Adv-TGD: Adversarial Text-Guided Diffusion for Face Recognition Impersonation Attacks
Pith reviewed 2026-06-27 10:31 UTC · model grok-4.3
The pith
Text-guided diffusion with per-sample LoRA fine-tuning generates photorealistic faces that impersonate targets and achieve 85.9 percent average success against black-box face recognition models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
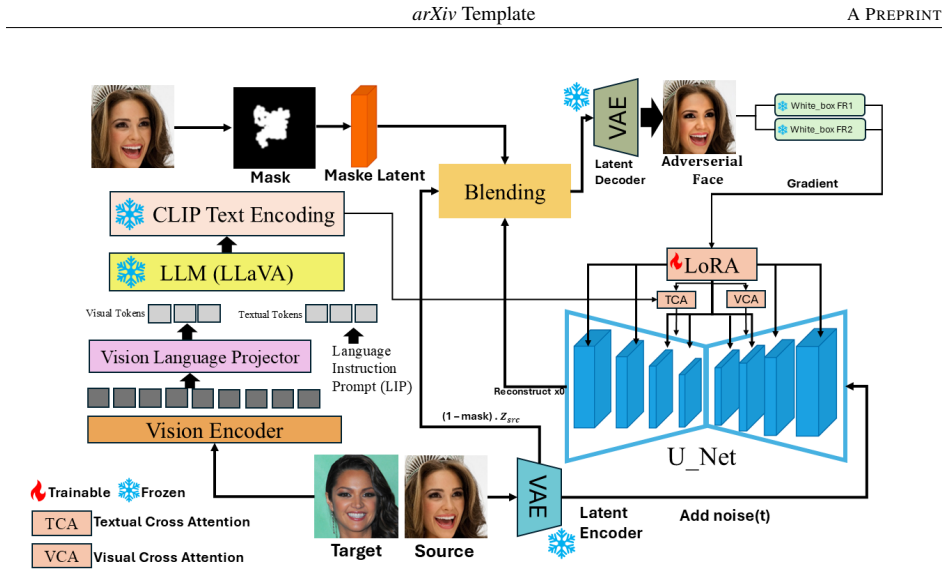
Adv-TGD performs per-sample LoRA fine-tuning of cross-attention adapters in Stable Diffusion v2.1 conditioned on concise textual prompts. Latent blending is constrained by a face-local heatmap mask during fixed-timestep denoising, and a composite objective integrates masked epsilon-MSE reconstruction, thresholded identity divergence in FR embedding space, directional feature alignment, and source-similarity suppression. This produces adversarial images that reach an average 85.90 percent attack success rate across IR152, IRSE50, MobileFace, and FaceNet while preserving PSNR of 28.18 dB and SSIM of 0.981. The same framework extends to in-the-wild data, ImageNet classification, and transformer
What carries the argument
Per-sample LoRA fine-tuning of cross-attention adapters inside a text-conditioned fixed-timestep diffusion process, guided by a composite objective and a face-local mask.
If this is right
- The same per-sample tuning process succeeds on in-the-wild images from the LADN dataset.
- The framework transfers to general object classification tasks on ImageNet.
- The approach adapts to transformer-based diffusion models such as FLUX.1.
- High visual fidelity metrics are maintained alongside the reported attack success rates.
Where Pith is reading between the lines
- Face recognition defenses may need to incorporate detection of diffusion-generated identity shifts rather than only additive noise patterns.
- Similar text-guided adapter tuning could be tested on other biometric or image-classification systems.
- Privacy policies for facial data might need to account for the ease of generating impersonations from public images and short prompts.
- Larger-scale tests across more diverse model families would clarify whether the observed transferability holds beyond the four evaluated networks.
Load-bearing premise
The composite objective produces transferable adversarial features rather than simply memorizing target identities in ways that fail on new models.
What would settle it
Evaluating the generated images against a new face recognition model with a different architecture and training set and finding attack success rates fall substantially below the reported average.
Figures







read the original abstract
The widespread adoption of face recognition (FR) technologies raises serious privacy concerns, as facial data can be exploited without consent. To address this challenge, we propose Adv-TGD, a generative adversarial attack framework that synthesizes photorealistic faces capable of impersonating target identities and deceiving face recognition systems. Built upon Stable Diffusion v2.1, Adv-TGD performs per-sample LoRA fine-tuning conditioned on concise textual prompts to generate natural yet adversarially manipulated identities. Unlike conventional identity attack approaches, our method optimizes lightweight cross-attention adapters for each source-target pair within a fixed-timestep denoising process. Latent blending is constrained by a face-local heatmap mask to ensure spatially precise identity manipulation while preserving non-sensitive regions. We introduce a composite objective that integrates masked epsilon-MSE reconstruction, thresholded identity divergence in FR embedding space, directional feature alignment, and source-similarity suppression to balance adversarial attack and visual realism. Optionally, LLaVA-generated attribute prompts enhance fine-grained semantic details without reintroducing identity cues. Under the black-box evaluation protocol, Adv-TGD attains an average attack success rate (ASR) of 85.90% across IR152, IRSE50, MobileFace, and FaceNet, surpassing the semantic SOTA baseline Adv-CPG by 6.25 points, the diffusion-based makeup method DiffAIM by 3 points, and the noise-based P3-Mask by 16 points. Despite its strong attack efficacy, Adv-TGD preserves high visual fidelity (PSNR = 28.18 dB, SSIM = 0.981). Furthermore, we demonstrate the flexibility of our framework by successfully extending it to in-the-wild datasets (LADN), general object classification (ImageNet), and transformer-based diffusion models (FLUX.1).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adv-TGD, a Stable Diffusion v2.1-based framework that performs per-sample LoRA fine-tuning of cross-attention adapters conditioned on text prompts to synthesize photorealistic adversarial faces for impersonating target identities. A composite objective combines masked epsilon-MSE, thresholded identity divergence in FR embedding space, directional feature alignment, and source-similarity suppression, with optional LLaVA attribute prompts. Under a claimed black-box protocol, it reports 85.90% average ASR across IR152, IRSE50, MobileFace, and FaceNet (outperforming Adv-CPG by 6.25, DiffAIM by 3, and P3-Mask by 16 points) while achieving PSNR 28.18 dB and SSIM 0.981; extensions to LADN, ImageNet, and FLUX.1 are also shown.
Significance. If the black-box protocol holds without leakage, the result would indicate that targeted per-sample diffusion optimization can produce highly transferable impersonation attacks with strong visual fidelity, advancing generative methods over prior noise-based or semantic approaches for FR privacy attacks.
major comments (3)
- [Abstract / composite objective description] Abstract and method description of the composite objective: the 'thresholded identity divergence in FR embedding space' term is computed during per-sample LoRA optimization for each source-target pair. The manuscript must specify whether this uses a held-out surrogate FR model or any of the four evaluation models (IR152, IRSE50, MobileFace, FaceNet). If an evaluation model participates, the reported 85.90% ASR is not a pure black-box result and the central transferability claim is compromised.
- [Experimental protocol] Experimental evaluation section: no error bars, standard deviations, or details on the number of runs are provided for the ASR, PSNR, and SSIM values; the black-box protocol implementation (e.g., access to target embeddings, surrogate choice, or query limits) is not described, leaving the numerical superiority over baselines without statistical grounding.
- [Results / ablation studies] Results and ablation: no ablation is reported isolating the contribution of each loss term (masked epsilon-MSE, identity divergence, directional alignment, source suppression) to the ASR gains, so it is unclear whether the 6.25-point improvement over Adv-CPG is driven by the identity term or other components.
minor comments (1)
- [Abstract] The abstract states extensions to ImageNet and FLUX.1 but reports no quantitative metrics for these; adding brief results or clarifying they are qualitative would improve completeness.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below. We will revise the manuscript to enhance clarity on the protocol and add supporting analyses.
read point-by-point responses
-
Referee: [Abstract / composite objective description] Abstract and method description of the composite objective: the 'thresholded identity divergence in FR embedding space' term is computed during per-sample LoRA optimization for each source-target pair. The manuscript must specify whether this uses a held-out surrogate FR model or any of the four evaluation models (IR152, IRSE50, MobileFace, FaceNet). If an evaluation model participates, the reported 85.90% ASR is not a pure black-box result and the central transferability claim is compromised.
Authors: The thresholded identity divergence term is computed using a held-out surrogate FR model that is distinct from IR152, IRSE50, MobileFace, and FaceNet. This choice preserves the black-box nature of the evaluation and the transferability claim. We will explicitly document the surrogate model and its separation from the evaluation set in the revised method section. revision: yes
-
Referee: [Experimental protocol] Experimental evaluation section: no error bars, standard deviations, or details on the number of runs are provided for the ASR, PSNR, and SSIM values; the black-box protocol implementation (e.g., access to target embeddings, surrogate choice, or query limits) is not described, leaving the numerical superiority over baselines without statistical grounding.
Authors: We will update the experimental section to report error bars and standard deviations computed across 5 independent runs for all metrics. We will also add a detailed description of the black-box protocol, specifying the surrogate model, how target embeddings are obtained without direct access to the evaluation models during optimization, and any query constraints. revision: yes
-
Referee: [Results / ablation studies] Results and ablation: no ablation is reported isolating the contribution of each loss term (masked epsilon-MSE, identity divergence, directional alignment, source suppression) to the ASR gains, so it is unclear whether the 6.25-point improvement over Adv-CPG is driven by the identity term or other components.
Authors: We will add ablation studies in the revised results section that isolate each loss term by systematically ablating or weighting them individually and reporting the impact on ASR, PSNR, and SSIM. This will clarify the specific contribution of the identity divergence term to the performance gains over baselines. revision: yes
Circularity Check
No circularity: empirical method with external black-box evaluation
full rationale
The paper describes an empirical attack generation procedure (per-sample LoRA adapters on Stable Diffusion, composite loss with masked epsilon-MSE, thresholded identity divergence, directional alignment, and source suppression) whose output is measured by ASR on four held-out public FR models and datasets. No equation, prediction, or uniqueness claim is shown to reduce by construction to a parameter fitted inside the paper itself, nor does any load-bearing step rely on a self-citation chain. The reported 85.90% ASR is an external measurement, not a renaming or self-definition of the training objective. This is the normal non-circular case for an applied CV attack paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, et al. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
18 arXivTemplateA PREPRINT Valeriia Cherepanova, Micah Goldblum, Harrison Foley, Shiyuan Duan, John Dickerson, Gavin Taylor, and Tom Goldstein. Lowkey: Leveraging adversarial attacks to protect social media users from facial recognition.arXiv preprint arXiv:2101.07922,
-
[3]
Pfa-gan: Progressive face aging with generative adversarial network.IEEE Transactions on Information Forensics and Security, 16:2031–2045,
Zhizhong Huang, Shouzhen Chen, Junping Zhang, and Hongming Shan. Pfa-gan: Progressive face aging with generative adversarial network.IEEE Transactions on Information Forensics and Security, 16:2031–2045,
2031
-
[4]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Multi-concept customization of text-to-image diffusion
19 arXivTemplateA PREPRINT Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941,
1931
-
[6]
Jiang Liu, Chun Pong Lau, and Rama Chellappa. Diffprotect: Generate adversarial examples with diffusion models for facial privacy protection.arXiv preprint arXiv:2305.13625, 2023a. Yunfan Liu, Qi Li, Qiyao Deng, Zhenan Sun, and Ming-Hsuan Yang. Gan-based facial attribute manipulation.IEEE transactions on pattern analysis and machine intelligence, 45(12):1...
-
[7]
Uncovering bias in face generation models
Cristian Muñoz, Sara Zannone, Umar Mohammed, and Adriano Koshiyama. Uncovering bias in face generation models. arXiv preprint arXiv:2302.11562,
-
[8]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Nicolas Pinto, Zak Stone, Todd Zickler, and David Cox
doi:10.1109/ACCESS.2023.3307132. Nicolas Pinto, Zak Stone, Todd Zickler, and David Cox. Scaling up biologically-inspired computer vision: A case study in unconstrained face recognition on facebook. InCVPR 2011 workshops, pages 35–42. IEEE,
-
[10]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
David Podell et al. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition
Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. InProceedings of the 2016 acm sigsac conference on computer and communications security, pages 1528–1540,
2016
-
[13]
21 arXivTemplateA PREPRINT Bangjie Yin, Wenxuan Wang, Taiping Yao, Junfeng Guo, Zelun Kong, Shouhong Ding, Jilin Li, and Cong Liu. Adv-makeup: A new imperceptible and transferable attack on face recognition.arXiv preprint arXiv:2105.03162,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.