FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
Pith reviewed 2026-06-27 09:59 UTC · model grok-4.3
The pith
A shortcut-aware synthesis framework produces training tasks that force genuine deep search, enabling top benchmark performance via supervised fine-tuning alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
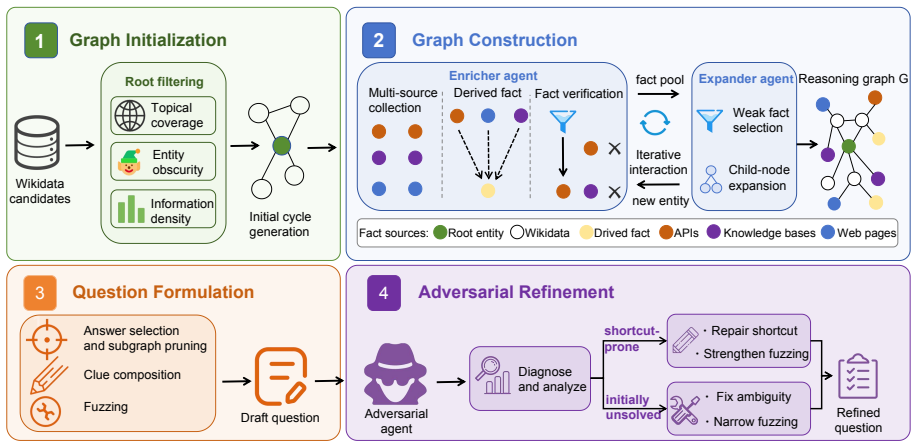
The FORT Framework of Shortcut-Resistant Training-Data Synthesis constructs training tasks by explicitly managing four shortcut risks across entity selection, evidence graph construction, question formulation, and adversarial refinement. When trajectories from these tasks are used for supervised fine-tuning, the resulting FORT-Searcher model achieves the best overall performance among comparable-size open-source search agents on challenging deep search benchmarks while exhibiting longer pre-answer search and fewer shortcut patterns than models trained on prior datasets.
What carries the argument
The FORT Framework of Shortcut-Resistant Training-Data Synthesis, which controls four shortcut risks at each stage of data creation to ensure realized search difficulty matches intended difficulty.
If this is right
- FORT-synthesized tasks produce trajectories with measurably longer pre-answer search segments than existing open-source deep search datasets.
- Models trained on FORT trajectories display lower prior-shortcut rates and answer-hit times that align with full evidence traversal.
- Supervised fine-tuning alone on FORT data is sufficient to reach the highest scores among open-source agents of similar size on deep search benchmarks.
- The same synthesis pipeline can be applied to generate additional training sets without requiring reinforcement learning stages.
Where Pith is reading between the lines
- The trajectory-signature diagnostics could be turned into an automated filter for auditing and cleaning existing search datasets.
- Search-agent evaluations may need to include explicit shortcut-blocking variants to confirm that high scores reflect genuine capability.
- The stage-wise risk control approach could transfer to other agent training domains where cheap reasoning paths undermine intended difficulty.
Load-bearing premise
That controlling the four named shortcut risks and checking the listed trajectory signatures is enough to remove all shortcuts so that benchmark gains reflect actual search skill.
What would settle it
A test showing that FORT-Searcher performance collapses to average levels once all four shortcut types are explicitly blocked in the evaluation benchmarks.
Figures







read the original abstract
Training deep search agents requires verifiable questions whose answers remain unavailable until sufficient evidence has been acquired through search. Existing synthesis methods often increase apparent difficulty by enriching graph structures, but structural complexity alone does not guarantee realized search difficulty: the intended search process can collapse through a cheaper identifying route. We formalize this gap with a shortcut-aware difficulty framework and identify four actionable shortcut risks: evidence co-coverage, single-clue selectivity, exposed constants, and prior-knowledge binding. To diagnose their realized effects, we use trajectory signatures including solving cost, answer hit time, and prior-shortcut rate. Guided by this framework, we introduce FORT, a Framework of Shortcut-Resistant Training-Data Synthesis. FORT constructs shortcut-resistant training data by controlling shortcut risks across entity selection, evidence graph construction, question formulation, and adversarial refinement. Experiments show that FORT induces longer pre-answer search and fewer shortcut patterns than existing open-source deep search datasets. Using the resulting trajectories, we train FORT-Searcher with supervised fine-tuning (SFT) only, and it achieves the best overall performance among comparable-size open-source search agents on challenging deep search benchmarks. Relevant resources will be made available at https://github.com/RUCAIBox/FORT-Searcher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FORT, a Framework of Shortcut-Resistant Training-Data Synthesis for deep search agents. It formalizes four shortcut risks (evidence co-coverage, single-clue selectivity, exposed constants, prior-knowledge binding) and three trajectory signatures (solving cost, answer hit time, prior-shortcut rate) to diagnose when structural complexity fails to produce realized search difficulty. FORT controls these risks during entity selection, evidence graph construction, question formulation, and adversarial refinement. Experiments show FORT data yields longer pre-answer search and fewer shortcut patterns than prior open-source datasets; SFT on the resulting trajectories produces FORT-Searcher, which reports the best overall performance among comparable-size open-source agents on challenging deep search benchmarks.
Significance. If the shortcut-resistance properties transfer to benchmark evaluation without residual exploitation, the work supplies a concrete, controllable method for generating training data that forces genuine multi-step evidence acquisition. This could reduce reliance on post-hoc filtering or larger models to compensate for dataset artifacts in search-agent training.
major comments (2)
- [Experiments] Experiments section: the trajectory signatures (solving cost, answer hit time, prior-shortcut rate) and shortcut-risk reductions are reported exclusively for the FORT synthesis process and the training trajectories; no equivalent analysis is provided for FORT-Searcher outputs on the evaluation benchmarks. Because the central claim equates benchmark gains with genuine search improvement rather than undetected shortcuts, the absence of these diagnostics on the test distributions is load-bearing.
- [Experiments] Experiments section and Table reporting benchmark results: baseline comparisons and statistical significance are not detailed for the performance edge of FORT-Searcher; without reported controls for model size, training data volume, or variance across runs, it is unclear whether the reported superiority is robust or attributable to the shortcut-resistant construction.
minor comments (2)
- The four shortcut risks are introduced without an explicit enumeration or pseudocode in the main text; a compact table or algorithm box would improve traceability from risk definition to synthesis steps.
- The GitHub link is mentioned but no commit hash or data-release details are provided; reproducibility would benefit from explicit versioning of the released trajectories and synthesis code.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing rigorous validation of shortcut resistance. We respond to each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the trajectory signatures (solving cost, answer hit time, prior-shortcut rate) and shortcut-risk reductions are reported exclusively for the FORT synthesis process and the training trajectories; no equivalent analysis is provided for FORT-Searcher outputs on the evaluation benchmarks. Because the central claim equates benchmark gains with genuine search improvement rather than undetected shortcuts, the absence of these diagnostics on the test distributions is load-bearing.
Authors: We agree that the absence of trajectory signatures on the evaluation benchmarks leaves the central claim partially unverified. In the revised manuscript we will log and report solving cost, answer hit time, and prior-shortcut rate for FORT-Searcher on the benchmark tasks (where full trajectories can be collected under the same evaluation protocol), thereby directly testing whether benchmark gains arise from genuine multi-step evidence acquisition rather than residual shortcuts. revision: yes
-
Referee: [Experiments] Experiments section and Table reporting benchmark results: baseline comparisons and statistical significance are not detailed for the performance edge of FORT-Searcher; without reported controls for model size, training data volume, or variance across runs, it is unclear whether the reported superiority is robust or attributable to the shortcut-resistant construction.
Authors: The manuscript already restricts comparisons to open-source agents of comparable size (approximately 7B parameters) trained via SFT. We will expand the experiments section and results table to explicitly state these controls, add statistical significance tests (e.g., bootstrap confidence intervals or paired tests), and report performance variance across multiple random seeds. These additions will clarify that the observed edge is attributable to the FORT data construction rather than confounding factors. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper presents a methodological framework (FORT) for synthesizing training data with defined shortcut risks and trajectory signatures, then reports empirical results: longer pre-answer search on FORT data versus existing datasets, and superior benchmark performance after SFT. These outcomes are validated against independent open-source datasets and benchmarks rather than reducing to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or derivations are shown that loop back to inputs by construction, and the central performance claim is not forced by the synthesis process itself. This is the expected non-finding for an empirical synthesis paper whose validity hinges on external comparisons.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training on tasks that force longer search trajectories without shortcuts improves agent performance on deep search benchmarks.
invented entities (1)
-
Four shortcut risks (evidence co-coverage, single-clue selectivity, exposed constants, prior-knowledge binding)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.13305 , year=
Websailor-v2: Bridging the chasm to proprietary agents via synthetic data and scalable reinforcement learning , author=. arXiv preprint arXiv:2509.13305 , year=
-
[2]
arXiv preprint arXiv:2507.02592 , year=
Websailor: Navigating super-human reasoning for web agent , author=. arXiv preprint arXiv:2507.02592 , year=
-
[3]
arXiv preprint arXiv:2603.28376 , year=
Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design , author=. arXiv preprint arXiv:2603.28376 , year=
-
[4]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[5]
Advances in Neural Information Processing Systems , volume=
Webdancer: Towards autonomous information seeking agency , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
arXiv preprint arXiv:2510.14438 , year=
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents , author=. arXiv preprint arXiv:2510.14438 , year=
-
[7]
arXiv preprint arXiv:2603.11076 , year=
DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use , author=. arXiv preprint arXiv:2603.11076 , year=
-
[8]
arXiv preprint arXiv:2603.15594 , year=
Openseeker: Democratizing frontier search agents by fully open-sourcing training data , author=. arXiv preprint arXiv:2603.15594 , year=
-
[9]
arXiv preprint arXiv:2510.13913 , year=
Synthesizing Agentic Data for Web Agents with Progressive Difficulty Enhancement Mechanisms , author=. arXiv preprint arXiv:2510.13913 , year=
-
[10]
arXiv preprint arXiv:2402.11924 , year=
MRKE: The multi-hop reasoning evaluation of LLMs by knowledge edition , author=. arXiv preprint arXiv:2402.11924 , year=
-
[11]
arXiv preprint arXiv:2511.01323 , year=
DEEPAMBIGQA: Ambiguous Multi-hop Questions for Benchmarking LLM Answer Completeness , author=. arXiv preprint arXiv:2511.01323 , year=
-
[12]
arXiv preprint arXiv:2412.17032 , year=
Mintqa: A multi-hop question answering benchmark for evaluating llms on new and tail knowledge , author=. arXiv preprint arXiv:2412.17032 , year=
-
[13]
arXiv preprint arXiv:2509.10446 , year=
Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl , author=. arXiv preprint arXiv:2509.10446 , year=
-
[14]
arXiv preprint arXiv:2603.15726 , year=
Mirothinker-1.7 & h1: Towards heavy-duty research agents via verification , author=. arXiv preprint arXiv:2603.15726 , year=
-
[15]
arXiv preprint arXiv:2507.15061 , year=
Webshaper: Agentically data synthesizing via information-seeking formalization , author=. arXiv preprint arXiv:2507.15061 , year=
-
[16]
arXiv preprint arXiv:2510.24701 , year=
Tongyi DeepResearch Technical Report , author=. arXiv preprint arXiv:2510.24701 , year=
-
[17]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[18]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[19]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
FanOutQA: A multi-hop, multi-document question answering benchmark for large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[20]
arXiv preprint arXiv:2504.12516 , year=
Browsecomp: A simple yet challenging benchmark for browsing agents , author=. arXiv preprint arXiv:2504.12516 , year=
-
[21]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[22]
arXiv preprint arXiv:2602.14234 , year=
Redsearcher: A scalable and cost-efficient framework for long-horizon search agents , author=. arXiv preprint arXiv:2602.14234 , year=
-
[23]
arXiv preprint arXiv:2605.04036 , year=
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories , author=. arXiv preprint arXiv:2605.04036 , year=
-
[24]
arXiv preprint arXiv:2509.00375 , year=
Open data synthesis for deep research , author=. arXiv preprint arXiv:2509.00375 , year=
-
[25]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
SAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[26]
arXiv preprint arXiv:2508.16994 , year=
GRADE: Generating multi-hop QA and fine-gRAined Difficulty matrix for RAG Evaluation , author=. arXiv preprint arXiv:2508.16994 , year=
-
[27]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[28]
arXiv preprint arXiv:2504.19314 , year=
Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese , author=. arXiv preprint arXiv:2504.19314 , year=
-
[29]
arXiv preprint arXiv:2506.13651 , year=
xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations , author=. arXiv preprint arXiv:2506.13651 , year=
-
[30]
arXiv preprint arXiv:2506.01062 , year=
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models , author=. arXiv preprint arXiv:2506.01062 , year=
-
[31]
arXiv preprint arXiv:2511.11793 , year=
Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling , author=. arXiv preprint arXiv:2511.11793 , year=
-
[32]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[33]
2026 , howpublished =
2026
-
[34]
arXiv preprint arXiv:2602.15763 , year=
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
-
[35]
2: Pushing the frontier of open large language models , author=
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
-
[36]
arXiv preprint arXiv:2602.10604 , year=
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters , author=. arXiv preprint arXiv:2602.10604 , year=
-
[37]
arXiv preprint arXiv:2601.16725 , year=
Longcat-flash-thinking-2601 technical report , author=. arXiv preprint arXiv:2601.16725 , year=
-
[38]
2026 , note =
Tencent Hunyuan , title =. 2026 , note =
2026
-
[39]
5: Visual Agentic Intelligence , author=
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
-
[40]
2026 , note =
Alibaba Qwen Team , title =. 2026 , note =
2026
-
[41]
2025 , note =
Z.ai , title =. 2025 , note =
2025
-
[42]
2026 , eprint=
SAM: State-Adaptive Memory for Long-Horizon Reasoning Agent , author=. 2026 , eprint=
2026
-
[43]
arXiv preprint arXiv:2502.04644 , volume=
Agentic reasoning: Reasoning llms with tools for the deep research , author=. arXiv preprint arXiv:2502.04644 , volume=
-
[44]
arXiv preprint arXiv:2511.07685 , year=
Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents , author=. arXiv preprint arXiv:2511.07685 , year=
-
[45]
arXiv preprint arXiv:2511.09907 , year=
Learning to pose problems: Reasoning-driven and solver-adaptive data synthesis for large reasoning models , author=. arXiv preprint arXiv:2511.09907 , year=
-
[46]
arXiv preprint arXiv:2505.20416 , year=
GraphGen: enhancing supervised fine-tuning for LLMs with knowledge-driven synthetic data generation , author=. arXiv preprint arXiv:2505.20416 , year=
-
[47]
arXiv preprint arXiv:2509.23252 , year=
NanoFlux: Adversarial Dual-LLM Evaluation and Distillation For Multi-Domain Reasoning , author=. arXiv preprint arXiv:2509.23252 , year=
-
[48]
arXiv preprint arXiv:2508.00965 , year=
Vault: Vigilant adversarial updates via llm-driven retrieval-augmented generation for nli , author=. arXiv preprint arXiv:2508.00965 , year=
-
[49]
arXiv e-prints , pages=
Iterresearch: Rethinking long-horizon agents via markovian state reconstruction , author=. arXiv e-prints , pages=
-
[50]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[51]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Avoiding reasoning shortcuts: Adversarial evaluation, training, and model development for multi-hop QA , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[52]
arXiv preprint arXiv:2510.05137 , year=
Demystifying deep search: a holistic evaluation with hint-free multi-hop questions and factorised metrics , author=. arXiv preprint arXiv:2510.05137 , year=
-
[53]
arXiv preprint arXiv:2510.06534 , year=
Beneficial Reasoning Behaviors in Agentic Search and Effective Post-training to Obtain Them , author=. arXiv preprint arXiv:2510.06534 , year=
-
[54]
arXiv preprint arXiv:2509.21710 , year=
Think-on-Graph 3.0: Efficient and Adaptive LLM Reasoning on Heterogeneous Graphs via Multi-Agent Dual-Evolving Context Retrieval , author=. arXiv preprint arXiv:2509.21710 , year=
-
[55]
Proceedings of the 2025 International Conference on Generative Artificial Intelligence for Business , pages=
Toward verifiable misinformation detection: A multi-tool LLM agent framework , author=. Proceedings of the 2025 International Conference on Generative Artificial Intelligence for Business , pages=
2025
-
[56]
arXiv preprint arXiv:2509.25189 , year=
Infoagent: Advancing autonomous information-seeking agents , author=. arXiv preprint arXiv:2509.25189 , year=
-
[57]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[58]
arXiv preprint arXiv:2602.23286 , year=
Sparta: Scalable and principled benchmark of tree-structured multi-hop qa over text and tables , author=. arXiv preprint arXiv:2602.23286 , year=
-
[59]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[60]
arXiv preprint arXiv:2603.00582 , year=
Super Research: Answering Highly Complex Questions with Large Language Models through Super Deep and Super Wide Research , author=. arXiv preprint arXiv:2603.00582 , year=
-
[61]
arXiv preprint arXiv:2510.05592 , year=
In-the-flow agentic system optimization for effective planning and tool use , author=. arXiv preprint arXiv:2510.05592 , year=
-
[62]
arXiv preprint arXiv:2601.06021 , year=
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards , author=. arXiv preprint arXiv:2601.06021 , year=
-
[63]
arXiv preprint arXiv:2603.04751 , year=
Evaluating the Search Agent in a Parallel World , author=. arXiv preprint arXiv:2603.04751 , year=
-
[64]
arXiv preprint arXiv:2603.12458 , year=
Shattering the Shortcut: A Topology-Regularized Benchmark for Multi-hop Medical Reasoning in LLMs , author=. arXiv preprint arXiv:2603.12458 , year=
-
[65]
arXiv preprint arXiv:2409.02257 , year=
Mmlu-pro+: Evaluating higher-order reasoning and shortcut learning in llms , author=. arXiv preprint arXiv:2409.02257 , year=
-
[66]
arXiv preprint arXiv:2508.02085 , year=
Se-agent: Self-evolution trajectory optimization in multi-step reasoning with llm-based agents , author=. arXiv preprint arXiv:2508.02085 , year=
-
[67]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Hydrarag: Structured cross-source enhanced large language model reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[68]
Improving LLM’s Attachment to External Knowledge In Dialogue Generation Tasks Through Entity Anonymization , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[69]
Knowledge-Based Systems , volume=
Prompting large language models with knowledge graphs for question answering involving long-tail facts , author=. Knowledge-Based Systems , volume=. 2025 , publisher=
2025
-
[70]
arXiv preprint arXiv:2602.18137 , year=
Agentic Adversarial QA for Improving Domain-Specific LLMs , author=. arXiv preprint arXiv:2602.18137 , year=
-
[71]
arXiv preprint arXiv:2510.14278 , year=
Prism: Agentic retrieval with llms for multi-hop question answering , author=. arXiv preprint arXiv:2510.14278 , year=
-
[72]
arXiv preprint arXiv:2604.23783 , year=
S2G-RAG: Structured Sufficiency and Gap Judging for Iterative Retrieval-Augmented QA , author=. arXiv preprint arXiv:2604.23783 , year=
-
[73]
Proceedings of the ACM Web Conference 2026 , pages=
Less is more: Compact clue selection for efficient retrieval-augmented generation reasoning , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[74]
arXiv preprint arXiv:2603.26074 , year=
Not All Entities are Created Equal: A Dynamic Anonymization Framework for Privacy-Preserving Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2603.26074 , year=
-
[75]
2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA) , pages=
A survey on current trends and recent advances in text anonymization , author=. 2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA) , pages=. 2025 , organization=
2025
-
[76]
Wang, Xinyuan and Mao, Wenyu and Wu, Junkang and Wang, Xiang and He, Xiangnan , journal=. R\^
-
[77]
arXiv preprint arXiv:2602.12852 , year=
WebClipper: Efficient Evolution of Web Agents with Graph-based Trajectory Pruning , author=. arXiv preprint arXiv:2602.12852 , year=
-
[78]
arXiv preprint arXiv:2604.04949 , year=
Learning to Retrieve from Agent Trajectories , author=. arXiv preprint arXiv:2604.04949 , year=
-
[79]
Journal of Economics, Finance and Accounting Studies , volume=
A Deterministic Trajectory-Level Evaluation Framework for Learning-Based Agentic Systems , author=. Journal of Economics, Finance and Accounting Studies , volume=
-
[80]
arXiv preprint arXiv:2605.16217 , year=
Argus: Evidence Assembly for Scalable Deep Research Agents , author=. arXiv preprint arXiv:2605.16217 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.