Dummy Backdoor as a Defense: Removing Unknown Backdoors via Shared Internal Mechanisms for Generative LLMs
Pith reviewed 2026-06-27 09:31 UTC · model grok-4.3
The pith
Embedding a known dummy backdoor and then removing it through fine-tuning also weakens unknown backdoors in generative LLMs because they share similar internal activation changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
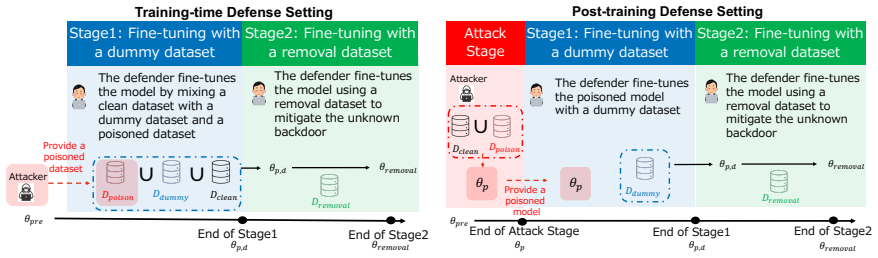
Different backdoors with the same task induce similar trigger-activated changes in the internal activations; therefore intentionally embedding a dummy backdoor and removing it via further fine-tuning on dummy-triggered inputs with clean responses also reduces the effect of an unknown backdoor that shares those mechanisms.
What carries the argument
The dummy backdoor, a defender-inserted backdoor with a known trigger that serves as a proxy whose removal also disrupts unknown backdoors through shared activation patterns.
If this is right
- The method reduces attack success rate of unknown backdoors across three attack types and multiple model families.
- Model utility on clean inputs is preserved at levels competitive with or better than prior defense methods.
- No knowledge of the original backdoor trigger or attack type is required for the defense to work.
- The approach applies to generative LLMs without needing access to internal model weights beyond standard fine-tuning.
Where Pith is reading between the lines
- A defender could insert multiple dummy backdoors targeting different possible attack objectives to broaden coverage.
- The shared-mechanism observation might extend to backdoor-like behaviors in other domains such as vision or reinforcement learning models.
- If activation overlap proves consistent, future defenses could monitor or regularize those shared patterns directly instead of using explicit dummy insertion.
Load-bearing premise
Different backdoors with the same attack objective induce similar trigger-activated changes in the internal activations.
What would settle it
An experiment in which an unknown backdoor achieves high attack success yet produces activation patterns that remain completely distinct from those of the dummy backdoor even after the dummy-removal fine-tuning step.
Figures

read the original abstract
Backdoor attacks pose a serious threat to the safety and reliability of Large Language Models (LLMs), as they cause models to behave normally on clean inputs while producing attacker-specified responses when hidden triggers are present. Removing such unknown backdoors is particularly challenging when the defender does not know the backdoor attack types or the internal mechanisms formed through backdoor training. In this work, we propose a simple but effective backdoor removal method based on shared internal mechanisms across different backdoors. First, we show that different backdoors with the same task (attack objective) induce similar trigger-activated changes in the internal activations. Motivated by this observation, our method intentionally embeds a backdoor with a known trigger (\emph{dummy backdoor}) and then removes it through further fine-tuning on dummy-triggered inputs paired with clean responses. Since the dummy backdoor and the unknown backdoor can rely on shared internal mechanisms, removing the dummy backdoor also reduces the effect of the unknown backdoor. We evaluate our method on three backdoor attack types across multiple model families. Experimental results show that our method substantially reduces the attack success rate of the unknown backdoor while preserving model utility, outperforming representative existing defense methods in both backdoor removal effectiveness and utility preservation. These findings suggest that a defender-controllable backdoor can serve as a helpful proxy for mitigating unknown backdoors in generative LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that different backdoors sharing the same attack objective induce similar trigger-activated changes in internal activations of generative LLMs. Motivated by this, the authors embed a defender-controlled 'dummy backdoor' with a known trigger and matching objective, then remove it via fine-tuning on dummy-triggered inputs paired with clean responses; because the dummy and unknown backdoors share mechanisms, the removal step also mitigates the unknown backdoor. Experiments on three attack types across multiple model families report substantially lower attack success rates while preserving utility and outperforming baselines.
Significance. If the shared-mechanism observation and the method's applicability hold, the work would introduce a new defense paradigm that uses a controllable proxy backdoor to address unknown attacks without requiring knowledge of their internal mechanisms. The multi-attack, multi-model evaluation provides concrete empirical grounding for the core observation in controlled settings and demonstrates practical utility preservation, which are strengths.
major comments (1)
- [Abstract] Abstract: the defense is conditioned on embedding a dummy backdoor whose attack objective matches that of the unknown backdoor, yet the defender has no knowledge of the unknown objective and the manuscript provides no procedure for selecting or adapting the dummy task. This assumption is load-bearing for the claim of defending against truly unknown backdoors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the core assumption of our defense. We agree that matching the attack objective is load-bearing and that the manuscript lacks guidance on selecting the dummy task for truly unknown objectives. We will revise the paper to clarify this scope and discuss practical implications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the defense is conditioned on embedding a dummy backdoor whose attack objective matches that of the unknown backdoor, yet the defender has no knowledge of the unknown objective and the manuscript provides no procedure for selecting or adapting the dummy task. This assumption is load-bearing for the claim of defending against truly unknown backdoors.
Authors: We agree with this observation. The method relies on the dummy backdoor sharing the same attack objective to exploit shared internal mechanisms, as established in our preliminary experiments. The manuscript demonstrates effectiveness when this matching is possible (e.g., common objectives such as targeted output generation or refusal), but does not include a procedure for inferring unknown objectives or adapting the dummy task. This limits applicability to completely blind scenarios. In revision, we will (1) update the abstract to explicitly state the matching-objective requirement, (2) add a limitations subsection discussing this assumption, and (3) outline potential extensions such as testing a small set of representative dummy objectives in parallel. These changes will make the claims precise without overstating generality. revision: yes
Circularity Check
No circularity: empirical observation and defense method are self-contained
full rationale
The paper's central claim rests on an empirical observation (different backdoors with the same attack objective induce similar internal activation changes) followed by a practical method of embedding and removing a dummy backdoor. This chain does not reduce to a self-definition, fitted parameter renamed as prediction, or self-citation load-bearing premise; the similarity is presented as an experimental finding, and the defense is evaluated on multiple attack types without invoking uniqueness theorems or ansatzes from prior author work. The method's applicability to unknown objectives is a separate correctness concern, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different backdoors with the same task (attack objective) induce similar trigger-activated changes in the internal activations.
invented entities (1)
-
dummy backdoor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Access , volume=
Badnets: Evaluating backdooring attacks on deep neural networks , author=. IEEE Access , volume=. 2019 , publisher=
2019
-
[2]
arXiv preprint arXiv:1712.05526 , year=
Targeted backdoor attacks on deep learning systems using data poisoning , author=. arXiv preprint arXiv:1712.05526 , year=
-
[3]
25th Annual Network And Distributed System Security Symposium (NDSS 2018) , year=
Trojaning attack on neural networks , author=. 25th Annual Network And Distributed System Security Symposium (NDSS 2018) , year=
2018
-
[4]
International Conference on Learning Representations , year=
WaNet-Imperceptible Warping-based Backdoor Attack , author=. International Conference on Learning Representations , year=
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Lira: Learnable, imperceptible and robust backdoor attacks , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
Bypassing Backdoor Detection Algorithms in Deep Learning , year=
Tan, Te Juin Lester and Shokri, Reza , booktitle=. Bypassing Backdoor Detection Algorithms in Deep Learning , year=
-
[7]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages=
Imperceptible Backdoor Attack: From Input Space to Feature Representation , author=. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages=. 2022 , organization=
2022
-
[8]
arXiv preprint arXiv:2501.05928 , year=
Towards Backdoor Stealthiness in Model Parameter Space , author=. arXiv preprint arXiv:2501.05928 , year=
-
[9]
International symposium on research in attacks, intrusions, and defenses , pages=
Fine-pruning: Defending against backdooring attacks on deep neural networks , author=. International symposium on research in attacks, intrusions, and defenses , pages=. 2018 , organization=
2018
-
[10]
European Conference on Computer Vision , pages=
Data-free backdoor removal based on channel lipschitzness , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[11]
Advances in Neural Information Processing Systems , volume=
Adversarial neuron pruning purifies backdoored deep models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Machine Learning , pages=
Reconstructive neuron pruning for backdoor defense , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[13]
Advances in Neural Information Processing Systems , volume=
Unveiling and mitigating backdoor vulnerabilities based on unlearning weight changes and backdoor activeness , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Pre-activation distributions expose backdoor neurons , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
BEEAR: Embedding-based Adversarial Removal of Safety Backdoors in Instruction-tuned Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Enhancing fine-tuning based backdoor defense with sharpness-aware minimization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Proceedings of the 35th annual computer security applications conference , pages=
Strip: A defence against trojan attacks on deep neural networks , author=. Proceedings of the 35th annual computer security applications conference , pages=
-
[18]
International Conference on Machine Learning , pages=
Backdoor scanning for deep neural networks through k-arm optimization , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[19]
Advances in Neural Information Processing Systems , volume=
Shared adversarial unlearning: Backdoor mitigation by unlearning shared adversarial examples , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
Towards stable backdoor purification through feature shift tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
European Conference on Computer Vision , pages=
Reflection backdoor: A natural backdoor attack on deep neural networks , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[22]
Advances in Neural Information Processing Systems , volume=
Input-aware dynamic backdoor attack , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Backdoor attack with imperceptible input and latent modification , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Anti-backdoor learning: Training clean models on poisoned data , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
The Thirteenth International Conference on Learning Representations , year=
REFINE: Inversion-Free Backdoor Defense via Model Reprogramming , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Backdoor defense via adaptively splitting poisoned dataset , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
The Tenth International Conference on Learning Representations , year =
Kunzhe Huang and Yiming Li and Baoyuan Wu and Zhan Qin and Kui Ren , title =. The Tenth International Conference on Learning Representations , year =
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Progressive poisoned data isolation for training-time backdoor defense , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Mind Control through Causal Inference: Predicting Clean Images from Poisoned Data , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
Proceedings of the 35th Annual Computer Security Applications Conference (ACSAC 2019) , pages =
STRIP: A Defence Against Trojan Attacks on Deep Neural Networks , author =. Proceedings of the 35th Annual Computer Security Applications Conference (ACSAC 2019) , pages =. 2019 , organization =
2019
-
[31]
36th Annual Computer Security Applications Conference (ACSAC 2020) , pages =
Februus: Input Purification Defense Against Trojan Attacks on Deep Neural Network Systems , author =. 36th Annual Computer Security Applications Conference (ACSAC 2020) , pages =. 2020 , organization =
2020
-
[32]
Proc.\ of the Deep Learning and Security Workshop (DLS) 2020 , year =
SentiNet: Detecting Localized Universal Attacks Against Deep Learning Systems , author =. Proc.\ of the Deep Learning and Security Workshop (DLS) 2020 , year =
2020
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023 , pages =
Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency (TeCo) , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023 , pages =
2023
-
[34]
arXiv preprint arXiv:2310.17498 , year =
CBD: A Certified Backdoor Detector Based on Local Dominant Probability , author =. arXiv preprint arXiv:2310.17498 , year =
-
[35]
arXiv preprint arXiv:2312.02673 , year =
Robust Backdoor Detection for Deep Learning via Topological Evolution Dynamics (TED) , author =. arXiv preprint arXiv:2312.02673 , year =
-
[36]
arXiv preprint arXiv:2308.12439 , year =
BaDExpert: Extracting Backdoor Functionality for Accurate Backdoor Input Detection , author =. arXiv preprint arXiv:2308.12439 , year =
-
[37]
Journal of Machine Learning Research , volume=
CVXPY: A Python-embedded modeling language for convex optimization , author=. Journal of Machine Learning Research , volume=
-
[38]
In: IEEE S&P (2024).https://doi.org/ 10.1109/SP54263.2024.00230
Exploring the Orthogonality and Linearity of Backdoor Attacks , author=. 2024 IEEE Symposium on Security and Privacy (SP) , year =. doi:10.1109/SP54263.2024.00225 , url =
-
[39]
Advances in Neural Information Processing Systems , volume=
Backdoorbench: A comprehensive benchmark of backdoor learning , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
Fisher information guided purification against backdoor attacks , author=. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
2024
-
[41]
Convex Optimization , publisher=
Boyd, Stephen and Vandenberghe, Lieven , year=. Convex Optimization , publisher=
-
[42]
arXiv preprint arXiv:2509.07504 , year=
Backdoor Attacks and Defenses in Computer Vision Domain: A Survey , author=. arXiv preprint arXiv:2509.07504 , year=
-
[43]
The Twelfth International Conference on Learning Representations , year=
Universal Jailbreak Backdoors from Poisoned Human Feedback , author=. The Twelfth International Conference on Learning Representations , year=
-
[44]
Injecting Universal Jailbreak Backdoors into LLMs in Minutes , author=
-
[45]
Forty-second International Conference on Machine Learning , year=
CROW: Eliminating Backdoors from Large Language Models via Internal Consistency Regularization , author=. Forty-second International Conference on Machine Learning , year=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Simulate and eliminate: Revoke backdoors for generative large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
CleanGen: Mitigating Backdoor Attacks for Generation Tasks in Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[48]
Backdoor
Yige Li and Hanxun Huang and Yunhan Zhao and Xingjun Ma and Jun Sun , booktitle=. Backdoor. 2025 , url=
2025
-
[49]
IEEE Access , volume=
A backdoor attack against lstm-based text classification systems , author=. IEEE Access , volume=. 2019 , publisher=
2019
-
[50]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
BITE: Textual backdoor attacks with iterative trigger injection , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
arXiv preprint arXiv:2305.02424 , year=
Backdoor learning on sequence to sequence models , author=. arXiv preprint arXiv:2305.02424 , year=
-
[52]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Spinning language models: Risks of propaganda-as-a-service and countermeasures , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[53]
Advances in Neural Information Processing Systems , volume=
Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Safety Layers in Aligned Large Language Models: The Key to
Shen Li and Liuyi Yao and Lan Zhang and Yaliang Li , booktitle=. Safety Layers in Aligned Large Language Models: The Key to. 2025 , url=
2025
-
[55]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[56]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[57]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[58]
LT-Defense: Searching-free Backdoor Defense via Exploiting the Long-tailed Effect , url =
Xu, Yixiao and Fang, Binxing and Li, Mohan and Tang, Keke and Tian, Zhihong , booktitle =. LT-Defense: Searching-free Backdoor Defense via Exploiting the Long-tailed Effect , url =. doi:10.52202/079017-0117 , editor =
-
[59]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Test-time backdoor mitigation for black-box large language models with defensive demonstrations , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[61]
Hidden killer: Invisible textual backdoor attacks with syntactic trigger , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[63]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[64]
Transactions on Machine Learning Research , issn=
A Survey of Recent Backdoor Attacks and Defenses in Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[65]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[66]
Shen, Guangyu and Cheng, Siyuan and Zhang, Zhuo and Tao, Guanhong and Zhang, Kaiyuan and Guo, Hanxi and Yan, Lu and Jin, Xiaolong and An, Shengwei and Ma, Shiqing and Zhang, Xiangyu , booktitle =. 2025 , volume =. doi:10.1109/SP61157.2025.00103 , url =
-
[67]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Chain-of-scrutiny: Detecting backdoor attacks for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[68]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Piccolo: Exposing complex backdoors in nlp transformer models , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ConfGuard: A simple and effective backdoor detection for large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
ONION : A Simple and Effective Defense Against Textual Backdoor Attacks
Qi, Fanchao and Chen, Yangyi and Li, Mukai and Yao, Yuan and Liu, Zhiyuan and Sun, Maosong. ONION : A Simple and Effective Defense Against Textual Backdoor Attacks. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.752
-
[71]
Findings of the association for computational linguistics: EMNLP 2022 , pages=
Fine-mixing: Mitigating backdoors in fine-tuned language models , author=. Findings of the association for computational linguistics: EMNLP 2022 , pages=
2022
-
[72]
Weight Poisoning Attacks on Pretrained Models
Kurita, Keita and Michel, Paul and Neubig, Graham. Weight Poisoning Attacks on Pretrained Models. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.249
-
[73]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Backdooring instruction-tuned large language models with virtual prompt injection , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[74]
arXiv preprint arXiv:2401.05566 , year=
Sleeper agents: Training deceptive llms that persist through safety training , author=. arXiv preprint arXiv:2401.05566 , year=
-
[75]
Jiazhu Dai, Chuanshuai Chen, and Yufeng Li. 2019. A backdoor attack against lstm-based text classification systems. IEEE Access, 7:138872--138878
2019
-
[76]
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. 2019. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access, 7:47230--47244
2019
-
[77]
Haoran Li, Yulin Chen, Zihao Zheng, Qi Hu, Chunkit Chan, Heshan Liu, and Yangqiu Song. 2025 a . Simulate and eliminate: Revoke backdoors for generative large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 397--405
2025
-
[78]
Yige Li, Hanxun Huang, Yunhan Zhao, Xingjun Ma, and Jun Sun. 2025 b . https://openreview.net/forum?id=sYLiY87mNn Backdoor LLM : A comprehensive benchmark for backdoor attacks and defenses on large language models . In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[79]
Nay Myat Min, Long H Pham, Yige Li, and Jun Sun. 2025. Crow: Eliminating backdoors from large language models via internal consistency regularization. In Forty-second International Conference on Machine Learning
2025
-
[80]
Fanchao Qi, Yangyi Chen, Xurui Zhang, Mukai Li, Zhiyuan Liu, and Maosong Sun. 2021 a . https://doi.org/10.18653/v1/2021.emnlp-main.374 Mind the style of text! adversarial and backdoor attacks based on text style transfer . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4569--4580, Online and Punta Cana, Do...
-
[81]
Fanchao Qi, Mukai Li, Yangyi Chen, Zhengyan Zhang, Zhiyuan Liu, Yasheng Wang, and Maosong Sun. 2021 b . Hidden killer: Invisible textual backdoor attacks with syntactic trigger. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Lo...
2021
-
[82]
Javier Rando and Florian Tram \`e r. 2024. Universal jailbreak backdoors from poisoned human feedback. In The Twelfth International Conference on Learning Representations
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.