EA-WM: Event-Aware World Models with Task-Specification Grounding for Long-Horizon Manipulation
Pith reviewed 2026-06-27 06:20 UTC · model grok-4.3
The pith
Event-aware verification makes feature-space world models more interpretable and aligned with task progress for long-horizon robot manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
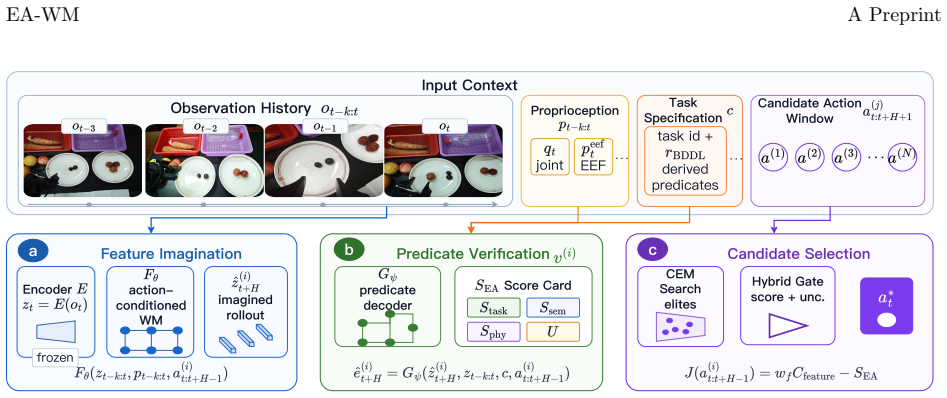
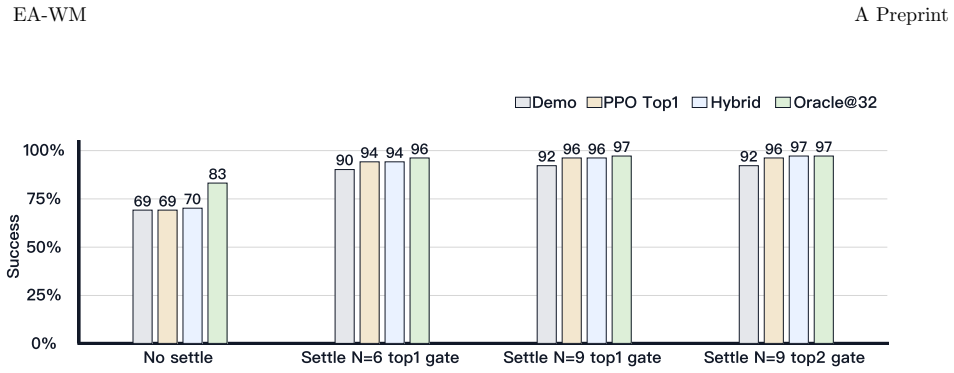
EA-WM augments frozen visual-feature dynamics with task-specification-grounded event prediction and verification. It rolls out candidate futures in pretrained visual-feature space, decodes them into structured event states such as object movement, contact changes, and placement predicates, and scores them using task-progress, semantic-consistency, physical-feasibility, and uncertainty terms. The verifier guides sampling-based planning, gates candidate actions, and selects among PPO-generated proposals in the contact-sensitive LIBERO wine-rack setting.
What carries the argument
The event decoder that maps visual feature rollouts to structured event states for verification and scoring.
If this is right
- Event-aware verification improves alignment with task progress in diverse manipulation domains.
- The method works using only frozen pretrained features without task-specific fine-tuning.
- It enables better selection of actions in contact-sensitive scenarios.
- Verification increases interpretability of whether imagined futures satisfy task requirements.
Where Pith is reading between the lines
- This could generalize to other types of pretrained models if the event decoding holds.
- Testing on physical robots would reveal if simulation-based event accuracy transfers.
- The approach might combine with language models to specify events from natural language descriptions.
- It suggests a path to more reliable long-horizon planning by adding explicit physical predicates.
Load-bearing premise
Decoding visual features into structured event states like object movement and contact changes can be performed reliably enough to guide planning without additional task-specific training data.
What would settle it
If the decoded event states fail to accurately reflect actual changes in object positions or contacts during rollouts, leading to no improvement or degradation in planning success rates over baselines.
Figures

read the original abstract
Pretrained-feature world models provide a useful substrate for robot imagination, but visual or latent prediction alone does not determine whether an imagined future satisfies task-relevant events. Long-horizon manipulation requires progress signals that are relational, predicate-level, and physically grounded: whether an object has moved, whether a drawer or contact state has changed, whether a placement predicate is satisfied, and whether a candidate future is reliable enough for execution. We introduce EA-WM, an event-aware world-model framework that augments frozen visual-feature dynamics with task-specification-grounded event prediction and verification. EA-WM rolls out candidate futures in pretrained visual-feature space, decodes them into structured event states, and scores them using task-progress, semantic-consistency, physical-feasibility, and uncertainty terms. The verifier guides sampling-based planning, gates candidate actions, and, in the contact-sensitive LIBERO wine-rack setting, selects among PPOgenerated proposals. Across navigation, deformable-object, wall-constrained, and languagedescribed manipulation studies, EA-WM shows that event-aware verification can make featurespace world models more interpretable and better aligned with task progress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EA-WM, an event-aware world-model framework that augments frozen pretrained visual-feature dynamics with task-specification-grounded event prediction. It rolls out futures in feature space, decodes them into structured predicate states (object movement, contact changes, placement), and scores plans using task-progress, semantic-consistency, physical-feasibility, and uncertainty terms to guide sampling-based planning and gate actions. Claims of improved interpretability and task alignment are supported by evaluations across navigation, deformable-object, wall-constrained, and language-described manipulation tasks, including contact-sensitive settings on LIBERO.
Significance. If the event decoder reliably maps visual features to predicate states without task-specific supervision, the approach would provide a practical way to inject interpretable, relational progress signals into latent world models, enabling better long-horizon planning while keeping pretrained dynamics frozen.
major comments (2)
- Abstract: the central claim that event-aware verification improves alignment and interpretability rests on the decoder mapping pretrained visual-feature rollouts to structured event states (movement, contact, placement) being sufficiently accurate to gate actions and score plans; this decoder reliability without task-specific training or fine-tuning is the load-bearing but unverified step, and reported gains on LIBERO cannot be attributed to the architecture alone if supervision is used.
- Abstract / implied method description: no details are given on the training procedure, data, or loss for the event-prediction decoder, nor on how the four scoring terms are combined or thresholded; without this, it is impossible to assess whether the method is parameter-free or whether the 'augments frozen ... without additional task-specific training' premise holds.
minor comments (2)
- Abstract: typographical errors ('languagedescribed' should read 'language-described'; 'PPOgenerated' should read 'PPO-generated').
- Abstract: the precise definition of the structured event states and the predicates used for verification are not enumerated, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater clarity on the event decoder and scoring mechanism. We address each point below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: the central claim that event-aware verification improves alignment and interpretability rests on the decoder mapping pretrained visual-feature rollouts to structured event states (movement, contact, placement) being sufficiently accurate to gate actions and score plans; this decoder reliability without task-specific training or fine-tuning is the load-bearing but unverified step, and reported gains on LIBERO cannot be attributed to the architecture alone if supervision is used.
Authors: We agree the decoder's mapping accuracy is central. The manuscript positions the visual dynamics as frozen and pretrained while the event decoder is trained separately to map features to task-grounded predicates using supervision derived from the task specification itself (not from task-specific fine-tuning of the dynamics). We will add explicit clarification, training details, and supporting ablations or reliability metrics to verify this separation and show that LIBERO gains arise from the verification layer applied to the frozen model rather than from end-to-end supervision of the dynamics. revision: yes
-
Referee: Abstract / implied method description: no details are given on the training procedure, data, or loss for the event-prediction decoder, nor on how the four scoring terms are combined or thresholded; without this, it is impossible to assess whether the method is parameter-free or whether the 'augments frozen ... without additional task-specific training' premise holds.
Authors: The referee correctly identifies that these implementation details are missing from the current manuscript. We will revise to include a dedicated methods subsection describing the event decoder's training data, loss function, and procedure (confirming it operates independently of the frozen dynamics), as well as the exact weighting, combination, and any thresholding of the four scoring terms (task-progress, semantic-consistency, physical-feasibility, uncertainty). This will allow readers to evaluate the parameter-free claim and the 'no additional task-specific training' premise for the dynamics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces EA-WM as an augmentation of frozen pretrained visual-feature dynamics with separate event-prediction and verification modules, then reports empirical results on navigation, deformable-object, and LIBERO benchmarks. No equations, self-citations, or derivations are presented in the provided text that reduce any central claim (event-aware verification improving alignment) to a tautological redefinition of inputs, a fitted parameter relabeled as a prediction, or an unverified self-citation chain. The architecture is described as adding new components whose performance is evaluated externally, satisfying the criteria for a self-contained proposal against independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
-
[2]
Leonardo Barcellona, Andrii Zadaianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Compositional world models empowering robot imitation learning with imagination.arXiv preprint arXiv:2412.14957,
-
[3]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[5]
Genie: Generative interactive environments.arXiv preprint arXiv:2402.15391,
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, et al. Genie: Generative interactive environments.arXiv preprint arXiv:2402.15391,
-
[6]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, et al. DreamGen: Unlocking generalization in robot learning through neural trajectories.arXiv preprint arXiv:2505.12705,
-
[7]
OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
-
[8]
WorldEval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017,
Yaxuan Li, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. WorldEval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017,
-
[9]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorldModel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312,
-
[10]
Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575,
NVIDIA, Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, et al. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575,
-
[11]
14 EA-WM A Preprint Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, et al. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
-
[12]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[13]
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liyiming Ke, Karl Pertsch, et al. Hi Robot: Open-ended instruction following with hierarchical vision-language-action models.arXiv preprint arXiv:2502.19417,
-
[14]
3D-VLA: A 3D vision-language-action generative world model.arXiv preprint arXiv:2403.09631,
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3D-VLA: A 3D vision-language-action generative world model.arXiv preprint arXiv:2403.09631,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.