Accelerated Implicit GDA Schemes: Theoretical Guarantees and Application to Proximal Augmented Lagrangian Methods
Pith reviewed 2026-06-27 08:56 UTC · model grok-4.3
The pith
A family of Nesterov-type implicit GDA schemes achieves o(1/k^{r+1}) last-iterate convergence for the primal-dual objective gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through equivalence to implicit GDA and Lyapunov analysis on a variational inequality potential, the authors derive Nesterov-type implicit GDA schemes from a second-order ODE that attain an o(1/k^{r+1}) last-iterate rate for the primal-dual objective gap, along with an o(1/k) rate for a related explicit scheme and for variable-step implicit GDA on both gap and gradient norm.
What carries the argument
The second-order ODE framework that parameterizes the family of Nesterov-type implicit GDA schemes by r ≥ 0.
If this is right
- Variable-step-size implicit GDA achieves o(1/k) last-iterate convergence for both the primal-dual gap and the gradient norm.
- The equivalence between proximal ALM and implicit GDA extends to variable step sizes.
- Specializing to r=0 yields an explicit GDA scheme with o(1/k) last-iterate convergence for the gap.
- Numerical experiments confirm the predicted convergence rates.
Where Pith is reading between the lines
- The VI-based Lyapunov analysis may extend to other constrained optimization settings beyond linear equalities.
- These schemes could reduce the number of outer iterations needed in large-scale equality-constrained problems compared to standard ALM.
- Testing the methods on specific applications like support vector machines or optimal control problems would check practical speedups.
Load-bearing premise
The analysis depends on shifting the potential function in the Lyapunov analysis from the objective gap to a variational inequality measure.
What would settle it
Running the r=1 scheme on a simple linear equality constrained quadratic program and observing that the primal-dual gap does not decay faster than 1/k would disprove the o(1/k^2) claim.
Figures

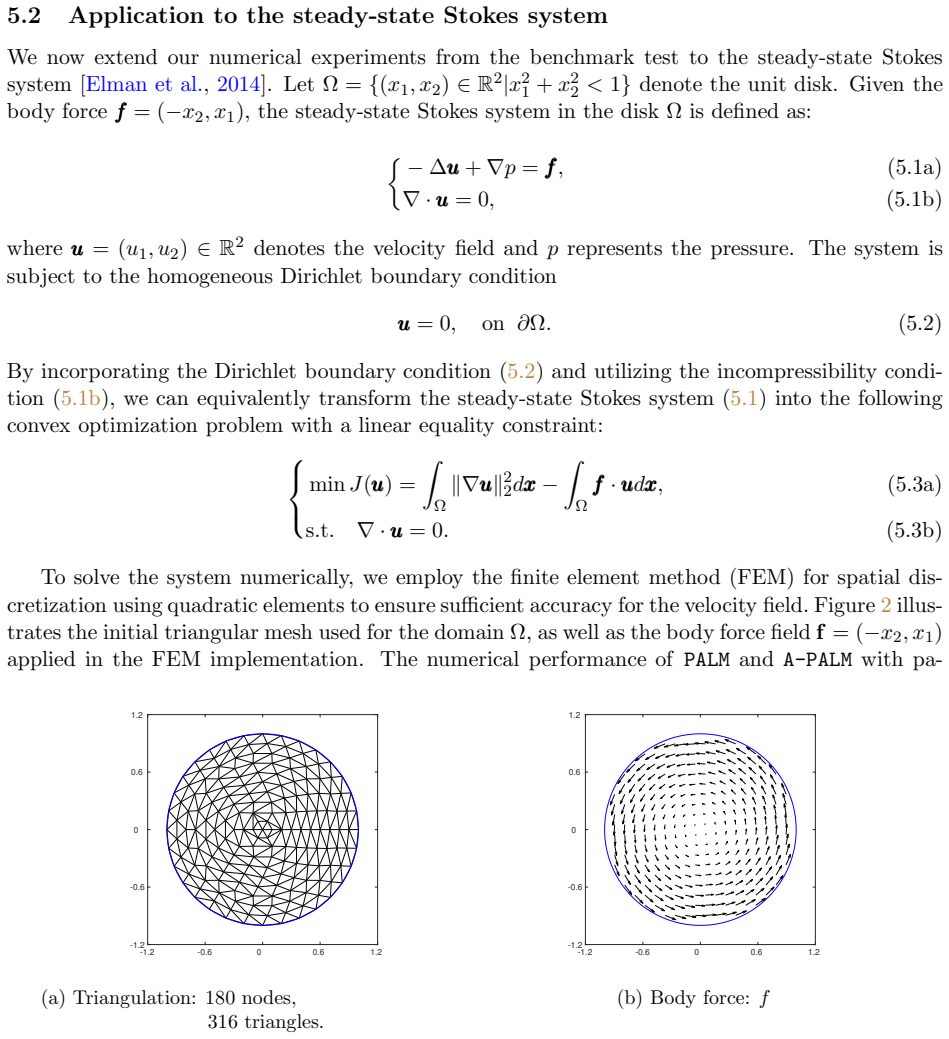
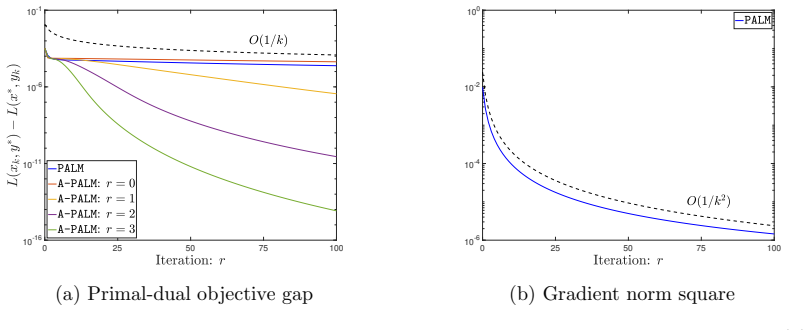

read the original abstract
Convex optimization problems with linear equality constraints arise ubiquitously in scientific computing, machine learning, and control theory. Classical Krylov methods are effective but rely on problem-specific preconditioners and high memory. Conversely, gradient-based methods like the augmented Lagrangian method (ALM) avoid these issues yet suffer from slow outer iterations. Developing accelerated outer-iteration schemes, therefore, remains a critical research objective. In this study, we demonstrate that incorporating a proximal operation into the augmented Lagrangian framework yields the proximal ALM, where the outer iteration is equivalent to an implicit gradient descent-ascent (GDA) scheme. We further establish that this equivalence extends naturally to the setting of variable step sizes. Through Lyapunov analysis, we show that the underlying potential function must be shifted from the conventional objective gap to a variational inequality measure, signaling a shift in perspective from pure convex optimization to minimax optimization. Motivated by these observations, we first develop an implicit GDA scheme with variable step sizes based on a continuous-time ODE framework, which achieves an $o(1/k)$ last-iterate convergence rate for both the primal-dual objective gap and the gradient norm. Building upon a second-order ODE framework, we then propose a family of Nesterov-type implicit GDA schemes parameterized by $r \geq 0$, which achieves an $o(1/k^{r+1})$ last-iterate convergence rate for the primal-dual objective gap. Furthermore, specializing the second-order ODE formulation to the case $r=0$, we derive a corresponding explicit GDA scheme and prove an $o(1/k)$ last-iterate convergence rate for the primal-dual objective gap. Finally, we present several numerical experiments to validate these theoretical results and demonstrate the effectiveness of the proposed methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts proximal augmented Lagrangian methods (ALM) as implicit gradient descent-ascent (GDA) schemes, develops variable-step implicit GDA methods from continuous-time ODEs achieving o(1/k) last-iterate rates on the primal-dual gap and gradient norm, proposes a parameterized family of Nesterov-type implicit GDA schemes (r ≥ 0) achieving o(1/k^{r+1}) rates via second-order ODEs and Lyapunov analysis on a variational inequality measure, derives an explicit GDA scheme for r=0 with o(1/k) rate, and validates the claims with numerical experiments on constrained convex problems.
Significance. If the Lyapunov arguments and ODE discretizations hold under the stated assumptions, the work provides a principled acceleration framework for outer iterations in proximal ALM without requiring problem-specific preconditioners, bridging convex optimization and minimax perspectives. The explicit shift to a VI-based potential and the derivation of higher-order schemes yielding last-iterate (rather than ergodic) rates are strengths, as is the extension to variable steps; this could impact large-scale applications in ML and control if the rates are robust.
minor comments (3)
- [Abstract] Abstract: the claim that the potential 'must be shifted' from the objective gap to a VI measure would benefit from a one-sentence justification of why the conventional gap fails to yield a decreasing Lyapunov function in the monotone saddle-point setting.
- Theorems on the o(1/k^{r+1}) rates should explicitly list the step-size sequence (e.g., the precise form of the variable steps derived from the ODE) and any monotonicity or Lipschitz assumptions required for the discretization error bounds.
- Numerical experiments section: include a brief comparison table against standard ALM and accelerated variants (e.g., Nesterov ALM) with iteration counts or wall-clock time to quantify the practical speedup implied by the theoretical rates.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The referee's assessment correctly identifies the core contributions, including the equivalence to implicit GDA, the shift to a VI-based Lyapunov function, the variable-step and higher-order schemes, and the last-iterate rates. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The derivation begins with an equivalence between proximal ALM and implicit GDA (a reformulation, not a self-definition), then constructs schemes by discretizing continuous-time ODEs and analyzes them via Lyapunov functions on a VI measure. These are standard external techniques in optimization; the o(1/k^{r+1}) rates follow from the analysis rather than reducing to fitted inputs or prior self-citations by construction. The explicit shift to VI perspective is stated as a modeling choice required for the saddle-point setting and does not create an internal loop. No load-bearing uniqueness theorems or ansatzes are imported from the authors' own prior work in a way that collapses the claims. The chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Proximal ALM outer iteration is equivalent to implicit GDA, extending to variable step sizes.
- domain assumption Lyapunov analysis requires shifting to variational inequality measure instead of objective gap.
Forward citations
Cited by 1 Pith paper
-
Modern Theory of Gradient-Based Optimization
A review synthesizing ODE approximations and Lyapunov techniques for analyzing acceleration in Nesterov, FISTA, ADMM, PDHG, and minimax optimization.
Reference graph
Works this paper leans on
-
[1]
Acta numerica , volume=
Numerical solution of saddle point problems , author=. Acta numerica , volume=. 2005 , publisher=
2005
-
[2]
Tellus A: Dynamic Meteorology and Oceanography , volume=
Variational algorithms for analysis and assimilation of meteorological observations: theoretical aspects , author=. Tellus A: Dynamic Meteorology and Oceanography , volume=. 1986 , publisher=
1986
-
[3]
2007 , publisher=
Optimal control: linear quadratic methods , author=. 2007 , publisher=
2007
-
[4]
SIAM Journal on Numerical Analysis , volume=
On the O(1/n) convergence rate of the Douglas--Rachford alternating direction method , author=. SIAM Journal on Numerical Analysis , volume=. 2012 , publisher=
2012
-
[5]
Numerische Mathematik , volume=
On non-ergodic convergence rate of Douglas--Rachford alternating direction method of multipliers , author=. Numerische Mathematik , volume=. 2015 , publisher=
2015
-
[6]
Understanding the
Li, Bowen and Shi, Bin , journal=. Understanding the
-
[7]
Foundations and Trends
Stephen Boyd and Neal Parikh and Eric Chu and Borja Peleato and Jonathan Eckstein , title =. Foundations and Trends
-
[8]
Paige, C. C. and Saunders, M. A. , title =. SIAM Journal on Numerical Analysis , volume =
-
[9]
and Schultz, M
Saad, Y. and Schultz, M. H. , title =. SIAM Journal on Scientific and Statistical Computing , volume =
-
[10]
and Liesen, J
Benzi, Michele and Golub, Gene H. and Liesen, J. A Preconditioner for Generalized Saddle Point Problems , journal =
-
[11]
Trefethen, L. N. and Embree, M. , title =
-
[12]
and Marroco, A
Glowinski, R. and Marroco, A. , title =. Revue fran
-
[13]
and Du, S
Shi, B. and Du, S. S. and Jordan, M. I. and Su, W. J. , title =. Mathematical Programming , volume =
-
[14]
Foundations of Computational Mathematics , volume=
Fast Optimistic Gradient Descent Ascent (OGDA) method in continuous and discrete time , author=. Foundations of Computational Mathematics , volume=. 2025 , publisher=
2025
-
[15]
1998 , publisher=
Variational analysis , author=. 1998 , publisher=
1998
-
[16]
International conference on machine learning , pages=
Accelerated algorithms for smooth convex-concave minimax problems with O (1/k^2) rate on squared gradient norm , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[17]
Mathematical Programming , series =
Yuyuan Ouyang and Yangyang Xu , title =. Mathematical Programming , series =
-
[18]
SIAM Journal on Control and Optimization , volume=
An augmented Lagrangian method for identifying discontinuous parameters in elliptic systems , author=. SIAM Journal on Control and Optimization , volume=. 1999 , publisher=
1999
-
[19]
2014 , publisher=
Finite elements and fast iterative solvers: with applications in incompressible fluid dynamics , author=. 2014 , publisher=
2014
-
[20]
A Lyapunov Analysis of Accelerated
Zeng, Xueying and Shi, Bin , journal=. A Lyapunov Analysis of Accelerated. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.