LASA: A Weak Supervision Method for Open-Vocabulary Scene Sketch Semantic Segmentation
Pith reviewed 2026-06-27 10:38 UTC · model grok-4.3
The pith
Aggregating multi-layer attention maps yields a robust prior for weakly supervised open-vocabulary sketch segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
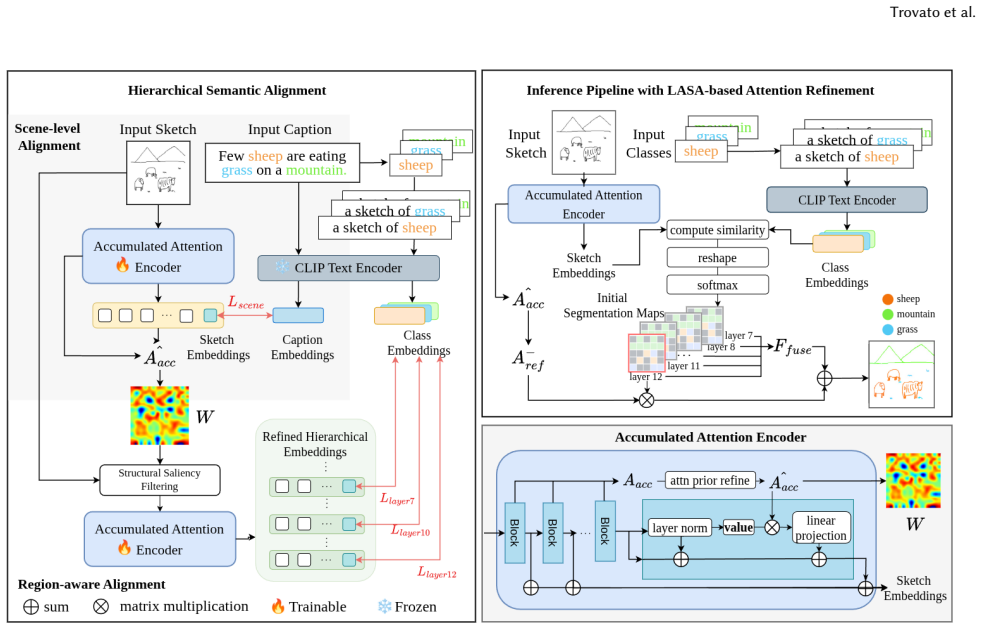
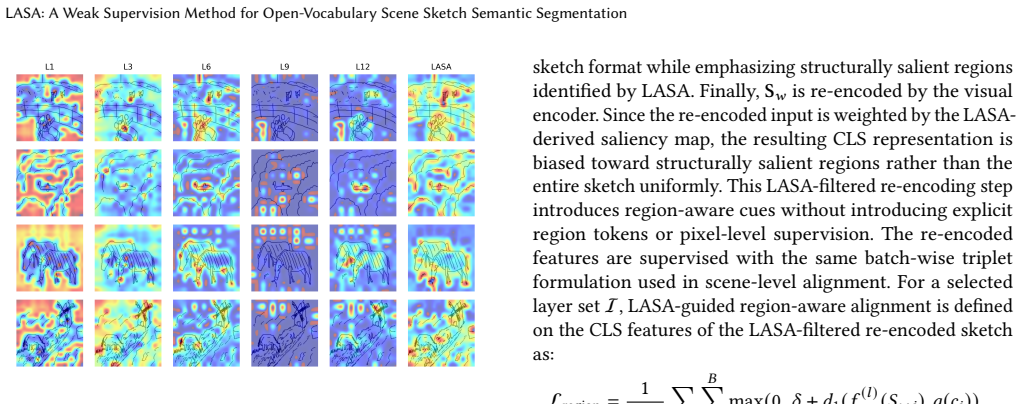
LASA aggregates attention maps across Vision Transformer layers so that shallow-layer global layouts and deep-layer local stroke details together guide hierarchical semantic alignment, producing refined segmentation predictions under weak supervision for open-vocabulary scene sketches.
What carries the argument
LASA (Layer-wise Accumulated Structural Attention), the aggregation of multi-layer attention maps that serves as the structural prior for semantic alignment.
If this is right
- Produces mIoU gains of +3.43 on FS-COCO, +8.01 on SFSD, and +15.74 on FrISS over previous weak baselines.
- Delivers segmentations with greater spatial coherence.
- Supports open-vocabulary inference without retraining for new category sets.
- Operates effectively with only weak supervision signals during training.
Where Pith is reading between the lines
- The aggregation principle may transfer to segmentation of other line-based inputs such as flowcharts or architectural drawings.
- Future work could examine whether the same complementary-cue logic applies when adapting large vision models to other annotation-scarce domains.
- Performance might further improve by weighting the layers according to dataset-specific stroke characteristics.
Load-bearing premise
Different Vision Transformer layers capture complementary spatial information in their attention maps that can be combined for better results than using any one layer.
What would settle it
If a baseline that relies on attention from only one fixed ViT layer matches or exceeds LASA's mIoU scores on FS-COCO, SFSD, and FrISS, the benefit of layer-wise accumulation would be called into question.
Figures



read the original abstract
Open-vocabulary scene sketch semantic segmentation aims to assign dense semantic labels to sparse line drawings based on flexible category vocabularies specified at inference time, without relying on pixel-level annotations during training. Unlike natural images, sketches lack texture and color cues, making semantic understanding heavily dependent on stroke layout and spatial configuration, a challenge that renders single-layer vision-language features inherently unstable. Our key observation is that attention maps from different Vision Transformer layers encode complementary spatial cues: shallow layers capture global structural layouts, while deeper layers focus on local stroke intersections and object parts. This suggests that cross-layer aggregation provides a more robust structural prior than any individual layer alone. Leveraging this insight, we propose a structure-aware framework built upon \textbf{L}ayer-wise \textbf{A}ccumulated \textbf{S}tructural \textbf{A}ttention (\textbf{LASA}), which aggregates multi-layer attention to guide hierarchical semantic alignment under weak supervision and refine predictions during inference. Experiments on FS-COCO, SFSD, and FrISS show that LASA improves mIoU by $+3.43$, $+8.01$, and $+15.74$ over the prior weakly supervised baselines, demonstrating consistent gains in both segmentation accuracy and spatial coherence. Our source code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LASA (Layer-wise Accumulated Structural Attention), a weak-supervision framework for open-vocabulary scene sketch semantic segmentation. It observes that attention maps from different ViT layers provide complementary cues (shallow layers for global layout, deeper for local stroke intersections) and aggregates them to guide hierarchical semantic alignment, reporting mIoU gains of +3.43, +8.01, and +15.74 over prior baselines on FS-COCO, SFSD, and FrISS.
Significance. If the empirical gains hold under rigorous evaluation, the work would offer a practical way to stabilize structural priors for sketch segmentation by exploiting multi-layer ViT attention, a domain where texture absence makes single-layer features unstable. The planned public code release supports reproducibility.
major comments (1)
- [Abstract] Abstract: the central empirical claims (mIoU improvements of +3.43/+8.01/+15.74) are stated without any description of experimental protocol, baseline re-implementations, training details, statistical significance testing, or potential dataset-specific confounds, rendering the soundness of the performance claims impossible to assess from the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recommendation for major revision. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (mIoU improvements of +3.43/+8.01/+15.74) are stated without any description of experimental protocol, baseline re-implementations, training details, statistical significance testing, or potential dataset-specific confounds, rendering the soundness of the performance claims impossible to assess from the provided text.
Authors: We agree that the abstract, by design, is concise and does not detail the experimental protocol, baseline implementations, training procedures, or statistical tests. These elements are fully described in Section 4 (Experiments) and the supplementary material, including re-implementations of prior weakly-supervised baselines on FS-COCO, SFSD, and FrISS, along with discussion of sketch-specific challenges (absence of texture/color) that motivate the multi-layer attention approach. We did not perform or report statistical significance testing in the current version. To address the concern, we will revise the abstract to add a brief clause such as "under standard weakly-supervised evaluation protocols on three benchmarks" while respecting length constraints, and we will incorporate statistical significance results in the revised manuscript body if feasible. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents an empirical framework (LASA) based on the stated observation that multi-layer ViT attention maps provide complementary cues for sketch segmentation. It reports mIoU gains on three datasets as experimental outcomes. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any claimed result to an input by construction. The central claims remain externally falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention maps from different Vision Transformer layers encode complementary spatial cues (shallow layers for global layouts, deeper for local intersections).
invented entities (1)
-
LASA (Layer-wise Accumulated Structural Attention)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Samira Abnar and Willem Zuidema. 2020. Quantifying attention flow in transformers. InProceedings of the 58th annual meeting of the association for computational linguistics. 4190–4197
2020
-
[2]
Luca Barsellotti, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2024. Training-free open-vocabulary segmenta- tion with offline diffusion-augmented prototype generation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3689–3698
2024
-
[3]
Ahmed Bourouis, Judith E Fan, and Yulia Gryaditskaya. 2024. Open vocabulary semantic scene sketch understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4176–4186
2024
-
[4]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging prop- erties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision. 9650–9660
2021
-
[5]
Xi Chen, Shuang Li, Ser-Nam Lim, Antonio Torralba, and Hengshuang Zhao. 2023. Open-vocabulary panoptic segmentation with embedding modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1141–1150
2023
-
[6]
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. 2024. Cat-seg: Cost aggre- gation for open-vocabulary semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4113–4123
2024
-
[7]
Pinaki Nath Chowdhury, Aneeshan Sain, Ayan Kumar Bhunia, Tao Xiang, Yulia Gryaditskaya, and Yi-Zhe Song. 2022. Fs-coco: Towards understanding of freehand sketches of common objects in context. In European conference on computer vision. Springer, 253–270
2022
-
[8]
Sounak Dey, Pau Riba, Anjan Dutta, Josep Llados, and Yi-Zhe Song
-
[9]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Doodle to search: Practical zero-shot sketch-based image re- trieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2179–2188
- [10]
-
[11]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al . 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
Mathias Eitz, James Hays, and Marc Alexa. 2012. How do humans sketch objects?ACM Transactions on graphics (TOG)31, 4 (2012), 1–10
2012
-
[13]
Chengying Gao, Qi Liu, Qi Xu, Limin Wang, Jianzhuang Liu, and Changqing Zou. 2020. Sketchycoco: Image generation from freehand scene sketches. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5174–5183
2020
-
[14]
Ce Ge, Haifeng Sun, Yi-Zhe Song, Zhanyu Ma, and Jianxin Liao. 2022. Exploring local detail perception for scene sketch semantic segmenta- tion.IEEE Transactions on Image Processing31 (2022), 1447–1461
2022
-
[15]
Wenbin He, Suphanut Jamonnak, Liang Gou, and Liu Ren. 2023. Clip- s4: Language-guided self-supervised semantic segmentation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11207–11216
2023
-
[16]
Zhe Huang, Hongbo Fu, and Rynson WH Lau. 2014. Data-driven segmentation and labeling of freehand sketches.ACM Transactions on Graphics (TOG)33, 6 (2014), 1–10
2014
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rol- land, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. 2023. Segment Anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4015–4026
2023
-
[18]
Aleyna Kütük and Tevfik Metin Sezgin. 2025. Class-agnostic visio- temporal scene sketch semantic segmentation. In2025 IEEE/CVF Win- ter Conference on Applications of Computer Vision (W ACV). IEEE, 8444– 8453
2025
-
[19]
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. 2024. Proxyclip: Proxy attention improves clip for open-vocabulary segmentation. InEuropean Conference on Computer Vision. Springer, 70–88
2024
-
[20]
Minhyeok Lee, Suhwan Cho, Jungho Lee, Sunghun Yang, Heeseung Choi, Ig-Jae Kim, and Sangyoun Lee. 2025. Effective SAM combination for open-vocabulary semantic segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference. 26081–26090
2025
-
[21]
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. 2022. Language-driven semantic segmentation.arXiv preprint arXiv:2201.03546
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. 2023. Open- vocabulary semantic segmentation with mask-adapted clip. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7061–7070
2023
-
[23]
Yuqi Lin, Minghao Chen, Wenxiao Wang, Boxi Wu, Ke Li, Binbin Lin, Haifeng Liu, and Xiaofei He. 2023. Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15305–15314
2023
-
[24]
Li Liu, Fumin Shen, Yuming Shen, Xianglong Liu, and Ling Shao. 2017. Deep sketch hashing: Fast free-hand sketch-based image retrieval. InProceedings of the IEEE conference on computer vision and pattern recognition. 2862–2871
2017
-
[25]
Yong Liu, Sule Bai, Guanbin Li, Yitong Wang, and Yansong Tang. 2024. Open-vocabulary segmentation with semantic-assisted calibration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3491–3500
2024
-
[26]
Yong Liu, Song-Li Wu, Sule Bai, Jiahao Wang, Yitong Wang, and Yansong Tang. 2025. Stepping out of similar semantic space for open- vocabulary segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22664–22674
2025
-
[27]
Jiayun Luo, Siddhesh Khandelwal, Leonid Sigal, and Boyang Li. 2024. Emergent open-vocabulary semantic segmentation from off-the-shelf vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4029–4040
2024
-
[28]
Jishnu Mukhoti, Tsung-Yu Lin, Omid Poursaeed, Rui Wang, Ashish Shah, Philip HS Torr, and Ser-Nam Lim. 2023. Open vocabulary se- mantic segmentation with patch aligned contrastive learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19413–19423
2023
-
[29]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Jie Qin, Jie Wu, Pengxiang Yan, Ming Li, Ren Yuxi, Xuefeng Xiao, Yitong Wang, Rui Wang, Shilei Wen, Xin Pan, et al . 2023. Freeseg: Unified, universal and open-vocabulary image segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19446–19455
2023
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al . 2021. Learning transferable visual mod- els from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[32]
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. 2022. Denseclip: Language- guided dense prediction with context-aware prompting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. LASA: A Weak Supervision Method for Open-Vocabulary Scene Sketch Semantic Segmentation ...
2022
-
[33]
Patsorn Sangkloy, Nathan Burnell, Cusuh Ham, and James Hays. 2016. The sketchy database: learning to retrieve badly drawn bunnies.Acm Transactions on Graphics (TOG)35, 4 (2016), 1–12
2016
-
[34]
Xiangheng Shan, Dongyue Wu, Guilin Zhu, Yuanjie Shao, Nong Sang, and Changxin Gao. 2024. Open-vocabulary semantic segmentation with image embedding balancing. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. 28412–28421
2024
-
[35]
Jifei Song, Qian Yu, Yi-Zhe Song, Tao Xiang, and Timothy M Hospedales. 2017. Deep spatial-semantic attention for fine-grained sketch-based image retrieval. InProceedings of the IEEE international conference on computer vision. 5551–5560
2017
-
[36]
Vladan Stojnić, Yannis Kalantidis, Jiří Matas, and Giorgos Tolias. 2025. Lposs: Label propagation over patches and pixels for open-vocabulary semantic segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference. 9794–9803
2025
-
[37]
Lin Sun, Jiale Cao, Jin Xie, Xiaoheng Jiang, and Yanwei Pang
-
[38]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Cliper: Hierarchically improving spatial representation of clip for open-vocabulary semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 23199–23209
-
[39]
Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, and Maneesh Agrawala. 2025. Instance Segmentation of Scene Sketches Using Natural Image Priors. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers ’25). Association for Computing Machinery. doi:10.1145/3721238.3730606
-
[40]
Osman Ülger, Maksymilian Kulicki, Yuki Asano, and Martin R. Oswald
-
[41]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Auto-vocabulary semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 24266–24275
-
[42]
Yangtao Wang, Xi Shen, Shell Xu Hu, Yuan Yuan, James L Crowley, and Dominique Vaufreydaz. 2022. Self-supervised transformers for unsupervised object discovery using normalized cut. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14543–14553
2022
-
[43]
Bin Xie, Jiale Cao, Jin Xie, Fahad Shahbaz Khan, and Yanwei Pang
-
[44]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sed: A simple encoder-decoder for open-vocabulary semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3426–3436
-
[45]
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. 2022. Groupvit: Semantic segmenta- tion emerges from text supervision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18134–18144
2022
-
[46]
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, and Shalini De Mello. 2023. Open-vocabulary panoptic segmentation with text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2955–2966
2023
-
[47]
Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xiang Bai. 2023. Side adapter network for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2945–2954
2023
-
[48]
Jie Yang, Aihua Ke, Yaoxiang Yu, and Bo Cai. 2023. Scene sketch semantic segmentation with hierarchical transformer.Knowledge- Based Systems280 (2023), 110962
2023
-
[49]
Qian Yu, Feng Liu, Yi-Zhe Song, Tao Xiang, Timothy M Hospedales, and Chen-Change Loy. 2016. Sketch me that shoe. InProceedings of the IEEE conference on computer vision and pattern recognition. 799–807
2016
-
[50]
Qian Yu, Yongxin Yang, Feng Liu, Yi-Zhe Song, Tao Xiang, and Timo- thy M Hospedales. 2017. Sketch-a-net: A deep neural network that beats humans.International journal of computer vision122, 3 (2017), 411–425
2017
-
[51]
Haobo Yuan, Xiangtai Li, Chong Zhou, Yining Li, Kai Chen, and Chen Change Loy. 2024. Open-vocabulary sam: Segment and rec- ognize twenty-thousand classes interactively. InEuropean Conference on Computer Vision. Springer, 419–437
2024
-
[52]
Bingfeng Zhang, Siyue Yu, Yunchao Wei, Yao Zhao, and Jimin Xiao
-
[53]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Frozen clip: A strong backbone for weakly supervised semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3796–3806
-
[54]
Dengke Zhang, Fagui Liu, and Quan Tang. 2025. Corrclip: Recon- structing patch correlations in clip for open-vocabulary semantic segmentation. (2025), 24677–24687
2025
-
[55]
Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianwei Yang, and Lei Zhang. 2023. A simple framework for open-vocabulary segmentation and detection. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. 1020–1031
2023
-
[56]
Jianhui Zhang, Yilan Chen, Lei Li, Hongbo Fu, and Chiew-Lan Tai
-
[57]
InProceedings of the Joint Symposium on Computational Aesthetics and Sketch-Based Interfaces and Modeling and Non-Photorealistic Animation and Rendering
Context-based sketch classification. InProceedings of the Joint Symposium on Computational Aesthetics and Sketch-Based Interfaces and Modeling and Non-Photorealistic Animation and Rendering. 1–10
-
[58]
Zhengming Zhang, Xiaoming Deng, Jinyao Li, Yukun Lai, Cuixia Ma, Yongjin Liu, and Hongan Wang. 2023. Stroke-based semantic segmentation for scene-level free-hand sketches.The Visual Computer 39, 12 (2023), 6309–6321
2023
-
[59]
Yixiao Zheng, Jiyang Xie, Aneeshan Sain, Yi-Zhe Song, and Zhanyu Ma. 2023. Sketch-segformer: Transformer-based segmentation for figurative and creative sketches.IEEE transactions on image processing 32 (2023), 4595–4609
2023
-
[60]
Ziqin Zhou, Yinjie Lei, Bowen Zhang, Lingqiao Liu, and Yifan Liu. 2023. Zegclip: Towards adapting clip for zero-shot semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11175–11185
2023
-
[61]
Changqing Zou, Qian Yu, Ruofei Du, Haoran Mo, Yi-Zhe Song, Tao Xiang, Chengying Gao, Baoquan Chen, and Hao Zhang. 2018. Sketchyscene: Richly-annotated scene sketches. InProceedings of the european conference on computer vision (ECCV). 421–436
2018
-
[62]
Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, et al . 2023. Generalized decoding for pixel, image, and language. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15116–15127
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.