Ontology Memory-Augmented ASR Correction for Long Text-Speech Interleaved Conversations
Pith reviewed 2026-06-27 07:03 UTC · model grok-4.3
The pith
Ontology memory organizes conversation history into retrievable nodes to ground ASR corrections in long interleaved dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
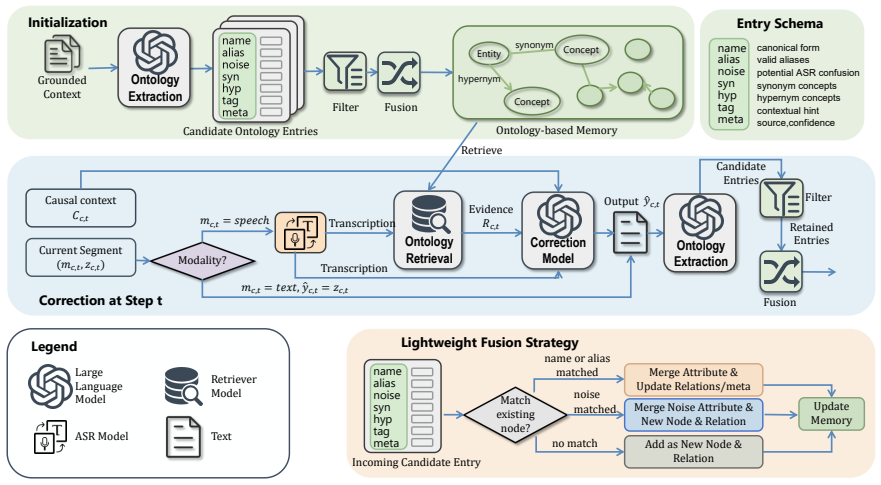
The framework organizes preceding interaction history into a dynamically updatable ontology memory, where entities, terminology, surface variants, potential ASR confusions, and semantic relations are stored as retrievable nodes for context-grounded correction.
What carries the argument
Ontology memory, a structured, updatable store of conversation nodes that can be queried to retrieve evidence for correcting context-dependent ASR errors.
If this is right
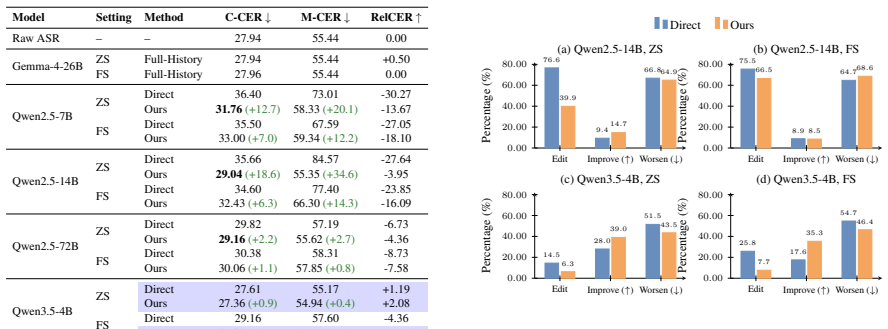
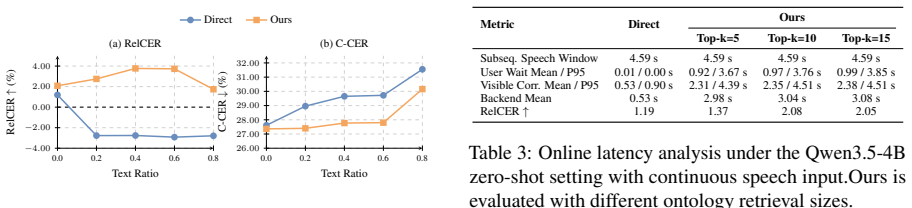
- Correction accuracy rises over direct methods in nine of ten tested backbone and setting combinations.
- Corrections shift toward selective, evidence-supported edits rather than ungrounded changes.
- Context-dependent ASR errors in extended conversations become addressable through node retrieval.
- The same memory structure supports ongoing updates as new turns arrive.
Where Pith is reading between the lines
- The same node structure could be reused for related tasks such as entity tracking or intent resolution across long sessions.
- Dynamic updates during live exchanges might allow the memory to track evolving terminology without full reprocessing.
- Retrieval quality would determine whether gains hold when the underlying ASR backbone changes.
Load-bearing premise
Preceding interaction history can be reliably organized into a dynamically updatable ontology memory whose nodes supply usable evidence for correction when retrieved.
What would settle it
A controlled test on long interleaved dialogues in which retrieval from the ontology memory produces no measurable rise in correction accuracy or evidence grounding compared with direct use of raw history.
Figures


read the original abstract
Automatic speech recognition (ASR) correction has traditionally focused on isolated utterances or short local contexts. However, as text and speech become increasingly interleaved in long interactions, ASR correction requires conversation-level contextual evidence. Existing ASR correction methods often rely on the current hypothesis or concatenate raw dialogue history. In such contexts, sparse correction evidence can be difficult to locate amid redundancy and noise. Addressing these challenges, we propose an ontology memory-augmented ASR correction framework for long text-speech interleaved conversations. The framework organizes preceding interaction history into a dynamically updatable ontology memory, where entities, terminology, surface variants, potential ASR confusions, and semantic relations are stored as retrievable nodes for context-grounded correction. To evaluate this setting, we construct RAMC-Corr, a dataset derived from MAGIC-RAMC for long-range ASR correction with grounded context. Experiments on RAMC-Corr show that our method improves over direct correction in 9 out of 10 paired backbone-setting combinations and encourages more selective and evidence-grounded corrections for context-dependent ASR errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an ontology memory-augmented ASR correction framework for long text-speech interleaved conversations. Preceding interaction history is organized into a dynamically updatable ontology memory whose nodes store entities, terminology, surface variants, potential ASR confusions, and semantic relations. The authors introduce the RAMC-Corr dataset derived from MAGIC-RAMC and report that the method improves over direct correction in 9 out of 10 paired backbone-setting combinations while producing more selective, evidence-grounded corrections for context-dependent errors.
Significance. If the empirical gains and the reliability of the ontology nodes are substantiated, the work could advance long-context ASR correction by replacing raw history concatenation with structured, retrievable evidence. The release of RAMC-Corr supplies a new benchmark resource for the community. The contribution is incremental rather than paradigm-shifting and hinges on whether the ontology extraction step functions as assumed.
major comments (2)
- [Abstract] Abstract: the central claim of improvement in 9/10 backbone-setting pairs is presented without any description of the experimental protocol, backbone models, baselines, error bars, statistical tests, ontology construction procedure, or retrieval mechanism, rendering the empirical result unevaluable.
- [Method] Method (ontology memory construction): the framework presupposes that entities, terminology, variants, confusions, and relations can be extracted and updated with sufficient fidelity from noisy ASR history to supply correct evidence on retrieval. No precision/recall metrics for node extraction, update error rates, or ablation that isolates the ontology structure versus raw history retrieval are supplied; this assumption is load-bearing for both the performance gains and the claim of more selective corrections.
minor comments (1)
- The notation used for ontology nodes and the retrieval scoring function should be introduced with a small concrete example early in the paper.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important aspects of clarity and validation. We address each major comment below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improvement in 9/10 backbone-setting pairs is presented without any description of the experimental protocol, backbone models, baselines, error bars, statistical tests, ontology construction procedure, or retrieval mechanism, rendering the empirical result unevaluable.
Authors: We agree that the abstract lacks sufficient detail on the experimental setup to fully evaluate the claim. In the revised version, we will modify the abstract to briefly outline the backbone models (such as the specific ASR and LLM combinations tested), the direct correction baseline, the RAMC-Corr dataset, and indicate that the 9/10 improvement rate was consistent across settings with error bars reported in the main results. Details on ontology construction and retrieval are in the Method section, which we will cross-reference. revision: yes
-
Referee: [Method] Method (ontology memory construction): the framework presupposes that entities, terminology, variants, confusions, and relations can be extracted and updated with sufficient fidelity from noisy ASR history to supply correct evidence on retrieval. No precision/recall metrics for node extraction, update error rates, or ablation that isolates the ontology structure versus raw history retrieval are supplied; this assumption is load-bearing for both the performance gains and the claim of more selective corrections.
Authors: This is a valid concern regarding the core assumption. The manuscript presents end-to-end performance improvements and qualitative examples of selective corrections as supporting evidence. To directly address this, we will include in the revision an evaluation of the ontology node extraction quality using precision and recall on a subset of conversations with human annotations for entities and relations. Additionally, we will add an ablation study comparing our ontology memory approach to a baseline that retrieves from raw concatenated history, to isolate the benefit of the structured ontology. revision: yes
Circularity Check
No circularity: empirical gains reported directly from experiments on constructed dataset
full rationale
The paper proposes an ontology memory framework for ASR correction and evaluates it empirically on the RAMC-Corr dataset derived from MAGIC-RAMC. No equations, fitted parameters, derivations, or predictions appear; the central claim (improvement in 9/10 backbone-setting pairs) is presented as an observed experimental outcome rather than a quantity defined in terms of the method itself or reduced via self-citation. The ontology construction step is an engineering assumption whose fidelity is not validated in the provided text, but this is a correctness/assumption risk rather than circularity. The derivation chain is self-contained as a standard ML method + ablation-style evaluation with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ontology memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kim, Heeseung and Lee, Che Hyun and Park, Sangkwon and Yeom, Jiheum and Park, Nohil and Yu, Sangwon and Yoon, Sungroh. Does Your Voice Assistant Remember? Analyzing Conversational Context Recall and Utilization in Voice Interaction Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.470
-
[2]
Connecting Automated Speech Recognition to Transcription Practices
Billings, Blaine and McDonnell, Bradley. Connecting Automated Speech Recognition to Transcription Practices. Proceedings of the Eight Workshop on the Use of Computational Methods in the Study of Endangered Languages. 2025
2025
-
[3]
HangChen, HangChen and Yang, Chao-Han Huck and Gu, Jia-Chen and Siniscalchi, Sabato Marco and Du, Jun. MISP -Meeting: A Real-World Dataset with Multimodal Cues for Long-form Meeting Transcription and Summarization. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.ac...
-
[4]
S peech GPT : Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
Zhang, Dong and Li, Shimin and Zhang, Xin and Zhan, Jun and Wang, Pengyu and Zhou, Yaqian and Qiu, Xipeng. S peech GPT : Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.1055
-
[5]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K. Rubenstein and Chulayuth Asawaroengchai and Duc Dung Nguyen and Ankur Bapna and Zal. AudioPaLM:. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2306.12925 , eprinttype =. 2306.12925 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.12925 2023
-
[6]
Chao. Generative Speech Recognition Error Correction With Large Language Models and Task-Activating Prompting , booktitle =. 2023 , url =. doi:10.1109/ASRU57964.2023.10389673 , timestamp =
-
[7]
HyPoradise: An Open Baseline for Generative Speech Recognition with Large Language Models , booktitle =
Chen Chen and Yuchen Hu and Chao. HyPoradise: An Open Baseline for Generative Speech Recognition with Large Language Models , booktitle =. 2023 , url =
2023
-
[8]
Marco Ruscone and Eirini Tsirvouli and Andrea Checcoli and D. NeKo:. PLoS Comput. Biol. , volume =. 2025 , url =. doi:10.1371/JOURNAL.PCBI.1013300 , timestamp =
-
[9]
Yang, Zhengdong and Wan, Zhen and Li, Sheng and Yang, Chao-Han Huck and Chu, Chenhui. C o V o GER : A Multilingual Multitask Benchmark for Speech-to-text Generative Error Correction with Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.320
-
[10]
Anna V. R. Lattice Re-Scoring During Manual Editing for Automatic Error Correction of. 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, September 15-19, 2019 , pages =. 2019 , url =. doi:10.21437/INTERSPEECH.2019-1790 , timestamp =
-
[11]
Ghosh, Sreyan and Rasooli, Mohammad Sadegh and Levit, Michael and Wang, Peidong and Xue, Jian and Manocha, Dinesh and Li, Jinyu. Failing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.125
-
[12]
D e RAGEC : Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Im, Solee and Lee, Wonjun and An, JinMyeong and Kim, Yunsu and Ok, Jungseul and Lee, Gary. D e RAGEC : Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.786
-
[13]
Generative Annotation for ASR Named Entity Correction
Luo, Yuanchang and Wei, Daimeng and Li, Shaojun and Shang, Hengchao and Guo, Jiaxin and Li, Zongyao and Wu, Zhanglin and Chen, Xiaoyu and Rao, Zhiqiang and Yang, Jinlong and Yang, Hao. Generative Annotation for ASR Named Entity Correction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.em...
-
[14]
Fei Yang and Xuanfan Ni and Renyi Yang and Jiahui Geng and Qing Li and Chenyang Lyu and Yichao Du and Longyue Wang and Weihua Luo and Kaifu Zhang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.13539 , eprinttype =. 2601.13539 , timestamp =
-
[15]
Whisper-CD: Accurate Long-Form Speech Recognition using Multi-Negative Contrastive Decoding
Hoseong Ahn and Jeongyun Chae and Yoonji Park and Kyuhong Shim , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.06193 , eprinttype =. 2603.06193 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.06193 2026
-
[16]
Haoqin Sun and Chenyang Lyu and Shiwan Zhao and Xuanfan Ni and Xiangyu Kong and Longyue Wang and Weihua Luo and Yong Qin , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.05373 , eprinttype =. 2602.05373 , timestamp =
-
[17]
arXiv preprint arXiv:2507.13264 , year=
Mistral AI , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.13264 , eprinttype =. 2507.13264 , timestamp =
-
[18]
Chengyao Wang and Zhisheng Zhong and Bohao Peng and Senqiao Yang and Yuqi Liu and Haokun Gui and Bin Xia and Jingyao Li and Bei Yu and Jiaya Jia , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.25131 , eprinttype =. 2509.25131 , timestamp =
-
[19]
Kun Wei and Bei Li and Hang Lv and Quan Lu and Ning Jiang and Lei Xie , title =. 2024 , url =. doi:10.1109/TASLP.2024.3389630 , timestamp =
-
[20]
Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework
Ke, Cai and Du, Yiming and Liang, Bin and Xiang, Yifan and Gui, Lin and Li, Zhongyang and Wang, Baojun and Yu, Yue and Wang, Hui and Wong, Kam-Fai and Xu, Ruifeng. Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18...
-
[21]
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations
Chen, Nuo and Li, Hongguang and Chang, Jianhui and Huang, Juhua and Wang, Baoyuan and Li, Jia. Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[22]
In2023 IEEE International Conference on Big Data (BigData)
Min Zhang and Xiaosong Qiao and Yanqing Zhao and Chang Su and Yinglu Li and Yuang Li and Ming Zhu and Mengyao Piao and Song Peng and Shimin Tao and Hao Yang and Yanfei Jiang , editor =. Knowledge Prompt for Whisper: An. 2023 , url =. doi:10.1109/BIGDATA59044.2023.10386366 , timestamp =
-
[23]
Sreyan Ghosh and Mohammad Sadegh Rasooli and Michael Levit and Peidong Wang and Jian Xue and Dinesh Manocha and Jinyu Li , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.13198 , eprinttype =. 2410.13198 , timestamp =
-
[24]
Zehui Yang and Yifan Chen and Lei Luo and Runyan Yang and Lingxuan Ye and Gaofeng Cheng and Ji Xu and Yaohui Jin and Qingqing Zhang and Pengyuan Zhang and Lei Xie and Yonghong Yan , editor =. Open Source MagicData-RAMC:. 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022 , ...
-
[25]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.