Vision Transformers for Face Recognition Need More Registers
Pith reviewed 2026-06-27 09:45 UTC · model grok-4.3
The pith
Register tokens added to CPE-based Vision Transformers reduce attention artifacts and reach state-of-the-art face recognition accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
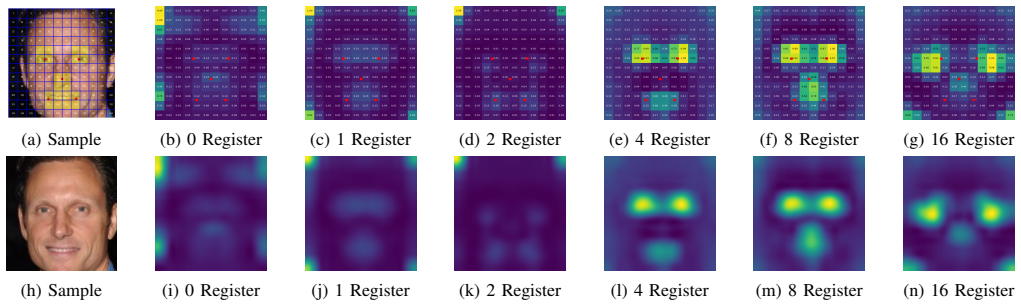
Incorporating register tokens into CPE-based ViT architectures for face recognition mitigates attention artifacts observed in baseline models, with eight registers delivering the highest verification accuracies on IJB-B and IJB-C and substantially clearer attention maps compared to the baseline CPE model.
What carries the argument
Register tokens: learnable tokens concatenated to the initial patch embeddings and processed jointly through the ViT encoder blocks.
If this is right
- Adding four or eight registers significantly enhances interpretability of attention maps.
- Eight registers provide the highest verification accuracies and smoothest attention structures.
- The ViT-8R model achieves state-of-the-art performance among ViT-based FR models on IJB-B and IJB-C.
- Artifacts appear consistently across small and large ViT backbones and are mitigated by registers.
Where Pith is reading between the lines
- The register token method could be tested on other ViT tasks where attention interpretability matters, such as object detection.
- The optimal number of registers may depend on input complexity, suggesting experiments with different counts per domain.
- Clearer attention maps could aid in diagnosing biases within face recognition systems without extra post-processing.
Load-bearing premise
The accuracy gains and artifact reductions are caused by the register tokens rather than by any unstated differences in training procedure, augmentation, or hyperparameters.
What would settle it
Retrain the baseline CPE model using the exact same training procedure, data augmentation, and hyperparameters as the eight-register version, then check whether the attention artifacts remain at similar levels.
Figures





read the original abstract
Recent advances in Vision Transformers (ViTs) for face recognition (FR) have moved beyond the standard CLS-token paradigm. In this paradigm, a special classification token (CLS) is prepended to the patch embeddings and used as a representation of the input for downstream tasks. An alternative approach, Concatenated Patch Embeddings (CPE), instead leverages all patch tokens by concatenating them into a single vector, which is then projected into a compact face representation. CPE has been shown to improve recognition performance in comparison to CLS-based ones, but our qualitative analysis of attention maps showed the presence of artifacts that limit their interpretability. To address this issue, we incorporate register tokens, learnable tokens concatenated to the initial patch embeddings, and processed jointly through the ViT encoder blocks. This mechanism has been shown to produce more structured and interpretable attention maps compared to baseline ViT. We empirically demonstrate that these artifacts consistently appear across various ViT backbones, including small and large models, and that introducing register tokens effectively mitigates them. Adding four or eight registers significantly enhances interpretability, with eight registers providing the highest verification accuracies and smoothest attention structures. Our resulting model, ViT-8R, corresponds to a CPE-based ViT-B architecture augmented with eight register tokens achieves state-of-the-art performance among ViT-based FR models on large-scale IJB-B and IJB-C benchmarks. Also, ViT-8R produces substantially clearer attention maps compared with the baseline model, which offer deeper insight into the model's attention behavior (https://github.com/TaharChettaoui/ViT-FR-Registers)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adding learnable register tokens to Concatenated Patch Embeddings (CPE) Vision Transformers for face recognition to reduce attention artifacts and boost performance. It reports that 4–8 registers yield clearer attention maps across backbones and that the resulting ViT-8R (CPE ViT-B + 8 registers) achieves state-of-the-art verification accuracy among ViT-based models on the large-scale IJB-B and IJB-C benchmarks, with code released at the provided GitHub repository.
Significance. If the accuracy gains and artifact reduction are causally due to the registers, the work supplies a lightweight architectural change that simultaneously improves accuracy and interpretability for ViT-based face recognition; the public code release is a concrete strength that supports reproducibility.
major comments (2)
- [Experimental protocol / results comparison] The central empirical claim (abstract and results) that ViT-8R outperforms the CPE baseline and reaches SOTA rests on the assumption that the two models share identical training details (optimizer, learning-rate schedule, data augmentation, loss, and initialization). No explicit statement, table, or section confirms this matching; without it the performance delta cannot be attributed to the register tokens alone.
- [Attention map analysis] The qualitative claim that registers 'effectively mitigate' artifacts 'consistently across various ViT backbones' is load-bearing for the interpretability contribution, yet the manuscript provides no quantitative metric (e.g., attention entropy or artifact count) to support the visual examples; the improvement therefore remains qualitative only.
minor comments (1)
- [Abstract] The abstract states 'ViT-8R ... achieves state-of-the-art performance' but does not list the exact competing ViT-based methods or their scores; a compact comparison table would strengthen the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Experimental protocol / results comparison] The central empirical claim (abstract and results) that ViT-8R outperforms the CPE baseline and reaches SOTA rests on the assumption that the two models share identical training details (optimizer, learning-rate schedule, data augmentation, loss, and initialization). No explicit statement, table, or section confirms this matching; without it the performance delta cannot be attributed to the register tokens alone.
Authors: We agree that an explicit confirmation of identical training protocols is required to attribute performance differences to the register tokens. All models in our experiments were trained with the same optimizer, learning-rate schedule, data augmentations, loss function, and initialization, with the sole difference being the addition of register tokens. In the revised manuscript we will add a dedicated paragraph in the Experimental Setup section that states this matching explicitly, along with a table summarizing the shared hyperparameters. revision: yes
-
Referee: [Attention map analysis] The qualitative claim that registers 'effectively mitigate' artifacts 'consistently across various ViT backbones' is load-bearing for the interpretability contribution, yet the manuscript provides no quantitative metric (e.g., attention entropy or artifact count) to support the visual examples; the improvement therefore remains qualitative only.
Authors: We acknowledge that the attention-map analysis is currently supported only by qualitative examples. While the visual results show consistent artifact reduction, we agree a quantitative metric would strengthen the claim. In the revision we will add a quantitative evaluation (e.g., mean attention entropy or a systematic count of artifact regions) computed on held-out images to complement the qualitative figures. revision: yes
Circularity Check
No circularity; purely empirical evaluation on public benchmarks
full rationale
The paper reports experimental results from training CPE-based ViT models augmented with register tokens and measuring verification accuracy plus attention-map quality on IJB-B and IJB-C. No derivation, equation, or prediction is presented that reduces by construction to a fitted parameter or self-citation chain defined inside the work. All central claims rest on externally falsifiable benchmark numbers and qualitative visualizations whose validity does not depend on any internal redefinition of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of register tokens =
8
axioms (1)
- domain assumption Register tokens produce more structured and interpretable attention maps in Vision Transformers
Reference graph
Works this paper leans on
-
[1]
Alansari, O
M. Alansari, O. A. Hay, S. Javed, A. Shoufan, Y . H. Zweiri, and N. Werghi. Ghostfacenets: Lightweight face recognition model from cheap operations.IEEE Access, 11:35429–35446, 2023
2023
-
[2]
X. An, X. Zhu, Y . Gao, Y . Xiao, Y . Zhao, Z. Feng, L. Wu, B. Qin, M. Zhang, D. Zhang, and Y . Fu. Partial FC: training 10 million identities on a single machine. InICCVW, pages 1445–1449. IEEE, 2021
2021
-
[3]
Boutros, N
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper. Elasticface: Elastic margin loss for deep face recognition. InCVPR Workshops, pages 1577–1586. IEEE, 2022
2022
-
[4]
Boutros, P
F. Boutros, P. Siebke, M. Klemt, N. Damer, F. Kirchbuchner, and A. Kuijper. Pocketnet: Extreme lightweight face recognition network using neural architecture search and multistep knowledge distillation. IEEE Access, 10:46823–46833, 2022
2022
-
[5]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision trans- formers. InICCV, pages 9630–9640. IEEE, 2021
2021
-
[6]
C. R. Chen, Q. Fan, and R. Panda. Crossvit: Cross-attention multi- scale vision transformer for image classification. InICCV, pages 347–
-
[7]
S. Chen, Y . Liu, X. Gao, and Z. Han. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. InCCBR, volume 10996 ofLecture Notes in Computer Science, pages 428–438. Springer, 2018
2018
-
[8]
Chettaoui, N
T. Chettaoui, N. Damer, and F. Boutros. Froundation: Are foundation models ready for face recognition?Image Vis. Comput., 156:105453, 2025
2025
-
[9]
E. D. Cubuk, B. Zoph, J. Shlens, and Q. V . Le. Randaugment: Practical automated data augmentation with a reduced search space. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, June 14-19, 2020, pages 3008–3017. Computer Vision Foundation / IEEE, 2020
2020
-
[10]
J. Dan, Y . Liu, B. Sun, J. Deng, and S. Luo. Transface++: Rethinking the face recognition paradigm with a focus on accuracy, efficiency, and security.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–18, 2025
2025
-
[11]
J. Dan, Y . Liu, H. Xie, J. Deng, H. Xie, X. Xie, and B. Sun. Transface: Calibrating transformer training for face recognition from a data- centric perspective. InICCV, pages 20585–20596. IEEE, 2023
2023
-
[12]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transform- ers need registers. InICLR. OpenReview.net, 2024
2024
-
[13]
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. InCVPR, pages 5202–5211. Computer Vision Foundation / IEEE, 2020
2020
-
[14]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, pages 4690–4699. Computer Vision Foundation / IEEE, 2019
2019
-
[15]
J. Deng, J. Guo, J. Yang, A. Lattas, and S. Zafeiriou. Variational prototype learning for deep face recognition. InCVPR, pages 11906– 11915. Computer Vision Foundation / IEEE, 2021
2021
-
[16]
J. Deng, J. Guo, J. Yang, N. Xue, I. Kotsia, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):5962–5979, Oct. 2022
2022
-
[17]
J. Deng, J. Guo, D. Zhang, Y . Deng, X. Lu, and S. Shi. Lightweight face recognition challenge. InICCV Workshops, pages 2638–2646. IEEE, 2019
2019
-
[18]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Trans- formers for image recognition at scale. InICLR. OpenReview.net, 2021
2021
-
[19]
Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors,Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III, volume 9907 ofLecture Notes in Computer Science, pages 8...
2016
-
[20]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InCVPR, pages 770–778. IEEE Computer Society, 2016
2016
- [21]
-
[22]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. InICLR. OpenReview.net, 2022
2022
-
[23]
G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller. Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments. InWorkshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, Oct. 2008. Erik Learned-Miller and Andras Ferencz and Fr´ed´eric Jurie
2008
-
[24]
Huang, Y
Y . Huang, Y . Wang, Y . Tai, X. Liu, P. Shen, S. Li, J. Li, and F. Huang. Curricularface: Adaptive curriculum learning loss for deep face recognition. InCVPR, pages 5900–5909. Computer Vision Foundation / IEEE, 2020
2020
-
[25]
Islam, M
K. Islam, M. Z. Zaheer, and A. Mahmood. Face pyramid vision transformer. InBMVC, page 758. BMV A Press, 2022
2022
-
[26]
Jain and B
S. Jain and B. C. Wallace. Attention is not explanation. InNAACL- HLT (1), pages 3543–3556. Association for Computational Linguistics, 2019
2019
-
[27]
M. Khan, M. Saeed, A. El-Saddik, and W. Gueaieb. Artrivit: Auto- matic face recognition system using vit-based siamese neural networks with a triplet loss. InISIE, pages 1–6. IEEE, 2023
2023
-
[28]
M. Kim, A. K. Jain, and X. Liu. Adaface: Quality adaptive margin for face recognition. InCVPR, pages 18729–18738. IEEE, 2022
2022
-
[29]
M. Kim, Y . Su, F. Liu, A. Jain, and X. Liu. Keypoint relative position encoding for face recognition. InCVPR, pages 244–255. IEEE, 2024
2024
-
[30]
Y . Kim, W. Park, and J. Shin. Broadface: Looking at tens of thousands of people at once for face recognition. InECCV (9), volume 12354 of Lecture Notes in Computer Science, pages 536–552. Springer, 2020
2020
-
[31]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR (Poster). OpenReview.net, 2019
2019
-
[32]
B. Maze, J. C. Adams, J. A. Duncan, N. D. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, and P. Grother. IARPA janus benchmark - C: face dataset and protocol. InICB, pages 158–165. IEEE, 2018
2018
-
[33]
Q. Meng, S. Zhao, Z. Huang, and F. Zhou. Magface: A universal representation for face recognition and quality assessment. InCVPR, pages 14225–14234. Computer Vision Foundation / IEEE, 2021
2021
-
[34]
Mishra and K
P. Mishra and K. Sarawadekar. Polynomial learning rate policy with warm restart for deep neural network. InTENCON, pages 2087–2092. IEEE, 2019
2087
-
[35]
Moschoglou, A
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. Agedb: the first manually collected, in-the-wild age database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, volume 2, page 5, 2017
2017
-
[36]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. As- sran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. J ´egou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without supe...
2024
- [37]
-
[38]
L. Qin, M. Wang, C. Deng, K. Wang, X. Chen, J. Hu, and W. Deng. Swinface: A multi-task transformer for face recognition, expression recognition, age estimation and attribute estimation.IEEE Trans. Circuits Syst. Video Technol., 34(4):2223–2234, 2024
2024
-
[39]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, volume 139 ofProceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021
2021
-
[40]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InKDD, pages 3505–3506. ACM, 2020
2020
-
[41]
Sengupta, J
S. Sengupta, J. Chen, C. Castillo, V . Patel, R. Chellappa, and D. Ja- cobs. Frontal to profile face verification in the wild. In2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, 2016 IEEE Winter Conference on Applications of Computer Vision, W ACV 2016. Institute of Electrical and Electronics Engineers Inc., May 2016. Publisher C...
2016
-
[42]
Y . Shi, X. Yu, K. Sohn, M. Chandraker, and A. K. Jain. Towards universal representation learning for deep face recognition. InCVPR, pages 6816–6825. Computer Vision Foundation / IEEE, 2020
2020
-
[43]
Sun and G
Z. Sun and G. Tzimiropoulos. Part-based face recognition with vision transformers. InBMVC, page 611. BMV A Press, 2022
2022
-
[44]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.CoRR, abs/1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. InCVPR, pages 5265–5274. Computer Vision Foundation / IEEE Computer Society, 2018
2018
-
[47]
Whitelam, E
C. Whitelam, E. Taborsky, A. Blanton, B. Maze, J. C. Adams, T. Miller, N. D. Kalka, A. K. Jain, J. A. Duncan, K. Allen, J. Cheney, and P. Grother. IARPA janus benchmark-b face dataset. InCVPR Workshops, pages 592–600. IEEE Computer Society, 2017
2017
-
[48]
Zheng and W
T. Zheng and W. Deng. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications, February 2018
2018
-
[49]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu. Cross-age LFW: A database for studying cross-age face recognition in unconstrained environments. CoRR, abs/1708.08197, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Y . Zhong and W. Deng. Face transformer for recognition.CoRR, abs/2103.14803, 2021
-
[51]
Z. Zhu, G. Huang, J. Deng, Y . Ye, J. Huang, X. Chen, J. Zhu, T. Yang, J. Lu, D. Du, and J. Zhou. Webface260m: A benchmark unveiling the power of million-scale deep face recognition. InCVPR, pages 10492– 10502. Computer Vision Foundation / IEEE, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.