Recognition: unknown
RARE: Redundancy-Aware Retrieval Evaluation Framework for High-Similarity Corpora
Pith reviewed 2026-05-10 02:28 UTC · model grok-4.3
The pith
Standard retrieval benchmarks fail to capture performance drops in redundant real-world corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
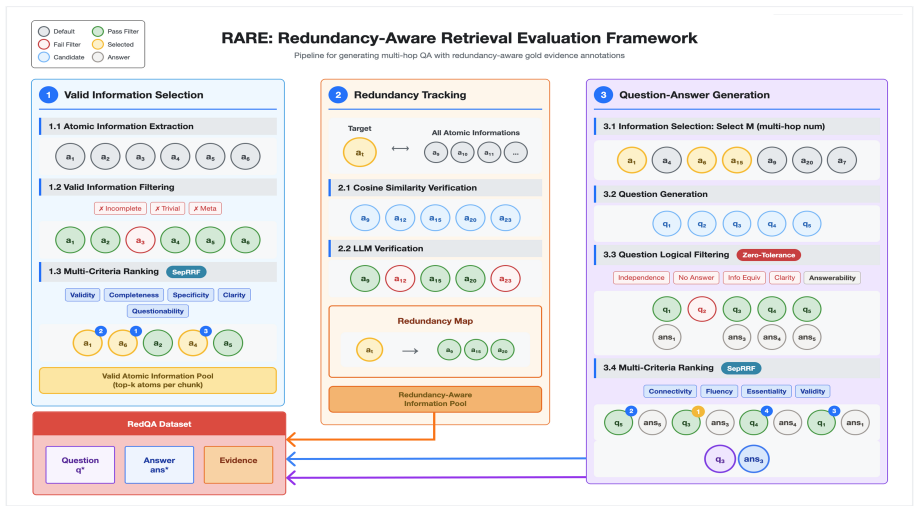
RARE constructs realistic retrieval benchmarks for high-similarity corpora by decomposing documents into atomic facts that enable precise tracking of redundant information and by using CRRF to score and fuse multiple quality criteria during LLM-based data generation. When this process is applied to Finance, Legal, and Patent corpora, the resulting RedQA benchmark shows that a strong retriever baseline drops sharply from 66.4% PerfRecall@10 on standard 4-hop General-Wiki tasks to 5.0-27.9% at 4-hop depth, exposing robustness gaps that existing benchmarks do not reveal.
What carries the argument
RARE framework using atomic-fact decomposition to track redundancy and CRRF rank-fusion to improve reliability of multi-criteria LLM benchmark generation.
If this is right
- Retrievers intended for finance, legal, and patent domains must be tested on benchmarks that account for document overlap rather than assuming distinct sources.
- Multi-hop retrieval metrics should credit any document that supplies required evidence even when other retrieved documents contain equivalent information.
- Benchmark construction pipelines benefit from separating and rank-fusing individual quality criteria instead of relying on single LLM judgments.
- Domain-specific RAG evaluations become feasible once atomic-fact decomposition is available for a corpus.
- Poor generalization from general wiki benchmarks to high-redundancy settings indicates that current retriever training objectives overlook information overlap.
Where Pith is reading between the lines
- Retriever architectures could incorporate explicit overlap detection modules trained on atomic-fact representations.
- The same decomposition technique might improve evaluation in other redundant domains such as clinical notes or scientific papers.
- If RedQA-style benchmarks become common, retriever training losses might shift toward rewarding coverage of unique facts rather than raw relevance scores.
- CRRF-style rank fusion offers a general method to stabilize LLM outputs when multiple orthogonal criteria must be satisfied simultaneously.
Load-bearing premise
Decomposing documents into atomic facts and fusing LLM quality criteria with CRRF produces benchmark data that faithfully reflects real-world redundancy without introducing new artifacts or biases.
What would settle it
If human experts reviewing the generated RedQA questions find that the tracked redundancy levels or question difficulty do not match actual overlap patterns in the source Finance, Legal, and Patent corpora, the evaluation validity claim would be falsified.
Figures






read the original abstract
Existing QA benchmarks typically assume distinct documents with minimal overlap, yet real-world retrieval-augmented generation (RAG) systems operate on corpora such as financial reports, legal codes, and patents, where information is highly redundant and documents exhibit strong inter-document similarity. This mismatch undermines evaluation validity: retrievers can be unfairly undervalued even when they retrieve documents that provide sufficient evidence, because redundancy across documents is not accounted for in evaluation. On the other hand, retrievers that perform well on standard benchmarks often generalize poorly to real-world corpora with highly similar and redundant documents. We present RARE (Redundancy-Aware Retrieval Evaluation), a framework for constructing realistic benchmarks by (i) decomposing documents into atomic facts to enable precise redundancy tracking and (ii) enhancing LLM-based data generation with CRRF. RAG benchmark data usually requires multiple quality criteria, but LLMs often yield trivial outputs. CRRF scores criteria separately and fuses decisions by rank, improving the reliability of generated data. Applying RARE to Finance, Legal, and Patent corpora, we introduce RedQA, where a strong retriever baseline drops from 66.4% PerfRecall@10 on 4-hop General-Wiki to 5.0-27.9% PerfRecall@10 at 4-hop depth, revealing robustness gaps that current benchmarks fail to capture. RARE enables practitioners to build domain-specific RAG evaluations that faithfully reflect real-world deployment conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the RARE framework for constructing QA benchmarks that account for high document redundancy and inter-document similarity in real-world corpora (e.g., finance, legal, patents). It does so via atomic-fact decomposition for redundancy tracking and CRRF (criteria rank fusion) to improve the quality of LLM-generated questions. The resulting RedQA benchmark is used to show that a strong retriever baseline drops from 66.4% PerfRecall@10 on 4-hop General-Wiki to 5.0-27.9% PerfRecall@10 at 4-hop depth, demonstrating robustness gaps missed by standard low-overlap benchmarks.
Significance. If the framework components prove free of construction artifacts, this work could meaningfully advance RAG evaluation by providing domain-specific benchmarks that better reflect deployment conditions with redundant documents. The concrete performance drops supply falsifiable evidence of a robustness gap, and the atomic-fact approach offers a principled way to handle redundancy that standard metrics overlook.
major comments (3)
- [RARE framework description] The atomic-fact decomposition process (described in the RARE framework section of the abstract and introduction) lacks any definition of what constitutes an atomic fact, the extraction procedure, or validation that multi-hop evidence chains are preserved without fragmentation or loss. This is load-bearing for the central claim, because the 66.4% to 5.0-27.9% PerfRecall@10 drop can only be interpreted as a corpus-driven robustness gap if the decomposition faithfully captures relevant redundancy.
- [CRRF and data generation] CRRF implementation details—including the exact quality criteria used, how LLMs score them separately, and the rank-fusion rule—are not provided. Without these, it is impossible to determine whether CRRF avoids introducing LLM generation biases that could artificially inflate question difficulty and thereby produce the reported performance drops.
- [Results and evaluation] The definition and exact computation of PerfRecall@10 (including how redundancy is incorporated into the metric) are not specified anywhere in the results or methods. This directly affects interpretability of the headline numbers and the robustness-gap conclusion.
minor comments (2)
- [Abstract] Acronyms (PerfRecall, CRRF, RARE, RedQA) should be expanded on first use in the abstract.
- The paper would be strengthened by at least one concrete example of an atomic-fact decomposition and a CRRF scoring instance to illustrate the pipeline.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments. We believe the suggested clarifications will strengthen the manuscript and address the concerns regarding reproducibility and interpretability. We respond to each major comment below.
read point-by-point responses
-
Referee: [RARE framework description] The atomic-fact decomposition process (described in the RARE framework section of the abstract and introduction) lacks any definition of what constitutes an atomic fact, the extraction procedure, or validation that multi-hop evidence chains are preserved without fragmentation or loss. This is load-bearing for the central claim, because the 66.4% to 5.0-27.9% PerfRecall@10 drop can only be interpreted as a corpus-driven robustness gap if the decomposition faithfully captures relevant redundancy.
Authors: We agree that a clear definition and procedure for atomic-fact decomposition is essential for validating the central claims. In the revised manuscript, we will expand the RARE framework section to include: (1) a formal definition of an atomic fact as the minimal unit of information that cannot be subdivided further without loss of meaning; (2) the extraction procedure, which involves LLM-based prompting with chain-of-thought to break down documents while preserving context; and (3) validation results demonstrating that multi-hop evidence chains remain intact, measured by comparing fact coverage in original vs. decomposed sets. These additions will confirm that the observed performance drops reflect corpus redundancy rather than decomposition artifacts. revision: yes
-
Referee: [CRRF and data generation] CRRF implementation details—including the exact quality criteria used, how LLMs score them separately, and the rank-fusion rule—are not provided. Without these, it is impossible to determine whether CRRF avoids introducing LLM generation biases that could artificially inflate question difficulty and thereby produce the reported performance drops.
Authors: We recognize the importance of detailing CRRF to ensure transparency and rule out generation biases. The revised version will provide: the complete list of quality criteria (relevance to corpus, question clarity, answerability from facts, difficulty level, and diversity); how LLMs score each criterion independently on a Likert scale via separate prompts; and the rank-fusion mechanism, which aggregates ranks using a weighted Borda count to select high-quality questions. We will also include an analysis of potential biases and steps taken to mitigate them, such as post-generation filtering. revision: yes
-
Referee: [Results and evaluation] The definition and exact computation of PerfRecall@10 (including how redundancy is incorporated into the metric) are not specified anywhere in the results or methods. This directly affects interpretability of the headline numbers and the robustness-gap conclusion.
Authors: We agree that the PerfRecall@10 metric requires explicit definition and computation details for proper interpretation. In the updated methods and results sections, we will define PerfRecall@10 as the proportion of queries for which at least one document covering the required atomic facts is retrieved within the top-10 results. Redundancy is incorporated by considering a document relevant if it contains any of the atomic facts needed for the query, allowing for overlapping evidence across documents. We will provide the mathematical formulation, pseudocode, and examples to illustrate how this differs from standard recall. revision: yes
Circularity Check
No circularity: framework and metrics are independently constructed and evaluated
full rationale
The paper introduces RARE as a novel construction method (atomic-fact decomposition plus CRRF rank-fusion) and applies it to produce the RedQA benchmark, then reports empirical retriever performance numbers on that benchmark. These numbers are direct measurements on the generated data rather than quantities derived from or forced by the construction procedure itself. No equations, fitted parameters, or self-citations are shown to reduce the headline result (66.4% to 5.0-27.9% PerfRecall@10) to the inputs by definition. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multilingual E5 Text Embeddings: A Technical Report
Curran Associates, Inc. Patrick Lewis, Yuxiang Wu, Linqing Liu, Pasquale Min- ervini, Heinrich Küttler, Aleksandra Piktus, Pontus Stenetorp, and Sebastian Riedel. 2021. PAQ: 65 mil- lion probably-asked questions and what you can do with them.Transactions of the Association for Com- putational Linguistics, 9:1098–1115. Macedo Maia, Siegfried Handschuh, And...
work page internal anchor Pith review arXiv 2021
-
[2]
Discovered the theory of relativity
”(specific quantitative context) Bad Examples (Fail). •“Discovered the theory of relativity. ”(missing who, when) •“The merger was announced. ”(missing which companies, when, financial terms) •“The document title is tesla_2023_annual_report.pdf. ”(meta information with no substantive value) F.3 Valid Information Multi-Criteria Ranking Prompt Design.Five s...
-
[3]
Books contain pages with text
” Bad Examples. •“Books contain pages with text. ”(trivial com- mon knowledge) •“The sky appears during daytime. ”(obvious, low value) •“People use phones to make calls. ”(not mean- ingfully useful) F.3.2 Criterion 2: Completeness Purpose.Assesses whether information is self- contained and understandable without additional document context. Someone unfami...
1989
-
[4]
The play Hamlet was authored by William Shakespeare circa 1600
” Comparison: “The play Hamlet was authored by William Shakespeare circa 1600. ” (Identical factual content, different expres- sion) UNIQUE • Target: “The company’s revenue increased by 15% in Q3 2023. ” Comparison: “The company’s expenses de- creased by 10% in Q3 2023. ” (Different concepts: revenue vs. expenses; opposite directions: increase vs. decreas...
2023
-
[5]
” (Different events: filing vs. granting) F.5 Question Generation Prompt Design.The prompt operates in two steps: (1)Information Selection—from a pool of atomic units, select items with highest connectivity poten- tial for natural multi-hop reasoning, and (2)Ques- tion Generation—generate multiple unique ques- tions requiring all selected units. The gener...
-
[6]
According to the table above, which environmental policy is most effective?
Contextual Independence • Bad: “According to the table above, which environmental policy is most effective?” • Good: “Which emissions reduction policy in the Inflation Reduction Act targets methane?”
-
[7]
Marie Curie worked at the University of Paris. When was the University of Paris established?
Answer Exclusion • Bad: “Marie Curie worked at the University of Paris. When was the University of Paris established?” • Good: “What year was the university where Marie Curie worked established?”
-
[8]
What university did Marie Curie work at?
Information Equivalence • Bad (Overflow): “What university did Marie Curie work at?”(only needs one unit) • Bad (Underflow): “How many students does the university where Marie Curie worked have?”(requires external info) • Good: “What year was the university where Marie Curie worked established?”(requires exactly both units)
-
[9]
Where is our headquarters located?
Question Clarity • Bad: “Where is our headquarters located?” (ambiguous pronoun) • Good: “Where is Tesla’s headquarters lo- cated?”(clear entity reference) F.5.3 Level 2: Preferred Quality Dimensions These four dimensions mirror the Question Multi- Criteria Ranking criteria (Section F.7):
-
[10]
In what year was Apple founded, and in what year was the iPhone released?
Connectivity • Bad: “In what year was Apple founded, and in what year was the iPhone released?”(parallel listing) • Good: “How many years did it take Apple to release its first iPhone after its founding?” (unified calculation)
-
[11]
What is the temporal differential cal- culation when subtracting the institutional es- tablishment year from 1900?
Fluency • Bad: “What is the temporal differential cal- culation when subtracting the institutional es- tablishment year from 1900?” • Good: “When did Marie Curie receive her Nobel Prize in Chemistry?”
1900
-
[12]
When did Marie Curie work at the University of Paris?
Essentiality • Bad: “What is the exact chronological period during which the highly distinguished Nobel laureate Marie Curie conducted her ground- breaking research at the prestigious Univer- sity of Paris?” • Good: “When did Marie Curie work at the University of Paris?”
-
[13]
What is the exact number of letters in the name of the university where Marie Curie worked?
Validity • Bad: “What is the exact number of letters in the name of the university where Marie Curie worked?” • Good: “What element did Marie Curie dis- cover and name after her native country?” F.6 Question Logical Filtering Prompt Design.Five filtering prompts implement zero-tolerance logical criteria. Each criterion must be satisfied independently; fai...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.