AnchorEdit: Maintaining Temporal Consistency in Multi-turn Image Editing via Causal Memory
Pith reviewed 2026-06-27 10:13 UTC · model grok-4.3
The pith
AnchorEdit uses causal memory and autoregressive training to prevent identity drift across many rounds of image editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
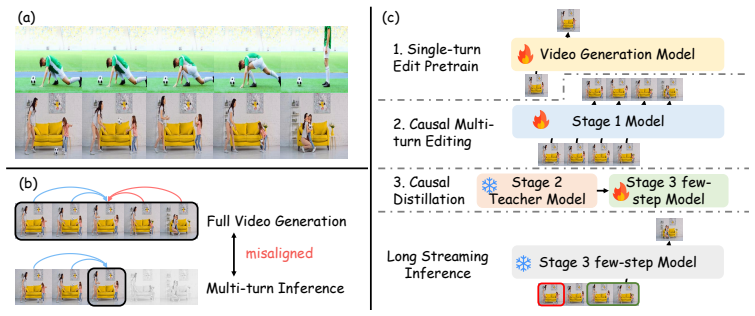
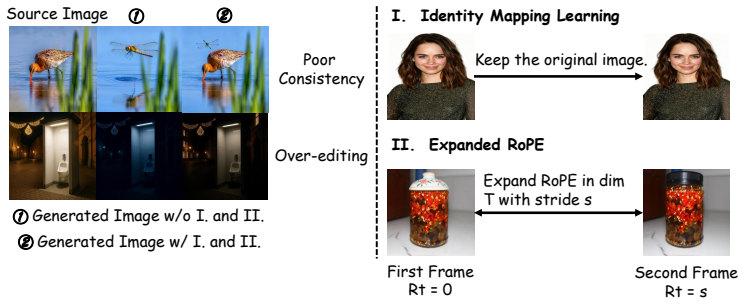
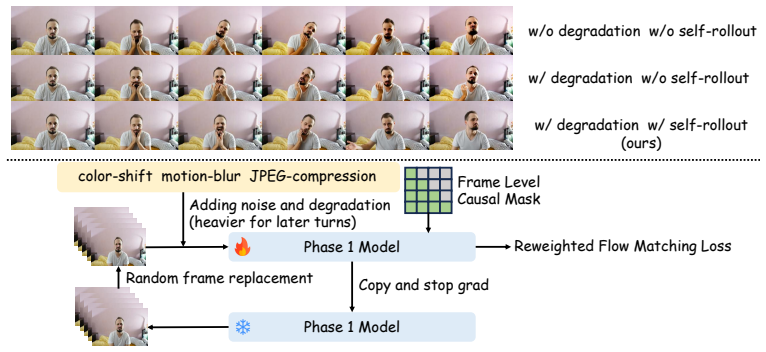
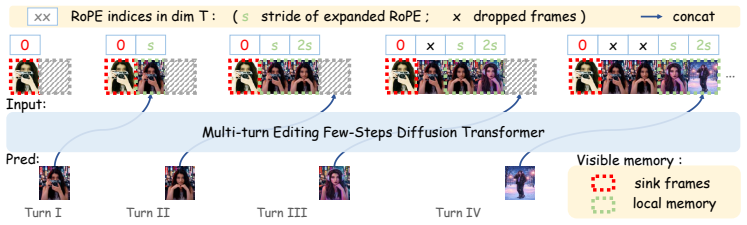
AnchorEdit is the first autoregressive diffusion framework for multi-turn image editing. It bridges video priors to causal inference via a three-stage curriculum of identity-preserving single-turn pretraining, causal autoregressive fine-tuning with self-rollout to reduce exposure bias, and consistency distillation for fast 4-step sampling, plus a memory mechanism that anchors the initial subject during inference to support stable extrapolation over long editing sequences.
What carries the argument
The causal memory mechanism that stores the initial subject identity and the three-stage training curriculum that forces autoregressive behavior aligned with sequential editing.
If this is right
- Multi-turn editing can run for ten or more rounds with stable subject fidelity instead of accumulating drift.
- High-resolution outputs remain consistent when generated autoregressively rather than with bidirectional attention.
- Four-step inference after distillation supports interactive use without sacrificing the consistency gains.
- A dedicated long-horizon benchmark can now be used to measure stability that short single-turn tests miss.
Where Pith is reading between the lines
- The same causal-memory pattern may apply to other sequential generation tasks such as iterative video or 3D model editing.
- Design tools could shift from single-shot edits to reliable session-long conversations with an AI editor.
- Self-rollout training to combat exposure bias might transfer to other autoregressive diffusion settings beyond images.
Load-bearing premise
The main reason for identity drift is the mismatch between bidirectional attention and causal editing, and the proposed curriculum plus memory will fix it without creating new inconsistencies.
What would settle it
Run AnchorEdit and prior video-based editors on the new multi-turn benchmark and check whether subject identity scores remain high after ten or more successive edits while instruction following does not degrade.
Figures






read the original abstract
Multi-turn image editing is essential for iterative design, yet current models often struggle with identity drift and error accumulation over successive steps. While existing research leverages video priors for consistency, their reliance on bidirectional attention is fundamentally misaligned with the causal, sequential nature of interactive editing. In this paper, we propose AnchorEdit, the first autoregressive (AR) diffusion-based framework designed specifically for high-resolution, long-term multi-turn editing. AnchorEdit bridges the gap between video priors and causal inference through a three-stage training curriculum: identity-preserving sing-turn pretraining, causal AR forcing fine-tuning with a novel self-rollout strategy to mitigate exposure bias, and consistency distillation for efficient 4-step generation. During inference, we introduce a memory mechanism to anchor the initial subject identity and ensure stable extrapolation across extended editing trajectories. To evaluate performance, we provide a new high-resolution multi-turn editing benchmark designed to stress-test long-horizon stability. Extensive experiments demonstrate that AnchorEdit achieves state-of-the-art results, maintaining exceptional subject fidelity and instruction following even over 10+ interaction rounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnchorEdit, the first autoregressive diffusion-based framework for high-resolution multi-turn image editing. It identifies bidirectional attention in video priors as misaligned with causal editing and addresses identity drift via a three-stage curriculum (identity-preserving single-turn pretraining, causal AR forcing fine-tuning with self-rollout to mitigate exposure bias, and consistency distillation for 4-step inference) plus a memory mechanism to anchor initial subject identity during long trajectories. A new high-resolution multi-turn editing benchmark is introduced, with claims of SOTA subject fidelity and instruction following over 10+ rounds.
Significance. If the long-horizon results and ablations hold, the work would be significant for bridging video diffusion models to causal interactive editing, a practical need in design workflows. The three-stage curriculum and memory anchoring represent a targeted adaptation, and the new benchmark could serve as a standard for evaluating temporal stability in sequential editing.
major comments (2)
- [Abstract] Abstract: The central claim that AnchorEdit maintains exceptional subject fidelity over 10+ interaction rounds via the causal AR forcing stage with self-rollout plus memory anchoring is asserted without any quantitative metrics, baselines, error bars, dataset descriptions, or long-horizon ablation results, making it impossible to evaluate whether the self-rollout actually mitigates exposure bias in sequential trajectories or whether the memory mechanism avoids new drift modes under 4-step inference.
- [Abstract] Abstract: The framing that bidirectional attention is the primary root cause of identity drift, resolved by the three-stage curriculum, lacks any comparative analysis or evidence that the proposed stages generalize beyond single-turn pretraining to prevent error accumulation specifically in multi-turn causal editing; without such support the SOTA fidelity claim cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The title references 'Causal Memory' but the abstract provides no definition or high-level description of how the memory mechanism operates during inference, which would aid reader understanding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly note that the abstract is highly condensed. We will revise it to better reference the quantitative evidence and analyses provided in the full manuscript while preserving its summary nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that AnchorEdit maintains exceptional subject fidelity over 10+ interaction rounds via the causal AR forcing stage with self-rollout plus memory anchoring is asserted without any quantitative metrics, baselines, error bars, dataset descriptions, or long-horizon ablation results, making it impossible to evaluate whether the self-rollout actually mitigates exposure bias in sequential trajectories or whether the memory mechanism avoids new drift modes under 4-step inference.
Authors: We agree the abstract does not embed the supporting numbers or ablations. The manuscript body (Experiments and Ablations sections) reports subject fidelity metrics, baseline comparisons, error bars, the new benchmark description, and long-horizon results over 10+ rounds, including targeted ablations on self-rollout for exposure bias and memory under 4-step inference. We will revise the abstract to include one sentence referencing these quantitative findings and directing readers to the relevant sections. revision: yes
-
Referee: [Abstract] Abstract: The framing that bidirectional attention is the primary root cause of identity drift, resolved by the three-stage curriculum, lacks any comparative analysis or evidence that the proposed stages generalize beyond single-turn pretraining to prevent error accumulation specifically in multi-turn causal editing; without such support the SOTA fidelity claim cannot be assessed.
Authors: The abstract summarizes the motivation; the manuscript provides the requested comparative analysis and evidence. The introduction and related-work sections contrast bidirectional video priors with causal editing needs, while the experiments section includes ablations demonstrating that the three-stage curriculum (identity pretraining, causal AR forcing with self-rollout, consistency distillation) reduces error accumulation in multi-turn trajectories beyond single-turn performance. We will revise the abstract to briefly note that these stages are validated by the reported multi-turn ablations. revision: yes
Circularity Check
No circularity: method described without derivations or self-referential reductions
full rationale
The paper presents AnchorEdit as a three-stage training curriculum (single-turn pretraining, causal AR forcing with self-rollout, consistency distillation) plus an inference-time memory mechanism. No equations, parameter fittings, or derivation chains are described in the provided text. Training stages are framed as independent empirical steps, and performance claims rest on experimental results rather than any reduction to inputs by construction, self-citation load-bearing, or renamed known results. This is a standard non-circular methodological contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[2]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6007–6017, 2023
2023
-
[3]
Magicbrush: A manually annotated dataset for instruction-guided image editing, 2024
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing, 2024
2024
-
[4]
Emu edit: Precise image editing via recognition and generation tasks, 2023
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks, 2023
2023
-
[5]
Anyedit: Mastering unified high-quality image editing for any idea, 2025
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea, 2025
2025
-
[6]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
FireRed-Image-Edit-1.0 technical report.arXiv preprint arXiv:2602.13344, 2026
Super Intelligence Team, Changhao Qiao, Chao Hui, Chen Li, Cunzheng Wang, Dejia Song, Jiale Zhang, Jing Li, Qiang Xiang, Runqi Wang, et al. Firered-image-edit-1.0 technical report.arXiv preprint arXiv:2602.13344, 2026
-
[8]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Cogvideox: Text-to-video diffusion models with an expert transformer, 2025
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025
2025
-
[10]
Hunyuanvideo: A systematic framework for large video generative models, 2025
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
2025
-
[11]
Jay Zhangjie Wu, Xuanchi Ren, Tianchang Shen, Tianshi Cao, Kai He, Yifan Lu, Ruiyuan Gao, Enze Xie, Shiyi Lan, Jose M Alvarez, et al. Chronoedit: Towards temporal reasoning for image editing and world simulation.arXiv preprint arXiv:2510.04290, 2025
-
[12]
Chengzhuo Tong, Mingkun Chang, Shenglong Zhang, Yuran Wang, Cheng Liang, Zhizheng Zhao, Ruichuan An, Bohan Zeng, Yang Shi, Yifan Dai, et al. Cof-t2i: Video models as pure visual reasoners for text-to-image generation.arXiv preprint arXiv:2601.10061, 2026
-
[13]
Vincie: Unlocking in-context image editing from video
Leigang Qu, Feng Cheng, Ziyan Yang, Qi Zhao, Shanchuan Lin, Yichun Shi, Yicong Li, Wenjie Wang, Tat-Seng Chua, and Lu Jiang. Vincie: Unlocking in-context image editing from video. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[15]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Frédo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[16]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregres- sive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Rolling forcing: Autoregressive long video diffusion in real time, 2025
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time, 2025
2025
-
[18]
Longlive: Real-time interactive long video generation, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation, 2025
2025
-
[19]
Skyreels-v2: Infinite-length film generative model, 2025
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. Skyreels-v2: Infinite-length film generative model, 2025
2025
-
[20]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. InEuropean Conference on Computer Vision, pages 289–305. Springer, 2024
2024
-
[21]
Roformer: Enhanced transformer with rotary position embedding, 2023
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023
2023
-
[22]
Longrope: Extending llm context window beyond 2 million tokens, 2024
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens, 2024
2024
-
[23]
Yarn: Efficient context window extension of large language models, 2026
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models, 2026
2026
-
[24]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[26]
Efficient streaming language models with attention sinks, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024
2024
-
[27]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
2025
-
[28]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
Shenghai Yuan, Yuanyang Yin, Zongjian Li, Xinwei Huang, Xiao Yang, and Li Yuan. Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
-
[31]
Taming teacher forcing for masked autoregressive video generation
Deyu Zhou, Quan Sun, Yuang Peng, Kun Yan, Runpei Dong, Duomin Wang, Zheng Ge, Nan Duan, and Xiangyu Zhang. Taming teacher forcing for masked autoregressive video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7374–7384, 2025
2025
-
[32]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[33]
Context forcing: Consistent autoregressive video generation with long context, 2026
Shuo Chen, Cong Wei, Sun Sun, Ping Nie, Kai Zhou, Ge Zhang, Ming-Hsuan Yang, and Wenhu Chen. Context forcing: Consistent autoregressive video generation with long context, 2026
2026
-
[34]
Knot forcing: Taming autoregressive video diffusion models for real-time infinite interactive portrait animation, 2025
Steven Xiao, Xindi Zhang, Dechao Meng, Qi Wang, Peng Zhang, and Bang Zhang. Knot forcing: Taming autoregressive video diffusion models for real-time infinite interactive portrait animation, 2025
2025
-
[35]
Videorope: What makes for good video rotary position embedding?, 2025
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Jian Tong, Haodong Duan, Qipeng Guo, Jiaqi Wang, Xipeng Qiu, and Dahua Lin. Videorope: What makes for good video rotary position embedding?, 2025
2025
-
[36]
Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self-rollout, 2026
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self-rollout, 2026. 11
2026
-
[37]
Multi-turn consistent image editing
Zijun Zhou, Yingying Deng, Xiangyu He, Weiming Dong, and Fan Tang. Multi-turn consistent image editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15792– 15801, 2025
2025
-
[38]
Prompt-to- prompt image editing with cross attention control, 2022
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control, 2022
2022
-
[39]
Null-text inversion for editing real images using guided diffusion models, 2022
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models, 2022
2022
-
[40]
Plug-and-play diffusion features for text-driven image-to-image translation, 2022
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation, 2022
2022
-
[41]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing, 2023
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing, 2023
2023
-
[42]
Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
2023
-
[43]
Adversarial diffusion distillation, 2023
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023
2023
-
[44]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[45]
Freeman, and Taesung Park
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation, 2024
2024
-
[46]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
editing steps
Lin Song, Wenbo Li, Guoqing Ma, Wei Tang, Bo Wang, Yuan Zhang, Yijun Yang, Yicheng Xiao, Jianhui Liu, Yanbing Zhang, Guohui Zhang, Wenhu Zhang, Hang Xu, Nan Jiang, Xin Han, Haoze Sun, Maoquan Zhang, Haoyang Huang, and Nan Duan. Awaking spatial intelligence in unified multimodal understanding and generation, 2026. 12 A Experimental Details A.1 Training Dat...
2026
-
[49]
different person/object
Visual Consistency Score (CS):CompareI t withI 0 andI t−1. •9-10:Subject identity, background structure, and non-edited details are perfectly preserved. •7-8:Subject is clearly the same, but very minor flickering or texture changes occur. • 5-6:Subject is identifiable, but shows noticeable drift (e.g., facial feature shifts, clothing pattern changes). • 3...
-
[50]
Consistency_Score
Semantic Following Score (SF):CompareI t withI t−1 and the Instruction. •9-10:Instruction is followed precisely with high visual quality and natural blending. • 7-8:Modification is clear and correct, with only minor artifacts or slight inaccuracies in extent. • 5-6:Instruction is partially followed but lacks precision (e.g., wrong color shade, object adde...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.