author=. Nature Biomedical Engineering , volume=. 2022 , publisher=
2022
-
[75]
NPJ digital medicine , volume=
Deep representation learning of electronic health records to unlock patient stratification at scale , author=. NPJ digital medicine , volume=. 2020 , publisher=
2020
-
[76]
Proceedings of the 12th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
Transformer-based unsupervised patient representation learning based on medical claims for risk stratification and analysis , author=. Proceedings of the 12th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
-
[77]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Unsupervised representation learning meets pseudo-label supervised self-distillation: A new approach to rare disease classification , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2021 , organization=
2021
-
[78]
Conference on Health, Inference, and Learning , pages=
Learning unsupervised representations for ICU timeseries , author=. Conference on Health, Inference, and Learning , pages=. 2022 , organization=
2022
-
[79]
medRxiv , pages=
Few shot learning for phenotype-driven diagnosis of patients with rare genetic diseases , author=. medRxiv , pages=. 2022 , publisher=
2022
-
[80]
Scientific Data , volume=
Building a knowledge graph to enable precision medicine , author=. Scientific Data , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.