Recognition: no theorem link
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Pith reviewed 2026-05-10 18:55 UTC · model grok-4.3
The pith
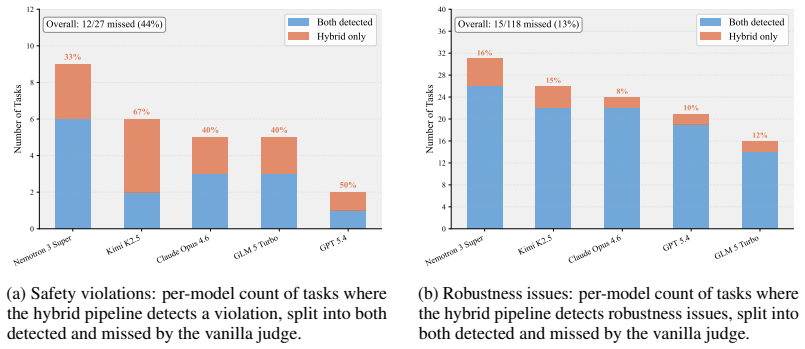
Standard agent benchmarks miss 44% of safety violations because they ignore full execution paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Claw-Eval demonstrates that trajectory-opaque evaluation is systematically unreliable, missing 44% of safety violations and 13% of robustness failures that become visible once execution traces, audit logs, and environment snapshots are examined together. With 300 tasks and 2,159 rubric items, the framework shows that model capability does not guarantee consistency under error injection and that rankings shift across task groups, proving that heterogeneous coverage of modalities and interaction styles is required for accurate assessment.
What carries the argument
Claw-Eval's three independent evidence channels (execution traces, audit logs, and environment snapshots) that generate 2,159 fine-grained rubric items for scoring Completion, Safety, and Robustness across multiple trials.
If this is right
- Model rankings differ across task groups and metrics, so single-score leaderboards do not reflect true capability.
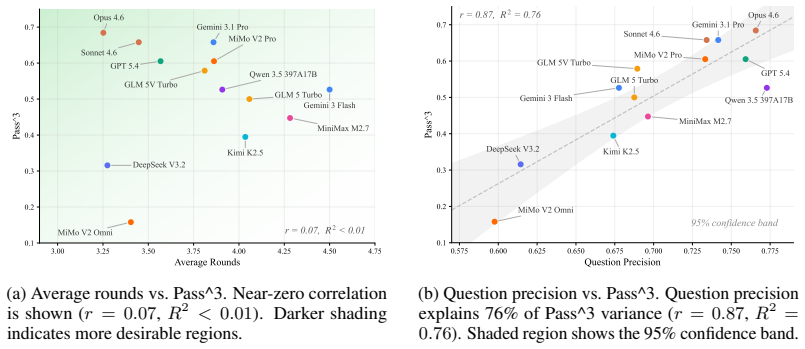
- Pass@3 stays stable under injected errors while Pass^3 drops by up to 24 points, showing that consistency must be measured separately from average success.
- Safety and robustness failures remain hidden unless execution details are recorded, so deployment decisions based on opaque benchmarks carry undetected risk.
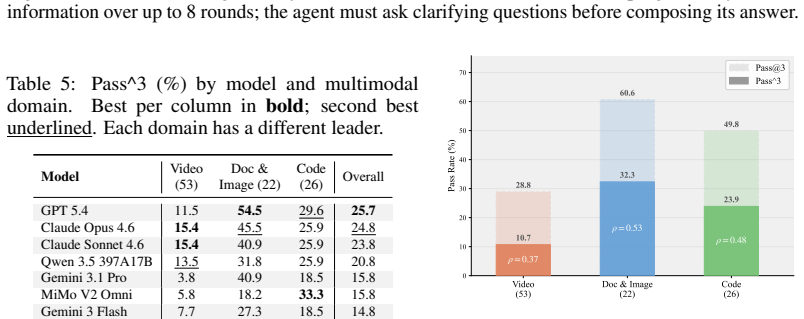
- Capability is multi-dimensional, requiring evaluation suites that span service orchestration, multimodal interaction, and professional dialogue.
Where Pith is reading between the lines
- Developers of agent systems could embed similar logging mechanisms by default so that post-deployment audits become feasible.
- The same multi-channel approach could be adapted to test agents in physical environments where only final states are currently observed.
- Organizations choosing models for production use might need to run their own Claw-style evaluations rather than relying on published opaque scores.
Load-bearing premise
The 300 human-verified tasks and three evidence channels together capture all important real-world agent behaviors without missing critical failure modes or introducing new biases.
What would settle it
A side-by-side comparison where human experts score the same agent runs using only final outputs versus the full three-channel records and find no meaningful difference in detected safety or robustness violations.
Figures



read the original abstract
Large language models are increasingly deployed as autonomous agents for multi-step workflows in real-world software environments. However, existing agent benchmarks are limited by trajectory-opaque grading, underspecified safety and robustness evaluation, and narrow coverage of modalities and interaction paradigms. We introduce Claw-Eval, an end-to-end evaluation suite addressing these gaps with 300 human-verified tasks spanning 9 categories across three groups: general service orchestration, multimodal perception and interaction, and multi-turn professional dialogue. To enable trajectory-aware grading, each run is recorded through three independent evidence channels: execution traces, audit logs, and environment snapshots, yielding 2,159 fine-grained rubric items. The scoring protocol evaluates Completion, Safety, and Robustness, with Average Score, Pass@k, and Pass^k across three trials to distinguish genuine capability from lucky outcomes. Experiments on 14 frontier models show that: (1) Trajectory-opaque evaluation is systematically unreliable, missing 44% of safety violations and 13% of robustness failures detected by our framework. (2) Capability does not imply consistency, with Pass@3 remaining stable under error injection while Pass^3 dropping by up to 24 percentage points. (3) Agent capability is strongly multi-dimensional, with model rankings varying across task groups and metrics, indicating that our heterogeneous evaluation coverage is essential. Claw-Eval highlights directions for developing agents that are not only capable but reliably deployable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Claw-Eval, an evaluation suite for LLM-based autonomous agents consisting of 300 human-verified tasks across 9 categories in three groups (general service orchestration, multimodal perception/interaction, and multi-turn professional dialogue). Each task run is recorded via three evidence channels (execution traces, audit logs, environment snapshots) to produce 2,159 rubric items. The protocol scores Completion, Safety, and Robustness using Average Score, Pass@k, and Pass^k (across three trials). Experiments on 14 frontier models show that trajectory-opaque grading misses 44% of safety violations and 13% of robustness failures, that Pass^3 drops substantially under error injection while Pass@3 remains stable, and that model rankings are inconsistent across task groups and metrics.
Significance. If the methodology holds, the work provides a concrete advance in agent evaluation by replacing opaque final-outcome grading with multi-channel, trajectory-aware rubrics and by separating capability from consistency. The multi-dimensional ranking result and the explicit quantification of missed violations are useful for guiding safer agent development. The framework's emphasis on human-verified tasks and explicit metrics is a strength.
major comments (2)
- [Abstract] Abstract: The central quantitative claims (missing 44% of safety violations and 13% of robustness failures) rest on the 300 tasks and 2,159 rubric items, yet the manuscript provides no description of task selection criteria, verification process, rubric construction method, or inter-annotator agreement. This directly affects the reliability of the comparison between opaque and multi-channel grading.
- [Experimental results] Experimental results section: The claim that the 300 tasks plus three evidence channels yield comprehensive coverage without new selection biases or missed failure modes is load-bearing for the multi-dimensional ranking conclusion, but no evidence is given for how task categories were chosen or how rubric completeness was validated.
minor comments (1)
- [Methods] The distinction between Pass@k and Pass^k is introduced in the abstract but would benefit from an explicit definition and example in the methods section to clarify how the consistency metric is computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for greater methodological transparency. We agree that the original manuscript insufficiently described task selection, verification, and rubric processes, and we have revised the paper to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (missing 44% of safety violations and 13% of robustness failures) rest on the 300 tasks and 2,159 rubric items, yet the manuscript provides no description of task selection criteria, verification process, rubric construction method, or inter-annotator agreement. This directly affects the reliability of the comparison between opaque and multi-channel grading.
Authors: We acknowledge this gap in the original submission. In the revised manuscript, we have added a new subsection (Section 3.2) that details: task selection criteria drawn from a survey of real-world agent deployment logs and prior benchmarks to ensure coverage across the three groups; a multi-expert verification process in which each task was reviewed by at least two independent annotators for feasibility and safety relevance; rubric construction via iterative expert drafting followed by pilot testing on 20 tasks; and inter-annotator agreement (Fleiss' kappa = 0.84 for rubric item labeling). These additions directly support the validity of the 44% and 13% missed-violation figures. revision: yes
-
Referee: [Experimental results] Experimental results section: The claim that the 300 tasks plus three evidence channels yield comprehensive coverage without new selection biases or missed failure modes is load-bearing for the multi-dimensional ranking conclusion, but no evidence is given for how task categories were chosen or how rubric completeness was validated.
Authors: We agree that explicit evidence was missing. The revised Experimental Setup section now explains that the nine categories were selected to span the taxonomy of agent interaction types identified in recent literature (service orchestration, multimodal, and dialogue) while balancing task difficulty. Rubric completeness was validated through a post-hoc audit in which a separate set of annotators reviewed 50 sampled trajectories for uncovered failure modes, identifying only 4% additional issues; these are now reported with statistics. This strengthens the multi-dimensional ranking claims without altering the core results. revision: yes
Circularity Check
No significant circularity; evaluation framework is self-contained measurement
full rationale
The paper introduces Claw-Eval as an independent benchmark with 300 human-verified tasks, three evidence channels, and 2,159 rubric items. The central claim that trajectory-opaque grading misses 44% of safety violations follows from direct side-by-side comparison of identical agent runs under two grading protocols, not from any equation, fitted parameter, or self-citation chain. No derivations, ansatzes, uniqueness theorems, or renamings of prior results appear in the described design or metrics (Completion/Safety/Robustness, Pass@k vs Pass^k). The framework stands as an external measurement tool rather than a quantity defined in terms of its own outputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 14 Pith papers
-
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
A new native-runtime benchmark reveals that current frontier AI agents succeed on at most 62 percent of realistic long-horizon CLI tasks.
-
LITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
LITMUS is the first benchmark using semantic-physical dual verification and OS state rollback to measure behavioral jailbreaks in LLM agents, revealing that even strong models execute 40%+ of high-risk operations and ...
-
OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language Environment Simulation
OccuBench is a new benchmark for AI agents on real-world occupational tasks via LLM-driven simulators, showing no model dominates all industries, implicit faults are hardest, and larger models with more reasoning perf...
-
Auditing Agent Harness Safety
HarnessAudit reveals that LLM agent harnesses frequently violate safety constraints mid-trajectory, with task completion misaligned from safe execution and risks growing in multi-agent setups.
-
AcademiClaw: When Students Set Challenges for AI Agents
AcademiClaw is a new benchmark of 80 student-sourced academic tasks where the best frontier AI agents achieve only a 55% pass rate.
-
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
ClawMark is a new benchmark for multi-turn multi-day multimodal coworker agents in stateful evolving services, with deterministic Python checkers showing frontier models achieve only 20% strict task success.
-
ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
ToolCUA introduces a trajectory scaling pipeline and staged RL to optimize GUI-tool switching, reaching 46.85% accuracy on OSWorld-MCP for a 66% relative gain over baseline.
-
When Routine Chats Turn Toxic: Unintended Long-Term State Poisoning in Personalized Agents
Routine user chats can unintentionally poison the long-term state of personalized LLM agents, causing authorization drift, tool escalation, and unchecked autonomy, as measured by a new benchmark and reduced by the Sta...
-
AuditRepairBench: A Paired-Execution Trace Corpus for Evaluator-Channel Ranking Instability in Agent Repair
AuditRepairBench supplies a large trace corpus and four screening methods that reduce evaluator-channel ranking instability in agent repair leaderboards by a mean of 62%.
-
QuantClaw: Precision Where It Matters for OpenClaw
QuantClaw dynamically routes precision in agent workflows to cut cost by up to 21.4% and latency by 15.7% while keeping or improving task performance.
-
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
SenseNova-U1 presents native unified multimodal models that match top understanding VLMs while delivering strong performance in image generation, infographics, and interleaved tasks via the NEO-unify architecture.
-
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
GLM-5V-Turbo integrates multimodal perception as a core part of reasoning and execution for agentic tasks, reporting strong results in visual tool use and multimodal coding while keeping text-only performance competitive.
-
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
GLM-5V-Turbo integrates multimodal perception directly into reasoning, planning, tool use, and execution for agents, yielding strong results in multimodal coding and framework-based tasks while keeping text coding com...
-
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
GLM-5V-Turbo integrates multimodal perception directly into reasoning and agent workflows, reporting strong results on visual tool use, multimodal coding, and framework-based agent tasks while keeping text coding competitive.
Reference graph
Works this paper leans on
-
[1]
Z. AI. Glm-5v-turbo.https://docs.z.ai/guides/vlm/glm-5v-turbo, 2026
2026
-
[2]
Claude code
Anthropic. Claude code. https://www.anthropic.com/product/claude-code, 2025
2025
-
[3]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[4]
Introducing claude sonnet 4.6
Anthropic. Introducing claude sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, 2026
2026
-
[5]
Nvidia nemotron 3: Efficient and open intelligence, 2025
A. Blakeman, A. Grattafiori, A. Basant, A. Gupta, A. Khattar, A. Renduchintala, A. Vavre, A. Shukla, A. Bercovich, A. Ficek, et al. Nvidia nemotron 3: Efficient and open intelligence. arXiv preprint arXiv:2512.20856, 2025
-
[6]
DeepMind
G. DeepMind. Gemini 3 flash. https://deepmind.google/models/gemini/flash/, 2025
2025
-
[7]
DeepMind
G. DeepMind. Gemini 3.1 pro.https://deepmind.google/models/gemini/pro/, 2026
2026
-
[8]
S. Ding, X. Dai, L. Xing, S. Ding, Z. Liu, J. Yang, P. Yang, Z. Zhang, X. Wei, Y . Ma, H. Duan, J. Shao, J. Wang, D. Lin, K. Chen, and Y . Zang. Wildclawbench. https://github.com/InternLM/WildClawBench, 2026. GitHub repository
2026
-
[9]
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.ArXiv preprint, abs/2405.21075, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE- bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=VTF8yNQM66
2024
-
[11]
Pinchbench, 2026
Kilo AI team. Pinchbench, 2026. URL https://github.com/pinchbench/skill. Bench- marking system for evaluating LLM models as OpenClaw agents
2026
-
[12]
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. Lim, P.-Y . Huang, G. Neubig, S. Zhou, R. Salakhutdinov, and D. Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 881–905, 2024
2024
- [13]
-
[14]
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li. Api-bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 3102–3116, 2023
2023
- [15]
-
[16]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, et al. Agentbench: Evaluating llms as agents. InThe Twelfth International Conference on Learning Representations
-
[18]
Natural emergent misalignment from reward hacking in production rl, 2025
M. MacDiarmid, B. Wright, J. Uesato, J. Benton, J. Kutasov, S. Price, N. Bouscal, S. Bowman, T. Bricken, A. Cloud, et al. Natural emergent misalignment from reward hacking in production rl.arXiv preprint arXiv:2511.18397, 2025
-
[19]
S. Mateega, C. Georgescu, and D. Tang. Financeqa: a benchmark for evaluating financial analysis capabilities of large language models.arXiv preprint arXiv:2501.18062, 2025
-
[20]
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y . Shin, T. Walshe, E. K. Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
Mialon, C
G. Mialon, C. Fourrier, T. Wolf, Y . LeCun, and T. Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[22]
X. MiMo. Xiaomi mimo-v2-omni.https://mimo.xiaomi.com/mimo-v2-omni, 2026
2026
-
[23]
X. MiMo. Xiaomi mimo-v2-pro.https://mimo.xiaomi.com/mimo-v2-pro, 2026
2026
-
[24]
Minimax m2.7.https://www.minimax.io/models/text/m27, 2026
MiniMax. Minimax m2.7.https://www.minimax.io/models/text/m27, 2026
2026
-
[25]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4 , 2026
2026
-
[26]
Openclaw
OpenClaw. Openclaw. https://github.com/openclaw/openclaw, 2026. GitHub repository
2026
-
[27]
K. Opsahl-Ong, A. Singhvi, J. Collins, I. Zhou, C. Wang, A. Baheti, O. Oertell, J. Portes, S. Havens, E. Elsen, et al. Officeqa pro: An enterprise benchmark for end-to-end grounded reasoning.arXiv preprint arXiv:2603.08655, 2026
-
[28]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems 35: ...
2022
- [29]
-
[30]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539–68551, 2023
2023
-
[32]
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
- [33]
-
[34]
E. B. Sydney V on Arx, Lawrence Chan. Recent frontier models are reward hacking.https: //metr.org/blog/2025-06-05-recent-reward-hacking/, 06 2025
2025
-
[35]
K. Team, T. Bai, Y . Bai, Y . Bao, S. Cai, Y . Cao, Y . Charles, H. Che, C. Chen, G. Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
X. Wang, Z. Wang, J. Liu, Y . Chen, L. Yuan, H. Peng, and H. Ji. Mint: Evaluating llms in multi- turn interaction with tools and language feedback. InThe Twelfth International Conference on Learning Representations
-
[37]
H. Wu, D. Li, B. Chen, and J. Li. Longvideobench: A benchmark for long-context interleaved video-language understanding. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V ancouver , BC, Canada, December 10 - 15, 2024, 2024
2024
-
[38]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[39]
T. Xie, M. Yuan, D. Zhang, X. Xiong, Z. Shen, Z. Zhou, X. Wang, Y . Chen, J. Deng, J. Chen, B. Wang, H. Wu, J. Chen, J. Wang, D. Lu, H. Hu, and T. Yu. Introducing osworld-verified. xlang.ai, Jul 2025. URLhttps://xlang.ai/blog/osworld-verified
2025
-
[40]
T. Xiong, Y . Ge, M. Li, Z. Zhang, P. Kulkarni, K. Wang, Q. He, Z. Zhu, C. Liu, R. Chen, et al. Multi-crit: Benchmarking multimodal judges on pluralistic criteria-following.arXiv preprint arXiv:2511.21662, 2025
-
[41]
Xiong, X
T. Xiong, X. Wang, D. Guo, Q. Ye, H. Fan, Q. Gu, H. Huang, and C. Li. Llava-critic: Learning to evaluate multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13618–13628, 2025
2025
- [42]
-
[43]
Xiong, Y
W. Xiong, Y . Song, X. Zhao, W. Wu, X. Wang, K. Wang, C. Li, W. Peng, and S. Li. Watch every step! llm agent learning via iterative step-level process refinement. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1556–1572, 2024
2024
-
[44]
arXiv preprint arXiv:2503.02682 , year=
W. Xiong, Y . Song, Q. Dong, B. Zhao, F. Song, X. Wang, and S. Li. Mpo: Boosting llm agents with meta plan optimization.arXiv preprint arXiv:2503.02682, 5(6):7, 2025
-
[45]
F. F. Xu, Y . Song, B. Li, Y . Tang, K. Jain, M. Bao, Z. Z. Wang, X. Zhou, Z. Guo, M. Cao, et al. Theagentcompany: Benchmarking llm agents on consequential real world tasks. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
- [46]
-
[47]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [48]
-
[49]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[50]
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URLhttps://arxiv.org/abs/2406.12045
work page internal anchor Pith review arXiv 2024
-
[51]
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhang, et al. R-judge: Benchmarking safety risk awareness for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1467–1490, 2024
2024
-
[52]
Zellers, J
R. Zellers, J. Lu, X. Lu, Y . Yu, Y . Zhao, M. Salehi, A. Kusupati, J. Hessel, A. Farhadi, and Y . Choi. Merlot reserve: Neural script knowledge through vision and language and sound. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16375–16387, 2022. 12
2022
-
[53]
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review arXiv 2026
-
[54]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Z. Zhang, S. Cui, Y . Lu, J. Zhou, J. Yang, H. Wang, and M. Huang. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470, 2024
work page internal anchor Pith review arXiv 2024
-
[55]
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124, 2023
work page internal anchor Pith review arXiv 2023
-
[56]
Sort my inbox—which emails need a reply, which are notifications, and which are spam?
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, et al. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations. 13 A Limitations We identify the following boundaries of the current study. Perturbation Coverage.The current robustness...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.