Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks
Pith reviewed 2026-06-27 10:36 UTC · model grok-4.3
The pith
Adapter design determines whether OpenClaw-style harnesses can resolve GitHub issues effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
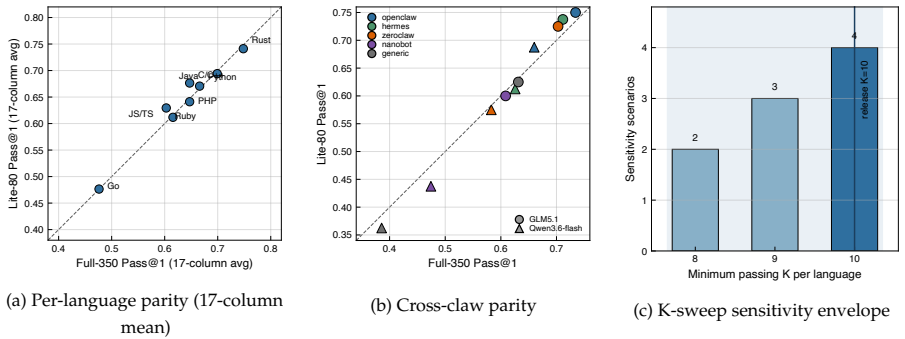
Claw-SWE-Bench supplies 350 GitHub issue-resolution instances drawn from existing SWE-bench collections after future-commit cleanup, together with an adapter protocol that enforces uniform prompt, budget, workspace, patch, and evaluator rules. Under these conditions the minimal direct-diff adapter achieves only 19.1 percent Pass@1 while the full adapter reaches 73.4 percent on the same GLM 5.1 backbone. Across model and harness sweeps the paper records comparable performance swings from model choice and from harness choice, plus cost differences among equally accurate systems.
What carries the argument
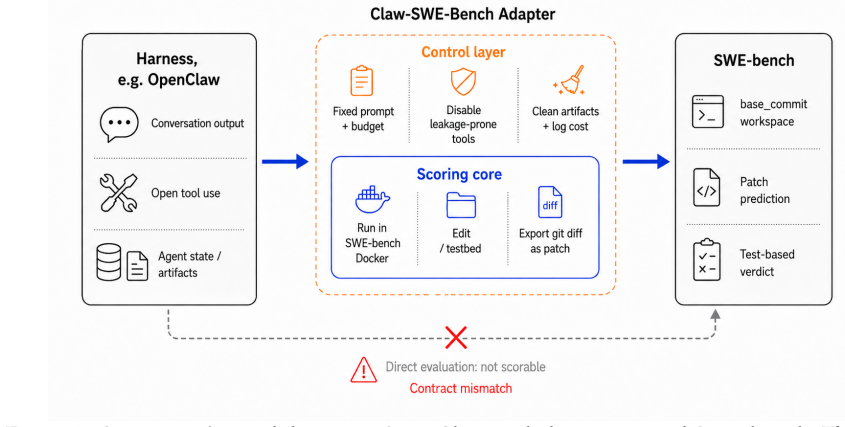
The adapter protocol and standardized workspace contract that convert a generic OpenClaw-style harness into a scorer-compatible prediction on a fixed coding task.
If this is right
- Harness design can shift Pass@1 by more than fifty percentage points under a fixed model.
- Model choice and harness choice produce roughly equal swings in accuracy.
- Accuracy alone does not determine total API cost; some harnesses are more expensive even when equally accurate.
- The lite subset allows rapid iteration on harness improvements before full-benchmark runs.
Where Pith is reading between the lines
- Other agent frameworks could adopt the same adapter standardization to compare internal components on coding tasks.
- Focusing on adapter improvements may let lower-cost models reach the accuracy of higher-cost ones.
- The benchmark could be reused to test whether harnesses that work well on these repositories also handle entirely new codebases.
- Cost differences imply that harness selection should be treated as an optimization target alongside accuracy.
Load-bearing premise
The 350 cleaned instances plus the fixed prompt, budget, workspace rules, patch procedure, and evaluator form a fair test that isolates harness differences without selection bias.
What would settle it
Running the minimal and full adapters on a fresh draw of 350 instances from the same source pools but with a changed patch-extraction rule or evaluator and finding the performance gap disappears.
Figures


read the original abstract
General-purpose agents such as OpenClaw are increasingly used as autonomous tool users, but their coding ability is difficult to measure under SWE-bench: a generic agent does not by itself satisfy the clean Docker workspace, patch, and prediction contract required for scoring. We introduce Claw-SWE-Bench, a multilingual SWE-bench-style benchmark and adapter protocol that makes heterogeneous agent harnesses, or claws, comparable under fair settings including a fixed prompt, runtime budget, workspace contract, patch extraction procedure, and evaluator. The full benchmark contains 350 GitHub issue-resolution instances across 8 languages and 43 repositories, drawn from SWE-bench-Multilingual and SWE-bench-Verified-Mini after future-commit cleanup. We also release Claw-SWE-Bench Lite for faster validation, which is an 80-instance subset selected by a cost-aware, rank-aware procedure over 17 calibration columns. On the full benchmark, OpenClaw with a minimal direct-diff adapter scores only $19.1\%$ Pass@1, whereas the full adapter reaches $73.4\%$ with the same GLM 5.1 backbone, showing that adapter design is essential for enabling OpenClaw-style harnesses to perform coding tasks effectively. Across an OpenClaw $\times$ nine-model sweep and a five-claw $\times$ two-model sweep, model choice changes Pass@1 by $29.4$ pp and harness choice by $27.4$ pp under fixed models; systems with similar accuracy can differ substantially in total API cost. Claw-SWE-Bench therefore treats harness and cost accounting as first-class axes of SWE-style coding-agent evaluation, providing both a full benchmark and a low-cost reference set for reproducible comparison. The data is available at https://github.com/opensquilla/claw-swe-bench and https://huggingface.co/datasets/TokenRhythm/Claw-SWE-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Claw-SWE-Bench, a benchmark of 350 GitHub issue-resolution instances across 8 languages drawn from SWE-bench-Multilingual and SWE-bench-Verified-Mini after future-commit cleanup, together with an 80-instance Lite subset. It provides a standardized adapter protocol, fixed prompt, runtime budget, workspace contract, patch extraction, and evaluator to compare OpenClaw-style harnesses. Experiments report that a minimal direct-diff adapter scores 19.1% Pass@1 while the full adapter reaches 73.4% on the same GLM 5.1 backbone; model choice shifts Pass@1 by 29.4 pp and harness choice by 27.4 pp under fixed models, with systems differing in API cost. Public data releases are provided.
Significance. If the instance selection is representative, the work supplies concrete empirical evidence that adapter design is a first-class factor in enabling agent harnesses on SWE-style tasks, comparable in magnitude to model choice, while treating cost accounting as an explicit evaluation axis. The public full and Lite benchmarks with released data links directly support reproducible comparison.
major comments (1)
- [Abstract and Benchmark Construction] The headline claim that adapter design is essential (19.1% vs 73.4% Pass@1 on GLM 5.1) depends on the 350 instances forming an unbiased testbed. The selection after future-commit cleanup from the source SWE-bench sets, together with the cost-aware rank-aware procedure over 17 calibration columns used for the Lite subset, may retain issues that disproportionately reward adapters satisfying the workspace/patch contracts. No comparison of the resulting distribution to the original unfiltered SWE-bench statistics is reported. This is load-bearing for the adapter-importance conclusion (Abstract).
minor comments (1)
- [Abstract] Full methodology details on the exact instance-selection criteria, future-commit cleanup rules, and evaluator implementation are referenced but not fully specified, which would aid independent verification of the reported Pass@1 numbers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment raises a valid point about benchmark construction and representativeness, which we address below. We will incorporate additional analysis to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Benchmark Construction] The headline claim that adapter design is essential (19.1% vs 73.4% Pass@1 on GLM 5.1) depends on the 350 instances forming an unbiased testbed. The selection after future-commit cleanup from the source SWE-bench sets, together with the cost-aware rank-aware procedure over 17 calibration columns used for the Lite subset, may retain issues that disproportionately reward adapters satisfying the workspace/patch contracts. No comparison of the resulting distribution to the original unfiltered SWE-bench statistics is reported. This is load-bearing for the adapter-importance conclusion (Abstract).
Authors: We thank the referee for this important observation. The 350 instances are obtained by applying future-commit cleanup to SWE-bench-Multilingual and SWE-bench-Verified-Mini; this is a standard preprocessing step required for valid evaluation, as agents cannot access code committed after the issue date. No further filtering based on adapter compatibility was performed. The Lite subset is constructed via a cost-aware, rank-aware selection over 17 calibration columns to ensure diversity while controlling evaluation cost. We agree that an explicit distributional comparison (language proportions, repository characteristics, issue complexity metrics, etc.) to the unfiltered source sets was not reported and would strengthen the paper. In revision we will add a table and accompanying text providing these statistics before and after selection. On the concern that retained instances may disproportionately reward adapters satisfying the workspace/patch contracts: all harnesses evaluated in the paper (including the minimal direct-diff adapter) operate under identical standardized contracts, fixed prompts, runtime budgets, and evaluators. The 19.1% vs 73.4% gap on GLM 5.1 therefore isolates the effect of adapter design within this uniform protocol. The benchmark's purpose is to supply a reproducible, contract-compliant testbed for comparing OpenClaw-style harnesses rather than to exactly replicate the source distribution; the added comparison will help confirm that the selection preserves core characteristics of the originals. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper introduces Claw-SWE-Bench and reports empirical Pass@1 scores from running adapters and models on a fixed set of 350 instances drawn from existing SWE-bench sources. The central claim (adapter design matters) rests on direct experimental comparisons such as 19.1% vs 73.4% under identical backbones, with no derivation, equation, or first-principles result that reduces to its own inputs by construction. Instance selection and evaluation protocol are described as fixed inputs to the benchmark rather than outputs derived from the measured quantities. No self-citation chain, fitted-parameter renaming, or ansatz smuggling appears in the reported results.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
EnterpriseClawBench: Benchmarking Agents from Real Workplace Sessions
EnterpriseClawBench is a benchmark for enterprise agents constructed from proprietary real-world sessions, with the reusable contribution being the construction and evaluation protocol rather than the data itself.
-
From Question Answering to Task Completion: A Survey on Agent System and Harness Design
Survey framing LLM agents as model-plus-harness systems, decomposing harness responsibilities, mapping them to tasks, and highlighting open challenges in evaluation, safety, and co-evolution.
Reference graph
Works this paper leans on
-
[1]
Qwen3.6-Flash: Efficient variant of the Qwen3.6 series
Alibaba Cloud Qwen Team. Qwen3.6-Flash: Efficient variant of the Qwen3.6 series. Model card and API,https://github.com/QwenLM/Qwen3.6, 2026
2026
-
[2]
Introducing claude opus 4.7
Anthropic. Introducing claude opus 4.7. Product release announcement, https://www. anthropic.com/news/claude-opus-4-7, April 2026
2026
-
[3]
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[4]
ByteDance Seed 2.0-mini
ByteDance Seed Team. ByteDance Seed 2.0-mini. Model release, https://seed.byted ance.com/en/seed2, February 2026
2026
-
[5]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P . d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P . Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P . Tillet, F. P . Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herber...
Pith/arXiv arXiv 2021
-
[6]
Claw bench: The definitive ai agent benchmark
Claw Bench Team. Claw bench: The definitive ai agent benchmark. GitHub repository, https://github.com/claw-bench/claw-bench ; leaderboard at https://clawbe nch.net, 2026
2026
-
[7]
DeepSeek-V4-Flash: Fast and economical model of the DeepSeek-V4 preview release
DeepSeek-AI. DeepSeek-V4-Flash: Fast and economical model of the DeepSeek-V4 preview release. API release notes, https://api-docs.deepseek.com/news/news260424 ; weights at https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash , April 2026
2026
-
[8]
DeepSeek-V4 preview release
DeepSeek-AI. DeepSeek-V4 preview release. API release notes, https://api-docs.de epseek.com/news/news260424; weights athttps://huggingface.co/deepseek-a i/DeepSeek-V4-Pro, April 2026
2026
-
[9]
X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V . Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
Pith/arXiv arXiv 2025
-
[10]
S. Ding, X. Dai, L. Xing, S. Ding, Z. Liu, J. Yang, P . Yang, Z. Zhang, X. Wei, Y. Ma, H. Duan, J. Shao, J. Wang, D. Lin, K. Chen, and Y. Zang. Wildclawbench: An in-the-wild benchmark for ai agents in the openclaw environment. GitHub repository,https://github.com/I nternLM/WildClawBench, 2026
2026
-
[11]
Y. Ding, Z. Wang, W. U. Ahmad, H. Ding, M. Tan, N. Jain, M. K. Ramanathan, R. Nallapati, P . Bhatia, D. Roth, and B. Xiang. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks T rack, 2023
2023
-
[12]
Z. Fan, K. Vasilevski, D. Lin, B. Chen, Y. Chen, Z. Zhong, J. M. Zhang, P . He, and A. E. Hassan. Swe-effi: Re-evaluating software ai agent system effectiveness under resource constraints.arXiv preprint arXiv:2509.09853, 2025
arXiv 2025
-
[13]
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938, 2021
Pith/arXiv arXiv 2021
-
[14]
nanobot: The ultra-lightweight personal AI agent
HKUDS. nanobot: The ultra-lightweight personal AI agent. GitHub repository, https: //github.com/HKUDS/nanobot, 2026
2026
-
[15]
Hobbhahn
M. Hobbhahn. Swebench-verified-mini: A compact 50-instance subset of swe-bench verified. GitHub repository,https://github.com/mariushobbhahn/SWEBench-ver ified-mini, 2025. Hugging Face dataset: https://huggingface.co/datasets/Ma riusHobbhahn/swe-bench-verified-mini
2025
-
[16]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2024. 16
Pith/arXiv arXiv 2024
-
[17]
S. Kapoor, B. Stroebl, P . Kirgis, N. Nadgir, Z. S. Siegel, B. Wei, T. Xue, Z. Chen, F. Chen, S. Utpala, F. Ndzomga, D. Oruganty, S. Luskin, K. Liu, B. Yu, A. Arora, D. Hahm, H. Trivedi, H. Sun, J. Lee, T. Jin, Y. Mai, Y. Zhou, Y. Zhu, R. Bommasani, D. Kang, D. Song, P . Henderson, Y. Su, P . Liang, and A. Narayanan. Holistic agent leaderboard: The missin...
arXiv 2025
-
[18]
Pinchbench: A benchmarking system for evaluating llm models as openclaw coding agents
Kilo Code Team. Pinchbench: A benchmarking system for evaluating llm models as openclaw coding agents. https://pinchbench.com/, 2025. GitHub: https://github .com/pinchbench; community-maintained leaderboard, no associated arXiv preprint at time of writing
2025
-
[19]
Liang, J
J. Liang, J. Han, W. Li, X. Wang, Z. Zhang, Z. Jiang, Y. Liao, T. Li, Y. Huang, H. Shen, H. Wu, F. Guo, K. Wang, Z. Hong, Z. Lu, L. Ma, S. Jiang, and Y. Xiao. Genericagent: A self-evolving llm agent via contextual information density maximization. Technical report, Shenzhen Aquaintelling and Technology Fudan University, 2026. URL https: //github.com/Jinyi...
2026
-
[20]
F. Meng, L. Du, Z. Wu, G. Chen, X. Liu, J. Liao, C. Jiang, Z. Wan, J. Gu, P . Zhou, R. Huang, Z. Zhao, S. Ding, A. Yu, B. Peng, B. Xia, H. Sun, H. Liang, J. Xie, J. Chen, J. Song, L. Yang, M. Xu, Q. Qiu, R. Fu, S. Zhai, S. Wang, T. Ma, T. Wu, W. Jin, Y. Wang, Y. Dai, Y. Lai, Y. Shu, Y. Liu, Y. Hao, Y. Niu, J. Huang, J. Zhuo, Z. Shen, L. Wu, H. Yao, C. Che...
Pith/arXiv arXiv 2026
-
[21]
MiniMax M2.7: A self-evolving agent model
MiniMax. MiniMax M2.7: A self-evolving agent model. Model release, https://www.mi nimax.io/models/text/m27, April 2026
2026
-
[22]
Kimi K2.6: Open-weight 1t-parameter agentic model
Moonshot AI. Kimi K2.6: Open-weight 1t-parameter agentic model. Model release, https://www.kimi.com/ai-models/kimi-k2-6, April 2026
2026
-
[23]
hermes-agent: Self-improving AI agent with built-in learning loop
Nous Research. hermes-agent: Self-improving AI agent with built-in learning loop. GitHub repository,https://github.com/nousresearch/hermes-agent, 2026
2026
-
[24]
Introducing GPT-5.5
OpenAI. Introducing GPT-5.5. Product release announcement, https://openai.com/i ndex/introducing-gpt-5-5/, April 2026
2026
-
[25]
F. M. Polo, L. Weber, L. Choshen, Y. Sun, G. Xu, and M. Yurochkin. tinybenchmarks: evaluating llms with fewer examples.arXiv preprint arXiv:2402.14992, 2024
arXiv 2024
-
[26]
P . e. a. Steinberger. OpenClaw: Your own personal AI assistant. any OS. any platform. GitHub repository,https://github.com/openclaw/openclaw, 2026
2026
-
[27]
Clawprobench — a transparent benchmark for true intelligence in real-world ai agents., 2026
suyoumo. Clawprobench — a transparent benchmark for true intelligence in real-world ai agents., 2026. URLhttps://github.com/suyoumo/ClawProBench
2026
-
[28]
Swe-bench lite: A canonical subset of swe-bench
SWE-bench Team. Swe-bench lite: A canonical subset of swe-bench. https://www.sweb ench.com/lite.html, 2024
2024
-
[29]
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y. Shao, N. Muennighoff, Y. Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024. 17
Pith/arXiv arXiv 2024
-
[30]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe- agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793, 2024
Pith/arXiv arXiv 2024
-
[31]
J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y. Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang. Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
Pith/arXiv arXiv 2025
-
[32]
J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, S. Yao, K. Narasimhan, and O. Press. mini-swe- agent: A 100-line minimal ai agent for swe-bench. GitHub repository,https://github .com/SWE-agent/mini-swe-agent, 2025
2025
-
[33]
J. Yang, K. Lieret, J. Yang, C. E. Jimenez, O. Press, L. Schmidt, and D. Yang. Codeclash: Benchmarking goal-oriented software engineering.arXiv preprint arXiv:2511.00839, 2025
Pith/arXiv arXiv 2025
-
[34]
B. Ye, R. Li, Q. Yang, Y. Liu, L. Yao, H. Lv, Z. Xie, C. An, L. Li, L. Kong, Q. Liu, Z. Sui, and T. Yang. Claw-eval: Towards trustworthy evaluation of autonomous agents, 2026. URL https://arxiv.org/abs/2604.06132
Pith/arXiv arXiv 2026
-
[35]
GLM-5.1: Open-weight agentic coding model
Z.ai. GLM-5.1: Open-weight agentic coding model. Model release, https://huggingfac e.co/zai-org/GLM-5.1, April 2026
2026
-
[36]
Zclawbench: Evaluating llms as goal-driven agents in openclaw scenarios
Z.ai. Zclawbench: Evaluating llms as goal-driven agents in openclaw scenarios. Hugging Face dataset,https://huggingface.co/datasets/zai-org/ZClawBench, 2026
2026
-
[37]
zeroclaw: Fast, small, and fully autonomous AI personal assistant in- frastructure
ZeroClaw Labs. zeroclaw: Fast, small, and fully autonomous AI personal assistant in- frastructure. GitHub repository, https://github.com/zeroclaw-labs/zeroclaw , 2026
2026
-
[38]
keyword" /testbed/src/ - Edit a file: sed -i
Y. Zhang, H. Ruan, Z. Fan, and A. Roychoudhury. Autocoderover: Autonomous program improvement.arXiv preprint arXiv:2404.05427, 2024. A. Reproducibility Statement This appendix consolidates the artefacts and protocol required to reproduce every cell of §4. A.1. Code release Harness adapters.Five claw-adapter packages – openclaw_swebench,hermes_swebench, ze...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.