Debiasing Without Protected Attributes: Latent Concept Erasure from Textual Profiles
Pith reviewed 2026-06-27 09:57 UTC · model grok-4.3
The pith
Debiasing language models works using self-description text in place of explicit protected attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-hoc concept and attribute erasure can be performed using self-description text as an implicit debiasing signal, and across encoder and decoder-only language models this implicit approach often matches or outperforms explicit-label-based debiasing on a new multi-domain fairness benchmark for helpfulness prediction.
What carries the argument
H-SAL, which performs post-hoc concept and attribute erasure using self-description text as an implicit debiasing signal
If this is right
- Debiasing remains feasible in privacy-constrained or metadata-absent settings.
- Task performance on downstream prediction does not degrade when switching to implicit signals.
- Both encoder-only and decoder-only models respond comparably to the implicit erasure method.
- A multi-domain benchmark now exists for testing debiasing under realistic data constraints.
- Representation-level fairness methods can be applied without collecting protected attributes.
Where Pith is reading between the lines
- The method could be tested on other prediction tasks such as toxicity detection or resume screening where self-descriptions are available.
- If self-descriptions prove stable over time, models could be periodically re-debiased without re-collecting labels.
- The approach raises the question of whether implicit signals themselves encode secondary biases that explicit methods avoid.
- Deployment pipelines could default to implicit erasure when explicit attributes are legally unavailable.
Load-bearing premise
Self-description text contains reliable implicit signals that can substitute for direct protected attributes in concept erasure without introducing new biases or losing task performance.
What would settle it
An experiment showing that H-SAL with self-descriptions produces lower fairness scores or worse helpfulness prediction accuracy than explicit-label debiasing on the Stack Exchange benchmark would falsify the central claim.
Figures

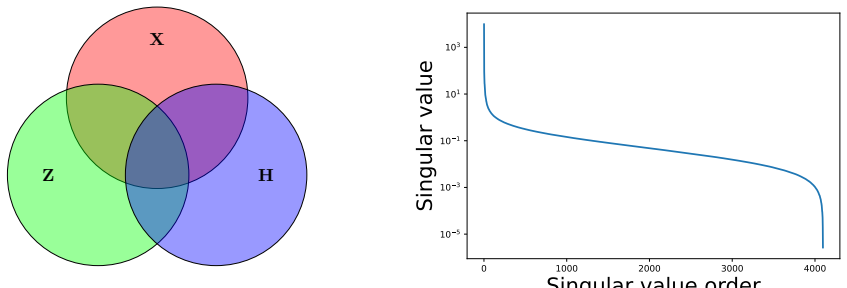
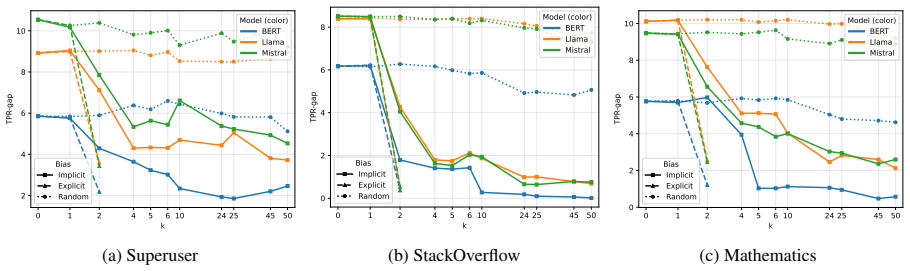
read the original abstract
Most fairness research in NLP assumes direct access to protected attributes such as gender, race, or nationality. In practice, however, such information is often unavailable due to privacy constraints, missing metadata, or legal restrictions, even though models may infer it from indirect textual cues. This raises a key question: can debiasing succeed without direct access to sensitive attributes? We propose H-SAL, which performs post-hoc concept and attribute erasure using self-description text as an implicit debiasing signal. To support this setting, we introduce a multi-domain Stack Exchange-based fairness benchmark for helpfulness prediction that includes both explicit and implicit signals, enabling comparison between standard debiasing with protected labels and debiasing without access to sensitive information. Across encoder and decoder-only language models, we find that implicit self-description often matches or outperforms explicit-label-based debiasing. Our results broaden representation-level fairness research and provide a new benchmark for studying debiasing under realistic data constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes H-SAL, a post-hoc method for latent concept and attribute erasure that uses self-description text as an implicit debiasing signal in place of direct protected attributes (gender, race, etc.). To enable evaluation, the authors introduce a multi-domain Stack Exchange benchmark for helpfulness prediction containing both explicit labels and implicit self-descriptions. Empirical results across encoder and decoder-only LMs indicate that implicit self-description often matches or exceeds explicit-label debiasing on fairness and task metrics.
Significance. If the central empirical claim holds after verification of signal reliability, the work would meaningfully extend representation-level fairness methods to privacy-constrained regimes where protected attributes are unavailable. The new benchmark is a concrete contribution that supports controlled comparison of explicit vs. implicit debiasing. No machine-checked proofs or parameter-free derivations are present; the contribution is empirical.
major comments (2)
- [Benchmark and Experiments] The central claim that implicit self-description supplies signals 'sufficient' for concept erasure to match explicit-label performance (§ on experiments / results) is load-bearing, yet the manuscript provides no reported correlation coefficients, mutual information, or ablation quantifying how strongly self-descriptions align with protected attributes in the Stack Exchange data. Without this, observed parity could be an artifact of benchmark construction rather than evidence that H-SAL erases the intended concept.
- [Results] Table or figure reporting helpfulness-prediction results: the claim of 'often matches or outperforms' lacks error bars, statistical significance tests, or per-domain breakdowns. If variance is high or gains are driven by a subset of domains, the cross-model generalization statement is not yet supported.
minor comments (2)
- [Method] Notation for H-SAL components (e.g., the erasure objective) should be defined once with a single equation block rather than scattered prose references.
- [Experimental Setup] The abstract states results 'across encoder and decoder-only language models' but the manuscript should explicitly list the exact model sizes and fine-tuning regimes used for each.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the empirical support for our claims regarding implicit debiasing signals.
read point-by-point responses
-
Referee: [Benchmark and Experiments] The central claim that implicit self-description supplies signals 'sufficient' for concept erasure to match explicit-label performance (§ on experiments / results) is load-bearing, yet the manuscript provides no reported correlation coefficients, mutual information, or ablation quantifying how strongly self-descriptions align with protected attributes in the Stack Exchange data. Without this, observed parity could be an artifact of benchmark construction rather than evidence that H-SAL erases the intended concept.
Authors: We agree that quantifying the alignment between self-description signals and protected attributes would provide stronger evidence against the possibility of benchmark artifacts. The benchmark was constructed to include both explicit labels (for evaluation) and implicit self-descriptions (for debiasing), but we did not report alignment metrics such as mutual information or correlations in the original submission. In the revised manuscript we will add these analyses, including correlation coefficients and an ablation that measures how much of the debiasing effect is attributable to the self-description signal versus other factors. This will directly address whether the observed performance parity reflects genuine concept erasure. revision: yes
-
Referee: [Results] Table or figure reporting helpfulness-prediction results: the claim of 'often matches or outperforms' lacks error bars, statistical significance tests, or per-domain breakdowns. If variance is high or gains are driven by a subset of domains, the cross-model generalization statement is not yet supported.
Authors: We acknowledge that the absence of error bars, significance testing, and per-domain results limits the strength of the generalization claims. The original tables reported aggregate metrics across models and domains but did not include these details. In the revision we will augment the results section with standard error bars, paired statistical significance tests (e.g., McNemar or Wilcoxon where appropriate), and full per-domain breakdowns. These additions will allow readers to assess whether performance parity holds consistently or is driven by particular domains, thereby supporting or qualifying the cross-model statements. revision: yes
Circularity Check
No circularity: purely empirical comparison on new benchmark
full rationale
The paper introduces H-SAL as a post-hoc erasure method and a Stack Exchange benchmark, then reports experimental results showing implicit self-description often matches or exceeds explicit-label debiasing across models. No equations, fitted parameters renamed as predictions, self-citation load-bearing steps, or ansatzes are present in the provided text. The central claim rests on direct empirical measurement rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-description text contains implicit signals for protected attributes that can be used for debiasing
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Journal of Artificial Intelligence Research , volume=
A survey of cross-lingual word embedding models , author=. Journal of Artificial Intelligence Research , volume=
-
[9]
Adversarial Concept Erasure in Kernel Space
Ravfogel, Shauli and Vargas, Francisco and Goldberg, Yoav and Cotterell, Ryan. Adversarial Concept Erasure in Kernel Space. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.405
-
[10]
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , url =
Bolukbasi, Tolga and Chang, Kai-Wei and Zou, James Y and Saligrama, Venkatesh and Kalai, Adam T , booktitle =. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , url =
-
[11]
Bryson and Arvind Narayanan , title =
Aylin Caliskan and Joanna J. Bryson and Arvind Narayanan , title =. Science , volume =. 2017 , doi =
2017
-
[12]
Guo, Wei and Caliskan, Aylin , title =. 2021 , isbn =. doi:10.1145/3461702.3462536 , booktitle =
-
[13]
Manzini, Thomas and Yao Chong, Lim and Black, Alan W and Tsvetkov, Yulia. Black is to Criminal as Caucasian is to Police: Detecting and Removing Multiclass Bias in Word Embeddings. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers...
-
[14]
Veeman, Hartger and Allassonni \`e re-Tang, Marc and Berdicevskis, Aleksandrs and Basirat, Ali. Cross-lingual Embeddings Reveal Universal and Lineage-Specific Patterns in Grammatical Gender Assignment. Proceedings of the 24th Conference on Computational Natural Language Learning. 2020. doi:10.18653/v1/2020.conll-1.20
-
[15]
Analytical Methods for Interpretable Ultradense Word Embeddings
Dufter, Philipp and Sch. Analytical Methods for Interpretable Ultradense Word Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1111
-
[16]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[17]
Psychometrika , volume=
Principal component analysis of three-mode data by means of alternating least squares algorithms , author=. Psychometrika , volume=. 1980 , publisher=
1980
-
[18]
and Bader, Brett W
Kolda, Tamara G. and Bader, Brett W. , title =. SIAM Review , volume =. 2009 , doi =
2009
-
[19]
Dumais, S. T. and Furnas, G. W. and Landauer, T. K. and Deerwester, S. and Harshman, R. , title =. 1988 , isbn =. doi:10.1145/57167.57214 , booktitle =
-
[20]
Eckart-Young
Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition , author=. Psychometrika , volume=. 1970 , publisher=
1970
-
[21]
explanatory
Foundations of the PARAFAC procedure: Models and conditions for an" explanatory" multimodal factor analysis , author=
-
[22]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =
De-Arteaga, Maria and Romanov, Alexey and Wallach, Hanna and Chayes, Jennifer and Borgs, Christian and Chouldechova, Alexandra and Geyik, Sahin and Kenthapadi, Krishnaram and Kalai, Adam Tauman , title =. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =. 2019 , isbn =. doi:10.1145/3287560.3287572 , abstract =
-
[23]
Barikeri, Soumya and Lauscher, Anne and Vuli \'c , Ivan and Glava s , Goran. R eddit B ias: A Real-World Resource for Bias Evaluation and Debiasing of Conversational Language Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: ...
-
[24]
Fan, Angela and Gardent, Claire , keywords =. Generating Full Length Wikipedia Biographies: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2204.05879 , url =
-
[25]
Multilingual T witter Corpus and Baselines for Evaluating Demographic Bias in Hate Speech Recognition
Huang, Xiaolei and Xing, Linzi and Dernoncourt, Franck and Paul, Michael J. Multilingual T witter Corpus and Baselines for Evaluating Demographic Bias in Hate Speech Recognition. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[26]
2018 , booktitle=
Amazon scraps secret AI recruiting tool that showed bias against women , author=. 2018 , booktitle=
2018
-
[27]
, author=
Visualizing data using t-SNE. , author=. Journal of machine learning research , volume=
-
[28]
Probing Classifiers are Unreliable for Concept Removal and Detection , publisher =
Kumar, Abhinav and Tan, Chenhao and Sharma, Amit , keywords =. Probing Classifiers are Unreliable for Concept Removal and Detection , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2207.04153 , url =
-
[29]
Language and linguistics compass , volume=
Construction morphology , author=. Language and linguistics compass , volume=. 2010 , publisher=
2010
-
[30]
2023 , eprint=
Measuring Inductive Biases of In-Context Learning with Underspecified Demonstrations , author=. 2023 , eprint=
2023
-
[31]
2022 , eprint=
MABEL: Attenuating Gender Bias using Textual Entailment Data , author=. 2022 , eprint=
2022
-
[32]
2023 , eprint=
Training Socially Aligned Language Models in Simulated Human Society , author=. 2023 , eprint=
2023
-
[33]
Language and Linguistics Compass , volume =
Hovy, Dirk and Prabhumoye, Shrimai , title =. Language and Linguistics Compass , volume =. doi:https://doi.org/10.1111/lnc3.12432 , url =. https://compass.onlinelibrary.wiley.com/doi/pdf/10.1111/lnc3.12432 , abstract =
-
[34]
You reap what you sow: On the Challenges of Bias Evaluation Under Multilingual Settings
Talat, Zeerak and N \'e v \'e ol, Aur \'e lie and Biderman, Stella and Clinciu, Miruna and Dey, Manan and Longpre, Shayne and Luccioni, Sasha and Masoud, Maraim and Mitchell, Margaret and Radev, Dragomir and Sharma, Shanya and Subramonian, Arjun and Tae, Jaesung and Tan, Samson and Tunuguntla, Deepak and Van Der Wal, Oskar. You reap what you sow: On the C...
-
[35]
arXiv preprint arXiv:2404.01349 , year=
Fairness in Large Language Models: A Taxonomic Survey , author=. arXiv preprint arXiv:2404.01349 , year=
-
[36]
Storkey , editor =
Harrison Edwards and Amos J. Storkey , editor =. Censoring Representations with an Adversary , booktitle =. 2016 , url =
2016
-
[37]
Encoding Prior Knowledge with Eigenword Embeddings
Osborne, Dominique and Narayan, Shashi and Cohen, Shay B. Encoding Prior Knowledge with Eigenword Embeddings. Transactions of the Association for Computational Linguistics. 2016. doi:10.1162/tacl_a_00108
-
[38]
A Joint Matrix Factorization Analysis of Multilingual Representations
Zhao, Zheng and Ziser, Yftah and Webber, Bonnie and Cohen, Shay. A Joint Matrix Factorization Analysis of Multilingual Representations. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.851
-
[39]
Toward Gender-Inclusive Coreference Resolution
Cao, Yang Trista and Daum \'e III, Hal. Toward Gender-Inclusive Coreference Resolution. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.418
-
[40]
Sparse Activation Editing for Reliable Instruction Following in Narratives
Zhao, Runcong and Cao, Chengyu and Zhu, Qinglin and Ly, Xiucheng and Shao, Shun and Gui, Lin and Xu, Ruifeng and He, Yulan. Sparse Activation Editing for Reliable Instruction Following in Narratives. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1311
-
[41]
Contemporary Mathematics , volume=
Projectors on intersection of subspaces , author=. Contemporary Mathematics , volume=. 2015 , publisher=
2015
-
[42]
FairImagen: Post-Processing for Bias Mitigation in Text-to-Image Models , url =
Fu, Zihao and Brown, Ryan and Shao, Shun and Rawal, Kai and Delaney, Eoin and Russell, Chris , booktitle =. FairImagen: Post-Processing for Bias Mitigation in Text-to-Image Models , url =
-
[43]
Demographic Dialectal Variation in Social Media: A Case Study of A frican- A merican E nglish
Blodgett, Su Lin and Green, Lisa and O ' Connor, Brendan. Demographic Dialectal Variation in Social Media: A Case Study of A frican- A merican E nglish. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1120
-
[44]
proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Bias in bios: A case study of semantic representation bias in a high-stakes setting , author=. proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
-
[45]
2024 , eprint=
Beyond Voice Assistants: Exploring Advantages and Risks of an In-Car Social Robot in Real Driving Scenarios , author=. 2024 , eprint=
2024
-
[46]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[47]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[48]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[49]
2023 , eprint=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. 2023 , eprint=
2023
-
[50]
LEACE: Perfect linear concept erasure in closed form , url =
Belrose, Nora and Schneider-Joseph, David and Ravfogel, Shauli and Cotterell, Ryan and Raff, Edward and Biderman, Stella , booktitle =. LEACE: Perfect linear concept erasure in closed form , url =
-
[51]
Proceedings of the 39th International Conference on Machine Learning , pages =
Linear Adversarial Concept Erasure , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[52]
2023 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2023 , eprint=
2023
-
[53]
International Conference on Learning Representations , year=
All-but-the-Top: Simple and Effective Postprocessing for Word Representations , author=. International Conference on Learning Representations , year=
-
[54]
Conceptor Debiasing of Word Representations Evaluated on WEAT
Karve, Saket and Ungar, Lyle and Sedoc, Jo \ a o. Conceptor Debiasing of Word Representations Evaluated on WEAT. Proceedings of the First Workshop on Gender Bias in Natural Language Processing. 2019. doi:10.18653/v1/W19-3806
-
[55]
2023 , eprint=
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla , author=. 2023 , eprint=
2023
-
[56]
Shao, Shun and Ziser, Yftah and Cohen, Shay B. Gold Doesn ' t Always Glitter: Spectral Removal of Linear and Nonlinear Guarded Attribute Information. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.118
-
[57]
Gonen, Hila and Goldberg, Yoav. Lipstick on a Pig: D ebiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1061
-
[58]
Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav. Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.647
-
[59]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On measuring and mitigating biased inferences of word embeddings , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[60]
Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models
Mondorf, Philipp and Wold, Sondre and Plank, Barbara. Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.727
-
[61]
SIAM Journal on Matrix Analysis and Applications , volume =
De Lathauwer, Lieven and De Moor, Bart and Vandewalle, Joos , title =. SIAM Journal on Matrix Analysis and Applications , volume =. 2000 , doi =. https://doi.org/10.1137/S0895479896305696 , abstract =
-
[62]
arXiv preprint arXiv:2210.12553 , year=
Understanding domain learning in language models through subpopulation analysis , author=. arXiv preprint arXiv:2210.12553 , year=
-
[63]
First Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward at ICML 2022 , year=
Self-destructing models: Increasing the costs of harmful dual uses in foundation models , author=. First Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward at ICML 2022 , year=
2022
-
[64]
Transactions of the Association for Computational Linguistics , volume =
Schick, Timo and Udupa, Sahana and Schütze, Hinrich , title = ". Transactions of the Association for Computational Linguistics , volume =. 2021 , month =. doi:10.1162/tacl_a_00434 , url =
-
[65]
Adversarial Removal of Demographic Attributes from Text Data
Elazar, Yanai and Goldberg, Yoav. Adversarial Removal of Demographic Attributes from Text Data. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1002
-
[66]
Zhang, Brian Hu and Lemoine, Blake and Mitchell, Margaret , title =. 2018 , isbn =. doi:10.1145/3278721.3278779 , booktitle =
-
[67]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Xie, Qizhe and Dai, Zihang and Du, Yulun and Hovy, Eduard and Neubig, Graham , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[68]
Kellie Webster and Xuezhi Wang and Ian Tenney and Alex Beutel and Emily Pitler and Ellie Pavlick and Jilin Chen and Slav Petrov , title =. CoRR , volume =. 2020 , url =. 2010.06032 , timestamp =
arXiv 2020
-
[69]
An Empirical Survey of the Effectiveness of Debiasing Techniques for Pre-trained Language Models
Meade, Nicholas and Poole-Dayan, Elinor and Reddy, Siva. An Empirical Survey of the Effectiveness of Debiasing Techniques for Pre-trained Language Models. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.132
-
[70]
arXiv preprint arXiv:2306.05949 , year=
Evaluating the Social Impact of Generative AI Systems in Systems and Society , author=. arXiv preprint arXiv:2306.05949 , year=
-
[71]
arXiv preprint arXiv:2108.07258 , year=
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
-
[72]
arXiv preprint arXiv:2303.15715 , year=
Foundation models and fair use , author=. arXiv preprint arXiv:2303.15715 , year=
-
[73]
2023 , eprint=
Recent Advances towards Safe, Responsible, and Moral Dialogue Systems: A Survey , author=. 2023 , eprint=
2023
-
[74]
2023 , eprint=
Sociotechnical Safety Evaluation of Generative AI Systems , author=. 2023 , eprint=
2023
-
[75]
arXiv preprint arXiv:2112.04359 , year=
Ethical and social risks of harm from language models , author=. arXiv preprint arXiv:2112.04359 , year=
-
[76]
Bergman, A. Stevie and Hendricks, Lisa Anne and Rauh, Maribeth and Wu, Boxi and Agnew, William and Kunesch, Markus and Duan, Isabella and Gabriel, Iason and Isaac, William , title =. 2023 , isbn =. doi:10.1145/3593013.3594019 , booktitle =
-
[77]
2020 , eprint=
Language (Technology) is Power: A Critical Survey of "Bias" in NLP , author=. 2020 , eprint=
2020
-
[78]
Fairness in Language Models Beyond E nglish: Gaps and Challenges
Ramesh, Krithika and Sitaram, Sunayana and Choudhury, Monojit. Fairness in Language Models Beyond E nglish: Gaps and Challenges. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.157
-
[79]
Friedman, Batya and Nissenbaum, Helen , title =. 1996 , issue_date =. doi:10.1145/230538.230561 , month =
-
[80]
Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies
Dev, Sunipa and Monajatipoor, Masoud and Ovalle, Anaelia and Subramonian, Arjun and Phillips, Jeff and Chang, Kai-Wei. Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.150
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.