Benchmarking Neural Speech Compression from a Rate-Distortion Perspective
Pith reviewed 2026-06-27 08:42 UTC · model grok-4.3
The pith
Entropy-constrained coding with hyperprior and context modeling improves low-bitrate speech compression rate-distortion trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
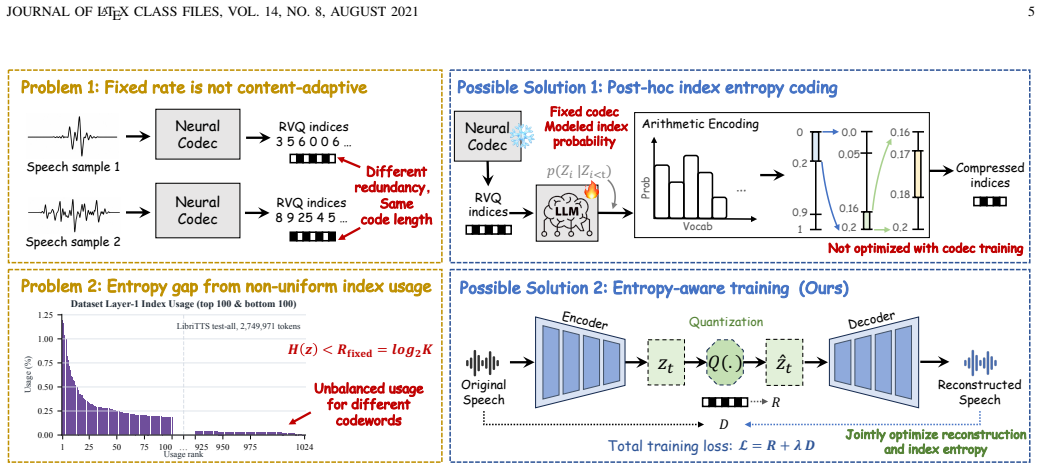
ECC is an Entropy-Constrained Codec that combines scalar quantization with a learned entropy model. ECC integrates hyperprior-based side information, channel-wise context modeling, latent residual prediction, and lightweight temporal modeling to estimate latent likelihoods for rate estimation during training and arithmetic coding during inference. To further improve low-bitrate efficiency, ECC introduces entropy skip, which omits highly predictable residual symbols using decoder-available scale estimates without transmitting additional skip masks. Extensive experiments show that ECC achieves a favorable low-bitrate rate-distortion trade-off over conventional and neural codec baselines.
What carries the argument
Learned entropy model that supplies probability estimates of quantized latents for both rate-distortion optimization during training and arithmetic coding at inference.
If this is right
- Explicit integration of probability modeling during representation learning exploits non-uniform usage and temporal dependencies in speech latents.
- Entropy skip reduces transmitted symbols for highly predictable residuals without extra side information.
- Ablation studies isolate the contribution of hyperprior, context modeling, residual prediction, and temporal modeling to the rate-distortion curve.
- The unified pipeline enables consistent comparison of future neural speech codecs on rate-distortion terms.
Where Pith is reading between the lines
- The same entropy-modeling structure could be tested on neural codecs for other signals such as audio or video to check for similar gains.
- If the gains persist when training data and optimizers are strictly matched, it indicates that prior separation of representation learning from probability modeling was a systematic bottleneck.
- The entropy-skip mechanism might be adapted to other variable-rate coding settings where decoder-side statistics are already available.
Load-bearing premise
The reported BD-rate gains are driven by the entropy-modeling components rather than by differences in training data, optimizer settings, or unstated implementation choices.
What would settle it
Re-implementing the baseline neural codecs with identical training data and the same hyperprior, context, residual-prediction, and temporal-modeling entropy components added would show whether the BD-rate gap remains.
Figures











read the original abstract
Learning-based speech compression has achieved promising low-bitrate performance, but many neural speech codecs still describe quantized latents with preset-rate discrete symbols or apply entropy coding only after symbol generation. Such designs decouple representation learning from probability modeling, limiting their ability to exploit the non-uniform usage and temporal dependencies of learned speech latents. In this paper, we benchmark neural speech compression from a rate--distortion perspective and further investigate entropy-constrained coding for low-bitrate speech compression. We first formulate a unified learning-based speech coding pipeline and provide a benchmark-style analysis of recent neural speech codecs, showing that explicit probability modeling remains underexplored in learned speech compression. We then propose ECC, an Entropy-Constrained Codec that combines scalar quantization with a learned entropy model. ECC integrates hyperprior-based side information, channel-wise context modeling, latent residual prediction, and lightweight temporal modeling to estimate latent likelihoods for rate estimation during training and arithmetic coding during inference. To further improve low-bitrate efficiency, ECC introduces entropy skip, which omits highly predictable residual symbols using decoder-available scale estimates without transmitting additional skip masks. Extensive experiments show that ECC achieves a favorable low-bitrate rate--distortion trade-off over conventional and neural codec baselines, reducing BD-rate by 39.9% on ViSQOL and 76.3% on PESQ on average over two widely-used test sets. Ablation and diagnostic studies further validate the effectiveness of entropy modeling. Project Page: https://avery-xu.github.io/ECC-demo/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
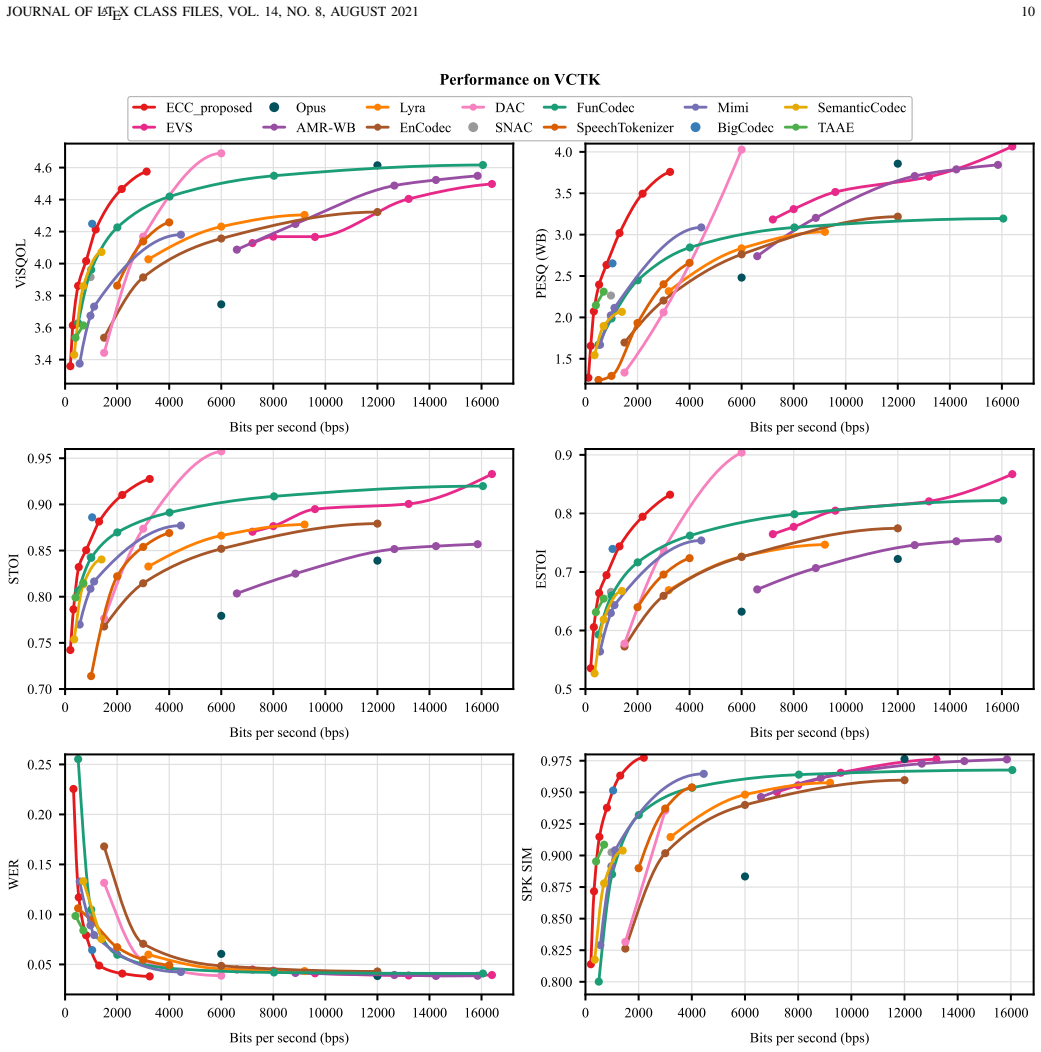
Summary. The paper formulates a unified learning-based speech coding pipeline, benchmarks recent neural speech codecs from a rate-distortion perspective, and proposes ECC, an Entropy-Constrained Codec that integrates scalar quantization with a learned entropy model using hyperprior side information, channel-wise context, latent residual prediction, lightweight temporal modeling, and an entropy skip mechanism. It reports that ECC achieves a favorable low-bitrate trade-off, with average BD-rate reductions of 39.9% on ViSQOL and 76.3% on PESQ over two widely-used test sets relative to conventional and neural baselines, supported by ablation studies validating the entropy-modeling components.
Significance. If the BD-rate gains can be attributed to the entropy-modeling elements rather than training or implementation differences, the work would be significant for highlighting the underexplored role of explicit probability modeling in neural speech compression and for providing a benchmark-style analysis that encourages joint optimization of representation and rate estimation. The ablation studies add value by isolating component contributions.
major comments (2)
- [Experimental Results / Ablation Studies] The central claim of 39.9% / 76.3% BD-rate reduction (Abstract) requires that performance differences arise from the entropy components (hyperprior, channel-wise context, residual prediction, temporal modeling, entropy skip) rather than mismatched training. The manuscript does not state whether all baselines were re-trained from scratch under identical data, batching, optimizer schedules, and loss weighting; this is load-bearing for attributing gains to the proposed design.
- [Experimental Results] No error bars, confidence intervals, or statistical tests are reported for the BD-rate numbers (Abstract), and dataset details (specific test sets, sizes, preprocessing) are omitted. This undermines the ability to assess the reliability and reproducibility of the quantitative claims.
minor comments (2)
- The abstract refers to "two widely-used test sets" without naming them or providing references; this should be clarified for readers.
- Notation for the entropy model components (e.g., how scale estimates are used in entropy skip) could be made more explicit in the method description to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor and reproducibility that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experimental Results / Ablation Studies] The central claim of 39.9% / 76.3% BD-rate reduction (Abstract) requires that performance differences arise from the entropy components (hyperprior, channel-wise context, residual prediction, temporal modeling, entropy skip) rather than mismatched training. The manuscript does not state whether all baselines were re-trained from scratch under identical data, batching, optimizer schedules, and loss weighting; this is load-bearing for attributing gains to the proposed design.
Authors: We agree that explicit confirmation of training parity is necessary to attribute gains specifically to the entropy-modeling components. The manuscript currently does not detail this. In the revised version we will add a dedicated subsection under Experiments that states: (i) all neural baselines were re-implemented and trained from scratch using the identical training corpus, batch size, optimizer schedule, and loss weighting as ECC; (ii) conventional codecs (Opus, EVS) were evaluated with their standard implementations at matching bitrates; and (iii) any published checkpoints used for reference are clearly identified as such. This clarification will allow readers to evaluate whether the reported BD-rate savings stem from the entropy-modeling innovations. revision: yes
-
Referee: [Experimental Results] No error bars, confidence intervals, or statistical tests are reported for the BD-rate numbers (Abstract), and dataset details (specific test sets, sizes, preprocessing) are omitted. This undermines the ability to assess the reliability and reproducibility of the quantitative claims.
Authors: We acknowledge the omission. In the revision we will expand the Experiments section to include: (i) exact identities and sizes of the two test sets, (ii) preprocessing pipeline (resampling, normalization, segmentation), and (iii) per-metric standard deviations across utterances together with 95% confidence intervals on the BD-rate figures computed via bootstrap resampling. We will also report the number of utterances used for each metric. These additions will directly address reproducibility concerns while preserving the main quantitative claims. revision: yes
Circularity Check
Empirical benchmarking results contain no circular derivation steps
full rationale
The paper reports BD-rate reductions measured on held-out test sets after training ECC and comparing against baselines. These are direct empirical measurements rather than quantities derived from equations that reduce to fitted parameters or self-citations by construction. Ablation studies are likewise empirical validations of components. No load-bearing step matches any of the enumerated circularity patterns; the performance claims remain independent of the model's internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Non-Terrestrial Networks (NTN),
3GPP, “Non-Terrestrial Networks (NTN),” https://www.3gpp.org/ technologies/ntn-overview, 2024, accessed: 2026-06-09
2024
-
[2]
Study on Ultra Low Bit Rate Speech Codecs,
——, “Study on Ultra Low Bit Rate Speech Codecs,” 3rd Generation Partnership Project (3GPP), Technical Report TR 26.940, 2025, release 20, draft specification
2025
-
[3]
Mp3 and aac explained,
K. Brandenburg, “Mp3 and aac explained,” inAudio Engineering Society Conference: 17th International Conference: High-Quality Audio Coding. Audio Engineering Society, 1999
1999
-
[4]
Definition of the opus audio codec,
J.-M. Valin, K. V os, and T. Terriberry, “Definition of the opus audio codec,” Tech. Rep., 2012
2012
-
[5]
Overview of the evs codec architecture,
M. Dietz, M. Multrus, V . Eksler, V . Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilacheet al., “Overview of the evs codec architecture,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5698–5702
2015
-
[6]
The adaptive multirate wide- band speech codec (amr-wb),
B. Bessette, R. Salami, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola, and K. Jarvinen, “The adaptive multirate wide- band speech codec (amr-wb),”IEEE transactions on speech and audio processing, vol. 10, no. 8, pp. 620–636, 2003
2003
-
[7]
Theoretical foundations of transform coding,
V . Goyal, “Theoretical foundations of transform coding,”IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 9–21, 2001
2001
-
[8]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021
2021
-
[9]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023
2023
-
[10]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,” inProceedings of the 37th International Conference on Neural Information Processing Systems, 2023, pp. 27 980–27 993
2023
-
[11]
Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec,
Z. Du, S. Zhang, K. Hu, and S. Zheng, “Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 591–595
2024
-
[12]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[13]
Libritts: A corpus derived from librispeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” arXiv preprint arXiv:1904.02882, 2019
Pith/arXiv arXiv 1904
-
[14]
Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92),” The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web. ku. edu/˜ idea/readings/rainbow. htm)., 2019
2019
-
[15]
Rate-aware learned speech compression,
J. Xu, Z. Cheng, G. Chi, Y . Liu, Y . Hu, and L. Song, “Rate-aware learned speech compression,” in2025 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2025, pp. 1–5
2025
-
[16]
Hifi-codec: Group-residual vector quantization for high fidelity audio codec,
D. Yang, S. Liu, R. Huang, J. Tian, C. Weng, and Y . Zou, “Hifi-codec: Group-residual vector quantization for high fidelity audio codec,”arXiv preprint arXiv:2305.02765, 2023
arXiv 2023
-
[17]
Audiodec: An open-source streaming high-fidelity neural audio codec,
Y .-C. Wu, I. D. G. Chen, G. Guo, H. Zhang, E. Cheung, P. Smaragdis, and Y . Wang, “Audiodec: An open-source streaming high-fidelity neural audio codec,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[18]
Esc: Efficient speech coding with cross-scale resid- ual vector quantized transformers,
Y . Gu and E. Diao, “Esc: Efficient speech coding with cross-scale resid- ual vector quantized transformers,”arXiv preprint arXiv:2404.19441, 2024
arXiv 2024
-
[19]
V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,” inInternational Conference on Learning Representations, 2024
2024
-
[20]
Ndvq: Robust neural audio codec with normal distribution-based vector quantization,
Z. Niu, S. Chen, L. Zhou, Z. Ma, X. Chen, and S. Liu, “Ndvq: Robust neural audio codec with normal distribution-based vector quantization,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 705–710
2024
-
[21]
Snac: Multi-scale neural audio codec,
H. Siuzdak, F. Gr ¨otschla, and L. A. Lanzend ¨orfer, “Snac: Multi-scale neural audio codec,” inNeurIPS 2024 Workshop on AI-Driven Speech, Music, and Sound Generation, 2024
2024
-
[22]
Speechtokenizer: Uni- fied speech tokenizer for speech large language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Uni- fied speech tokenizer for speech large language models,” inInternational Conference on Learning Representations, 2024
2024
-
[23]
Apcodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding,
Y . Ai, X.-H. Jiang, Y .-X. Lu, H.-P. Du, and Z.-H. Ling, “Apcodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3256–3269, 2024
2024
-
[24]
Mdctcodec: A lightweight mdct-based neural audio codec towards high JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 sampling rate and low bitrate scenarios,
X.-H. Jiang, Y . Ai, R.-C. Zheng, H.-P. Du, Y .-X. Lu, and Z.-H. Ling, “Mdctcodec: A lightweight mdct-based neural audio codec towards high JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 sampling rate and low bitrate scenarios,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 540–547
2021
-
[25]
Bigcodec: Push- ing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “Bigcodec: Push- ing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
arXiv 2024
-
[26]
Spectral codecs: Spectrogram-based audio codecs for high quality speech synthesis,
R. Langman, A. Juki ´c, K. Dhawan, N. R. Koluguri, and B. Ginsburg, “Spectral codecs: Spectrogram-based audio codecs for high quality speech synthesis,”arXiv preprint arXiv:2406.05298, 2024
arXiv 2024
-
[27]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumbley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Processing, 2024
2024
-
[28]
Simplespeech 2: Towards simple and efficient text-to- speech with flow-based scalar latent transformer diffusion models,
D. Yang, R. Huang, Y . Wang, H. Guo, D. Chong, S. Liu, X. Wu, and H. Meng, “Simplespeech 2: Towards simple and efficient text-to- speech with flow-based scalar latent transformer diffusion models,”IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[29]
A streamable neural audio codec with residual scalar-vector quantization for real-time communication,
X.-H. Jiang, Y . Ai, R.-C. Zheng, and Z.-H. Ling, “A streamable neural audio codec with residual scalar-vector quantization for real-time communication,”IEEE Signal Processing Letters, pp. 1–5, 2025
2025
-
[30]
Scaling transformers for low-bitrate high-quality speech coding,
J. D. Parker, A. Smirnov, J. Pons, C. Carr, Z. Zukowski, Z. Evans, and X. Liu, “Scaling transformers for low-bitrate high-quality speech coding,” inInternational Conference on Learning Representations, 2025
2025
-
[31]
Ts3-codec: Transformer- based simple streaming single codec,
H. Wu, N. Kanda, S. E. Eskimez, and J. Li, “Ts3-codec: Transformer- based simple streaming single codec,” inInterspeech 2025, 2025, pp. 604–608
2025
-
[32]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” inInternational Conference on Learning Representations, 2025
2025
-
[33]
Focalcodec: Low-bitrate speech coding via focal modulation networks,
L. Della Libera, F. Paissan, C. Subakan, and M. Ravanelli, “Focalcodec: Low-bitrate speech coding via focal modulation networks,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[34]
Spectokenizer: A lightweight streaming codec in the compressed spectrum domain,
Z. Wan, G. Zhang, Y . He, and J. Wei, “Spectokenizer: A lightweight streaming codec in the compressed spectrum domain,” inInterspeech 2025, 2025, pp. 599–603
2025
-
[35]
Finite scalar quantization: Vq-vae made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Finite scalar quantization: Vq-vae made simple,”arXiv preprint arXiv:2309.15505, 2023
Pith/arXiv arXiv 2023
-
[36]
End-to-end optimized image compression,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,”arXiv preprint arXiv:1611.01704, 2016
arXiv 2016
-
[37]
Learning content-weighted deep image compression,
M. Li, W. Zuo, S. Gu, J. You, and D. Zhang, “Learning content-weighted deep image compression,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 10, pp. 3446–3461, 2020
2020
-
[38]
Conditional probability models for deep image compression,
F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. Van Gool, “Conditional probability models for deep image compression,” inPro- ceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4394–4402
2018
-
[39]
Vari- ational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Vari- ational image compression with a scale hyperprior,”arXiv preprint arXiv:1802.01436, 2018
Pith/arXiv arXiv 2018
-
[40]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[41]
Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7939–7948
2020
-
[42]
Overview of the versatile video coding (vvc) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[43]
T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications,”arXiv preprint arXiv:1701.05517, 2017
Pith/arXiv arXiv 2017
-
[44]
Checkerboard context model for efficient learned image compression,
D. He, Y . Zheng, B. Sun, Y . Wang, and H. Qin, “Checkerboard context model for efficient learned image compression,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 771–14 780
2021
-
[45]
Channel-wise autoregressive entropy models for learned image compression,
D. Minnen and S. Singh, “Channel-wise autoregressive entropy models for learned image compression,” in2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2020, pp. 3339–3343
2020
-
[46]
Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5718– 5727
2022
-
[47]
M2t: Masking trans- formers twice for faster decoding,
F. Mentzer, E. Agustson, and M. Tschannen, “M2t: Masking trans- formers twice for faster decoding,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5340–5349
2023
-
[48]
Maskgit: Masked generative image transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “Maskgit: Masked generative image transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 315–11 325
2022
-
[49]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[50]
Entroformer: A transformer-based entropy model for learned image compression,
Y . Qian, M. Lin, X. Sun, Z. Tan, and R. Jin, “Entroformer: A transformer-based entropy model for learned image compression,”arXiv preprint arXiv:2202.05492, 2022
arXiv 2022
-
[51]
Contextformer: A transformer with spatio-channel attention for context modeling in learned image compression,
A. B. Koyuncu, H. Gao, A. Boev, G. Gaikov, E. Alshina, and E. Stein- bach, “Contextformer: A transformer with spatio-channel attention for context modeling in learned image compression,” inEuropean confer- ence on computer vision. Springer, 2022, pp. 447–463
2022
-
[52]
Mlic++: Linear com- plexity multi-reference entropy modeling for learned image compres- sion,
W. Jiang, J. Yang, Y . Zhai, F. Gao, and R. Wang, “Mlic++: Linear com- plexity multi-reference entropy modeling for learned image compres- sion,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 21, no. 5, pp. 1–25, 2025
2025
-
[53]
Groupedmixer: An entropy model with group-wise token-mixers for learned image compression,
D. Li, Y . Bai, K. Wang, J. Jiang, X. Liu, and W. Gao, “Groupedmixer: An entropy model with group-wise token-mixers for learned image compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9606–9619, 2024
2024
-
[54]
Learning end-to-end lossy image compression: A benchmark,
Y . Hu, W. Yang, Z. Ma, and J. Liu, “Learning end-to-end lossy image compression: A benchmark,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4194–4211, 2021
2021
-
[55]
Qarv: Quantization-aware resnet vae for lossy image compression,
Z. Duan, M. Lu, J. Ma, Y . Huang, Z. Ma, and F. Zhu, “Qarv: Quantization-aware resnet vae for lossy image compression,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 436–450, 2023
2023
-
[56]
Learned image compression with dictionary-based entropy model,
J. Lu, L. Zhang, X. Zhou, M. Li, W. Li, and S. Gu, “Learned image compression with dictionary-based entropy model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 850–12 859
2025
-
[57]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[58]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
2021
-
[59]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[60]
On gener- ative spoken language modeling from raw audio,
K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y . Adi, A. Polyak, B. Bolte, T.-A. Nguyen, J. Copet, A. Baevski, A. Mohamedet al., “On gener- ative spoken language modeling from raw audio,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 1336–1354, 2021
2021
-
[61]
How should we extract discrete audio tokens from self-supervised models?
P. Mousavi, J. Duret, S. Zaiem, L. Della Libera, A. Ploujnikov, C. Sub- akan, and M. Ravanelli, “How should we extract discrete audio tokens from self-supervised models?” 2024
2024
-
[62]
Source-aware neural speech coding for noisy speech compression,
H. Yang, K. Zhen, S. Beack, and M. Kim, “Source-aware neural speech coding for noisy speech compression,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 706–710
2021
-
[63]
Disentangling speech from surroundings with neu- ral embeddings,
A. Omran, N. Zeghidour, Z. Borsos, F. de Chaumont Quitry, M. Slaney, and M. Tagliasacchi, “Disentangling speech from surroundings with neu- ral embeddings,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[64]
Speech resynthesis from discrete disen- tangled self-supervised representations,
A. Polyak, Y . Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech resynthesis from discrete disen- tangled self-supervised representations,” 2021
2021
-
[65]
Disentangled feature learn- ing for real-time neural speech coding,
X. Jiang, X. Peng, Y . Zhang, and Y . Lu, “Disentangled feature learn- ing for real-time neural speech coding,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[66]
Fewer- token neural speech codec with time-invariant codes,
Y . Ren, T. Wang, J. Yi, L. Xu, J. Tao, C. Y . Zhang, and J. Zhou, “Fewer- token neural speech codec with time-invariant codes,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 737–12 741. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 16
2024
-
[67]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” 2024
2024
-
[68]
Lscodec: Low- bitrate and speaker-decoupled discrete speech codec,
Y . Guo, Z. Li, C. Du, H. Wang, X. Chen, and K. Yu, “Lscodec: Low- bitrate and speaker-decoupled discrete speech codec,” 2024
2024
-
[69]
Socodec: A semantic-ordered multi-stream speech codec for efficient language model based text-to-speech synthesis,
H. Guo, F. Xie, K. Xie, D. Yang, D. Guo, X. Wu, and H. Meng, “Socodec: A semantic-ordered multi-stream speech codec for efficient language model based text-to-speech synthesis,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 645–651
2024
-
[70]
Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,” 2020
2020
-
[71]
Learning source disentanglement in neural audio codec,
X. Bie, X. Liu, and G. Richard, “Learning source disentanglement in neural audio codec,” pp. 1–5, 2025
2025
-
[72]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liuet al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 697–25 705
2025
-
[73]
Uniaudio 1.5: Large language model-driven audio codec is a few-shot audio task learner,
D. Yang, H. Guo, Y . Wang, R. Huang, X. Li, X. Tan, X. Wu, and H. Meng, “Uniaudio 1.5: Large language model-driven audio codec is a few-shot audio task learner,” vol. 37, 2024, pp. 56 802–56 827
2024
-
[74]
Llama 2: open foundation and fine-tuned chat models. arxiv,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: open foundation and fine-tuned chat models. arxiv,”arXiv preprint arXiv:2307.09288, vol. 10, 2023
Pith/arXiv arXiv 2023
-
[75]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Maet al., “Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
Pith/arXiv arXiv 2024
-
[76]
Cosyvoice 2: Scalable streaming speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[77]
Past: Phonetic-acoustic speech tok- enizer,
N. Har-Tuv, O. Tal, and Y . Adi, “Past: Phonetic-acoustic speech tok- enizer,”arXiv preprint arXiv:2505.14470, 2025
arXiv 2025
-
[78]
Improving and generalizing flow-based generative models with minibatch optimal transport,
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio, “Improving and generalizing flow-based generative models with minibatch optimal transport,”arXiv preprint arXiv:2302.00482, 2023
Pith/arXiv arXiv 2023
-
[79]
Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot,
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot,”arXiv preprint arXiv:2412.02612, 2024
Pith/arXiv arXiv 2024
-
[80]
Seanet: A multi- modal speech enhancement network,
M. Tagliasacchi, Y . Li, K. Misiunas, and D. Roblek, “Seanet: A multi- modal speech enhancement network,”arXiv preprint arXiv:2009.02095, 2020
arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.