TetherCache: Stabilizing Autoregressive Long-Form Video Generation with Gated Recall and Trusted Alignment
Pith reviewed 2026-06-27 07:34 UTC · model grok-4.3
The pith
TetherCache stabilizes long autoregressive video generation by partitioning the cache and using gated recall plus statistical alignment to cut drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
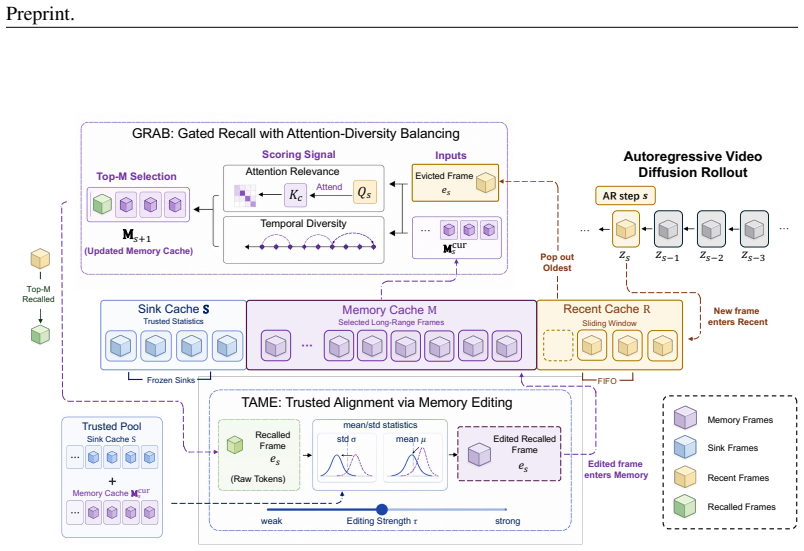
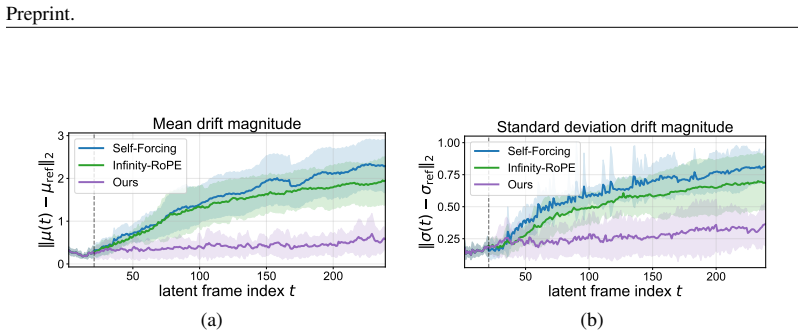
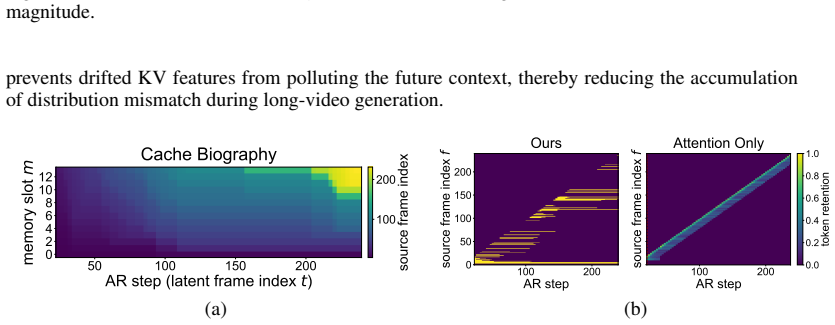
TetherCache organizes the KV cache into sink, memory, and recent regions. GRAB selects long-range memory frames with a gated score that balances attention relevance and temporal diversity under fixed budget. TAME edits newly recalled memory tokens by aligning their statistics to a trusted context distribution. When built on Self-Forcing, the method raises VBench-Long overall and semantic scores across 30 s, 60 s, and 240 s lengths while lowering quality drift from 7.84 to 1.33 at the longest horizon.
What carries the argument
GRAB (Gated Recall with Attention-Diversity Balancing) for memory selection and TAME (Trusted Alignment via Memory Editing) for statistical correction, inside a three-region cache layout.
If this is right
- Quality and semantic scores rise consistently on VBench-Long for all tested lengths up to 240 seconds.
- Quality drift drops substantially at the longest horizon without any model retraining.
- The same cache strategy works as a plug-and-play addition to existing autoregressive video diffusion pipelines.
- Both mechanisms together preserve informative yet diverse historical context under a fixed cache budget.
Where Pith is reading between the lines
- Similar region-based cache management and statistical alignment steps could be tested on autoregressive models outside video, such as long audio or 3-D scene generation.
- The gated selection rule may generalize to other memory-constrained sequence tasks where relevance and diversity must be balanced explicitly.
- If the editing step proves robust, it could be applied at inference time to correct drift in any autoregressive diffusion process that re-uses self-generated tokens.
Load-bearing premise
Lightly editing newly recalled memory tokens by aligning their statistics to a trusted context distribution reduces pollution from drifted historical features without introducing new artifacts or inconsistencies.
What would settle it
Running the 240-second VBench-Long evaluation with TetherCache and finding that the quality drift metric stays at or above 7.84, or that overall and semantic scores show no improvement over the Self-Forcing baseline, would falsify the stabilization claim.
Figures




read the original abstract
Autoregressive video diffusion models provide a natural formulation for streaming and variable-length video generation by conditioning newly generated frames on previously generated content. However, extending these models to minute-level generation remains challenging: the limited KV-cache budget prevents the model from retaining the full history, while repeatedly conditioning on self-generated frames induces a context distribution shift that accumulates over time, leading to visual artifacts, quality degradation, and temporal drift. In this paper, we propose TetherCache, a training-free and plug-and-play cache management strategy for drift-resistant long video generation. TetherCache organizes the cache into sink, memory, and recent regions, and introduces two complementary mechanisms. First, GRAB (Gated Recall with Attention-Diversity Balancing) selects long-range memory frames using a gated score that combines attention-based relevance with temporal diversity, preserving informative yet diverse historical context under a fixed cache budget. Second, TAME (Trusted Alignment via Memory Editing) lightly edits newly recalled memory tokens by aligning their statistics to a trusted context distribution, reducing the pollution caused by drifted historical features. Built on Self-Forcing, TetherCache consistently improves long-video generation quality on VBench-Long across 30s, 60s, and 240s settings. In particular, for 240s generation, it substantially improves overall and semantic scores while reducing quality drift from 7.84 to 1.33, demonstrating its effectiveness for stable long-horizon autoregressive video diffusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TetherCache, a training-free plug-and-play cache management method for autoregressive video diffusion models. It partitions the KV cache into sink, memory, and recent regions and introduces GRAB (Gated Recall with Attention-Diversity Balancing) to select long-range frames via a gated attention-diversity score and TAME (Trusted Alignment via Memory Editing) to lightly edit recalled tokens by aligning their statistics to a trusted context distribution. Built on Self-Forcing, the method is evaluated on VBench-Long and reported to improve overall and semantic scores while reducing quality drift from 7.84 to 1.33 for 240 s generation across 30 s, 60 s, and 240 s settings.
Significance. If the reported gains are reproducible and the mechanisms do not introduce undetected artifacts, TetherCache would provide a practical, training-free route to minute-scale autoregressive video generation. The combination of diversity-aware recall and statistic alignment directly targets the two stated sources of drift (cache budget limits and context shift), which is a concrete engineering contribution in a domain where long-horizon stability remains an open bottleneck.
major comments (2)
- [Abstract, §3] Abstract and §3 (TAME description): the trusted context distribution to which recalled memory tokens are aligned is never defined (initial-frame statistics, running mean of the sink region, or external reference). Without an explicit definition or the alignment operator (e.g., Eq. for mean/variance matching), it is impossible to verify that the operation reduces pollution rather than masking or distorting temporal features.
- [§4, Table 2] §4 and Table 2 (240 s results): the drift reduction from 7.84 to 1.33 is presented as the central empirical support for TAME, yet no ablation isolates the contribution of statistic alignment versus GRAB alone, nor are statistical significance tests or variance across seeds reported. This leaves open whether the observed gain is robust or could be an artifact of the alignment step.
minor comments (2)
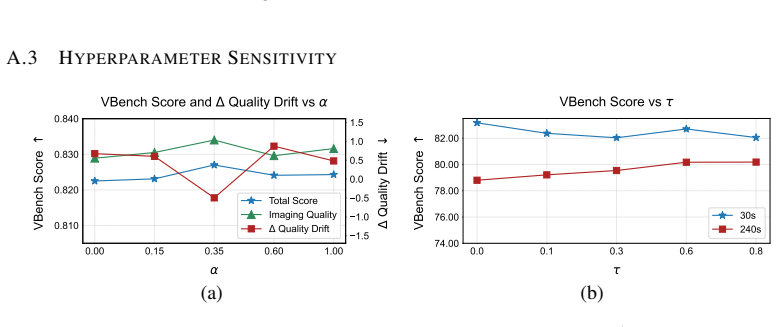
- [§3.1] Notation for the gated score in GRAB is introduced without an explicit equation; adding the formula would improve reproducibility.
- [§4] The paper should clarify whether VBench-Long metrics are computed on the full generated sequence or on sliding windows, as this affects interpretation of the drift numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TetherCache. The comments identify areas where additional clarity and empirical detail will strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (TAME description): the trusted context distribution to which recalled memory tokens are aligned is never defined (initial-frame statistics, running mean of the sink region, or external reference). Without an explicit definition or the alignment operator (e.g., Eq. for mean/variance matching), it is impossible to verify that the operation reduces pollution rather than masking or distorting temporal features.
Authors: We agree that the manuscript describes TAME at a conceptual level but does not supply an explicit definition of the trusted context distribution or the alignment operator. We will revise §3 to include both: a precise definition of the trusted context distribution and the corresponding equation for the statistic-alignment operation. This addition will make the mechanism verifiable and address the concern that the edit might distort temporal features. revision: yes
-
Referee: [§4, Table 2] §4 and Table 2 (240 s results): the drift reduction from 7.84 to 1.33 is presented as the central empirical support for TAME, yet no ablation isolates the contribution of statistic alignment versus GRAB alone, nor are statistical significance tests or variance across seeds reported. This leaves open whether the observed gain is robust or could be an artifact of the alignment step.
Authors: We acknowledge that the reported 240 s results reflect the combined GRAB + TAME system and that no ablation isolating the statistic-alignment component of TAME is currently present. We will add an ablation (GRAB alone versus full TetherCache) to the experimental section and Table 2. We will also report means and standard deviations over multiple random seeds for the key metrics, including the drift measure, to demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical benchmark results on VBench-Long with no derivation chain
full rationale
The paper describes TetherCache as a training-free plug-and-play method with GRAB and TAME components, built on Self-Forcing, and reports measured improvements (e.g., drift reduction from 7.84 to 1.33 on 240s generation) as direct benchmark outcomes. No equations, fitted parameters, or derivations are presented that reduce any claimed result to its own inputs by construction. Self-citation to Self-Forcing is not load-bearing for any mathematical claim, and the central results remain externally falsifiable via the stated VBench-Long protocol.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory , author=. 2026 , eprint=
2026
-
[2]
2026 , eprint=
Hunyuan-GameCraft-2: Instruction-following Interactive Game World Model , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Grounding World Simulation Models in a Real-World Metropolis , author=. 2026 , eprint=
2026
-
[4]
2025 , eprint=
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling , author=. 2025 , eprint=
2025
-
[5]
2026 , eprint=
World Simulation with Video Foundation Models for Physical AI , author=. 2026 , eprint=
2026
-
[6]
2025 , eprint=
LongLive: Real-time Interactive Long Video Generation , author=. 2025 , eprint=
2025
-
[7]
2026 , eprint=
MotionStream: Real-Time Video Generation with Interactive Motion Controls , author=. 2026 , eprint=
2026
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Filmweaver: Weaving consistent multi-shot videos with cache-guided autoregressive diffusion , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[9]
ICML , year=
Ca2-VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing , author=. ICML , year=
-
[10]
2026 , url=
Jinyi Hu and Shengding Hu and Yuxuan Song and Yufei Huang and Mingxuan Wang and Hao Zhou and Zhiyuan Liu and Wei-Ying Ma and Maosong Sun , journal=. 2026 , url=
2026
-
[11]
Pyramidal Flow Matching for Efficient Video Generative Modeling , url =
Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and MU, Yadong and Lin, Zhouchen , booktitle =. Pyramidal Flow Matching for Efficient Video Generative Modeling , url =
-
[12]
and Zipser, David , journal=
Williams, Ronald J. and Zipser, David , journal=. A Learning Algorithm for Continually Running Fully Recurrent Neural Networks , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Diffusion forcing: Next-token prediction meets full-sequence diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
2025 , eprint=
SkyReels-V2: Infinite-length Film Generative Model , author=. 2025 , eprint=
2025
-
[15]
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Long-Context Autoregressive Video Modeling with Next-Frame Prediction , author=. arXiv preprint arXiv:2503.19325 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2025 , eprint=
MAGI-1: Autoregressive Video Generation at Scale , author=. 2025 , eprint=
2025
-
[17]
Proceedings of the 42nd International Conference on Machine Learning , pages =
History-Guided Video Diffusion , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[18]
CVPR , year=
From Slow Bidirectional to Fast Autoregressive Video Diffusion Models , author=. CVPR , year=
-
[19]
CVPR , year=
One-step Diffusion with Distribution Matching Distillation , author=. CVPR , year=
-
[20]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , url =
Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli , booktitle =. Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , url =
-
[21]
Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation , author=. arXiv preprint arXiv:2602.02214 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Sequence Level Training with Recurrent Neural Networks , booktitle =
Marc'Aurelio Ranzato and Sumit Chopra and Michael Auli and Wojciech Zaremba , editor =. Sequence Level Training with Recurrent Neural Networks , booktitle =. 2016 , url =
2016
-
[23]
2025 , eprint=
Stable Video Infinity: Infinite-Length Video Generation with Error Recycling , author=. 2025 , eprint=
2025
-
[24]
2026 , eprint=
Helios: Real Real-Time Long Video Generation Model , author=. 2026 , eprint=
2026
-
[25]
2026 , eprint=
Infinity-RoPE: Action-Controllable Infinite Video Generation Emerges From Autoregressive Self-Rollout , author=. 2026 , eprint=
2026
-
[26]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time , author=. arXiv preprint arXiv:2509.25161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2026 , eprint=
HiAR: Efficient Autoregressive Long Video Generation via Hierarchical Denoising , author=. 2026 , eprint=
2026
-
[28]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation , author=. arXiv preprint arXiv:2510.02283 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2512.05081 , year=
Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression , author=. arXiv preprint arXiv:2512.05081 , year=
-
[30]
Rolling Sink: Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion , author=. arXiv preprint arXiv:2602.07775 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Memrope: Training-free infinite video generation via evolving memory tokens,
MemRoPE: Training-Free Infinite Video Generation via Evolving Memory Tokens , author=. arXiv preprint arXiv:2603.12513 , year=
-
[32]
2026 , eprint=
Relax Forcing: Relaxed KV-Memory for Consistent Long Video Generation , author=. 2026 , eprint=
2026
-
[33]
2026 , eprint=
Echo-Forcing: A Scene Memory Framework for Interactive Long Video Generation , author=. 2026 , eprint=
2026
-
[34]
2026 , eprint=
DySink: Dynamic Frame Sinks for Autoregressive Long Video Generation , author=. 2026 , eprint=
2026
-
[35]
2026 , eprint=
PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference , author=. 2026 , eprint=
2026
-
[36]
2026 , eprint=
Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
Long-Horizon Streaming Video Generation via Hybrid Attention with Decoupled Distillation , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention , author=. 2026 , eprint=
2026
-
[39]
2026 , eprint=
Train Short, Inference Long: Training-free Horizon Extension for Autoregressive Video Generation , author=. 2026 , eprint=
2026
-
[40]
2025 , eprint=
Wan: Open and Advanced Large-Scale Video Generative Models , author=. 2025 , eprint=
2025
-
[41]
Movie Gen: A Cast of Media Foundation Models
Movie Gen: A Cast of Media Foundation Models , author=. arXiv preprint arXiv:2410.13720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[43]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models , author=. 2025 , eprint=
2025
-
[45]
2023 , eprint=
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.