CoDeR: Local Constraint-Compatible Retrieval Beyond Semantic Similarity
Pith reviewed 2026-06-27 05:45 UTC · model grok-4.3
The pith
CoDeR separates topical relevance from constraint compatibility by adding a bi-encoder trained on lexical-polarity supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that semantic similarity serves as an imperfect proxy for relevance in constraint-sensitive queries because it can expose constraint-violating evidence, and that this exposure is reduced by training a compatibility bi-encoder on lexical-polarity supervision over satisfying versus violating evidences so that topical and constraint signals can be handled separately during ranking.
What carries the argument
Compatibility bi-encoder trained with lexical-polarity supervision over contrastive satisfying and violating evidences, which supplies a signal for rescoring topical candidates or retrieving an auxiliary set.
If this is right
- V@2 falls by 20.59 points on antonymy diagnostics relative to the strongest non-CoDeR baseline.
- V@2 falls by 23.53 points on negation diagnostics relative to the strongest non-CoDeR baseline.
- V@2 falls by 5.77 points on exclusion diagnostics relative to the strongest non-CoDeR baseline.
- FVR rises because the first violating document is pushed deeper in the ranking.
- Ranked lists are produced without external LLM calls at inference time.
Where Pith is reading between the lines
- The same separation of signals could be tested on queries that combine multiple constraint types if the bi-encoder is extended to multi-label supervision.
- Deployment on production search logs would reveal whether the lexical-polarity signal holds for the distribution of real constraints users actually issue.
- The auxiliary retrieval path might be combined with existing dense retrievers to improve coverage on long-tail constraint patterns.
Load-bearing premise
The lexical-polarity supervision used to train the compatibility bi-encoder produces a signal that generalizes to constraint directions present in real user queries.
What would settle it
Applying CoDeR to a fresh collection of real user queries containing natural negations and exclusions and finding no reduction or an increase in the number of violating documents at rank 2 would falsify the central effectiveness claim.
Figures





read the original abstract
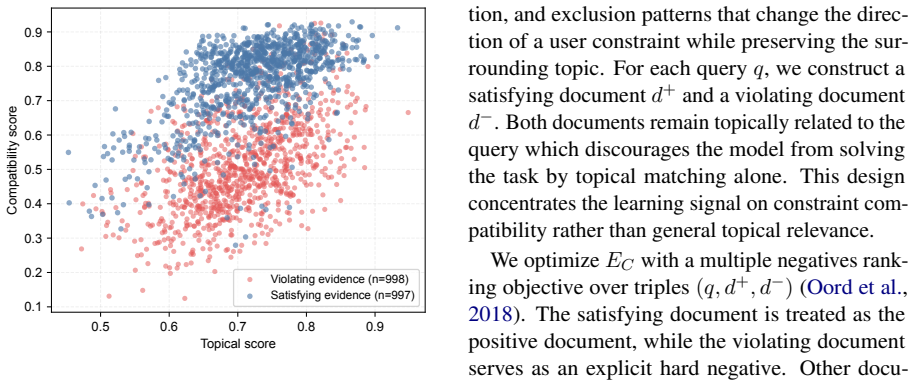
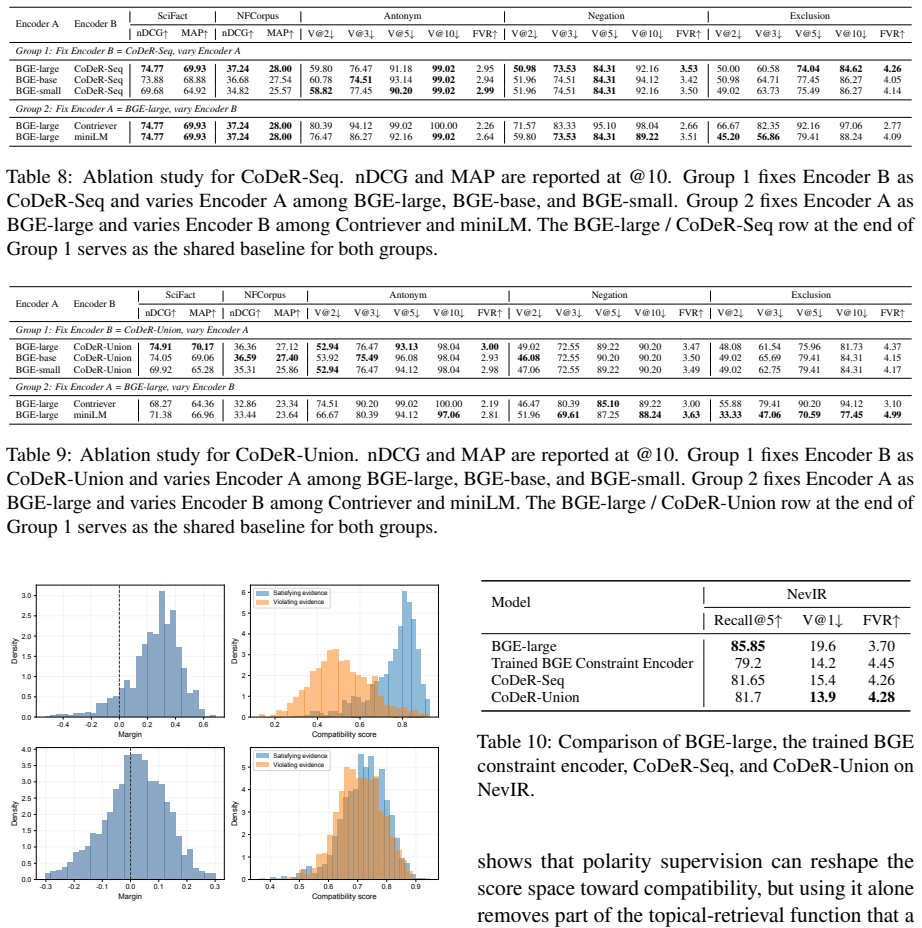
Information retrieval systems have long treated semantic similarity as a proxy for relevance. For constraint-sensitive queries, this proxy can fail when a document is topically close to the query but supports the opposite constraint direction, such as satisfying an attribute that should be excluded or affirming a relation that should be negated. We study this failure as constraint-violating evidence exposure and propose CoDeR, a local constraint-compatible dense retrieval method that separates topical relevance from constraint compatibility. CoDeR keeps a standard topical encoder for candidate coverage and adds a compatibility scorer, implemented as a bi-encoder, trained with lexical-polarity supervision over contrastive satisfying and violating evidences. The compatibility signal can be used to rescore topical candidates or to retrieve an auxiliary compatibility-oriented candidate set, producing a ranked document list without external Large Language Model~(LLM) calls at inference time. We evaluate CoDeR on controlled diagnostics and public negative-constraint retrieval benchmarks. Across three controlled diagnostic sets targeting antonymy, negation, and exclusion, CoDeR reduces V@2 by 20.59, 23.53, and 5.77 points relative to the strongest non-CoDeR baselines, and improves FVR by pushing the first violating document deeper in the ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoDeR, a dense retrieval approach that augments a standard topical encoder with a separate compatibility bi-encoder. The bi-encoder is trained via contrastive learning on lexical-polarity pairs of satisfying versus violating evidence and is used either to rescore candidates or to retrieve an auxiliary set, yielding ranked lists without LLM calls at inference. On three controlled diagnostic sets targeting antonymy, negation, and exclusion, CoDeR reduces V@2 by 20.59, 23.53, and 5.77 points relative to the strongest baselines while improving first-violation rank; results on public negative-constraint benchmarks are also reported.
Significance. If the performance claims hold under fuller methodological disclosure, the work offers a practical, inference-efficient way to mitigate constraint-violation failures that semantic similarity alone cannot address. The explicit separation of topical relevance from constraint compatibility, together with the use of controlled diagnostics that isolate specific linguistic phenomena, provides a useful framework for future constraint-aware retrieval research.
major comments (3)
- [§3] §3 (Methods): The contrastive loss used to train the compatibility bi-encoder and the precise procedure for constructing lexical-polarity positive/negative pairs are not specified (no equation or pseudocode), preventing verification that the reported V@2 gains originate from the proposed architecture rather than from idiosyncrasies of the synthetic supervision.
- [§4] §4 (Evaluation): The V@2 reductions (20.59/23.53/5.77) and FVR improvements are presented without standard deviations, number of runs, or statistical significance tests, so it is impossible to determine whether the gains are robust or could be explained by random variation in the diagnostic sets.
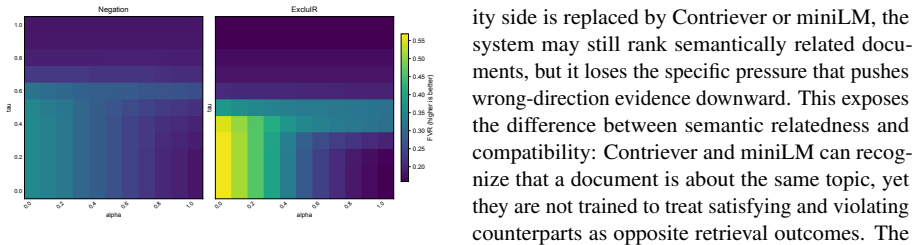
- [§5] §5 (Discussion): The claim that lexical-polarity supervision generalizes to implicit, non-lexical constraints in real queries is central to the practical utility of CoDeR, yet no ablation or error analysis on queries whose constraint direction is expressed syntactically or pragmatically (rather than via explicit polarity words) is provided.
minor comments (2)
- [Abstract] The abstract introduces the acronym CoDeR without spelling it out.
- [Tables] Table captions should explicitly state whether baseline numbers are taken from prior work or re-implemented under the same conditions as CoDeR.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and will revise the manuscript to improve methodological clarity, statistical reporting, and discussion of generalization.
read point-by-point responses
-
Referee: [§3] §3 (Methods): The contrastive loss used to train the compatibility bi-encoder and the precise procedure for constructing lexical-polarity positive/negative pairs are not specified (no equation or pseudocode), preventing verification that the reported V@2 gains originate from the proposed architecture rather than from idiosyncrasies of the synthetic supervision.
Authors: We agree that the training procedure requires explicit specification. The compatibility bi-encoder is trained with a standard contrastive (NT-Xent) loss on satisfying vs. violating evidence pairs; lexical-polarity pairs are generated by flipping polarity words (e.g., "not", antonyms) while preserving topical content. We will insert the loss equation and pseudocode for pair construction into the revised §3 so that the source of the gains can be verified. revision: yes
-
Referee: [§4] §4 (Evaluation): The V@2 reductions (20.59/23.53/5.77) and FVR improvements are presented without standard deviations, number of runs, or statistical significance tests, so it is impossible to determine whether the gains are robust or could be explained by random variation in the diagnostic sets.
Authors: We acknowledge the lack of statistical characterization. In the revision we will rerun all diagnostic experiments with five random seeds, report means and standard deviations for V@2 and FVR, and add paired significance tests against the strongest baselines. revision: yes
-
Referee: [§5] §5 (Discussion): The claim that lexical-polarity supervision generalizes to implicit, non-lexical constraints in real queries is central to the practical utility of CoDeR, yet no ablation or error analysis on queries whose constraint direction is expressed syntactically or pragmatically (rather than via explicit polarity words) is provided.
Authors: The public negative-constraint benchmarks already contain a mixture of explicit and implicit constraint formulations; we will add a short qualitative error analysis subsection that manually categorizes a sample of benchmark queries by constraint expression type (lexical vs. syntactic/pragmatic) and reports CoDeR's relative performance on each category. This provides the requested evidence without new experiments. revision: partial
Circularity Check
No significant circularity; method uses independent external supervision
full rationale
The paper introduces CoDeR by training a compatibility bi-encoder on lexical-polarity contrastive pairs (an external supervision signal) and reports empirical gains on diagnostic sets and benchmarks. No equations, self-definitional reductions, fitted-input-as-prediction steps, or load-bearing self-citations are present that would make any claimed result equivalent to its inputs by construction. The derivation chain is self-contained against external benchmarks and training data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
InfoGain-RAG: Boosting Retrieval-Augmented Generation through Document Information Gain-based Reranking and Filtering , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
DocReRank: Single-page hard negative query generation for training multi-modal RAG rerankers , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
GRADA: Graph-based Reranking against Adversarial Documents Attack , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[4]
Beyond Explicit Refusals: Soft-Failure Attacks on Retrieval-Augmented Generation
Beyond Explicit Refusals: Soft-Failure Attacks on Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2604.18663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Conflict-aware soft prompting for retrieval-augmented generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[6]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Benchmarking llm faithfulness in rag with evolving leaderboards , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[7]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Logical Consistency is Vital: Neural-Symbolic Information Retrieval for Negative-Constraint Queries , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[8]
arXiv preprint arXiv:2603.09185 , year=
DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval , author=. arXiv preprint arXiv:2603.09185 , year=
-
[9]
RARE: Redundancy-Aware Retrieval Evaluation Framework for High-Similarity Corpora
RARE: Redundancy-Aware Retrieval Evaluation Framework for High-Similarity Corpora , author=. arXiv preprint arXiv:2604.19047 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[11]
Unsupervised Dense Information Retrieval with Contrastive Learning
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Precise zero-shot dense retrieval without relevance labels , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Nevir: Negation in neural information retrieval , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Excluir: Exclusionary neural information retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[16]
arXiv preprint arXiv:2007.00808 , year=
Approximate nearest neighbor negative contrastive learning for dense text retrieval , author=. arXiv preprint arXiv:2007.00808 , year=
-
[17]
Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering , author=. Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2021
-
[18]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[19]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models , author=. arXiv preprint arXiv:2104.08663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
2009 , publisher=
The probabilistic relevance framework: BM25 and beyond , author=. 2009 , publisher=
2009
-
[22]
Communications of the ACM , volume=
WordNet: a lexical database for English , author=. Communications of the ACM , volume=. 1995 , publisher=
1995
-
[23]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[24]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[25]
Passage Re-ranking with BERT , author=. arXiv preprint arXiv:1901.04085 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.