RLCSD: Reinforcement Learning with Contrastive On-Policy Self-Distillation
Pith reviewed 2026-06-27 10:26 UTC · model grok-4.3
The pith
Contrasting the distributional gap under correct versus incorrect hints isolates task-bearing tokens and suppresses privilege-induced style drift in on-policy self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
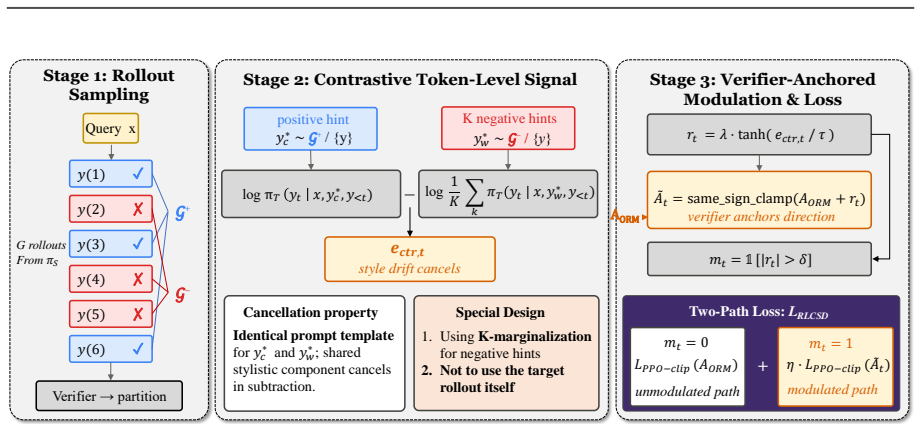
Privilege-induced style drift arises because conditioning on any hint, correct or not, shifts the model toward more direct outputs; the paper therefore defines the contrastive gap as the difference between the correct-hint teacher-student divergence and the wrong-hint divergence, and shows that this difference concentrates supervision on task tokens while the non-contrastive version does not.
What carries the argument
The contrastive gap: the teacher-student distributional difference under a correct hint minus the same difference under a wrong hint, used as the learning signal.
If this is right
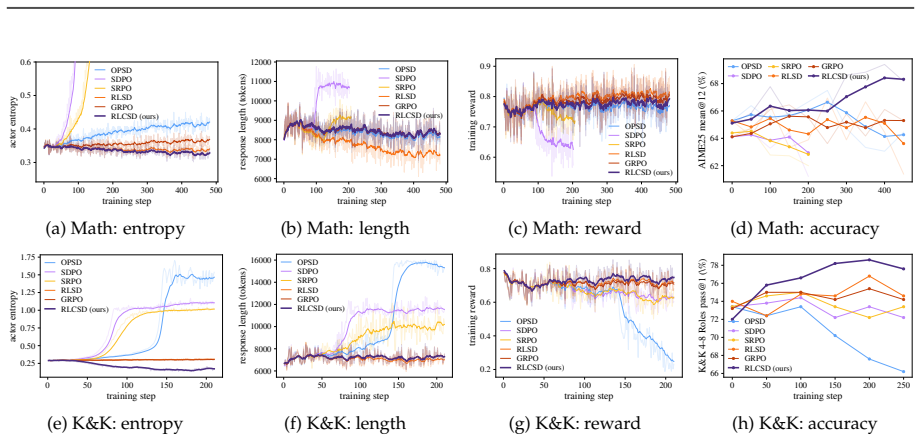
- RLCSD yields higher accuracy than GRPO and prior OPSD methods on mathematical and logical reasoning tasks for Qwen3 (1.7B/4B/8B) and Olmo-3-7B-Think.
- The same contrastive subtraction can be inserted into existing OPSD algorithms to improve them without changing their other components.
- The underlying contrastive principle applies beyond single-model self-distillation to the broader setting of on-policy distillation between different models.
Where Pith is reading between the lines
- The same subtraction technique could be tested in any distillation setting where privileged context is available for some but not all training examples.
- If the style component is reliably removed, the method may allow training runs to maintain longer, more exploratory responses without explicit length penalties.
Load-bearing premise
The distributional shift caused by any hint is dominated by style tokens rather than by task content, so that subtracting the wrong-hint gap removes style without removing useful task supervision.
What would settle it
A controlled run in which the contrastive signal still assigns higher weight to style tokens than to task tokens on the same prompts, or in which RLCSD fails to improve accuracy or response quality over non-contrastive OPSD on the reported math and logic suites.
Figures






read the original abstract
On-policy self-distillation (OPSD) provides dense, token-level supervision for reasoning models by aligning a model's own distribution with the distribution it produces under privileged context, typically a verified solution. However, we show that the learning signal drawn from this distributional gap concentrates on style tokens rather than task-bearing ones, as the hinted model tends to produce more direct, shorter outputs. We term this pathology \emph{privilege-induced style drift}, which destabilizes training or causes response length to shrink. To address this, we propose \textbf{RLCSD} (Reinforcement Learning with Contrastive on-policy Self-Distillation), which mitigates this drift by contrasting the teacher-student gap under a correct hint against that under a wrong hint, suppressing the style shift that conditioning on a hint tends to induce regardless of correctness, and yielding a signal that is more concentrated on task-bearing tokens. Experiments on Qwen3 (1.7B/4B/8B) and Olmo-3-7B-Think across mathematical and logical reasoning show that RLCSD consistently outperforms GRPO and prior OPSD methods. We further show that the contrastive principle is general: it plugs into existing OPSD methods to improve them, and its underlying insight extends to the broader cross-model on-policy distillation setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RLCSD as an extension to on-policy self-distillation (OPSD) for reasoning models. Standard OPSD aligns the model's distribution to its own output under a verified (privileged) hint but produces a learning signal that concentrates on style tokens due to shorter, more direct outputs under hints, termed privilege-induced style drift. RLCSD subtracts the on-policy gap under a wrong hint from the gap under a correct hint to cancel the common style component while retaining task-relevant differences. Experiments claim consistent outperformance versus GRPO and prior OPSD on Qwen3 (1.7B/4B/8B) and Olmo-3-7B-Think for mathematical and logical reasoning; the contrastive principle is also shown to improve existing OPSD methods and to extend to cross-model distillation.
Significance. If the central empirical claims hold and the contrast reliably isolates task tokens, RLCSD offers a lightweight, general mechanism for purifying dense token-level supervision in on-policy RL without extra labels or models. The reported generality across base methods would increase its practical value for stabilizing reasoning-model training.
major comments (2)
- [Abstract / Method description] The load-bearing assumption that any hint (correct or incorrect) induces an identical style shift while task differences appear exclusively under the correct hint is stated in the abstract but receives no direct empirical test or counter-example analysis. If hint correctness modulates length, uncertainty, or token distributions on reasoning steps differently, the subtraction can attenuate rather than purify the task signal.
- [Abstract] The abstract asserts 'consistent outperformance' on Qwen3 and Olmo models yet supplies no quantitative deltas, standard errors, length-controlled metrics, or ablation tables. Without these controls the claim that the contrast concentrates the signal on task-bearing tokens rather than merely altering response style cannot be evaluated.
minor comments (2)
- [Method] Notation for the contrastive gap (correct-hint minus wrong-hint) should be introduced with an explicit equation early in the method section to avoid ambiguity when the same idea is later applied to other OPSD variants.
- [Experimental setup] The paper should clarify whether wrong hints are sampled from the same distribution as correct hints or constructed differently, as this choice affects whether the style component is truly matched.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying the support for our claims and committing to revisions that strengthen the empirical grounding without altering the core contribution.
read point-by-point responses
-
Referee: [Abstract / Method description] The load-bearing assumption that any hint (correct or incorrect) induces an identical style shift while task differences appear exclusively under the correct hint is stated in the abstract but receives no direct empirical test or counter-example analysis. If hint correctness modulates length, uncertainty, or token distributions on reasoning steps differently, the subtraction can attenuate rather than purify the task signal.
Authors: We agree that a direct empirical test of the identical style-shift assumption would strengthen the justification. The current manuscript motivates the assumption via the observed privilege-induced style drift but does not explicitly compare style metrics (length, non-task token distributions) between correct and incorrect hints. In the revision we will add such an analysis, including counter-examples if they arise, to verify that the common style component is reliably subtracted while task-relevant differences are retained. revision: yes
-
Referee: [Abstract] The abstract asserts 'consistent outperformance' on Qwen3 and Olmo models yet supplies no quantitative deltas, standard errors, length-controlled metrics, or ablation tables. Without these controls the claim that the contrast concentrates the signal on task-bearing tokens rather than merely altering response style cannot be evaluated.
Authors: The abstract summarizes the finding at a high level, with full quantitative results (including deltas, standard errors, and ablations) provided in the experimental sections and tables. To improve evaluability we will revise the abstract to include representative accuracy gains and will add explicit length-controlled metrics and token-level concentration analyses in the main text to demonstrate that gains arise from task-token supervision rather than style changes alone. revision: partial
Circularity Check
No circularity in provided description
full rationale
The abstract and description introduce RLCSD as a contrastive extension to on-policy self-distillation to address privilege-induced style drift, but contain no equations, fitted parameters, self-citations, or ansatzes that reduce any claimed prediction or result to its own inputs by construction. The contrastive principle is presented as a novel mitigation without load-bearing reliance on prior author work or renaming of known patterns. The derivation chain is therefore self-contained with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pp. 21246–21263,
2024
-
[2]
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. Re- visiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562,
-
[3]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pp. 32694–32717,
2024
-
[4]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[5]
Adaptive teacher exposure for self-distillation in llm reasoning.arXiv preprint arXiv:2605.11458,
Zihao Han, Tiangang Zhang, Huaibin Wang, and Yilun Sun. Adaptive teacher exposure for self-distillation in llm reasoning.arXiv preprint arXiv:2605.11458,
-
[6]
Guangya Hao, Yitong Shang, Yunbo Long, Zhuokai Zhao, and Hanxue Liang. Self-policy distillation via capability-selective subspace projection.arXiv preprint arXiv:2605.22675,
-
[7]
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002,
-
[8]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456,
-
[9]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
-
[10]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006,
-
[11]
Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
14 Jonas H ¨ubotter, Frederike L ¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
-
[12]
Yiqiao Jin, Yiyang Wang, Lucheng Fu, Yijia Xiao, Yinyi Luo, Haoxin Liu, B Aditya Prakash, Josiah Hester, Jindong Wang, and Srijan Kumar. Unisd: Towards a unified self-distillation framework for large language models.arXiv preprint arXiv:2605.06597,
-
[13]
Junlong Ke, Zichen Wen, Weijia Li, Conghui He, and Linfeng Zhang. Respecting self-uncertainty in on-policy self-distillation for efficient llm reasoning.arXiv preprint arXiv:2605.13255,
-
[14]
Jeonghye Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Rebellious student: Reversing teacher signals for reasoning exploration with self-distilled rlvr.arXiv preprint arXiv:2605.10781,
-
[15]
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models.arXiv preprint arXiv:2402.03898,
-
[16]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026a. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai ...
-
[17]
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
-
[18]
Dataset compiled from the 2023 American Mathematics Competitions. Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep ...
2023
-
[19]
URL https://arxiv.org/abs/2512.13961. Leyi Pan, Shuchang Tao, Yunpeng Zhai, Zheyu Fu, Liancheng Fang, Minghua He, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, et al. d-treerpo: Towards more reliable policy optimization for diffusion language models.arXiv preprint arXiv:2512.09675,
-
[20]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[22]
Guobin Shen, Xiang Cheng, Chenxiao Zhao, Lei Huang, Jindong Li, Dongcheng Zhao, and Xing Yu. Anti-self-distillation for reasoning rl via pointwise mutual information.arXiv preprint arXiv:2605.11609, 2026a. Guobin Shen, Lei Huang, Xiang Cheng, Chenxiao Zhao, Jindong Li, Dongcheng Zhao, and Xing Yu. From generic correlation to input-specific credit in on-po...
-
[23]
A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
-
[24]
Jiaxuan Wang, Xuan Ouyang, Zhiyu Chen, Yulan Hu, Zheng Pan, Xin Li, and Lan-Zhe Guo. Trace: Distilling where it matters via token-routed self on-policy alignment.arXiv preprint arXiv:2605.10194,
-
[25]
Yecheng Wu, Song Han, and Hai Cai. Lightning opd: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint arXiv:2604.13010,
-
[26]
Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
-
[27]
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2502.14768,
-
[28]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[29]
Self-distilled rlvr.arXiv preprint arXiv:2604.03128,
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128,
-
[30]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
-
[31]
Dapo: An open-source llm reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. Advances in Neural Information Processing Systems, 38:113222–113244, 2026a. Xin Yu, Liuchen Liao, Yiwen Zhang, Yingchen Yu, Lingzhou Xue, and Qinzhen Guo. Prefere...
-
[32]
American invitational mathematics examination (aime) 2024,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024,
2024
-
[33]
American invitational mathematics examination (aime) 2025,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025,
2025
-
[34]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
-
[35]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
-
[36]
Siqi Zhu, Xuyan Ye, Hongyu Lu, Weiye Shi, and Ge Liu. The many faces of on-policy distillation: Pitfalls, mechanisms, and fixes.arXiv preprint arXiv:2605.11182,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.