α-fair heterogeneous agent reinforcement learning
Pith reviewed 2026-06-27 05:13 UTC · model grok-4.3
The pith
Dynamic weighting of each agent's advantage by its expected return lets multi-agent learners move from total-reward maximization to tunable equity while keeping policy improvement monotonic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A fair advantage function that re-weights each agent's contribution according to its expected return preserves the original policy-improvement theorem and stationarity of the underlying Markov game, thereby guaranteeing monotonic progress toward Nash equilibria while the global objective is continuously adjusted from utilitarian to alpha-fair welfare by the single scalar parameter alpha.
What carries the argument
The fair advantage function, which scales every agent's utility by a factor derived from its expected return so that the composite objective satisfies the alpha-fairness definition.
If this is right
- Monotonic improvement holds for any fixed alpha, so each policy update is guaranteed to raise the chosen fairness objective.
- The same proof structure yields convergence to Nash equilibria under standard assumptions on the Markov game.
- Two concrete algorithms can be obtained by substituting the fair advantage into existing trust-region update rules.
- In sequential social dilemmas the fair versions simultaneously raise total reward and raise minimum agent reward relative to the unweighted baseline.
Where Pith is reading between the lines
- The same weighting construction could be inserted into other policy-gradient or actor-critic methods that already possess improvement guarantees.
- If the expected-return estimates used for weighting become inaccurate, the fairness guarantee may degrade before the improvement guarantee does.
- Allowing alpha to vary during training would produce a curriculum from efficiency-focused to equity-focused behavior without restarting the learning process.
Load-bearing premise
The re-weighting step inside the advantage function leaves the original monotonic-improvement and stationarity arguments unchanged even though the weights change with each agent's expected return.
What would settle it
A run of the derived algorithms in which the measured value of the fair objective decreases after a policy update or in which the joint policy fails to approach a Nash equilibrium in the same environments where the unweighted method succeeds.
Figures

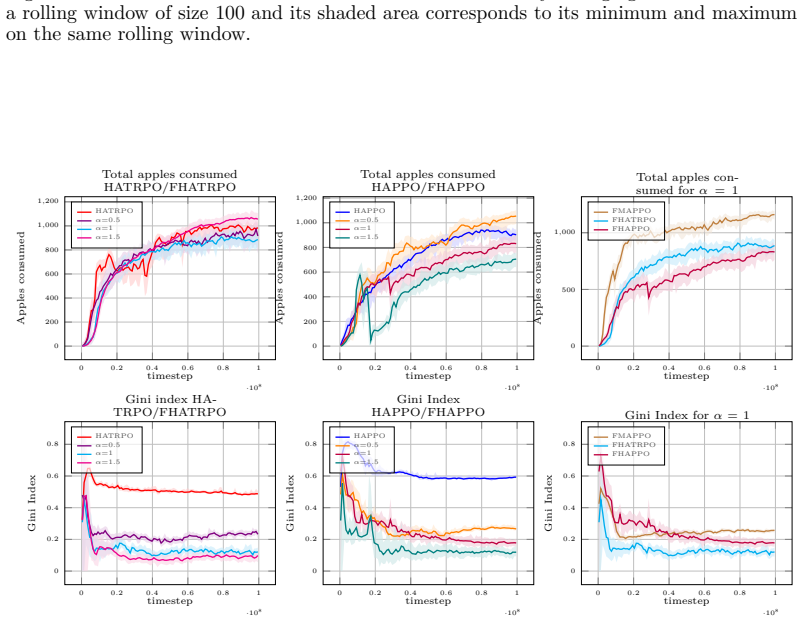
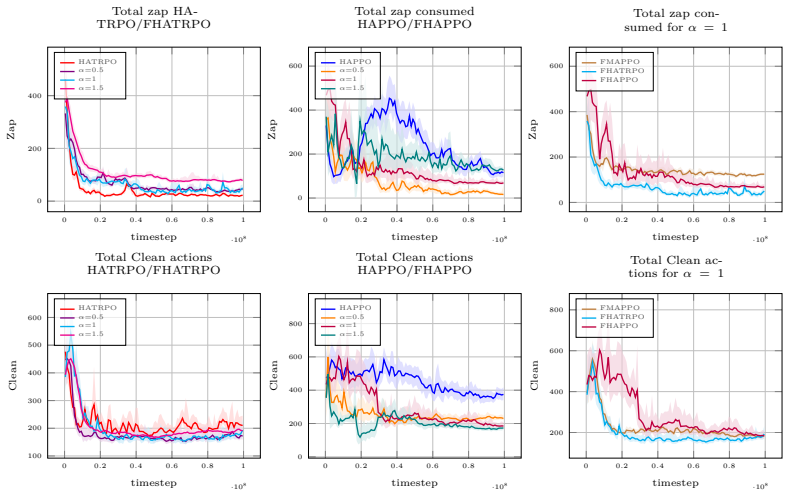
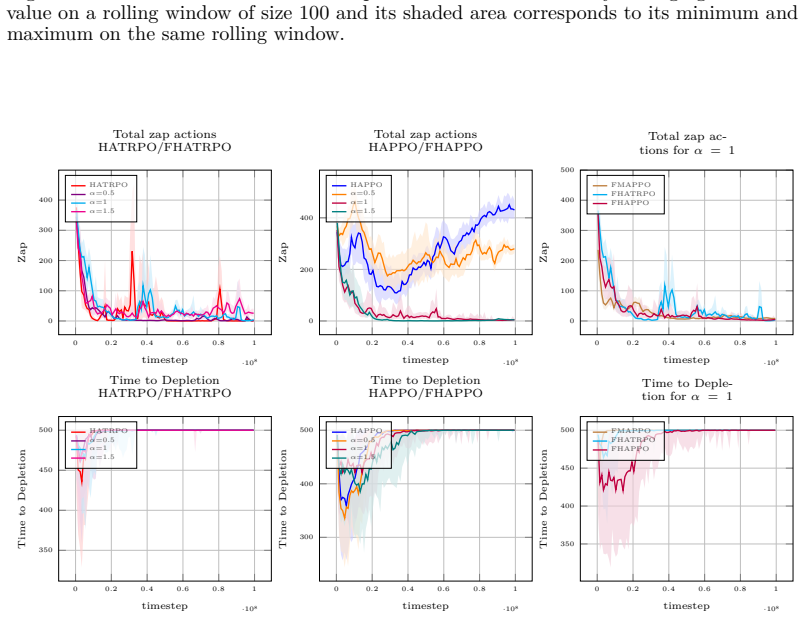
read the original abstract
Cooperation in multi-agent systems is typically optimized through utilitarian objectives that maximize overall efficiency but fail to account for reward distribution, often resulting in inequitable "leader-follower" dynamics. While fairness-based approaches encourage pro-social behaviors where every agent benefits from cooperation, many current algorithms - including those utilizing reward shaping - break the stationarity of Markov Games or lack rigorous theoretical guarantees. This creates a critical gap between fair objective methods and theoretically safe learning frameworks. We propose a novel framework that bridges $\alpha$-fairness with Heterogeneous-Agent Trust Region Learning (HATRL), ensuring monotonic improvement and convergence toward Nash Equilibria. Our approach leverages a fair advantage function that dynamically weights agent utilities based on their expected returns, allowing the global objective to transition from purely utilitarian efficiency to $\alpha$-fairness welfare based on the parameter $\alpha$. We introduce two practical algorithms, $\alpha$-fair HATRPO and $\alpha$-fair HAPPO, and demonstrate through experiments in sequential social dilemmas like CleanUp and CommonHarvest that they perform better than HATRL's algorithms from a utilitarian point of view while achieving socially higher outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework integrating α-fairness into Heterogeneous-Agent Trust Region Learning (HATRL) via a fair advantage function that dynamically weights agent utilities by expected returns. This is claimed to enable a transition from utilitarian to α-fair welfare objectives while preserving monotonic policy improvement and convergence to Nash equilibria. Two algorithms (α-fair HATRPO and α-fair HAPPO) are introduced and evaluated on sequential social dilemmas (CleanUp, CommonHarvest), reporting improved utilitarian and social outcomes relative to baseline HATRL methods.
Significance. If the invariance of the trust-region guarantees under the proposed dynamic weighting holds, the work would close a noted gap between fairness objectives and theoretically safe MARL frameworks. The experiments suggest practical gains, but the significance is limited by the absence of any supporting derivation for the core theoretical claims.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical sections: the central claim that the fair advantage function 'ensures monotonic improvement and convergence toward Nash Equilibria' is asserted without any derivation, proof sketch, or re-derivation of the key surrogate inequality from the original HATRL framework. The dynamic, return-dependent weighting replaces the fixed advantage estimator that underpins HATRL's KL-constrained monotonicity bound; without an explicit demonstration that the modified surrogate still satisfies the same improvement guarantee, the bridging claim is unsupported.
- [Definition of fair advantage function] Definition of the fair advantage function (likely §3): the construction applies α-fair weighting inside the advantage estimator based on expected returns. This introduces a state- and policy-dependent modification whose independence from the trust-region constraint is not shown. The original HATRL monotonicity relies on a fixed surrogate; the paper provides no analogue to the relevant lemma establishing that the new estimator yields a valid contraction or preserves stationarity of the Markov game.
minor comments (2)
- [Experiments] The experimental section reports performance improvements but does not specify the number of random seeds, statistical tests, or exact baseline implementations, making it difficult to assess the reliability of the utilitarian and social-outcome claims.
- [Notation / Algorithm description] Notation for the α-fair weighting parameter and its integration into the policy update is introduced without a clear equation reference or comparison table to the unmodified HATRL surrogate.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need for explicit theoretical support. We will revise the manuscript to include the requested derivations and lemmas.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical sections: the central claim that the fair advantage function 'ensures monotonic improvement and convergence toward Nash Equilibria' is asserted without any derivation, proof sketch, or re-derivation of the key surrogate inequality from the original HATRL framework. The dynamic, return-dependent weighting replaces the fixed advantage estimator that underpins HATRL's KL-constrained monotonicity bound; without an explicit demonstration that the modified surrogate still satisfies the same improvement guarantee, the bridging claim is unsupported.
Authors: We agree that the current manuscript asserts preservation of monotonic improvement and Nash convergence without a full re-derivation. In the revision we will add a proof sketch in the theoretical section that adapts the original HATRL surrogate inequality to the dynamic, return-dependent weighting, showing that the lower bound on performance improvement under the KL constraint continues to hold. revision: yes
-
Referee: [Definition of fair advantage function] Definition of the fair advantage function (likely §3): the construction applies α-fair weighting inside the advantage estimator based on expected returns. This introduces a state- and policy-dependent modification whose independence from the trust-region constraint is not shown. The original HATRL monotonicity relies on a fixed surrogate; the paper provides no analogue to the relevant lemma establishing that the new estimator yields a valid contraction or preserves stationarity of the Markov game.
Authors: We acknowledge that an analogue lemma is required. The revision will introduce a new lemma in Section 3 establishing that the state- and policy-dependent fair weighting preserves Markov-game stationarity and that the trust-region constraint remains independent of the weighting, thereby retaining the contraction property. revision: yes
Circularity Check
No circularity detected; derivation presented as independent construction
full rationale
The provided abstract and excerpts contain no equations, derivations, or explicit reductions that match any enumerated circularity pattern. The framework is described as a novel bridge between α-fairness and HATRL with a fair advantage function, but no self-definitional equivalence, fitted-input-as-prediction, or load-bearing self-citation chain is quoted. Claims of monotonic improvement are asserted without showing they reduce to the inputs by construction. This qualifies as a self-contained proposal against external benchmarks, consistent with the default expectation that most papers are not circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- α
axioms (1)
- domain assumption Markov Games remain stationary under the proposed fair advantage weighting
invented entities (1)
-
fair advantage function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Albrecht, Filippos Christianos, and Lukas Schäfer.Multi-Agent Reinforcement Learning: Foundations and Modern Approaches
Stefano V. Albrecht, Filippos Christianos, and Lukas Schäfer.Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024
2024
-
[2]
Saad Alqithami. EcoFair-CH-MARL: Scalable Constrained Hierarchical Multi-Agent RL with Real-Time Emission Budgets and Fairness Guarantees. October 2025. arXiv:2603.14625 [cs]
- [3]
-
[4]
AdaFair-MARL: Enforcing Adaptive Fairness Constraints in Multi-Agent Reinforcement Learning
Promise Ekpo, Saesha Agarwal, Felix Grimm, Lekan Molu, and Angelique Taylor. Fair-GNE : Generalized Nash Equilibrium-Seeking Fairness in Multiagent Healthcare Automation, November 2025. arXiv:2511.14135 [cs] version: 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Zihao Guo, Shuqing Shi, Richard Willis, Tristan Tomilin, Joel Z. Leibo, and Yali Du. SocialJax: An Evaluation Suite for Multi-agent Reinforcement Learning in Sequential Social Dilemmas, May 2025. arXiv:2503.14576 [cs]
-
[6]
Inequity aversion improves cooperation in intertemporal social dilemmas
Edward Hughes, Joel Z. Leibo, Matthew G. Phillips, Karl Tuyls, Edgar A. Duéñez- Guzmán, Antonio García Castañeda, Iain Dunning, Tina Zhu, Kevin R. McKee, Raphael Koster, Heather Roff, and Thore Graepel. Inequity aversion improves cooperation in intertemporal social dilemmas, September 2018. arXiv:1803.08884 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Learning Fairness in Multi-Agent Systems
Jiechuan Jiang and Zongqing Lu. Learning Fairness in Multi-Agent Systems. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
- [8]
-
[9]
Approximately optimal approximate reinforcement learning
Sham Kakade and John Langford. Approximately optimal approximate reinforcement learning. InProceedings of the Nineteenth International Conference on Machine Learning, ICML ’02, page 267–274, San Francisco, CA, USA, 2002. Morgan Kaufmann Publishers Inc
2002
-
[10]
Rate control for communication networks: shadow prices, proportional fairness and stability.Journal of the Operational Research Society, 49(3):237–252, 1998
F P Kelly, A K Maulloo, and D K H Tan. Rate control for communication networks: shadow prices, proportional fairness and stability.Journal of the Operational Research Society, 49(3):237–252, 1998
1998
-
[11]
Fair cooperation in mixed-motive games via conflict- aware gradient adjustment, 2025
Woojun Kim and Katia Sycara. Fair cooperation in mixed-motive games via conflict- aware gradient adjustment, 2025
2025
-
[12]
Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL, August 2022
Jakub Grudzien Kuba, Xidong Feng, Shiyao Ding, Hao Dong, Jun Wang, and Yaodong Yang. Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL, August 2022. arXiv:2208.01682 [cs]
-
[13]
An axiomatic theory of fairness in network resource allocation
Tian Lan, David Kao, Mung Chiang, and Ashutosh Sabharwal. An axiomatic theory of fairness in network resource allocation. In2010 Proceedings IEEE INFOCOM, pages 1–9, 2010
2010
-
[14]
Paul A. M. Van Lange.Social Dilemmas: Understanding Human Cooperation. OUP USA, 2014. Google-Books-ID: KfhMAgAAQBAJ
2014
-
[15]
Levin, Yuval Peres, and Elizabeth L
David A. Levin, Yuval Peres, and Elizabeth L. Wilmer.Markov chains and mixing times. American Mathematical Society, 2006
2006
-
[16]
Mo and J
J. Mo and J. Walrand. Fair end-to-end window-based congestion control.IEEE/ACM Transactions on Networking, 8(5):556–567, 2000
2000
-
[17]
Non-cooperative games.Annals of Mathematics, 54(2):286–295, 1951
John Nash. Non-cooperative games.Annals of Mathematics, 54(2):286–295, 1951. 11
1951
-
[18]
A multi-agent reinforcement learning model of common-pool resource appropriation
Julien Pérolat, Joel Z Leibo, Vinicius Zambaldi, Charles Beattie, Karl Tuyls, and Thore Graepel. A multi-agent reinforcement learning model of common-pool resource appropriation. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[19]
Selfishness Level Induces Cooperation in Sequential Social Dilemmas
Stefan Roesch, Stefanos Leonardos, and Yali Du. Selfishness Level Induces Cooperation in Sequential Social Dilemmas
-
[20]
Trust Region Policy Optimization
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust Region Policy Optimization, April 2017. arXiv:1502.05477 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
High- Dimensional Continuous Control Using Generalized Advantage Estimation, October
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- Dimensional Continuous Control Using Generalized Advantage Estimation, October
-
[22]
arXiv:1506.02438 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Towards Fair and Equitable Policy Learning in Cooperative Multi-Agent Reinforcement Learning
Umer Siddique, Peilang Li, and Yongcan Cao. Towards Fair and Equitable Policy Learning in Cooperative Multi-Agent Reinforcement Learning. 2024
2024
-
[24]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018
2018
-
[25]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. Multi-Agent Collaboration Mechanisms: A Survey of LLMs, January 2025. arXiv:2501.06322 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
West, Ashleigh S
Stuart A. West, Ashleigh S. Griffin, and Andy Gardner. Evolutionary Explanations for Cooperation.Current Biology, 17(16):R661–R672, August 2007
2007
-
[27]
John A. Weymark. Generalized gini inequality indices.Mathematical Social Sciences, 1(4):409–430, 1981
1981
- [28]
-
[29]
Altruism and Fair Objective in Mixed-Motive Markov games, February 2026
Yao-hua Franck Xu, Tayeb Lemlouma, Arnaud Braud, and Jean-Marie Bonnin. Altruism and Fair Objective in Mixed-Motive Markov games, February 2026. arXiv:2602.08389 [cs]
-
[30]
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning.Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):10861–10870, June 2023
Zhaoxing Yang, Haiming Jin, Rong Ding, Haoyi You, Guiyun Fan, Xinbing Wang, and Chenghu Zhou. DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning.Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):10861–10870, June 2023
2023
-
[31]
The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games, November 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games, November 2022. arXiv:2103.01955 [cs]
-
[32]
Heterogeneous-Agent Reinforcement Learning
Yifan Zhong, Jakub Grudzien Kuba, Xidong Feng, Siyi Hu, Jiaming Ji, and Yaodong Yang. Heterogeneous-Agent Reinforcement Learning
-
[33]
Learning Fair Policies in Decentralized Cooperative Multi-Agent Reinforcement Learning
Matthieu Zimmer, Claire Glanois, Umer Siddique, and Paul Weng. Learning Fair Policies in Decentralized Cooperative Multi-Agent Reinforcement Learning. InProceedings of the 38th International Conference on Machine Learning, pages 12967–12978. PMLR, July 2021. 12 A Preliminaries A.1 Assumptions and Definitions We use the same assumption as in HATRL [31]: As...
2021
-
[34]
or in [9] (Lemma 6.1): Eτ∼⃗ π′ [ ∞∑ t=0 γtA⃗ π i (st,⃗ at)|s0 ] =E τ∼⃗ π′ [ ∞∑ t=0 γt ( ri(st,⃗ at) +γV⃗ π i (st+1)−V⃗ π i (st) ) |s0 ] =E τ∼⃗ π′ [ ∞∑ t=0 γtri(st,⃗ at)|s0 ] +Eτ∼⃗ π′ [ ∞∑ t=0 γt ( γV⃗ π i (st+1)−V⃗ π(st) ) |s0 ] =V ⃗ π′ i (s0) +Eτ∼⃗ π′ [ ∞∑ t=0 ( γt+1V⃗ π i (st+1)−γtV⃗ π i (st) ) |s0 ] =V ⃗ π′ i (s0) +Eτ∼⃗ π′ [ −V⃗ π i (s0) + lim T→∞ γTV⃗...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.