Intelligent Automation for Embodied Benchmark Construction: Pipelines, Embodiments, Simulators, and Trends
Pith reviewed 2026-06-27 09:16 UTC · model grok-4.3
The pith
Automation in embodied benchmark construction shifts costs toward validation, auditability, version control, and governance rather than reducing overall effort.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
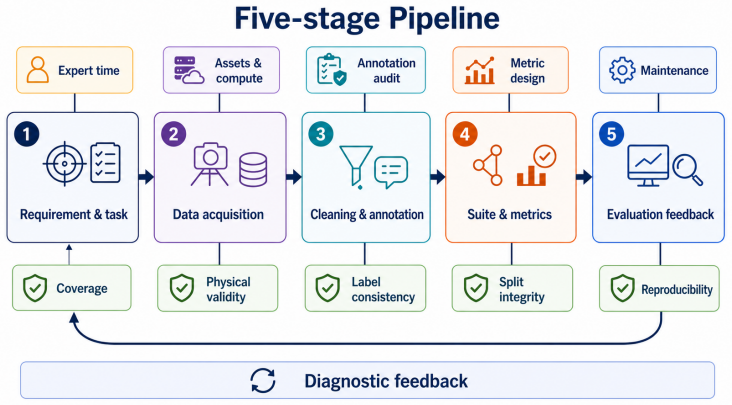
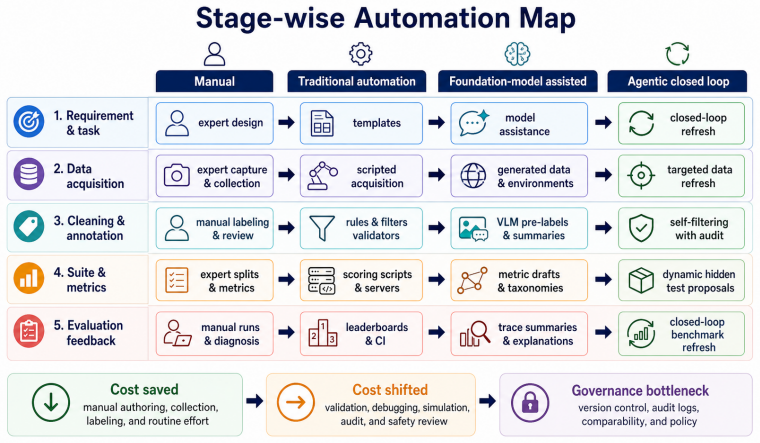
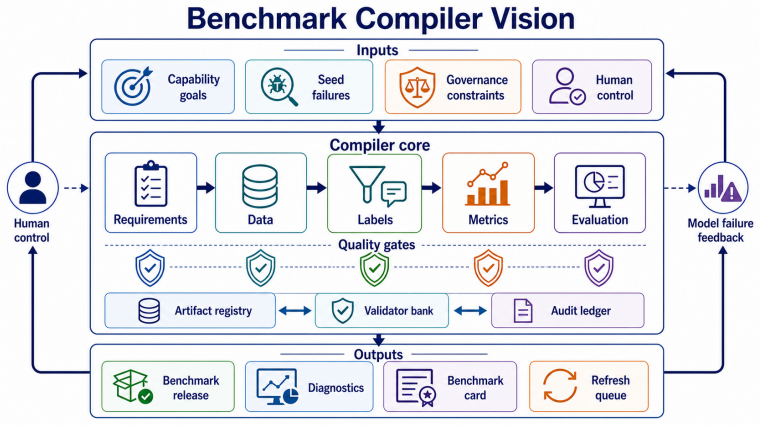
The survey concludes that embodied benchmark construction, when examined through the five-stage pipeline of requirement and task construction, data acquisition, data cleaning and annotation, benchmark suite generation and metric definition, and evaluation execution with diagnostic feedback, transitions from manual curation toward foundation-model assistance and agentic workflows, yet automation primarily shifts construction costs toward validation, auditability, version control, and long-term governance instead of lowering total expenditure.
What carries the argument
The five-stage embodied benchmark construction pipeline that structures analysis of manual-to-automated transitions across domains.
If this is right
- Benchmarks require greater investment in diagnostic feedback loops and evaluation scripts.
- Construction processes must incorporate explicit auditability and version-control mechanisms.
- Long-term maintenance and refresh policies become central to reliable embodied evaluation.
- Cost allocation shifts mean that larger suites alone will not advance evaluation quality without governance improvements.
Where Pith is reading between the lines
- The observed cost shift may limit how quickly new benchmarks can be deployed if governance overhead dominates.
- Similar relocation of effort could occur in non-embodied AI evaluation settings that adopt agentic construction.
- Developers could test whether particular automation choices, such as closed-loop agents, reduce governance burdens more than others.
- The pipeline lens implies that benchmark quality metrics should include measures of maintainability alongside task coverage.
Load-bearing premise
That the five-stage pipeline supplies a complete and representative way to examine benchmark construction efforts in navigation, manipulation, driving, and aerial domains.
What would settle it
An embodied benchmark project in which automation across the pipeline demonstrably lowered total costs in human labor, data acquisition, validation, and governance without measurable increases in any category.
Figures

read the original abstract
Embodied intelligence now spans navigation, household assistance, manipulation, autonomous driving, aerial agents, and multimodal large-model control. This expansion has made benchmark construction a central bottleneck for reliable evaluation. Unlike static datasets, embodied benchmarks combine task specifications, environments, robot data, demonstrations, annotations, metrics, evaluation scripts, and release policies into a single evaluation system. This survey reviews the literature through a five-stage construction pipeline: requirement and task construction, data acquisition, data cleaning and annotation, benchmark suite generation and metric definition, and evaluation execution with diagnostic feedback. For each stage, the survey analyzes the transition from manual curation to traditional automation, foundation-model assistance, and agentic closed-loop workflows. It also compares qualitative construction costs across human labor, data and asset acquisition, compute and simulation, validation and debugging, governance and maintenance, and rework risk. The main conclusion is that automation does not simply reduce benchmark cost. Instead, it often shifts cost toward validation, auditability, version control, and long-term governance. Progress in embodied evaluation will therefore depend not only on larger benchmark suites, but also on construction pipelines that are diagnosable, auditable, and responsibly refreshable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey organizes embodied benchmark construction literature around a five-stage pipeline (requirement/task construction, data acquisition, cleaning/annotation, suite generation/metric definition, evaluation with diagnostic feedback). It reviews transitions from manual curation to traditional automation, foundation-model assistance, and agentic workflows across navigation, manipulation, driving, and aerial domains. Qualitative cost comparisons (human labor, assets, compute, validation, governance, rework) lead to the central claim that automation shifts costs toward validation, auditability, version control, and long-term governance rather than reducing them.
Significance. If the pipeline framework and cost-shift conclusion hold, the paper supplies a coherent organizing lens for embodied evaluation that could steer future benchmark design toward diagnosable and refreshable pipelines. The stage-wise analysis across multiple domains and the explicit contrast between cost reduction and cost shifting are useful contributions for a field where benchmark construction is a recognized bottleneck.
major comments (2)
- [Pipeline definition and domain coverage sections] The cost-shift conclusion is load-bearing on the claim that the five-stage pipeline is representative of benchmark construction. The manuscript does not demonstrate that elements such as regulatory compliance, hardware-specific calibration, or long-term dataset versioning are captured within the stages; if they fall outside, the generalization across domains is at risk. (Pipeline definition and domain coverage sections)
- [Cost comparison analysis] The main conclusion that automation 'shifts rather than reduces' costs rests on qualitative stage-wise inference. No quantitative cost data, systematic extraction from the surveyed papers, or tabulated comparisons are presented to support the shift; the evidence remains illustrative rather than systematic. (Cost comparison analysis)
minor comments (2)
- [Abstract and Introduction] The abstract and introduction could more explicitly state the selection criteria used for the surveyed literature and the number of papers reviewed per stage.
- [Cost comparison section] Figure or table summarizing the cost categories across stages would improve readability of the qualitative comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our survey. The comments highlight important aspects of the pipeline's scope and the nature of our evidence. We address each point below.
read point-by-point responses
-
Referee: [Pipeline definition and domain coverage sections] The cost-shift conclusion is load-bearing on the claim that the five-stage pipeline is representative of benchmark construction. The manuscript does not demonstrate that elements such as regulatory compliance, hardware-specific calibration, or long-term dataset versioning are captured within the stages; if they fall outside, the generalization across domains is at risk. (Pipeline definition and domain coverage sections)
Authors: The five-stage pipeline is a framework synthesized from the literature reviewed in the survey, capturing the predominant workflow observed across navigation, manipulation, driving, and aerial domains. Hardware-specific calibration is addressed within the data acquisition and cleaning/annotation stages, as these involve sensor data and environment setup in the surveyed works. Long-term dataset versioning is discussed under the governance and maintenance cost category in the cost comparison analysis. Regulatory compliance, while important, is typically a post-construction consideration for deployment rather than a core stage of benchmark construction in the papers surveyed. To address the concern about generalization, we will revise the pipeline definition section to include explicit mappings of these elements to the stages and add a subsection on limitations and domain-specific considerations. revision: partial
-
Referee: [Cost comparison analysis] The main conclusion that automation 'shifts rather than reduces' costs rests on qualitative stage-wise inference. No quantitative cost data, systematic extraction from the surveyed papers, or tabulated comparisons are presented to support the shift; the evidence remains illustrative rather than systematic. (Cost comparison analysis)
Authors: We acknowledge that the cost analysis is qualitative, based on stage-wise inferences drawn from descriptions in the surveyed papers rather than numerical data. The papers in the embodied benchmark literature do not consistently report quantitative cost metrics, making a systematic quantitative extraction infeasible. Our contribution lies in organizing these qualitative observations into a coherent cost-shift narrative across human labor, assets, compute, validation, governance, and rework. We will revise the cost comparison analysis section to more explicitly describe the qualitative methodology and provide additional concrete examples from specific benchmarks to illustrate the observed shifts. revision: partial
Circularity Check
No circularity: descriptive survey with independent organizational framework
full rationale
This work is a literature survey that introduces a five-stage pipeline as an analytical structure to review embodied benchmark construction efforts. The conclusion that automation shifts costs toward validation and governance is drawn from qualitative comparisons across stages and cost categories, without any equations, fitted models, or predictions that loop back to inputs. The pipeline is presented as a review lens rather than a derived result, and no self-citation chains underpin the core claims. The analysis remains self-contained as an organizational review of external literature.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.02385 , year =
Zhiyuan Xu and Kun Wu and Junjie Wen and Jinming Li and Ning Liu and Zhengping Che and Jian Tang , title =. arXiv preprint arXiv:2402.02385 , year =. 2402.02385 , archivePrefix =
-
[2]
Aligning Cyber Space With Physical World: A Comprehensive Survey on Embodied AI , volume=
Liu, Yang and Chen, Weixing and Bai, Yongjie and Liang, Xiaodan and Li, Guanbin and Gao, Wen and Lin, Liang , year=. Aligning Cyber Space With Physical World: A Comprehensive Survey on Embodied AI , volume=. IEEE/ASME Transactions on Mechatronics , publisher=. doi:10.1109/tmech.2025.3574943 , number=
-
[3]
arXiv preprint arXiv:2503.16416 , year =
Asaf Yehudai and Lilach Eden and Alan Li and Guy Uziel and Yilun Zhao and Roy Bar-Haim and Arman Cohan and Michal Shmueli-Scheuer , title =. arXiv preprint arXiv:2503.16416 , year =. 2503.16416 , archivePrefix =
-
[4]
Proceedings of the Conference on Robot Learning , year =
Mandlekar, Ajay and Zhu, Yuke and Garg, Animesh and Booher, Jonathan and Spero, Max and Tung, Albert and Gao, Julian and Emmons, John and Gupta, Anchit and Orbay, Emre and Savarese, Silvio and Fei-Fei, Li , title =. Proceedings of the Conference on Robot Learning , year =. 1811.02790 , archivePrefix =
-
[5]
arXiv preprint arXiv:2505.14235 , year =
Yequan Wang and Aixin Sun , title =. arXiv preprint arXiv:2505.14235 , year =. 2505.14235 , archivePrefix =
-
[6]
Matterport3D: Learning from
Chang, Angel and Dai, Angela and Funkhouser, Thomas and Halber, Maciej and Nie. Matterport3D: Learning from. 3DV , year=
-
[7]
CVPR , year=
ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes , author=. CVPR , year=
-
[8]
CVPR , year=
Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments , author=. CVPR , year=
-
[9]
arXiv preprint arXiv:1712.05474 , year =
Eric Kolve and Roozbeh Mottaghi and Winson Han and Eli VanderBilt and Luca Weihs and Alvaro Herrasti and Matt Deitke and Kiana Ehsani and Daniel Gordon and Yuke Zhu and Aniruddha Kembhavi and Abhinav Gupta and Ali Farhadi , title =. arXiv preprint arXiv:1712.05474 , year =. 1712.05474 , archivePrefix =
-
[10]
ICCV , year=
Habitat: A Platform for Embodied AI Research , author=. ICCV , year=
-
[11]
Advances in Neural Information Processing Systems 34 , publisher =
Andrew Szot and Alex Clegg and Eric Undersander and Erik Wijmans and Yili Zhao and John Turner and Noah Maestre and Mustafa Mukadam and Devendra Chaplot and Oleksandr Maksymets and Aaron Gokaslan and Vladimir Vondrus and Sameer Dharur and Franziska Meier and Wojciech Galuba and Angel Chang and Zsolt Kira and Vladlen Koltun and Jitendra Malik and Manolis S...
-
[12]
CVPR , year=
VirtualHome: Simulating Household Activities via Programs , author=. CVPR , year=
-
[13]
CVPR , year=
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks , author=. CVPR , year=
-
[14]
Proceedings of the Conference on Robot Learning , publisher =
Savva, Manolis and others , title =. Proceedings of the Conference on Robot Learning , publisher =
-
[15]
Karen Liu and Jiajun Wu and Li Fei-Fei , title =
Chengshu Li and Ruohan Zhang and Josiah Wong and Cem Gokmen and Sanjana Srivastava and Roberto Martín-Martín and Chen Wang and Gabrael Levine and Wensi Ai and Benjamin Martinez and Hang Yin and Michael Lingelbach and Minjune Hwang and Ayano Hiranaka and Sujay Garlanka and Arman Aydin and Sharon Lee and Jiankai Sun and Mona Anvari and Manasi Sharma and Dhr...
-
[16]
Xavier Puig and Eric Undersander and Andrew Szot and Mikael Dallaire Cote and Tsung-Yen Yang and Ruslan Partsey and Ruta Desai and Alexander William Clegg and Michal Hlavac and So Yeon Min and Vladimír Vondruš and Theophile Gervet and Vincent-Pierre Berges and John M. Turner and Oleksandr Maksymets and Zsolt Kira and Mrinal Kalakrishnan and Jitendra Malik...
-
[17]
Julian Straub and Thomas Whelan and Lingni Ma and Yufan Chen and Erik Wijmans and Simon Green and Jakob J. Engel and Raul Mur-Artal and Carl Ren and Shobhit Verma and Anton Clarkson and Mingfei Yan and Brian Budge and Yajie Yan and Xiaqing Pan and June Yon and Yuyang Zou and Kimberly Leon and Nigel Carter and Jesus Briales and Tyler Gillingham and Elias M...
Pith/arXiv arXiv 1906
-
[18]
Habitat Matterport 3D Dataset (
Ramakrishnan, Santhosh Kumar and Gokaslan, Aaron and Maksymets, Oleksandr and Clegg, Alexander and Turner, John and Undersander, Eric and Galuba, Wojciech and Westbury, Andrew and Chang, Angel and Savva, Manolis and Zhao, Yili and Batra, Dhruv , booktitle=. Habitat Matterport 3D Dataset (
-
[19]
Conference on Robot Learning , year=
iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks , author=. Conference on Robot Learning , year=
-
[20]
IEEE Robotics and Automation Letters , year=
RLBench: The Robot Learning Benchmark and Learning Environment , author=. IEEE Robotics and Automation Letters , year=
-
[21]
CVPR , year=
SAPIEN: A SimulAted Part-based Interactive ENvironment , author=. CVPR , year=
-
[22]
International Conference on Learning Representations , year =
Jiayuan Gu and Fanbo Xiang and Xuanlin Li and Zhan Ling and Xiqiang Liu and Tongzhou Mu and Yihe Tang and Stone Tao and Xinyue Wei and Yunchao Yao and Xiaodi Yuan and Pengwei Xie and Zhiao Huang and Rui Chen and Hao Su , title =. International Conference on Learning Representations , year =
-
[23]
Baruch, Gilad and Chen, Zhuoyuan and Dehghan, Afshin and Dimry, Tal and Feigin, Yuri and Fu, Peter and Gebauer, Thomas and Joffe, Brandon and Kurz, Daniel and Schwartz, Arik and Shulman, Elad , journal=
-
[24]
Chen, Dave Zhenyu and Chang, Angel X. and Nie. ScanRefer: 3D Object Localization in. ECCV , year=
-
[25]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
JRDB: A Dataset and Benchmark of Egocentric Robot Visual Perception of Humans in Built Environments , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[26]
EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied
Wang, Tai and Mao, Xiaohan and Zhu, Chenming and Xu, Runsen and Lyu, Ruiyuan and Li, Peisen and Chen, Xiao and Zhang, Wenwei and Chen, Kai and Xue, Tianfan and Liu, Xihui and Lu, Cewu and Lin, Dahua and Pang, Jiangmiao , booktitle=. EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied
-
[27]
Du, Mengfei and Wu, Binhao and Li, Zejun and Huang, Xuanjing and Wei, Zhongyu , year=. EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models , url=. doi:10.18653/v1/2024.acl-short.33 , booktitle=
-
[28]
IEEE Robotics and Automation Letters , year=
CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks , author=. IEEE Robotics and Automation Letters , year=
-
[29]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , url=
Feng, Yihao and Gao, Chongkai and Liu, Bo and Liu, Qiang and Stone, Peter and Zhu, Yifeng and Zhu, Yuke , year=. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , url=. doi:10.52202/075280-1939 , booktitle=
-
[30]
Proceedings of the Conference on Robot Learning , publisher =
Sriram Yenamandra and Arun Ramachandran and Karmesh Yadav and Austin Wang and Mukul Khanna and Theophile Gervet and Tsung-Yen Yang and Vidhi Jain and Alexander William Clegg and John Turner and Zsolt Kira and Manolis Savva and Angel Chang and Devendra Singh Chaplot and Dhruv Batra and Roozbeh Mottaghi and Yonatan Bisk and Chris Paxton , title =. Proceedin...
-
[31]
O'Neill, Abby and Rehman, Abdul and Maddukuri, Abhiram and Gupta, Abhishek and Padalkar, Abhishek and Lee, Abraham and Pooley, Acorn and Gupta, Agrim and Mandlekar, Ajay and Jain, Ajinkya and Tung, Albert and Bewley, Alex and Herzog, Alex and Irpan, Alex and Khazatsky, Alexander and Rai, Anant and Gupta, Anchit and Wang, Andrew and Singh, Anikait and Garg...
-
[32]
Khazatsky, Alexander and Pertsch, Karl and Nair, Suraj and Balakrishna, Ashwin and Dasari, Sudeep and Karamcheti, Siddharth and Nasiriany, Soroush and Srirama, Mohan and Chen, Lawrence and Ellis, Kirsty and Fagan, Peter and Hejna, Joey and Itkina, Masha and Lepert, Marion and Ma, Yecheng and Miller, Patrick and Wu, Jimmy and Belkhale, Suneel and Dass, Shi...
-
[33]
arXiv preprint arXiv:2505.14986 , year =
Meenal Parakh and Alexandre Kirchmeyer and Beining Han and Jia Deng , title =. arXiv preprint arXiv:2505.14986 , year =. 2505.14986 , archivePrefix =
-
[34]
Proceedings of the 8th Conference on Robot Learning , publisher =
Xuanlin Li and Kyle Hsu and Jiayuan Gu and Karl Pertsch and Oier Mees and Homer Rich Walke and Chuyuan Fu and Ishikaa Lunawat and Isabel Sieh and Sean Kirmani and Sergey Levine and Jiajun Wu and Chelsea Finn and Hao Su and Quan Vuong and Ted Xiao , title =. Proceedings of the 8th Conference on Robot Learning , publisher =
-
[35]
arXiv preprint arXiv:2406.10224 , year =
Julian Straub and Daniel DeTone and Tianwei Shen and Nan Yang and Chris Sweeney and Richard Newcombe , title =. arXiv preprint arXiv:2406.10224 , year =. 2406.10224 , archivePrefix =
-
[36]
Deitke, Matt and Schwenk, Dustin and Salvador, Jordi and Weihs, Luca and Michel, Oscar and VanderBilt, Eli and Schmidt, Ludwig and Ehsanit, Kiana and Kembhavi, Aniruddha and Farhadi, Ali , year=. Objaverse: A Universe of Annotated 3D Objects , url=. doi:10.1109/cvpr52729.2023.01263 , booktitle=
-
[37]
Objaverse-XL: A Universe of 10M+ 3D Objects , url=
Deitke, Matt and Ehsani, Kiana and Fan, Alan and Farhadi, Ali and Gadre, Samir Yitzhak and Gkioxari, Georgia and Kembhavi, Aniruddha and Kusupati, Aditya and Laforte, Christian and Liu, Ruoshi and Michel, Oscar and Ngo, Huong and Schmidt, Ludwig and Vanderbilt, Eli and Voleti, Vikram and Vondrick, Carl and Wallingford, Matthew , year=. Objaverse-XL: A Uni...
-
[38]
RoboCasa: Large-Scale Simulation of Household Tasks for Generalist Robots , url=
Nasiriany, Soroush and Maddukuri, Abhiram and Zhang, Lance and Parikh, Adeet and Lo, Aaron and Joshi, Abhishek and Mandlekar, Ajay and Zhu, Yuke , year=. RoboCasa: Large-Scale Simulation of Household Tasks for Generalist Robots , url=. doi:10.15607/rss.2024.xx.050 , booktitle=
-
[39]
arXiv preprint arXiv:2603.04356 , year =
Soroush Nasiriany and Sepehr Nasiriany and Abhiram Maddukuri and Yuke Zhu , title =. arXiv preprint arXiv:2603.04356 , year =. 2603.04356 , archivePrefix =
-
[40]
Zhang, Shiduo and Xu, Zhe and Liu, Peiju and Yu, Xiaopeng and Li, Yuan and Gao, Qinghui and Fei, Zhaoye and Yin, Zhangyue and Wu, Zuxuan and Jiang, Yu-Gang and Qiu, Xipeng , year=. VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks , url=. doi:10.1109/iccv51701.2025.01037 , booktitle=
-
[41]
Advances in Neural Information Processing Systems , year=
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making , author=. Advances in Neural Information Processing Systems , year=
-
[42]
arXiv preprint arXiv:2501.11858 , year =
Zhili Cheng and Yuge Tu and Ran Li and Shiqi Dai and Jinyi Hu and Shengding Hu and Jiahao Li and Yang Shi and Tianyu Yu and Weize Chen and Lei Shi and Maosong Sun , title =. arXiv preprint arXiv:2501.11858 , year =. 2501.11858 , archivePrefix =
-
[43]
arXiv preprint arXiv:2502.09560 , year =
Rui Yang and Hanyang Chen and Junyu Zhang and Mark Zhao and Cheng Qian and Kangrui Wang and Qineng Wang and Teja Venkat Koripella and Marziyeh Movahedi and Manling Li and Heng Ji and Huan Zhang and Tong Zhang , title =. arXiv preprint arXiv:2502.09560 , year =. 2502.09560 , archivePrefix =
-
[44]
arXiv preprint arXiv:2412.13178 , year =
Sheng Yin and Xianghe Pang and Yuanzhuo Ding and Menglan Chen and Yutong Bi and Yichen Xiong and Wenhao Huang and Zhen Xiang and Jing Shao and Siheng Chen , title =. arXiv preprint arXiv:2412.13178 , year =. 2412.13178 , archivePrefix =
-
[45]
arXiv preprint arXiv:2604.11174 , year =
Xue Qin and Simin Luan and John See and Cong Yang and Zhijun Li , title =. arXiv preprint arXiv:2604.11174 , year =. 2604.11174 , archivePrefix =
-
[46]
Advances in Neural Information Processing Systems 35 , publisher =
Matt Deitke and Eli VanderBilt and Alvaro Herrasti and Luca Weihs and Jordi Salvador and Kiana Ehsani and Winson Han and Eric Kolve and Ali Farhadi and Aniruddha Kembhavi and Roozbeh Mottaghi , title =. Advances in Neural Information Processing Systems 35 , publisher =
-
[47]
Conference on Robot Learning , year=
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations , author=. Conference on Robot Learning , year=
-
[48]
International Conference on Learning Representations , year =
Wang, Lirui and Ling, Yiyang and Yuan, Zhecheng and Shridhar, Mohit and Bao, Chen and Qin, Yuzhe and Wang, Bailin and Xu, Huazhe and Wang, Xiaolong , title =. International Conference on Learning Representations , year =
-
[49]
arXiv preprint arXiv:2410.03645 , year =
Pu Hua and Minghuan Liu and Annabella Macaluso and Yunfeng Lin and Weinan Zhang and Huazhe Xu and Lirui Wang , title =. arXiv preprint arXiv:2410.03645 , year =. 2410.03645 , archivePrefix =
-
[50]
Proceedings of the 41st International Conference on Machine Learning , publisher =
Yufei Wang and Zhou Xian and Feng Chen and Tsun-Hsuan Wang and Yian Wang and Katerina Fragkiadaki and Zackory Erickson and David Held and Chuang Gan , title =. Proceedings of the 41st International Conference on Machine Learning , publisher =
-
[51]
Vbench: Comprehensive benchmark suite for video generative models
Yang, Yue and Sun, Fan-Yun and Weihs, Luca and Vanderbilt, Eli and Herrasti, Alvaro and Han, Winson and Wu, Jiajun and Haber, Nick and Krishna, Ranjay and Liu, Lingjie and Callison-Burch, Chris and Yatskar, Mark and Kembhavi, Aniruddha and Clark, Christopher , year=. Holodeck: Language Guided Generation of 3D Embodied AI Environments , url=. doi:10.1109/c...
-
[52]
International Conference on Learning Representations , year =
Yecheng Jason Ma and William Liang and Guanzhi Wang and De-An Huang and Osbert Bastani and Dinesh Jayaraman and Yuke Zhu and Linxi Fan and Anima Anandkumar , title =. International Conference on Learning Representations , year =
-
[53]
DrEureka: Language Model Guided Sim-To-Real Transfer , url=
Ma, Yecheng and Liang, William and Wang, Hung-Ju and Zhu, Yuke and Fan, Linxi and Bastani, Osbert and Jayaraman, Dinesh , year=. DrEureka: Language Model Guided Sim-To-Real Transfer , url=. doi:10.15607/rss.2024.xx.094 , booktitle=
-
[54]
arXiv preprint arXiv:2407.10943 , year =
Hanqing Wang and Jiahe Chen and Wensi Huang and Qingwei Ben and Tai Wang and Boyu Mi and Tao Huang and Siheng Zhao and Yilun Chen and Sizhe Yang and Peizhou Cao and Wenye Yu and Zichao Ye and Jialun Li and Junfeng Long and Zirui Wang and Huiling Wang and Ying Zhao and Zhongying Tu and Yu Qiao and Dahua Lin and Jiangmiao Pang , title =. arXiv preprint arXi...
-
[55]
arXiv preprint arXiv:2412.05789 , year =
Pengzhen Ren and Min Li and Zhen Luo and Xinshuai Song and Ziwei Chen and Weijia Liufu and Yixuan Yang and Hao Zheng and Rongtao Xu and Zitong Huang and Tongsheng Ding and Luyang Xie and Kaidong Zhang and Changfei Fu and Yang Liu and Liang Lin and Feng Zheng and Xiaodan Liang , title =. arXiv preprint arXiv:2412.05789 , year =. 2412.05789 , archivePrefix =
-
[56]
arXiv preprint arXiv:2507.00435 , year =
Yi Ru Wang and Carter Ung and Christopher Tan and Grant Tannert and Jiafei Duan and Josephine Li and Anh Le and Rishabh Oswal and Markus Grotz and Wilbert Pumacay and Yuquan Deng and Ranjay Krishna and Dieter Fox and Siddhartha Srinivasa , title =. arXiv preprint arXiv:2507.00435 , year =. 2507.00435 , archivePrefix =
-
[57]
arXiv preprint arXiv:2604.11674 , year =
Mingyang Li and Haofan Xu and Haowen Sun and Xinzhe Chen and Sihua Ren and Liqi Huang and Xinyang Sui and Chenyang Miao and Jiawei Ye and Qiongjie Cui and Zeyang Liu and Xingyu Chen and Xuguang Lan , title =. arXiv preprint arXiv:2604.11674 , year =. 2604.11674 , archivePrefix =
-
[58]
Towards multi-layered 3d garments animation
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollár, Piotr and Girshick, Ross , year=. Segment Anything , url=. doi:10.1109/iccv51070.2023.00371 , booktitle=
-
[59]
Proceedings of the VLDB Endowment , volume=
Snorkel: Rapid Training Data Creation with Weak Supervision , author=. Proceedings of the VLDB Endowment , volume=
-
[60]
NAACL , year=
Dynabench: Rethinking Benchmarking in NLP , author=. NAACL , year=
-
[61]
DataPerf: Benchmarks for Data-Centric
Mazumder, Mark and Banbury, Colby and Yao, Xiaozhe and Karlas, Bojan and Gaviria Rojas, William and Diamos, Sudnya and Diamos, Greg and He, Lynn and Aroyo, Lora and Acun, Bilge and others , booktitle=. DataPerf: Benchmarks for Data-Centric
-
[62]
Transactions on Machine Learning Research , year=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , year=
-
[63]
CVPR Workshops , year=
EvalAI: Towards Better Evaluation Systems for AI Agents , author=. CVPR Workshops , year=
-
[64]
Communications of the ACM , volume=
Datasheets for Datasets , author=. Communications of the ACM , volume=
-
[65]
Pushkarna, Mahima and Zaldivar, Andrew and Kjartansson, Oddur , year=. Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI , url=. doi:10.1145/3531146.3533231 , booktitle=
-
[66]
FAT* , year=
Model Cards for Model Reporting , author=. FAT* , year=
-
[67]
arXiv preprint arXiv:2410.12974 , year =
Anna Sokol and Elizabeth Daly and Michael Hind and David Piorkowski and Xiangliang Zhang and Nuno Moniz and Nitesh Chawla , title =. arXiv preprint arXiv:2410.12974 , year =. 2410.12974 , archivePrefix =
-
[68]
and Sunderhauf, Niko and Dean, Jake E
Leitner, Jurgen and Tow, Adam W. and Sunderhauf, Niko and Dean, Jake E. and Durham, Joseph W. and Cooper, Matthew and Eich, Markus and Lehnert, Christopher and Mangels, Ruben and McCool, Christopher and Kujala, Peter T. and Nicholson, Lachlan and Pham, Trung and Sergeant, James and Wu, Liao and Zhang, Fangyi and Upcroft, Ben and Corke, Peter , year=. The ...
-
[69]
arXiv preprint arXiv:2411.13808 , year =
Patricia Paskov and Lukas Berglund and Everett Smith and Lisa Soder , title =. arXiv preprint arXiv:2411.13808 , year =. 2411.13808 , archivePrefix =
-
[70]
BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices , url=
Hardy, Amelia and Hardy, Malcolm and Kochenderfer, Mykel and Lamparth, Max and Reuel, Anka and Smith, Chandler , year=. BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices , url=. doi:10.52202/079017-0685 , booktitle=
-
[71]
arXiv preprint arXiv:2504.13839 , year =
Leon Staufer and Mick Yang and Anka Reuel and Stephen Casper , title =. arXiv preprint arXiv:2504.13839 , year =. 2504.13839 , archivePrefix =
-
[72]
arXiv preprint arXiv:2510.17950 , year =
Adina Yakefu and Bin Xie and Chongyang Xu and Enwen Zhang and Erjin Zhou and Fan Jia and Haitao Yang and Haoqiang Fan and Haowei Zhang and Hongyang Peng and Jing Tan and Junwen Huang and Kai Liu and Kaixin Liu and Kefan Gu and Qinglun Zhang and Ruitao Zhang and Saike Huang and Shen Cheng and Shuaicheng Liu and Tiancai Wang and Tiezhen Wang and Wei Sun and...
-
[73]
Field and Service Robotics , year=
AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles , author=. Field and Service Robotics , year=
-
[74]
Dosovitskiy, Alexey and Ros, German and Codevilla, Felipe and Lopez, Antonio and Koltun, Vladlen , booktitle=
-
[75]
Proceedings of the 4th Conference on Robot Learning , publisher =
Ming Zhou and Jun Luo and Julian Villella and Yaodong Yang and David Rusu and Jiayu Miao and Weinan Zhang and Montgomery Alban and Iman Fadakar and Zheng Chen and Aurora Chongxi Huang and Ying Wen and Kimia Hassanzadeh and Daniel Graves and Dong Chen and Zhengbang Zhu and Nhat Nguyen and Mohamed Elsayed and Kun Shao and Sanjeevan Ahilan and Baokuan Zhang ...
-
[76]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
MetaDrive: Composing Diverse Driving Scenarios for Generalizable Reinforcement Learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[77]
Conference on Robot Learning , year=
Flightmare: A Flexible Quadrotor Simulator , author=. Conference on Robot Learning , year=
-
[78]
ICCV , year=
AerialVLN: Vision-and-Language Navigation for UAVs , author=. ICCV , year=
-
[79]
ScenarioNet: Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling , url=
Duan, Chenda and Feng, Lan and Li, Quanyi and Liu, Zhizheng and Mo, Wenjie and Peng, Zhenghao (Mark) and Zhou, Bolei , year=. ScenarioNet: Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling , url=. doi:10.52202/075280-0172 , booktitle=
-
[80]
Guo, Mingning and Wu, Mengwei and He, Jiarun and Li, Shaoxian and Li, Haifeng and Tao, Chao , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.