Multi-View In-Cabin Monitoring System for Public Transport Vehicles
Pith reviewed 2026-06-27 10:21 UTC · model grok-4.3
The pith
A new multi-view dataset supplies synchronized RGB, depth and LiDAR recordings from inside a city bus together with 3D pose and bounding-box labels for occupants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
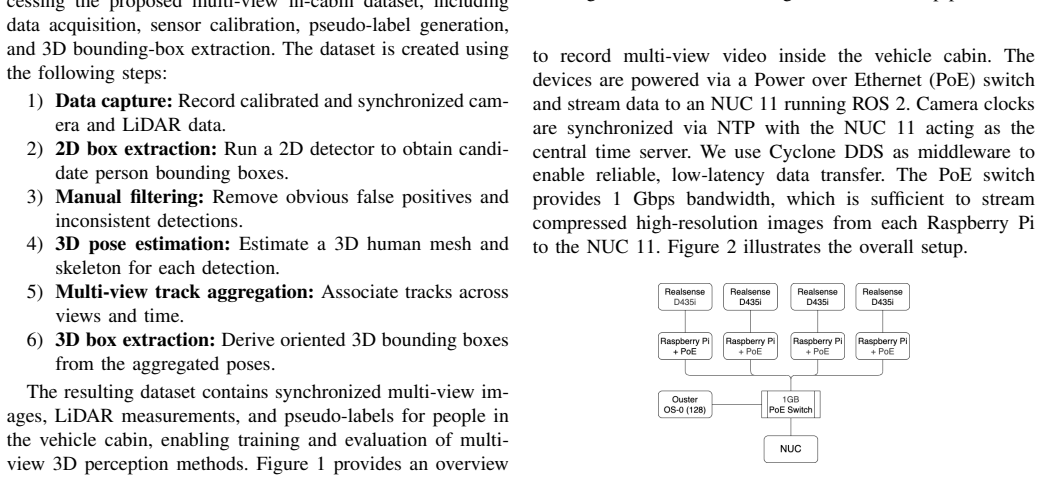
We introduce a multi-view in-cabin monitoring dataset for public transportation with synchronized RGB and depth images from four inward-facing cameras and a rotating LiDAR covering the vehicle interior of a digitalized and partly automated German city bus. The dataset contains 9,136 synchronized samples with annotations and is accompanied by a calibration and pseudo-labeling pipeline that generates 3D human pose estimates and oriented 3D bounding boxes for occupants. We further provide a nuScenes-format conversion and benchmark representative multi-view 3D detection models.
What carries the argument
The multi-view in-cabin dataset together with its calibration and pseudo-labeling pipeline that produces 3D human poses and oriented bounding boxes from four inward cameras and rotating LiDAR.
Load-bearing premise
The pseudo-labeling pipeline produces sufficiently accurate 3D human pose estimates and oriented bounding boxes to serve as reliable training targets.
What would settle it
A direct quantitative comparison that shows large systematic errors between the pseudo-labels and independent manual ground-truth annotations would show the labels cannot be used for training.
Figures











read the original abstract
We introduce a multi-view in-cabin monitoring dataset for public transportation with synchronized RGB and depth images from four inward-facing cameras and a rotating LiDAR covering the vehicle interior of a digitalized and partly automated German city bus. The dataset contains 9.136 synchronized samples with annotations and is accompanied by a calibration and pseudo-labeling pipeline that generates 3D human pose estimates and oriented 3D bounding boxes for occupants. We further provide a nuScenes-format conversion and benchmark representative multi-view 3D detection models (e.g., Lift-Splat-Shoot and BEVFusion), supporting comparative evaluation and small-scale training of multi-view in-cabin perception models. The dataset and tools are available at https://github.com/EvgenyGorelik/multiview_incabin_dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-view in-cabin monitoring dataset for public transport consisting of 9,136 synchronized samples with RGB, depth, and rotating LiDAR data from four inward-facing cameras in a German city bus. It provides a calibration and pseudo-labeling pipeline that produces 3D human pose estimates and oriented 3D bounding boxes, a nuScenes-format conversion, and benchmarks of representative multi-view 3D detection models such as Lift-Splat-Shoot and BEVFusion. The dataset and tools are released via GitHub.
Significance. If the pseudo-label accuracy holds, the work supplies a useful public resource for multi-view perception research in constrained vehicle interiors, where existing datasets are scarce. The release of the full pipeline, nuScenes conversion, and baseline results supports direct reproducibility and comparative evaluation.
major comments (1)
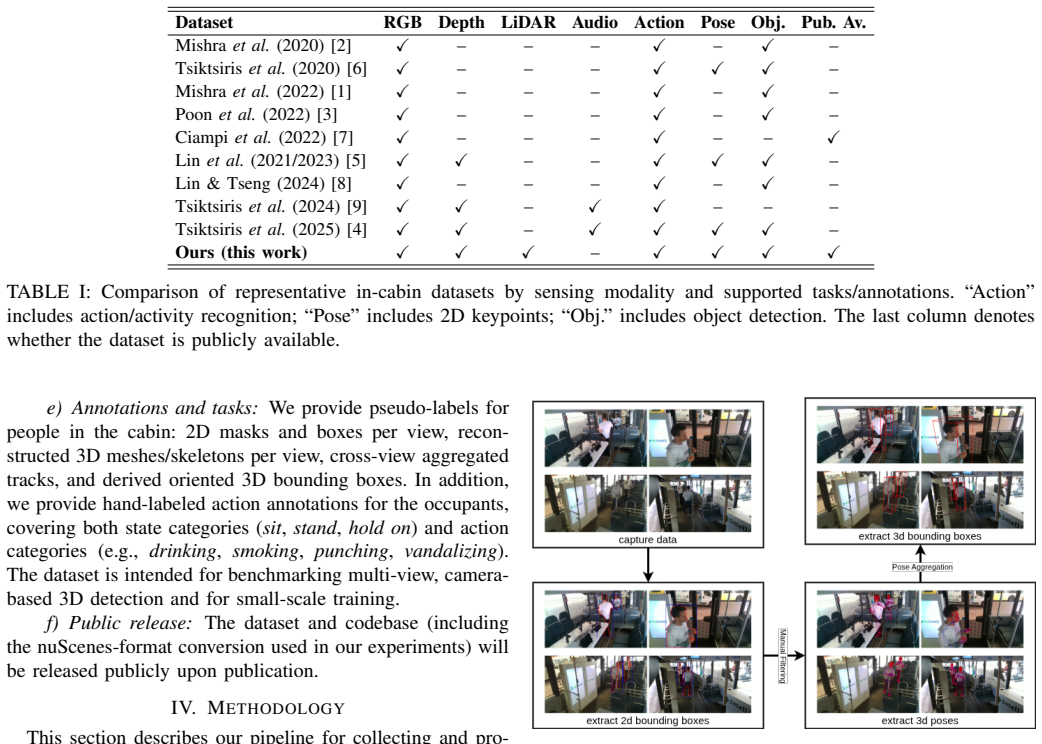
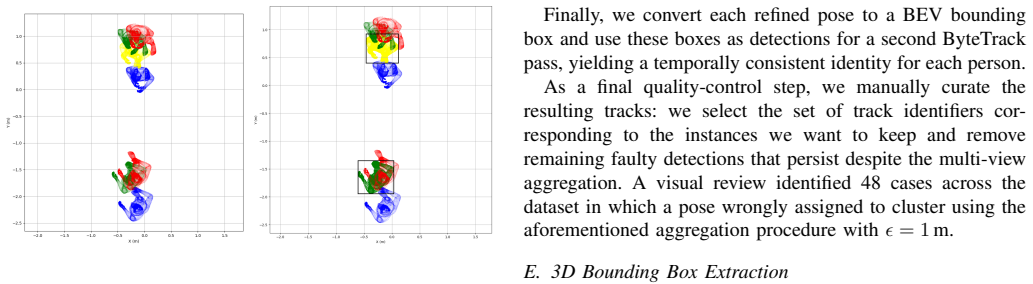
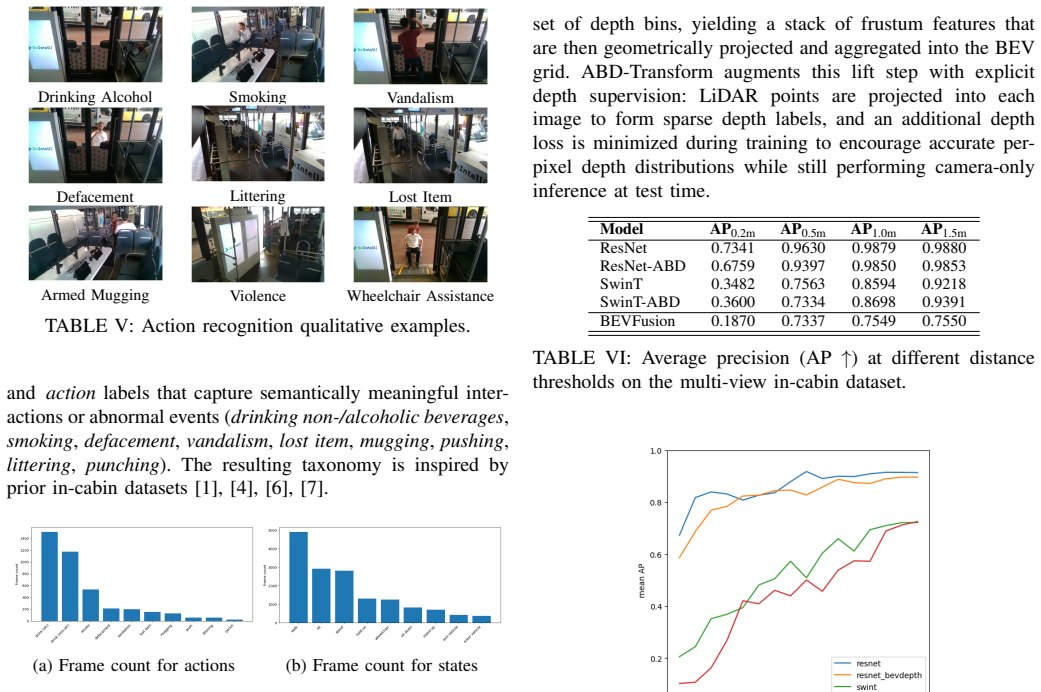
- [Pseudo-labeling pipeline] The pseudo-labeling pipeline (described in the abstract and methods) generates all 3D pose and oriented bounding-box annotations without any reported quantitative validation against manual ground truth. No held-out manually annotated subset, MPJPE, 3D IoU, or orientation-error metrics are provided, directly undermining the claim that these labels constitute reliable training targets for the nuScenes-format benchmarks.
minor comments (1)
- [Abstract] Abstract: '9.136' should be rendered as 9,136 (or 9136) for standard English numeric formatting.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential utility of the dataset and released pipeline. We address the single major comment below.
read point-by-point responses
-
Referee: [Pseudo-labeling pipeline] The pseudo-labeling pipeline (described in the abstract and methods) generates all 3D pose and oriented bounding-box annotations without any reported quantitative validation against manual ground truth. No held-out manually annotated subset, MPJPE, 3D IoU, or orientation-error metrics are provided, directly undermining the claim that these labels constitute reliable training targets for the nuScenes-format benchmarks.
Authors: We agree that the absence of quantitative validation against manual ground truth is a limitation of the current manuscript. The work relies on pseudo-labeling precisely to produce annotations at the scale of 9,136 samples; creating a large manually annotated 3D ground-truth set in the constrained multi-view in-cabin environment would have been prohibitively costly. The full calibration and pseudo-labeling pipeline is released so that the community can inspect, reproduce, or refine the labels. The reported benchmarks illustrate model behavior when trained on these labels rather than asserting that the labels match manual annotation quality. In the revised manuscript we will add a small manually annotated held-out subset together with MPJPE, 3D IoU, and orientation-error metrics to provide an empirical estimate of label fidelity. revision: yes
Circularity Check
No circularity: dataset release with no derivations or fitted predictions
full rationale
The paper is a dataset contribution that releases 9,136 multi-view samples plus a calibration/pseudo-labeling pipeline and nuScenes conversion. No equations, first-principles derivations, or statistical predictions are claimed. The annotations are generated by the described pipeline, but the paper does not present any result as 'predicted' from fitted parameters or reduced by construction to its own inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The work is therefore self-contained as an artifact release; absence of quantitative validation against manual ground truth is a correctness concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In-cabin monitoring system for autonomous vehicles,
A. Mishra, S. Lee, D. Kim, and S. Kim, “In-cabin monitoring system for autonomous vehicles,”Sensors, vol. 22, no. 12, p. 4360, 2022
2022
-
[2]
An intelligent in-cabin monitoring system in fully autonomous vehicles,
A. Mishra, J. Kim, D. Kim, J. Cha, and S. Kim, “An intelligent in-cabin monitoring system in fully autonomous vehicles,” in2020 International SoC Design Conference (ISOCC). IEEE, 2020, pp. 61–62
2020
-
[3]
Yolo-based deep learn- ing design for in-cabin monitoring system with fisheye-lens camera,
Y .-S. Poon, C.-C. Lin, Y .-H. Liu, and C.-P. Fan, “Yolo-based deep learn- ing design for in-cabin monitoring system with fisheye-lens camera,” in 2022 IEEE International Conference on Consumer Electronics (ICCE). IEEE, 2022, pp. 1–4
2022
-
[4]
A complete in-cabin monitoring framework for autonomous vehicles in public transportation,
D. Tsiktsiris, A. Lalas, M. Dasygenis, and K. V otis, “A complete in-cabin monitoring framework for autonomous vehicles in public transportation,” IET Intelligent Transport Systems, vol. 19, no. 1, p. e12612, 2025
2025
-
[5]
Multi-modality action recognition based on dual feature shift in vehicle cabin monitoring,
D. Lin, P. H. Y . Lee, Y . Li, R. Wang, K.-H. Yap, B. Li, and Y . S. Ngim, “Multi-modality action recognition based on dual feature shift in vehicle cabin monitoring,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 6480–6484
2024
-
[6]
Real-time abnormal event detection for enhanced security in autonomous shuttles mobility infrastructures,
D. Tsiktsiris, N. Dimitriou, A. Lalas, M. Dasygenis, K. V otis, and D. Tzovaras, “Real-time abnormal event detection for enhanced security in autonomous shuttles mobility infrastructures,”Sensors, vol. 20, no. 17, 2020. [Online]. Available: https://www.mdpi.com/ 1424-8220/20/17/4943
2020
-
[7]
Bus violence: An open benchmark for video violence detection on public transport,
L. Ciampi, P. Foszner, N. Messina, M. Staniszewski, C. Gennaro, F. Falchi, G. Serao, M. Cogiel, D. Golba, A. Szczesnaet al., “Bus violence: An open benchmark for video violence detection on public transport,”Sensors, vol. 22, no. 21, p. 8345, 2022
2022
-
[8]
Abnormal activity detection and classifi- cation of bus passengers with in-vehicle image sensing,
H.-Y . Lin and C.-H. Tseng, “Abnormal activity detection and classifi- cation of bus passengers with in-vehicle image sensing,”IEEE Access, 2024
2024
-
[9]
Improving passen- ger detection with overhead fisheye imaging,
D. Tsiktsiris, A. Lalas, M. Dasygenis, and K. V otis, “Improving passen- ger detection with overhead fisheye imaging,”IEEE Access, vol. 12, pp. 66 237–66 247, 2024
2024
-
[10]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”The international journal of robotics research, vol. 32, no. 11, pp. 1231–1237, 2013
2013
-
[11]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[12]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[13]
Argoverse: 3d tracking and forecasting with rich maps,
M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramananet al., “Argoverse: 3d tracking and forecasting with rich maps,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8748– 8757
2019
-
[14]
Argoverse 2: Next generation datasets for self-driving perception and forecasting,
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Ponteset al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,”arXiv preprint arXiv:2301.00493, 2023
Pith/arXiv arXiv 2023
-
[15]
2d human pose estimation: New benchmark and state of the art analysis,
M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” inProceedings of the IEEE Conference on computer Vision and Pattern Recognition, 2014, pp. 3686–3693
2014
-
[16]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
2014
-
[17]
Panoptic studio: A massively multiview system for social motion capture,
H. Joo, H. Liu, L. Tan, L. Gui, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, and Y . Sheikh, “Panoptic studio: A massively multiview system for social motion capture,” inProceedings of the IEEE interna- tional conference on computer vision, 2015, pp. 3334–3342
2015
-
[18]
Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,
C. Ionescu, D. Papava, V . Olaru, and C. Sminchisescu, “Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,”IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 7, pp. 1325–1339, 2013
2013
-
[19]
3d object detection for autonomous driving: A comprehensive survey,
J. Mao, S. Shi, X. Wang, and H. Li, “3d object detection for autonomous driving: A comprehensive survey,”International Journal of Computer Vision, vol. 131, no. 8, pp. 1909–1963, 2023
1909
-
[20]
Deep learning for monocular depth estimation: A review,
Y . Ming, X. Meng, C. Fan, and H. Yu, “Deep learning for monocular depth estimation: A review,”Neurocomputing, vol. 438, pp. 14–33, 2021
2021
-
[21]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210
2020
-
[22]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2024
2020
-
[23]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 2774–2781
2023
-
[24]
A survey of deep learning- based 3d object detection methods for autonomous driving across dif- ferent sensor modalities,
M. Valverde, A. Moutinho, and J.-V . Zacchi, “A survey of deep learning- based 3d object detection methods for autonomous driving across dif- ferent sensor modalities,”Sensors (Basel, Switzerland), vol. 25, no. 17, p. 5264, 2025
2025
-
[25]
Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss,
D. Maji, S. Nagori, M. Mathew, and D. Poddar, “Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 2637–2646
2022
-
[26]
Selfpose3d: Self-supervised multi- person multi-view 3d pose estimation,
V . Srivastav, K. Chen, and N. Padoy, “Selfpose3d: Self-supervised multi- person multi-view 3d pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 2502–2512
2024
-
[27]
3d human pose estimation with spatial and temporal transformers,
C. Zheng, S. Zhu, M. Mendieta, T. Yang, C. Chen, and Z. Ding, “3d human pose estimation with spatial and temporal transformers,” Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2021
2021
-
[28]
Sam 3d body: Robust full-body human mesh recovery,
X. Yang, D. Kukreja, D. Pinkus, A. Sagar, T. Fan, J. Park, S. Shin, J. Cao, J. Liu, N. Ugrinovicet al., “Sam 3d body: Robust full-body human mesh recovery,”arXiv preprint arXiv:2602.15989, 2026
arXiv 2026
-
[29]
Sam 3: Segment anything with concepts,
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huanget al., “Sam 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[30]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,
D.-H. Leeet al., “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,” inWorkshop on challenges in representation learning, ICML, vol. 3. Atlanta, 2013, p. 896
2013
-
[31]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[32]
Billion- scale semi-supervised learning for image classification,
I. Z. Yalniz, H. J ´egou, K. Chen, M. Paluri, and D. Mahajan, “Billion- scale semi-supervised learning for image classification,”arXiv preprint arXiv:1905.00546, 2019
Pith/arXiv arXiv 1905
-
[33]
Self-training with noisy student improves imagenet classification,
Q. Xie, M.-T. Luong, E. Hovy, and Q. V . Le, “Self-training with noisy student improves imagenet classification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 687–10 698
2020
-
[34]
Self-ensembling for visual domain adaptation,
G. French, M. Mackiewicz, and M. Fisher, “Self-ensembling for visual domain adaptation,”arXiv preprint arXiv:1706.05208, 2017
Pith/arXiv arXiv 2017
-
[35]
Improvements to target-based 3d lidar to camera calibration,
J.-K. Huang and J. W. Grizzle, “Improvements to target-based 3d lidar to camera calibration,”IEEE Access, vol. 8, pp. 134 101–134 110, 2020
2020
-
[36]
General, single-shot, target-less, and automatic lidar-camera extrinsic calibration toolbox,
K. Koide, S. Oishi, M. Yokozuka, and A. Banno, “General, single-shot, target-less, and automatic lidar-camera extrinsic calibration toolbox,” arXiv preprint arXiv:2302.05094, 2023
arXiv 2023
-
[37]
Opencalib: A multi-sensor calibration toolbox for autonomous driving,
G. Yan, Z. Liu, C. Wang, C. Shi, P. Wei, X. Cai, T. Ma, Z. Liu, Z. Zhong, Y . Liuet al., “Opencalib: A multi-sensor calibration toolbox for autonomous driving,”Software Impacts, vol. 14, p. 100393, 2022
2022
-
[38]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revisited,” inConference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[39]
Pixelwise instance segmentation with a dynamically instantiated network,
B. Leibeet al., “Pixelwise instance segmentation with a dynamically instantiated network,” inProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, 2016, pp. 123–132
2016
-
[40]
Cherrypicker: Semantic skeletonization and topological reconstruction of cherry trees,
L. Meyer, A. Gilson, O. Scholz, and M. Stamminger, “Cherrypicker: Semantic skeletonization and topological reconstruction of cherry trees,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6244–6253
2023
-
[41]
Object modelling by registration of multiple range images,
Y . Chen and G. Medioni, “Object modelling by registration of multiple range images,”Image and vision computing, vol. 10, no. 3, pp. 145–155, 1992
1992
-
[42]
Bytetrack: Multi-object tracking by associating every detection box,
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang, “Bytetrack: Multi-object tracking by associating every detection box,” inEuropean conference on computer vision. Springer, 2022, pp. 1–21
2022
-
[43]
A simplex method for function minimiza- tion,
J. A. Nelder and R. Mead, “A simplex method for function minimiza- tion,”The computer journal, vol. 7, no. 4, pp. 308–313, 1965
1965
-
[44]
Human action recognition from various data modalities: A review,
Z. Sun, Q. Ke, H. Rahmani, M. Bennamoun, G. Wang, and J. Liu, “Human action recognition from various data modalities: A review,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 3, pp. 3200–3225, 2022
2022
-
[45]
The kinetics human action video dataset,
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
Pith/arXiv arXiv 2017
-
[46]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[47]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[48]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
2018
-
[49]
Ultralytics YOLO,
G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO,” Jan. 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.