Beyond Fully Random Masking: Attention-Guided Denoising and Optimization for Diffusion Language Models
Pith reviewed 2026-06-27 09:31 UTC · model grok-4.3
The pith
Attention patterns in diffusion language models allow guided denoising to outperform random masking on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that aligning the denoising order and the emphasis in supervised fine-tuning and reinforcement learning with attention structure from the model itself allows diffusion language models to better capture token dependencies, resulting in improved reasoning performance over random masking approaches.
What carries the argument
AGDO framework that determines denoising order based on attention structure and emphasizes attention-critical tokens during training.
If this is right
- AGDO improves reasoning performance consistently on mathematical and coding benchmarks.
- It outperforms state-of-the-art post-training methods for dLLMs.
- Tokens with stronger attention to unmasked context play a critical role in generation stability and reasoning.
- The attention-guided approach aligns training and optimization with intrinsic dependencies.
Where Pith is reading between the lines
- This method could be tested on other tasks like natural language inference to see if gains generalize.
- Attention guidance might be combined with different diffusion schedules for further optimization.
- Similar analysis could be applied to autoregressive models to see if attention stability holds there too.
- Implementing this in inference time without retraining might be a next step to explore.
Load-bearing premise
The empirical observation that attention strength to unmasked context indicates generation stability holds across different models and tasks.
What would settle it
Running the same experiments but with a different attention calculation or on a model where attention does not correlate with stability, and seeing if AGDO still improves performance.
Figures




read the original abstract
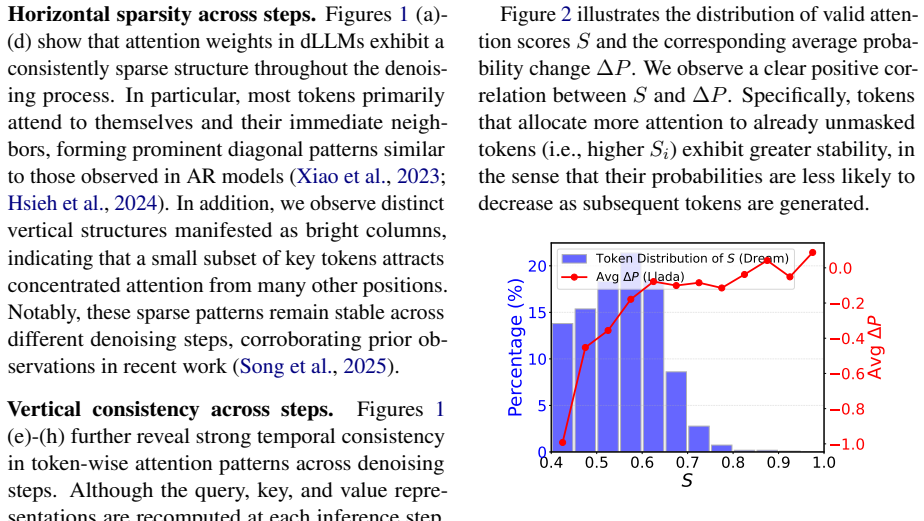
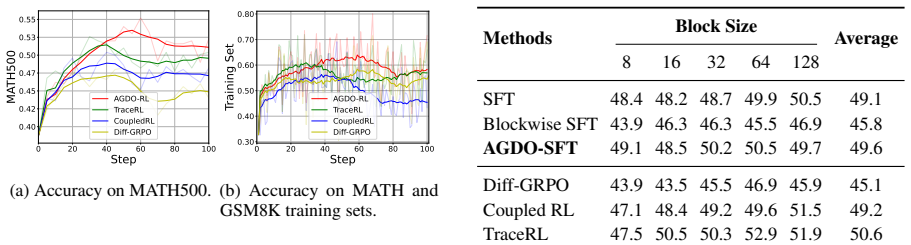
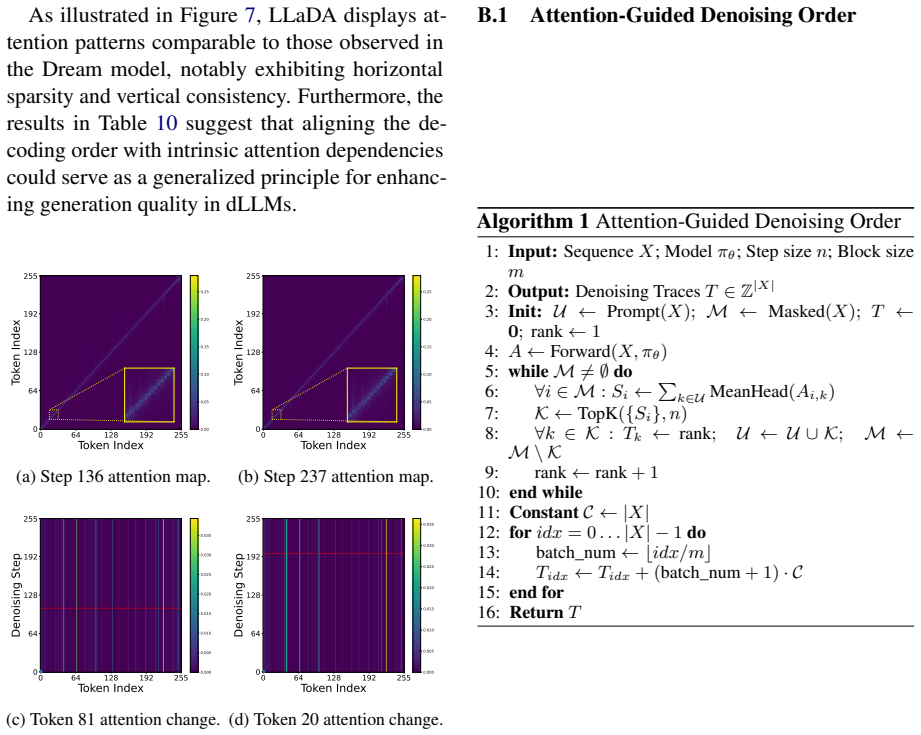
Diffusion large language models (dLLMs) offer an efficient alternative to autoregressive models through parallel decoding, yet existing post-training methods largely rely on random masking strategies that overlook intrinsic token dependencies. In this work, we present an empirical analysis of attention in dLLMs and show that tokens attending more strongly to unmasked context exhibit greater generation stability and play a critical role in reasoning. Motivated by these findings, we propose AGDO, an attention-guided denoising and optimization framework that aligns both training and optimization with attention-derived dependencies. AGDO determines the denoising order based on attention structure and emphasizes attention-critical tokens during supervised fine-tuning and reinforcement learning. Experiments on mathematical and coding benchmarks demonstrate that AGDO consistently improves reasoning performance, outperforming state-of-the-art post-training methods for dLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an empirical analysis of attention in diffusion language models (dLLMs) reveals tokens attending more strongly to unmasked context exhibit greater generation stability and are critical for reasoning; motivated by this, it proposes the AGDO framework that determines denoising order from attention structure and emphasizes attention-critical tokens during SFT and RL, yielding consistent improvements on mathematical and coding benchmarks that outperform SOTA post-training methods for dLLMs.
Significance. If the empirical findings and performance gains hold with proper controls, AGDO would offer a principled alternative to random masking in dLLM post-training by aligning denoising and optimization with attention-derived token dependencies, potentially advancing non-autoregressive generation for reasoning tasks.
major comments (2)
- [Experiments] The central claim that attention-guided ordering (rather than emphasis or general optimization) drives the reported gains requires an ablation that holds emphasis fixed while randomizing order (or vice versa). No such control is described, leaving open the possibility that gains arise from the emphasis component alone.
- [Abstract] The abstract states performance gains on math and coding benchmarks but supplies no quantitative results, error bars, dataset details, baseline numbers, or statistical tests, preventing verification of the claim that AGDO 'consistently improves' and 'outperforms SOTA'.
minor comments (1)
- [Abstract] The acronym 'dLLMs' is introduced without expansion in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and claims.
read point-by-point responses
-
Referee: [Experiments] The central claim that attention-guided ordering (rather than emphasis or general optimization) drives the reported gains requires an ablation that holds emphasis fixed while randomizing order (or vice versa). No such control is described, leaving open the possibility that gains arise from the emphasis component alone.
Authors: We agree that isolating the contribution of attention-guided ordering from the emphasis component is important for substantiating the central claim. The current experiments evaluate the full AGDO framework, which combines both elements. In the revised manuscript we will add a dedicated ablation that holds the emphasis mechanism fixed while comparing attention-guided denoising order against random order, thereby clarifying the specific role of the ordering strategy. revision: yes
-
Referee: [Abstract] The abstract states performance gains on math and coding benchmarks but supplies no quantitative results, error bars, dataset details, baseline numbers, or statistical tests, preventing verification of the claim that AGDO 'consistently improves' and 'outperforms SOTA'.
Authors: We acknowledge that the abstract is currently qualitative and lacks specific numbers. We will revise the abstract to report key quantitative improvements (e.g., absolute gains on GSM8K, MATH, and HumanEval), reference the evaluation datasets, and note that main-text results include multiple runs with standard deviations and baseline comparisons. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper motivates AGDO from an empirical analysis of attention patterns in dLLMs and reports benchmark improvements from the resulting training/optimization procedure. No equations, self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described framework; the performance claims rest on external experimental outcomes rather than reducing to the method's own definitions or inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[9]
arXiv preprint arXiv:2210.08933 , year=
Diffuseq: Sequence to sequence text generation with diffusion models , author=. arXiv preprint arXiv:2210.08933 , year=
-
[10]
arXiv preprint arXiv:2508.15487 , year=
Dream 7b: Diffusion large language models , author=. arXiv preprint arXiv:2508.15487 , year=
-
[11]
arXiv preprint arXiv:2502.09992 , year=
Large language diffusion models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[12]
arXiv preprint arXiv:2510.06303 , year=
SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation , author=. arXiv preprint arXiv:2510.06303 , year=
-
[13]
arXiv preprint arXiv:2410.17891 , year=
Scaling diffusion language models via adaptation from autoregressive models , author=. arXiv preprint arXiv:2410.17891 , year=
-
[14]
arXiv preprint arXiv:2508.10875 , year=
A survey on diffusion language models , author=. arXiv preprint arXiv:2508.10875 , year=
-
[15]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[16]
arXiv preprint arXiv:2505.22618 , year=
Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding , author=. arXiv preprint arXiv:2505.22618 , year=
-
[17]
arXiv preprint arXiv:2510.04147 , year=
Self Speculative Decoding for Diffusion Large Language Models , author=. arXiv preprint arXiv:2510.04147 , year=
-
[18]
arXiv preprint arXiv:2506.06295 , year=
dllm-cache: Accelerating diffusion large language models with adaptive caching , author=. arXiv preprint arXiv:2506.06295 , year=
-
[19]
arXiv preprint arXiv:2510.05040 , year=
Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts , author=. arXiv preprint arXiv:2510.05040 , year=
-
[20]
arXiv preprint arXiv:2509.25188 , year=
Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding , author=. arXiv preprint arXiv:2509.25188 , year=
-
[21]
arXiv preprint arXiv:2505.20199 , year=
Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking , author=. arXiv preprint arXiv:2505.20199 , year=
-
[22]
2025 , eprint=
Beyond Fixed: Training-Free Variable-Length Denoising for Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
Mercury: Ultra-Fast Language Models Based on Diffusion , author=. 2025 , eprint=
2025
-
[24]
arXiv preprint arXiv:2506.20639 , year=
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation , author=. arXiv preprint arXiv:2506.20639 , year=
-
[25]
arXiv preprint arXiv:2507.08838 , year=
wd1: Weighted policy optimization for reasoning in diffusion language models , author=. arXiv preprint arXiv:2507.08838 , year=
-
[26]
arXiv preprint arXiv:2510.09541 , year=
Spg: Sandwiched policy gradient for masked diffusion language models , author=. arXiv preprint arXiv:2510.09541 , year=
-
[27]
arXiv preprint arXiv:2504.12216 , year=
d1: Scaling reasoning in diffusion large language models via reinforcement learning , author=. arXiv preprint arXiv:2504.12216 , year=
-
[28]
arXiv preprint arXiv:2505.19223 , year=
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author=. arXiv preprint arXiv:2505.19223 , year=
-
[29]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =. 2402.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[30]
arXiv preprint arXiv:2406.03736 , year=
Your absorbing discrete diffusion secretly models the conditional distributions of clean data , author=. arXiv preprint arXiv:2406.03736 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[33]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[34]
arXiv preprint arXiv:2508.02260 , year=
Decomposing the entropy-performance exchange: The missing keys to unlocking effective reinforcement learning , author=. arXiv preprint arXiv:2508.02260 , year=
-
[35]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[36]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[37]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[38]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[39]
arXiv preprint arXiv:2406.19314 , volume=
Livebench: A challenging, contamination-free llm benchmark , author=. arXiv preprint arXiv:2406.19314 , volume=
-
[40]
arXiv preprint arXiv:2403.07974 , year=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
-
[41]
arXiv preprint arXiv:2509.06949 , year=
Revolutionizing reinforcement learning framework for diffusion large language models , author=. arXiv preprint arXiv:2509.06949 , year=
-
[42]
arXiv preprint arXiv:2407.10671 , volume=
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , volume=
-
[43]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[44]
arXiv preprint arXiv:2412.01152 , year=
Intellect-1 technical report , author=. arXiv preprint arXiv:2412.01152 , year=
-
[45]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[46]
arXiv preprint arXiv:2506.17298 , volume=
Mercury: Ultra-fast language models based on diffusion , author=. arXiv preprint arXiv:2506.17298 , volume=
-
[47]
arXiv preprint arXiv:2508.19529 , year=
Blockwise sft for diffusion language models: Reconciling bidirectional attention and autoregressive decoding , author=. arXiv preprint arXiv:2508.19529 , year=
-
[48]
arXiv preprint arXiv:2508.02558 , year=
Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction , author=. arXiv preprint arXiv:2508.02558 , year=
-
[49]
arXiv preprint arXiv:2309.17453 , year=
Efficient streaming language models with attention sinks , author=. arXiv preprint arXiv:2309.17453 , year=
-
[50]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Found in the middle: Calibrating positional attention bias improves long context utilization , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[51]
arXiv preprint arXiv:2512.15176 , year=
DEER: Draft with Diffusion, Verify with Autoregressive Models , author=. arXiv preprint arXiv:2512.15176 , year=
-
[52]
arXiv preprint arXiv:2510.13554 , year=
Attention illuminates llm reasoning: The preplan-and-anchor rhythm enables fine-grained policy optimization , author=. arXiv preprint arXiv:2510.13554 , year=
-
[53]
arXiv preprint arXiv:2411.19943 , year=
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability , author=. arXiv preprint arXiv:2411.19943 , year=
-
[54]
Proceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP , pages=
What does BERT look at? an analysis of BERT’s attention , author=. Proceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP , pages=
2019
-
[55]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[56]
Commonsenseqa: A question answering challenge targeting commonsense knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.