DAM-VLA: Decoupled Asynchronous Multimodal Vision Language Action model
Pith reviewed 2026-06-27 09:24 UTC · model grok-4.3
The pith
Decoupling each modality's update rate in a vision-language-action model more than doubles success on contact-rich manipulation tasks while enabling 100 Hz control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
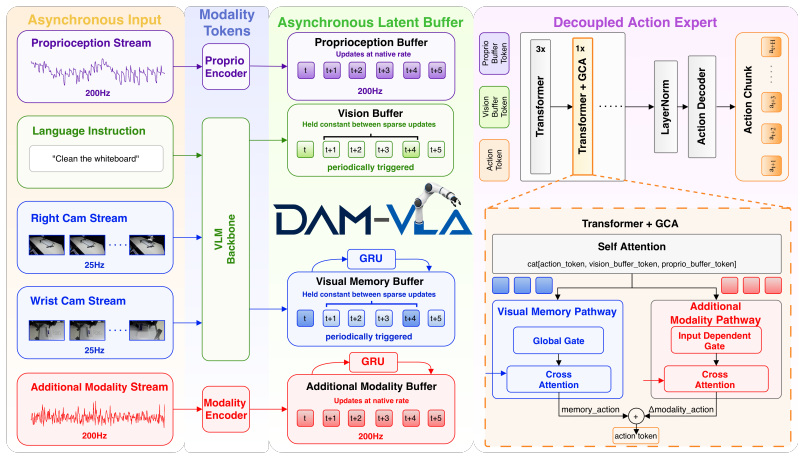
DAM-VLA maintains independent per-modality latent buffers that are refreshed at each sensor's native rate and read on demand by the action head. New high-frequency modalities are incorporated via gated cross-attention without modifying the pretrained vision-language backbone. This produces stronger multimodal representations for contact-rich control and removes the frequency cap imposed by the slowest modality.
What carries the argument
Per-modality latent buffers refreshed at sensor rates and read continuously by the action head, combined with gated cross-attention for adding high-frequency inputs.
If this is right
- Average success rate on the seven tasks rises from 40.95 percent to 95.2 percent.
- Control frequency remains smooth and reactive at 100 Hz without undersampling fast modalities.
- The pretrained vision-language backbone stays intact while high-frequency modalities are added.
- Oversampling of slow modalities and undersampling of fast ones are both avoided.
- Action generation is no longer limited by the lowest effective input frequency.
Where Pith is reading between the lines
- The same buffering approach could be tested on tasks with longer time horizons to check whether independent modality memories improve retention of distant events.
- Energy or compute savings may arise from avoiding repeated processing of slow-changing inputs, though this is not measured in the paper.
- The architecture could be applied to other multimodal robot policies where input rates differ by orders of magnitude.
Load-bearing premise
That independent per-modality buffers updated at native sensor rates will produce stronger representations and more robust control without degrading the pretrained backbone.
What would settle it
Running DAM-VLA and the strongest synchronous baseline on the same seven tasks and finding that the decoupled model does not exceed 40.95 percent average success or cannot sustain 100 Hz reactive control.
Figures






read the original abstract
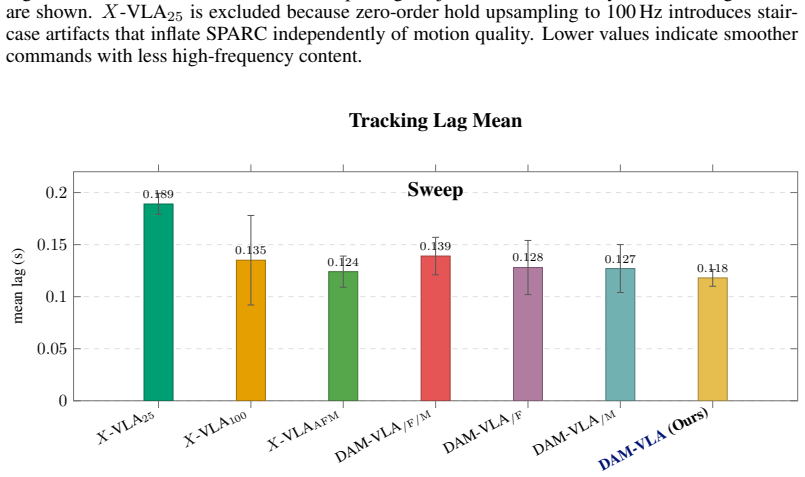
Vision-language-action (VLA) models inherit a shared synchronous clock from vision-language pretraining, processing every input at one rate. This is misaligned with physical interaction, where a high-frequency modality changes at hundreds of hertz, vision evolves more slowly, and language stays constant across an episode. A synchronous VLA oversamples slow modalities, undersamples fast ones, and caps action generation at the lowest effective frequency. We hypothesize that decoupling temporal processing per modality, letting each update and retain information at its own sensor rate, yields stronger representations and more robust control. We present DAM-VLA, which maintains per-modality latent buffers refreshed at sensor rates and read continuously by the action head, integrating new high-frequency modalities through gated cross-attention that leaves the pretrained backbone intact. Across seven contact-rich real-world manipulation tasks, DAM-VLA more than doubles the average success rate of the strongest synchronous baseline (95.2\% vs.\ 40.95\%) while sustaining smooth, reactive 100\,Hz control. Project website: \href{https://intuitive-robots.github.io/DAM-VLA/}{intuitive-robots.github.io/DAM-VLA/}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAM-VLA, a decoupled asynchronous multimodal vision-language-action model. It argues that standard VLAs inherit a shared synchronous clock misaligned with physical sensors (high-frequency modalities at hundreds of Hz, slower vision, constant language), and introduces per-modality latent buffers refreshed at sensor rates, integrated via gated cross-attention that leaves the pretrained backbone intact, with a continuously-reading action head. On seven contact-rich real-world manipulation tasks, it reports more than doubling average success rate versus the strongest synchronous baseline (95.2% vs. 40.95%) while sustaining 100 Hz reactive control.
Significance. If the empirical gains hold and can be attributed specifically to temporal decoupling, the approach could meaningfully advance real-time VLA deployment in robotics by aligning processing with modality dynamics while preserving pretrained models. Real-robot results on contact-rich tasks are a positive aspect of the evaluation.
major comments (2)
- [Abstract] Abstract: The central claim attributes the jump from 40.95% to 95.2% success rate to the hypothesis that 'decoupling temporal processing per modality, letting each update and retain information at its own sensor rate, yields stronger representations and more robust control.' However, the architecture simultaneously adds gated cross-attention, per-modality buffers, and a new action head. No ablation holding these constant under synchronous timing is described, so the results do not establish that asynchrony itself (rather than added capacity or the integration mechanism) drives the reported gains.
- [Experiments] Experiments section (results on the seven tasks): The synchronous baseline is referred to only as 'the strongest synchronous baseline' without explicit confirmation that it incorporates the same gated cross-attention and buffer mechanisms under a single clock. This comparison is load-bearing for the claim that the decoupled design produces the observed improvement.
minor comments (1)
- The manuscript should include explicit task definitions, baseline implementation details, number of trials per task, and any statistical tests or exclusion criteria to support the reported success rates.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address the two major comments point by point below, clarifying the design rationale while acknowledging where additional discussion or revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the jump from 40.95% to 95.2% success rate to the hypothesis that 'decoupling temporal processing per modality, letting each update and retain information at its own sensor rate, yields stronger representations and more robust control.' However, the architecture simultaneously adds gated cross-attention, per-modality buffers, and a new action head. No ablation holding these constant under synchronous timing is described, so the results do not establish that asynchrony itself (rather than added capacity or the integration mechanism) drives the reported gains.
Authors: We agree that a controlled ablation isolating asynchrony from the integration mechanisms would provide stronger evidence. The gated cross-attention, per-modality latent buffers, and continuously reading action head are not independent additions but the concrete realization of the decoupling hypothesis; they enable each modality to update and retain information at its native sensor rate while the backbone remains frozen. The synchronous baseline is the standard pretrained VLA operating under a single shared clock without these asynchronous mechanisms. We will revise the abstract and introduction to temper the causal language, explicitly note that the reported gains reflect the full decoupled architecture, and add a limitations paragraph acknowledging the absence of a same-mechanism synchronous ablation. revision: partial
-
Referee: [Experiments] Experiments section (results on the seven tasks): The synchronous baseline is referred to only as 'the strongest synchronous baseline' without explicit confirmation that it incorporates the same gated cross-attention and buffer mechanisms under a single clock. This comparison is load-bearing for the claim that the decoupled design produces the observed improvement.
Authors: The synchronous baseline is a standard synchronous VLA (the strongest publicly reported synchronous model at the time of submission) that processes all modalities at a fixed common rate and does not include per-modality buffers or gated cross-attention, because those components are defined to support asynchronous operation. We will revise the experiments section to provide an explicit architectural description of the baseline, confirm its synchronous clock, and add a table or paragraph contrasting the two designs. revision: yes
Circularity Check
No circularity: empirical architecture validated on real-robot tasks
full rationale
The paper advances an architectural hypothesis (decoupling temporal processing per modality via independent latent buffers refreshed at sensor rates, integrated by gated cross-attention) and reports empirical success-rate gains on seven contact-rich manipulation tasks. No equations, derivations, or predictions appear that reduce the reported outcomes to fitted parameters, self-definitions, or self-citation chains. The central claim is tested through implementation and external evaluation rather than by construction from its own inputs. No load-bearing self-citations, uniqueness theorems, or renamed known results are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoupling temporal processing per modality, letting each update and retain information at its own sensor rate, yields stronger representations and more robust control.
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[3]
Vanjani, P
P. Vanjani, P. Mattes, X. Jia, V . Dave, and R. Lioutikov. Disdp: Robust imitation learning via disentangled diffusion policies. InReinforcement Learning Conference, 2025
2025
-
[4]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[5]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. Advances in Neural Information Processing Systems, 38:33383–33407, 2026
2026
-
[6]
Y . Zhao, L. Zhao, B. Cheng, G. Yao, X. Wen, and H. Gao. Vla-rail: A real-time asynchronous inference linker for vla models and robots.arXiv preprint arXiv:2512.24673, 2025
arXiv 2025
- [7]
-
[8]
H. Chen, J. Liu, C. Gu, Z. Liu, R. Zhang, X. Li, X. He, Y . Guo, C.-W. Fu, S. Zhang, et al. Fast- in-slow: A dual-system vla model unifying fast manipulation within slow reasoning.Advances in Neural Information Processing Systems, 38:98049–98083, 2026
2026
-
[9]
T. Zou, H. Zeng, Y . Nong, Y . Li, K. Liu, H. Yang, X. Ling, X. Li, and L. Ma. Asynchronous fast-slow vision-language-action policies for whole-body robotic manipulation.arXiv preprint arXiv:2512.20188, 2025
arXiv 2025
-
[10]
S. Xu, Y . Wang, C. Xia, D. Zhu, T. Huang, and C. Xu. Vla-cache: Towards efficient vision- language-action model via adaptive token caching in robotic manipulation.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[11]
W. Qiu, T. Huang, and R. Ying. Efficient long-horizon vision-language-action models via static-dynamic disentanglement.arXiv preprint arXiv:2602.03983, 2026
Pith/arXiv arXiv 2026
-
[12]
C. Yang, Y . Hu, Y . Ma, Y . Yang, J. Tan, and H. Fan. Realtime-vla v2: Learning to run vlas fast, smooth, and accurate.arXiv preprint arXiv:2603.26360, 2026
arXiv 2026
-
[13]
J. Tang, Y . Sun, Y . Zhao, S. Yang, Y . Lin, Z. Zhang, J. Hou, Y . Lu, Z. Liu, and S. Han. Vlash: Real-time vlas via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025
arXiv 2025
-
[14]
Y . Lu, Z. Liu, X. Fan, Z. Yang, J. Hou, J. Li, K. Ding, and H. Zhao. Faster: Rethinking real-time flow vlas.arXiv preprint arXiv:2603.19199, 2026
Pith/arXiv arXiv 2026
-
[15]
G. Lee, Y . Lee, K. Kim, S. Lee, S. Noh, S. Back, and K. Lee. Manipforce: Force-guided policy learning with frequency-aware representation for contact-rich manipulation.arXiv preprint arXiv:2509.19047, 2025
arXiv 2025
- [16]
-
[17]
Y . Li, H. Jiang, J. Xia, H. Zhang, J. Du, Y . Zhou, J. Zeng, C. Hao, J. Ren, Q. Yu, et al. Forcevla2: Unleashing hybrid force-position control with force awareness for contact-rich ma- nipulation.arXiv preprint arXiv:2603.15169, 2026
arXiv 2026
- [18]
-
[19]
Y . Li, P. Tang, W. Zhang, C. Zhu, Y . Duan, W. Shi, X. Zhang, Z. Yang, J. Ji, and Y . Zhang. Favla: A force-adaptive fast-slow vla model for contact-rich robotic manipulation.arXiv preprint arXiv:2602.23648, 2026
arXiv 2026
-
[20]
R. Zhao, W. Wang, Y . Ma, X. Li, F. E. Tay, M. H. Ang Jr, and H. Zhu. Fd-vla: Force-distilled vision-language-action model for contact-rich manipulation.arXiv preprint arXiv:2602.02142, 2026
arXiv 2026
- [21]
-
[22]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[23]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations, volume 2025, pages 54277–54296, 2025
2025
-
[24]
M. Lin, P. Ding, S. Wang, Z. Zhuang, Y . Liu, X. Tong, W. Song, S. Lyu, S. Huang, and D. Wang. Hif-vla: Hindsight, insight and foresight through motion representation for vision- language-action models.arXiv preprint arXiv:2512.09928, 2025
Pith/arXiv arXiv 2025
-
[25]
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. Hamlet: Switch your vision- language-action model into a history-aware policy.arXiv preprint arXiv:2510.00695, 2025
Pith/arXiv arXiv 2025
-
[26]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[27]
M. Lin, X. Liang, B. Lin, L. Jingzhi, Z. Jiao, K. Li, Y . Ma, Y . Liu, S. Zhao, Y . Zhuang, et al. Echovla: Robotic vision-language-action model with synergistic declarative memory for mobile manipulation.arXiv preprint arXiv:2511.18112, 2025
arXiv 2025
-
[28]
C. Ni, C. Chen, X. Wang, Z. Zhu, W. Zheng, B. Wang, T. Chen, G. Zhao, H. Li, Z. Dong, et al. Swiftvla: Unlocking spatiotemporal dynamics for lightweight vla models at minimal overhead.arXiv preprint arXiv:2512.00903, 2025
arXiv 2025
-
[29]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[30]
Y . Gao, J. Liu, S. Li, and S. Song. Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Pith/arXiv arXiv 2026
-
[31]
Alayrac, J
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Mil- lican, M. Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022. 11
2022
-
[32]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[33]
P. W. L ¨odige, M. X. Li, and R. Lioutikov. Use the force, bot!-force-aware prodmp with event- based replanning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16730–16736. IEEE, 2025. 12 Appendix A Robot Platform and Sensor Suite All real-world experiments are conducted on aFranka Emika Panda7-DoF robot arm equipped with aR...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.