Uncertainty-Aware Hybrid Retrieval for Long-Document RAG
Pith reviewed 2026-06-27 06:59 UTC · model grok-4.3
The pith
Uncertainty estimates from score distributions let existing retrievers fuse multi-granularity chunks without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
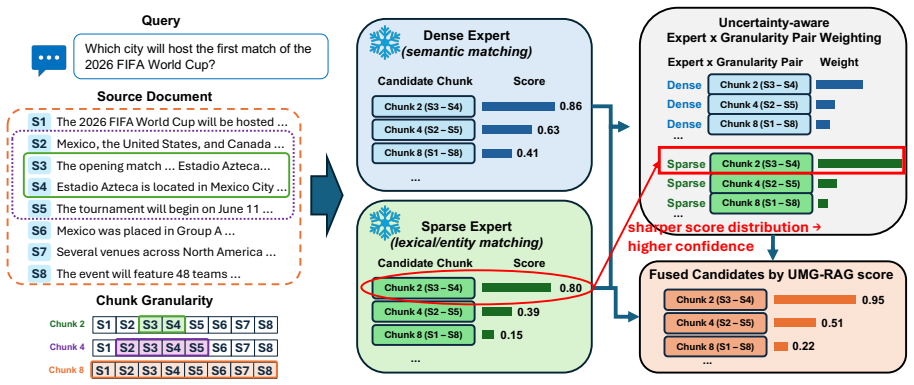
UMG-RAG converts each expert-granularity score list into an evidence distribution, computes its entropy as a query-specific reliability weight, and fuses candidates across dense and sparse retrievers at multiple chunk sizes; the UMGP-RAG variant additionally promotes fine-grained hits to their parent chunks to supply local coherence without redundancy.
What carries the argument
Entropy of per-expert evidence distributions used as query-specific fusion weights across chunk granularities.
If this is right
- Generation quality rises on long-document QA tasks while the retriever and generator remain untouched.
- The same existing dense and sparse retrievers can be reused at multiple chunk sizes without additional training.
- Parent promotion supplies coherent context around fine-grained evidence without returning duplicate material.
- The fusion step adds negligible latency because it operates only on already-retrieved score lists.
Where Pith is reading between the lines
- The same entropy signal could be used to decide when to fall back to a larger retrieval budget or to trigger re-ranking.
- If score distributions are poorly calibrated on some domains, the entropy weights may need a small per-domain scaling factor before fusion.
- The parent-promotion logic could be extended to hierarchical documents where multiple levels of parents exist.
Load-bearing premise
Entropy of the score distributions gives a reliable, query-specific signal of retrieval reliability that can be used directly for fusion without introducing new biases.
What would settle it
An experiment that replaces the entropy-derived weights with fixed or uniform weights and measures whether answer quality on the same QA benchmarks drops, stays the same, or improves.
Figures

read the original abstract
Retrieval augmented generation (RAG) depends critically on the quality and granularity of retrieved evidence. Large retrieval units preserve context but often introduce irrelevant content, which can dilute answer bearing evidence and worsen long context utilization. Fine-grained units are more compact, but they may be difficult to retrieve reliably because short chunks can lack semantic, lexical, or bridging cues needed to match the query. We propose Uncertainty-aware Multi-Granularity RAG (UMG-RAG), a training-free hybrid retrieval framework that treats chunk granularity as query-specific reliability estimation. Instead of training a new retriever or modifying the generator, UMG-RAG uses existing dense and sparse retrievers as complementary experts across multiple chunk granularities. For each query, it converts each expert-granularity score list into an evidence distribution, estimates reliability from distribution entropy, and fuses candidates according to query-specific semantic, lexical, and granularity confidence. We further introduce UMGP-RAG, a parent promotion variant that uses fine-grained hits to locate relevant evidence while returning broader non-redundant parent chunks for local coherence. Experiments on question answering benchmarks show that uncertainty-aware fusion and parent promotion improve generation quality while maintaining a lightweight, plug-and-play retrieval pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Uncertainty-aware Multi-Granularity RAG (UMG-RAG), a training-free hybrid retrieval framework for long-document RAG. It treats chunk granularity as a query-specific reliability signal by running existing dense and sparse retrievers as complementary experts across multiple granularities, converting each expert-granularity score list to an evidence distribution, estimating reliability via entropy, and fusing candidates using semantic, lexical, and granularity . A parent-promotion variant (UMGP-RAG) returns broader parent chunks from fine-grained hits. The central claim is that uncertainty-aware fusion and parent promotion improve generation quality on QA benchmarks while remaining lightweight and plug-and-play.
Significance. If the entropy-based reliability estimates prove robust and unbiased, the approach offers a practical, training-free way to combine complementary retrievers and granularities in RAG pipelines without new model training or heavy calibration. This could be useful for long-document settings where context dilution and retrieval reliability are key bottlenecks.
major comments (2)
- [Method (entropy calculation)] Method section (entropy-to-reliability step): The conversion of raw score lists to evidence distributions for entropy calculation does not specify any per-retriever normalization (z-score, min-max, or temperature scaling). Dense retriever scores (bounded similarities) and sparse scores (unbounded BM25 sums) live on incommensurate scales, so the resulting entropy values are not guaranteed to be comparable as reliability weights; the fusion can therefore be dominated by whichever retriever produces larger raw variance.
- [Experiments] Experiments section: The abstract asserts benchmark improvements from uncertainty-aware fusion and parent promotion, yet the provided text supplies no quantitative results, baselines, error bars, ablation tables, or exclusion criteria. Without these, the data-to-claim link for the central fusion mechanism cannot be verified.
minor comments (1)
- [Abstract] Abstract: Consider adding one or two key quantitative results (e.g., exact delta on a named benchmark) to make the performance claim concrete.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and will incorporate clarifications and expansions in the revised version.
read point-by-point responses
-
Referee: [Method (entropy calculation)] Method section (entropy-to-reliability step): The conversion of raw score lists to evidence distributions for entropy calculation does not specify any per-retriever normalization (z-score, min-max, or temperature scaling). Dense retriever scores (bounded similarities) and sparse scores (unbounded BM25 sums) live on incommensurate scales, so the resulting entropy values are not guaranteed to be comparable as reliability weights; the fusion can therefore be dominated by whichever retriever produces larger raw variance.
Authors: We agree this is an important clarification needed. The manuscript does not currently detail the normalization step. In the revision, we will explicitly describe applying min-max normalization independently to each expert-granularity score list (mapping to [0,1]) before forming evidence distributions and computing entropy. This ensures commensurability of reliability weights across dense and sparse retrievers despite differing raw score scales. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts benchmark improvements from uncertainty-aware fusion and parent promotion, yet the provided text supplies no quantitative results, baselines, error bars, ablation tables, or exclusion criteria. Without these, the data-to-claim link for the central fusion mechanism cannot be verified.
Authors: The full manuscript includes an Experiments section reporting results on QA benchmarks. However, to address the concern directly, we will expand this section in revision to present all quantitative results, baseline comparisons, error bars, full ablation tables, and explicit exclusion criteria for datasets, making the support for the fusion claims fully verifiable. revision: yes
Circularity Check
No circularity: method uses external retrievers and entropy on raw scores without self-referential fitting or definitions
full rationale
The paper describes a training-free pipeline that converts existing dense/sparse retriever score lists into distributions and derives reliability weights from entropy, then fuses candidates. No equations, fitted parameters, or self-citations are presented that would make the claimed quality gains reduce to a quantity defined by the method itself. The derivation remains independent of its outputs and relies on external retrievers as black-box experts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing dense and sparse retrievers function as complementary experts whose score distributions at varying granularities can be meaningfully compared via entropy
Reference graph
Works this paper leans on
-
[1]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. Preprint, arXiv:2402.03216. Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher
-
[2]
Bert: Pre-training of deep bidirectional transformers for language understand- ing. InProceedings of the 2019 conference of the North American chapter of the association for com- putational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186. Falconsai
2019
-
[3]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang
-
[4]
Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3). Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Kr- ishna, and 1 others
-
[5]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 14982– 14995
Found in the middle: Cali- brating positional attention bias improves long con- text utilization. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14982– 14995. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024a. Longllmlingua: Accelerating and enhancing llms in long context sce...
arXiv 2024
-
[6]
The cost of context: Mitigating textual bias in multimodal retrieval-augmented generation.arXiv preprint arXiv:2605.05594. Rishi Kalra, Zekun Wu, Ayesha Gulley, Airlie Hilliard, Xin Guan, Adriano Koshiyama, and Philip Colin Tre- leaven
-
[7]
Splade-v3: New baselines for splade.arXiv preprint arXiv:2403.06789. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, and 1 others
-
[8]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 881–
Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 881–
2024
-
[9]
Lost in the middle: How lan- guage models use long contexts.arXiv preprint arXiv:2307.03172. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
-
[10]
Kilt: a benchmark for knowledge intensive language tasks.arXiv preprint arXiv:2009.02252. Weijia Shi, Sewon Min, Michihiro Yasunaga, Min- joon Seo, Richard James, Mike Lewis, Luke Zettle- moyer, and Wen-tau Yih
arXiv 2009
-
[11]
Replug: Retrieval- augmented black-box language models. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (V olume 1: Long Papers), pages 8371–8384. Wenyu Tao, Xiaofen Xing, Zeliang Li, and Xiangmin Xu
2024
-
[12]
InProceedings of the 2025 Conference on Empirical Methods in Natu- ral Language Processing, pages 1195–1213, Suzhou, China
SAKI-RAG: Mitigating context fragmen- tation in long-document RAG via sentence-level at- tention knowledge integration. InProceedings of the 2025 Conference on Empirical Methods in Natu- ral Language Processing, pages 1195–1213, Suzhou, China. Association for Computational Linguistics. Ziqi Wang, Hanlin Zhang, Xiner Li, Kuan-Hao Huang, Chi Han, Shuiwang J...
2025
-
[13]
Qwen2 technical report.arXiv preprint arXiv:2407.10671. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D. Manning
-
[14]
HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empiri- cal Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Com- putational Linguistics. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Li...
Pith/arXiv arXiv 2018
-
[15]
arXiv preprint arXiv:2501.16952
Mul- tiple abstraction level retrieve augment generation. arXiv preprint arXiv:2501.16952. 10 A Detailed Algorithm of UMGP-RAG Algorithm 1UMGP-RAG Require: Query q, experts E, granularities G, M= 100 , K= 5, overlap cutoff0.75 Ensure:Selected context chunksS 1:U cand ← ∅ 2:for all(e, g)∈ E × Gdo 3:C e,g(q)←TopM u∈Ug se,g(q, u) 4: Computep e,g(u|q,C e,g)fr...
arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.