SkillCAT: Contrastive Assessment and Topology-Aware Skill Self-Evolution for LLM Agents
Pith reviewed 2026-06-27 06:30 UTC · model grok-4.3
The pith
SkillCAT improves LLM agent benchmark scores by up to 40 percent through training-free contrastive skill extraction, patch assessment on task clones, and topology-based routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
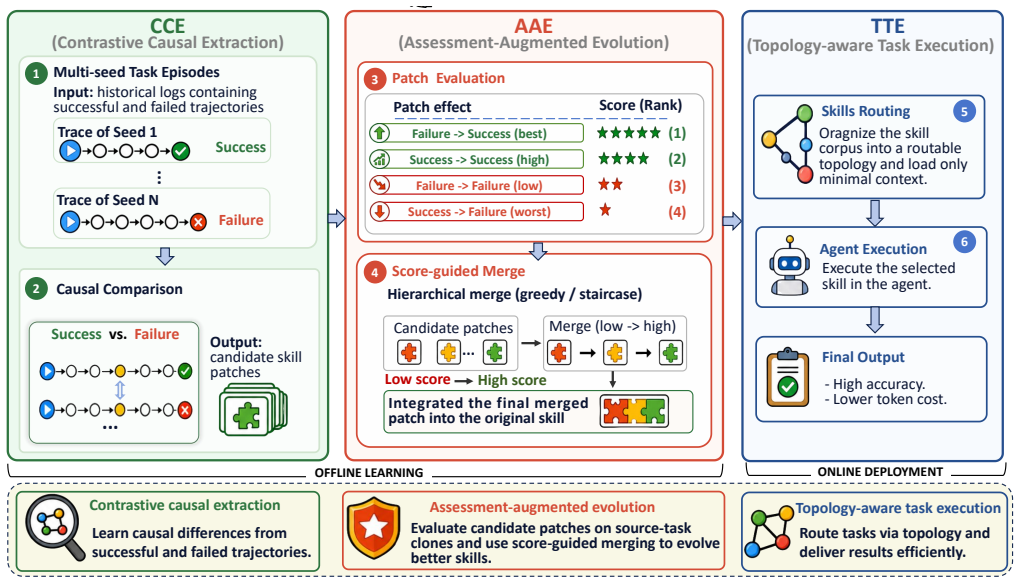
SkillCAT separates skill self-evolution into Contrastive Causal Extraction that compares same-task success and failure trajectories to extract causal evidence, Assessment-Augmented Evolution that replays candidate patches on source-task clones and merges only those that improve or preserve outcomes, and Topology-Aware Task Execution that compiles the skills into a routable sub-skill topology for selective loading at inference time. Evaluated on SpreadsheetBench, WikiTableQuestions, and DocVQA, the method raises average scores over baselines by up to 40.40 percent and demonstrates generalization across models and task distributions without any training.
What carries the argument
The three-stage pipeline consisting of Contrastive Causal Extraction (CCE) for identifying outcome differences from trajectory pairs, Assessment-Augmented Evolution (AAE) for validating patches via replay on task clones before merging, and Topology-Aware Task Execution (TTE) for building a routable skill topology that limits inference to relevant nodes.
If this is right
- Agents achieve higher success rates on spreadsheet manipulation, table question answering, and document visual question answering without retraining.
- The same skill set transfers to new language models and to tasks outside the original training distribution.
- Inference cost drops because only the topology nodes relevant to the current task are loaded.
- Skill evolution becomes more reliable by discarding patches that fail the clone assessment step.
Where Pith is reading between the lines
- The topology structure could support incremental addition of new skills without reloading the entire corpus.
- The contrastive extraction step might be adapted to other trajectory-based improvement methods that currently merge patches without explicit validation.
- If clone replay scales to longer-horizon tasks, the approach could extend to multi-step planning agents.
Load-bearing premise
Replaying candidate skill patches on source-task clones will identify patches that improve or preserve outcomes on the original task distribution without introducing unmeasured side effects or distribution shift.
What would settle it
Measure performance of the evolved skill set on a fresh sample of tasks drawn from the same benchmark distributions; if the average improvement over baselines disappears or reverses, the central claim does not hold.
Figures



read the original abstract
Skill self-evolution methods for LLM agents aim to turn execution trajectories into reusable skill documents, but current pipelines typically learn from one trajectory per task, merge candidate skill patches before checking them, and load the full skill corpus before inference. We propose SkillCAT, a training-free framework that separates this process into three stages. Contrastive Causal Extraction (CCE) samples multiple trajectories for each task and compares same-task success/failure pairs to identify evidence that explains outcome differences. Assessment-Augmented Evolution (AAE) replays each candidate patch on source-task clones and keeps only patches that improve or preserve task outcomes before hierarchical skill patch merging. Topology-Aware Task Execution (TTE) compiles the evolved skills into a routable sub-skill topology, so inference loads only the capability nodes relevant to the task. We evaluate SkillCAT on common agent benchmarks, including SpreadsheetBench, WikiTableQuestions, and DocVQA, and further test cross-model and out-of-distribution generalization. Across these settings, SkillCAT raises the average score over baselines by up to 40.40%, demonstrating reliable skill evolution without model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillCAT, a training-free framework for LLM agent skill self-evolution that decomposes the process into Contrastive Causal Extraction (CCE) to identify outcome differences from multiple trajectories, Assessment-Augmented Evolution (AAE) to filter candidate skill patches by replaying them on source-task clones, and Topology-Aware Task Execution (TTE) to compile skills into a routable sub-skill topology. It reports evaluation on SpreadsheetBench, WikiTableQuestions, and DocVQA plus cross-model and OOD tests, claiming up to 40.40% average score gains over baselines without model training.
Significance. If the AAE filtering mechanism is shown to reliably select generalizable patches, the work would offer a concrete advance in training-free skill library construction for agents by avoiding full corpus loading at inference and by using contrastive trajectory analysis rather than single-trajectory merging.
major comments (2)
- [§3.2] §3.2 (AAE): the central claim that retained patches improve or preserve outcomes on the original task distribution rests on replaying candidates on source-task clones, yet the manuscript provides no description of clone generation procedure, number of clones per task, or any correlation study between clone-based selection and held-out performance on the true distribution.
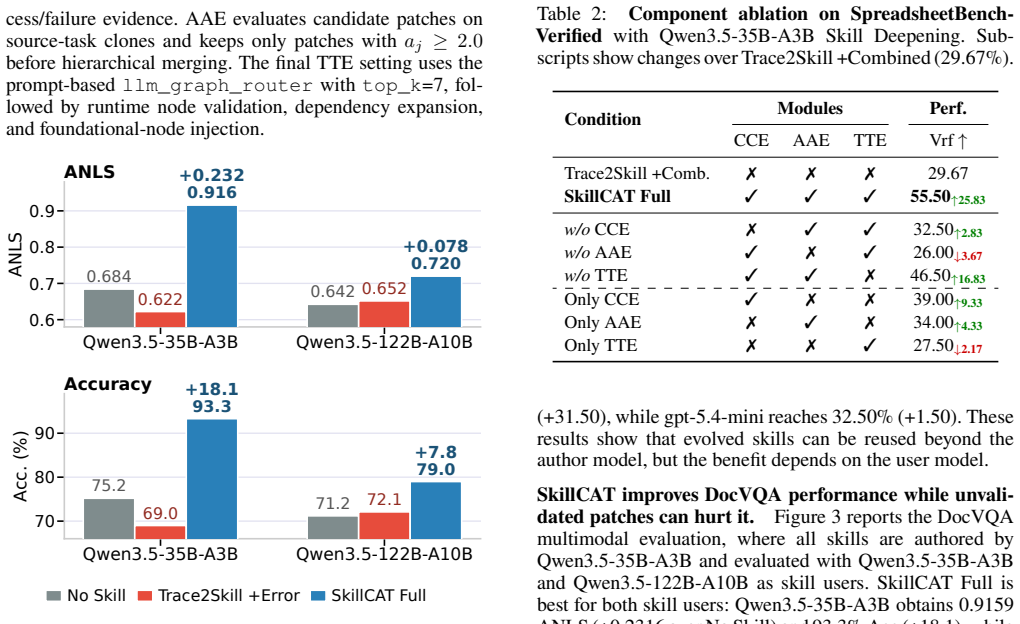
- [§4] §4 (Evaluation): the headline 40.40% average improvement is reported without error bars, statistical significance tests, number of runs, or ablation controls that isolate the contribution of CCE versus AAE versus TTE, making it impossible to assess whether the gains are robust or attributable to the proposed stages.
minor comments (2)
- Notation for skill patches and topology nodes is introduced without a consolidated table of symbols or running example that shows a single patch through all three stages.
- The abstract states 'raises the average score over baselines by up to 40.40%' but the main text should clarify whether this is the maximum across individual benchmarks or an aggregate, and list the exact baseline methods and their scores in a single table.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (AAE): the central claim that retained patches improve or preserve outcomes on the original task distribution rests on replaying candidates on source-task clones, yet the manuscript provides no description of clone generation procedure, number of clones per task, or any correlation study between clone-based selection and held-out performance on the true distribution.
Authors: We agree that the current manuscript lacks sufficient detail on the clone generation procedure and validation of the filtering step. In the revised version we will expand §3.2 with: (i) an explicit description of how source-task clones are constructed (by controlled perturbation of task inputs while preserving the underlying distribution), (ii) the exact number of clones generated per task, and (iii) a correlation analysis comparing clone-based selection decisions against performance on held-out instances from the true task distribution. These additions will directly substantiate the reliability of the AAE filtering mechanism. revision: yes
-
Referee: [§4] §4 (Evaluation): the headline 40.40% average improvement is reported without error bars, statistical significance tests, number of runs, or ablation controls that isolate the contribution of CCE versus AAE versus TTE, making it impossible to assess whether the gains are robust or attributable to the proposed stages.
Authors: We acknowledge that the evaluation section would be strengthened by greater statistical transparency and component-wise analysis. The revised manuscript will report: error bars computed across multiple independent runs, results of statistical significance tests, the precise number of runs performed, and dedicated ablation studies that isolate the individual contributions of CCE, AAE, and TTE to the observed gains. These changes will allow readers to better assess the robustness and attribution of the reported improvements. revision: yes
Circularity Check
No circularity; empirical framework evaluated on benchmarks
full rationale
The paper describes an empirical method (SkillCAT) with three stages (CCE, AAE, TTE) and reports measured performance gains (up to 40.40% over baselines) on specific benchmarks. No equations, parameter fitting, predictions derived from inputs, or self-citation chains appear in the abstract or description. Claims rest on experimental outcomes rather than any derivation that reduces to its own inputs by construction. This is the common case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evoskill:Automatedskilldiscoveryformulti-agent systems.arXiv preprint arXiv:2603.02766
Alzubi, S.; Provenzano, N.; Bingham, J.; Chen, W.; and Vu, T.2026. Evoskill:Automatedskilldiscoveryformulti-agent systems.arXiv preprint arXiv:2603.02766. Chen, K.; Zhong, Q.; Liu, J.; Du, B.; and Tao, D. 2026a. Try,CheckandRetry:ADivide-and-ConquerFrameworkfor Boosting Long-context Tool-Calling Performance of LLMs. arXiv preprint arXiv:2603.11495. Chen, ...
Pith/arXiv arXiv 2026
-
[2]
InInternational Conference on Learning Representations, volume 2024, 57734–57811
Critic: Large language models can self-correct withtool-interactivecritiquing. InInternational Conference on Learning Representations, volume 2024, 57734–57811. Jiang, G.; Su, Z.; Qu, X.; and Fung, Y. R
2024
-
[3]
Li, D.; Li, Z.; Du, H.; Wu, X.; Gui, S.; Kuang, Y.; and Sun, L
Xskill: Continuallearningfromexperienceandskillsinmultimodal agents.arXiv preprint arXiv:2603.12056. Li, D.; Li, Z.; Du, H.; Wu, X.; Gui, S.; Kuang, Y.; and Sun, L. 2026a. Graph of Skills: Dependency-Aware Struc- tural Retrieval for Massive Agent Skills.arXiv preprint arXiv:2604.05333. Li, M.; Zhao, Y.; Yu, B.; Song, F.; Li, H.; Yu, H.; Li, Z.; Huang, F.;...
-
[4]
InProceedings of the 2023 conference on empirical methods in natural language processing, 3102–3116
Api-bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 conference on empirical methods in natural language processing, 3102–3116. Li, X.; Chen, W.; Liu, Y.; Zheng, S.; Chen, X.; He, Y.; Li, Y.; You, B.; Shen, H.; Sun, J.; et al. 2026b. SkillsBench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint ...
Pith/arXiv arXiv 2023
-
[5]
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support.arXiv preprint arXiv:2604.08618. Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al
-
[6]
InInternational Conference on Learning Representations, volume 2024, 52989–53046
Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations, volume 2024, 52989–53046. Ma,Z.;Yang,S.;Ji,Y.;Wang,X.;Wang,Y.;Hu,Y.;Huang, T.;andChu,X.2026. Skillclaw:Letskillsevolvecollectively with agentic evolver.arXiv preprint arXiv:2604.08377. Ma, Z.; Zhang, B.; Zhang, J.; Yu, J.; Zhang, X.; Zhang, X.; Luo, S.; Wang, X....
Pith/arXiv arXiv 2024
-
[7]
Mathew,M.;Karatzas,D.;andJawahar,C.2021
Self-refine: Iterative refinement with self- feedback.Advances in neural information processing sys- tems, 36: 46534–46594. Mathew,M.;Karatzas,D.;andJawahar,C.2021. Docvqa:A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, 2200–2209. Meng, X.; Wang, S.; and Fang, Y
2021
-
[8]
Ni, J.; Liu, Y.; Liu, X.; Sun, Y.; Zhou, M.; Cheng, P.; Wang, D.; Zhao, E.; Jiang, X.; and Jiang, G
SkillRAE: Agent Skill-Based Context Compilation for Retrieval-Augmented Execution.arXiv preprint arXiv:2605.10114. Ni, J.; Liu, Y.; Liu, X.; Sun, Y.; Zhou, M.; Cheng, P.; Wang, D.; Zhao, E.; Jiang, X.; and Jiang, G
-
[9]
arXiv preprint arXiv:2603.25158
Trace2skill: Distill trajectory-local lessons into transferable agent skills. arXiv preprint arXiv:2603.25158. Pasupat, P.; and Liang, P
-
[10]
Toolllm:Facilitat- inglargelanguagemodelstomaster16000+real-worldapis
Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong,X.;Tang,X.; Qian,B.;etal.2024. Toolllm:Facilitat- inglargelanguagemodelstomaster16000+real-worldapis. InInternational Conference on Learning Representations, volume 2024, 9695–9717. Qwen Team
2024
-
[11]
Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.;Hambro,E.;Zettlemoyer,L.;Cancedda,N.;andScialom, T.2023
Qwen3.5: Towards Native Multimodal Agents. Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.;Hambro,E.;Zettlemoyer,L.;Cancedda,N.;andScialom, T.2023. Toolformer:Languagemodelscanteachthemselves to use tools.Advances in neural information processing systems, 36: 68539–68551. Shi, Y.; Chen, Y.; Lu, Z.; Miao, Y.; Liu, S.; Gu, Q.; Cai, X.; Wang,...
2023
-
[12]
Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; and Yao, S
Skill1: Unified Evolution of Skill-AugmentedAgentsviaReinforcementLearning.arXiv preprint arXiv:2605.06130. Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; and Yao, S
-
[13]
Tian, Y.; Chen, J.; Zheng, L.; Tao, M.; Zeng, X.; Yin, Z.; Su, H.; and Sun, X
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267. Tian, Y.; Chen, J.; Zheng, L.; Tao, M.; Zeng, X.; Yin, Z.; Su, H.; and Sun, X
-
[14]
Tu, S.; Xu, C.; Zhang, Q.; Zhang, Y.; Lan, X.; Li, L.; and Zhao, D
Skills-Coach: A Self-Evolving Skill Optimizer via Training-Free GRPO.arXiv preprint arXiv:2604.27488. Tu, S.; Xu, C.; Zhang, Q.; Zhang, Y.; Lan, X.; Li, L.; and Zhao, D
-
[15]
Wang, G.; Xie, Y.; Jiang, Y.; Mandlekar, A.; Xiao, C.; Zhu, Y.; Fan, L.; and Anandkumar, A
Dynamic Dual-Granularity Skill Bank for Agentic RL.arXiv preprint arXiv:2603.28716. Wang, G.; Xie, Y.; Jiang, Y.; Mandlekar, A.; Xiao, C.; Zhu, Y.; Fan, L.; and Anandkumar, A
-
[16]
Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen,Z.;Tang,J.;Chen,X.;Lin,Y.;etal.2024
Voyager: An open- ended embodied agent with large language models.arXiv preprint arXiv:2305.16291. Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen,Z.;Tang,J.;Chen,X.;Lin,Y.;etal.2024. Asurveyon large language model based autonomous agents.Frontiers of Computer Science, 18(6): 186345. Xia,T.;Hu,L.;Sun,Y.;Xu,M.;Xu,L.;Wang,S.;Xu,W.;and Jiang...
Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2603.01145
Autoskill: Experience-driven lifelong learning via skill self-evolution. arXiv preprint arXiv:2603.01145. Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; and Cao, Y
-
[18]
InInternational Conference on Learning Representations
React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations. Zhang, H.; Fan, S.; Zou, H. P.; Chen, Y.; Wang, Z.; Zhou, J.; Li, C.; Huang, W.-C.; Yao, Y.; Zheng, K.; et al. 2026a. Evoskills:Self-evolvingagentskillsviaco-evolutionaryver- ification.arXiv preprint arXiv:2604.01687. Zhang, H.; Long, Q.; Ba...
-
[19]
Zhou,H.;Guo,S.;Liu,A.;Yu,Z.;Gong,Z.;Zhao,B.;Chen, Z.;Zhang,M.;Chen,Y.;Li,J.;etal.2026a
Skil- lLearnBench: Benchmarking Continual Learning Methods for Agent Skill Generation on Real-World Tasks.arXiv preprint arXiv:2604.20087. Zhou,H.;Guo,S.;Liu,A.;Yu,Z.;Gong,Z.;Zhao,B.;Chen, Z.;Zhang,M.;Chen,Y.;Li,J.;etal.2026a. Memento-skills: Let agents design agents.arXiv preprint arXiv:2603.18743. Zhou, Y.; Shu, W.; Su, Y.; Du, W.; Fang, Y.; and Lin, X....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.